基于GPU并行加速的基础矩阵和单应矩阵估计方法和系统与流程
本发明属于计算机视觉领域,更具体地,涉及一种基于gpu并行加速的基础矩阵和单应矩阵估计方法和系统。
背景技术:
三维重建是在计算机中建立表达客观世界的虚拟现实的关键技术。近几年来,三维重建已经越来越成为一门比较热门的课题。而在其中对于无序图像的重建也渐渐成为很多人关注的重点,对无序图像的重建最经典的方法要属增量式structurefrommotion(sfm)。该方法的过程主要包括:提取图像特征点;建立图像对之间特征点匹配关系;计算图像之间的双视图几何关系;根据匹配估计稀疏三维点云和相机参数。双视图几何关系中主要是计算图像之间的基础矩阵和单应矩阵,基础矩阵可以用于剔除图像之间的错误匹配,提高重建精度;单应矩阵的内点率可以反映图像之间是否存在平面场景以及推测图像之间基线的大小,可用于选择合适的重建起点,因此两者对于重建都有比较重要的作用。
但是在sfm中,基础矩阵和单应矩阵的计算主要还是在cpu上完成。其往往需要与随机采样一致性算法(ransac)结合,才能得到比较鲁棒的结果,但是利用ransac算法需要多次采样并重复计算,因而是比较耗时的,特别是在大规模图像的三维重建中,基础矩阵和单应矩阵计算时间的问题将会更加突出。
由此可见,现有的基础矩阵和单应矩阵估计方法中存在计算时间长,效率低的技术问题。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于gpu并行加速的基础矩阵和单应矩阵估计方法和系统,由此解决现有的基础矩阵和单应矩阵估计方法中存在计算时间长,效率低的技术问题。
为实现上述目的,按照本发明的一个方面,提供了一种基于gpu并行加速的基础矩阵和单应矩阵估计方法,包括:
(1)对多个图像,提取每个图像的特征点,基于特征点利用匹配算法得到每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息,定义图像对的匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号,以便于查找;
(2)从具有匹配关系的所有图像对中选取m个图像对进行并行计算,在选取的每个图像对的匹配列表中采集c*n个匹配对,此时c表示计算一个基础矩阵或单应矩阵需要的匹配对数量,n为矩阵原始算法中ransac的最大迭代次数,对于m个图像对,利用gpu并行产生m*n组随机采样序列,每组随机采样序列包含c个随机数,每个随机数为相应图像对中匹配对的索引编号;
(3)对于每组随机采样序列,基于索引编号对应的匹配对得到候选基础矩阵或候选单应矩阵和相应的内点数量,利用gpu并行得到m*n个候选基础矩阵或m*n个候选单应矩阵和相应的m*n个内点数;
(4)在属于同一个图像对的n个候选基础矩阵或n个候选单应矩阵中获取内点数最大的矩阵为初始基础矩阵或初始单应矩阵,则m*n个候选基础矩阵中得到m个初始基础矩阵,m*n个候选单应矩阵中得到m个初始单应矩阵,对m个初始基础矩阵或m个初始单应矩阵进行优化得到最终的基础矩阵或最终的单应矩阵。
进一步的,步骤(3)的具体实现方式为:
对于每组随机采样序列,基于索引编号对应的匹配对利用归一化八点法得到候选基础矩阵,并计算候选基础矩阵相应的内点数,利用gpu并行得到m*n个候选基础矩阵和m*n个相应的内点数量;对于每组随机采样序列,基于索引编号对应的匹配对利用双视图几何中平面的单应性得到候选单应矩阵,并通过计算匹配对的投影误差得到候选单应矩阵相应的内点数量,利用gpu并行得到m*n个候选基础矩阵和m*n个相应的内点数量。
进一步的,步骤(4)的具体实现方式为:
在属于同一个图像对的n个候选基础矩阵或n个候选单应矩阵中获取内点数最大的矩阵为初始基础矩阵或初始单应矩阵,则m*n个候选基础矩阵中得到m个初始基础矩阵,m*n个候选单应矩阵中得到m个初始单应矩阵,利用cminpack库中的lmdif非线性最小二乘法对这m个初始基础矩阵进行并行优化,得到图像对最终的基础矩阵,利用cminpack库中的dgelsy线性最小二乘法优化多个图像对的初始单应矩阵,得到优化单应矩阵;然后利用cminpack库中的lmdif非线性最小二乘法对多个图像对的优化单应矩阵进行并行优化,得到图像对最终的单应矩阵。
按照本发明的另一方面,提供了一种基于gpu并行加速的基础矩阵和单应矩阵估计系统,包括:
第一模块,用于对多个图像,提取每个图像的特征点,基于特征点利用匹配算法得到每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息,定义图像对的匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号,以便于查找;
第二模块,用于从具有匹配关系的所有图像对中选取m个图像对进行并行计算,在选取的每个图像对的匹配列表中采集c*n个匹配对,此时c表示计算一个基础矩阵或单应矩阵需要的匹配对数量,n为矩阵原始算法中ransac的最大迭代次数,对于m个图像对,利用gpu并行产生m*n组随机采样序列,每组随机采样序列包含c个随机数,每个随机数为相应图像对中匹配对的索引编号;
第三模块,用于对于每组随机采样序列,基于索引编号对应的匹配对得到候选基础矩阵或候选单应矩阵和相应的内点数量,利用gpu并行得到m*n个候选基础矩阵或m*n个候选单应矩阵和相应的m*n个内点数;
第四模块,用于在属于同一个图像对的n个候选基础矩阵或n个候选单应矩阵中获取内点数最大的矩阵为初始基础矩阵或初始单应矩阵,则m*n个候选基础矩阵中得到m个初始基础矩阵,m*n个候选单应矩阵中得到m个初始单应矩阵,对m个初始基础矩阵或m个初始单应矩阵进行优化得到最终的基础矩阵或最终的单应矩阵。
进一步的,第三模块的具体实现方式为:
对于每组随机采样序列,基于索引编号对应的匹配对利用归一化八点法得到候选基础矩阵,并计算候选基础矩阵相应的内点数,利用gpu并行得到m*n个候选基础矩阵和m*n个相应的内点数量;对于每组随机采样序列,基于索引编号对应的匹配对利用双视图几何中平面的单应性得到候选单应矩阵,并通过计算匹配对的投影误差得到候选单应矩阵相应的内点数量,利用gpu并行得到m*n个候选基础矩阵和m*n个相应的内点数量。
进一步的,第四模块的具体实现方式为:
在属于同一个图像对的n个候选基础矩阵或n个候选单应矩阵中获取内点数最大的矩阵为初始基础矩阵或初始单应矩阵,则m*n个候选基础矩阵中得到m个初始基础矩阵,m*n个候选单应矩阵中得到m个初始单应矩阵,利用cminpack库中的lmdif非线性最小二乘法对这m个初始基础矩阵进行并行优化,得到图像对最终的基础矩阵,利用cminpack库中的dgelsy线性最小二乘法优化多个图像对的初始单应矩阵,得到优化单应矩阵;然后利用cminpack库中的lmdif非线性最小二乘法对多个图像对的优化单应矩阵进行并行优化,得到图像对最终的单应矩阵。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明基于特征点利用匹配算法得到每个图像对的匹配列表,然后根据显存大小选取m个预计算的图像对,对此m个图像对中的特征点匹配对进行并行随机采样,根据采样结果并行地计算得到对应的候选矩阵和相应的内点数,进而选取每个图像对中内点数最大的候选矩阵进行优化得到最终的基础矩阵或单应矩阵,最终达到大幅度减少基础矩阵和单应矩阵计算时间的目的。
(2)优选的,本发明利用线性同余算法并行地产生m*n组随机采样序列,优化过程中,基础矩阵利用cminpack库中的lmdif非线性最小二乘法对这m个初始基础矩阵进行并行优化,减少了基础矩阵的计算时间,单应矩阵利用cminpack库中的dgelsy线性最小二乘法优化多个图像对的初始单应矩阵,得到优化单应矩阵;然后利用cminpack库中的lmdif非线性最小二乘法对多个图像对的优化单应矩阵进行并行优化,得到每个图像对最终的单应矩阵,减少了单应矩阵的计算时间。
附图说明
图1是本发明实施例提供的一种基于gpu并行加速的基础矩阵和单应矩阵估计方法的流程图;
图2是本发明实施例1提供一种基于gpu并行加速的基础矩阵估计方法的流程图;
图3是本发明实施例1提供的特征点匹配的流程图;
图4是本发明实施例1提供的一种基于gpu并行加速的单应矩阵估计的流程图;
图5是本发明实施例1提供的单应矩阵计算中优化得到最终单应矩阵的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
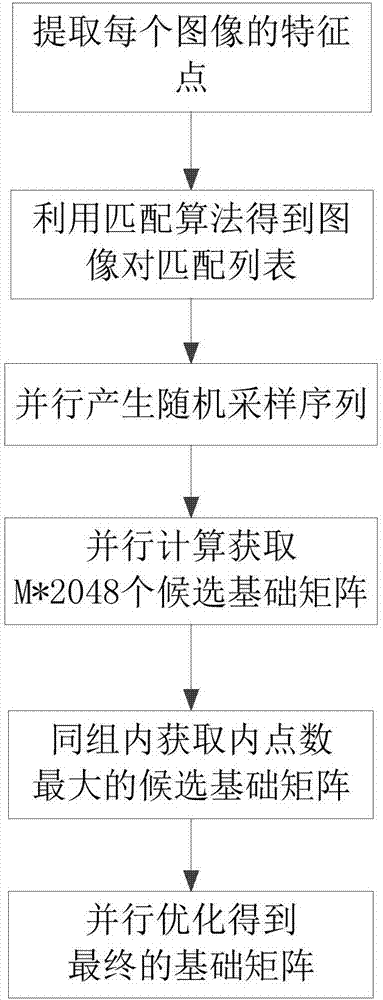
如图1所示,一种基于gpu并行加速的基础矩阵和单应矩阵估计方法,包括:
(1)对多个图像,提取每个图像的特征点,基于特征点利用匹配算法得到每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息,定义图像对的匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号,以便于查找;
(2)从具有匹配关系的所有图像对中选取m个图像对进行并行计算,在选取的每个图像对的匹配列表中采集c*n个匹配对,此时c表示计算一个基础矩阵或单应矩阵需要的匹配对数量,n为矩阵原始算法中ransac的最大迭代次数,对于m个图像对,利用gpu并行产生m*n组随机采样序列,每组随机采样序列包含c个随机数,每个随机数为相应图像对中匹配对的索引编号;
(3)对于每组随机采样序列,基于索引编号对应的匹配对得到候选基础矩阵或候选单应矩阵和相应的内点数量,利用gpu并行得到m*n个候选基础矩阵或m*n个候选单应矩阵和相应的m*n个内点数;
(4)在属于同一个图像对的n个候选基础矩阵或n个候选单应矩阵中获取内点数最大的矩阵为初始基础矩阵或初始单应矩阵,则m*n个候选基础矩阵中得到m个初始基础矩阵,m*n个候选单应矩阵中得到m个初始单应矩阵,对m个初始基础矩阵或m个初始单应矩阵进行优化得到最终的基础矩阵或最终的单应矩阵。
实施例1
如图2所示,一种基于gpu并行加速的基础矩阵估计方法,包括:
(1)对多个图像,提取每个图像的特征点,基于特征点利用匹配算法得到每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息,定义图像对匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号,以便于查找;
(2)由于显存容量的限制,每次只从具有匹配关系的所有图像对中选取m个图像对进行并行计算,对于m个图像对并行产生m*2048(此时n=2048)组随机采样序列,每组随机采样序列包含8(此时c=8)个随机数,每个随机数为相应图像对匹配列表中匹配对的索引编号;
(3)对于每组随机采样序列,基于索引编号对应的匹配对利用归一化八点法得到候选基础矩阵,并计算候选基础矩阵相应的内点数,最终得到m*2048个候选基础矩阵和m*2048个相应的内点数量;
(4)在属于同一个图像对的2048个候选基础矩阵中获取内点数最大的矩阵为初始基础矩阵,则在这m*2048个候选基础矩阵中可以获取m个初始基础矩阵,对这m个初始基础矩阵进行优化得到图像对最终的基础矩阵。
进一步的,如图3所示,步骤(1)还包括:
(1-1)对多个图像,利用sift算法提取每个图像的特征点;
(1-2)基于特征点利用hash匹配算法构建图像对之间特征点的对应关系,生成每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息;
(1-3)具有匹配关系的图像对存储时会按照一定的顺序排列,排列规则为先对图像对中的左边图像进行升序排列,若左边图像序号相同,则对图像对中的右边图像进行升序排列;
(1-4)按照图像对的排列顺序依次将每个图像对匹配列表中特征点位置信息存储为一维数组,图像对匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对的匹配列表中匹配对数量构建索引,得到索引编号。
进一步的,步骤(1-4)的具体实现方式为:
以单个图像对(i,j)为例,其匹配列表mij中的每一个元素都表示一个匹配对(如元素(p,k),表示图像i中的第p个特征点与图像j中的第k个特征点相互匹配),此时,在建立的一维数组l和r中,按照匹配列表中元素的排列顺序将左边图像(即图像i)和右边图像(即图像j)的特征点位置分别存入数组l和r,当所有图像对的匹配列表按此方式都依次存储到l和r中后,再根据每个图像对的特征点匹配对数量构建索引,得到索引编号,以便于查找。
进一步的,步骤(2)还包括:
(2-1)因为计算机显存容量的限制,在大规模的图像匹配数据中所有图像对的并行计算可能不能一次性完成,在此可以根据显存的大小每次选取m个图像对进行并行计算,在每个图像对的匹配列表中采集8*2048个匹配对,8为利用归一化八点法计算基础矩阵时需要的匹配对数量,2048为此时随机采样一致性算法(ransac)的最大迭代次数,利用线性同余算法并行地产生m*2048组随机采样序列,每组随机采样序列包含8个随机数。具体的实现方法是在gpu上分配m*2048个线程,每个线程以线程id为起点利用线性同余算法产生一组随机采样序列,则m*2048个线程共产生m*2048组随机采样序列,每组随机采样序列包含8个随机数,每个随机数为相应图像对匹配列表中匹配对的索引编号,属于同一组随机采样序列的8个随机数均不相同。
(2-2)将所有的随机采样序列按照图像对的排列顺序线性存储。
进一步的,步骤(3)包括:
(3-1)在gpu中分配m*2048个线程,每个线程获取一组随机采样序列基于索引编号对应的匹配对;
(3-2)根据m*2048组随机序列对应的匹配对,并行地利用归一化八点法计算得到m*2048个候选基础矩阵,其中每2048个候选基础矩阵对应于同一个图像对;
(3-3)遍历候选基础矩阵所对应图像对的匹配列表,并行地计算图像对匹配列表中匹配对的对称对极点距离,并将对称对极点距离与预先设定的阈值比较后得到每个候选基础矩阵的内点数量,最终得到m*2048个候选基础矩阵和相应的m*2048个内点数量。
进一步的,所述步骤(4)包括:
(4-1)根据步骤(3)每个图像对得到2048个候选基础矩阵及对应的2048个内点数量,在属于同一个图像对的2048个候选基础矩阵中获取内点数量最大的矩阵为初始基础矩阵;
(4-2)m*2048个候选基础矩阵中可以获取m个初始基础矩阵,这m个初始基础矩阵与m个图像对一一对应,在gpu上通过计算匹配对对称对极点距离的方法并行地获取这m个初始基础矩阵的内点;
(4-3)在各自内点上利用cminpack库中的lmdif非线性最小二乘法对这m个初始基础矩阵进行并行优化,得到图像对最终的基础矩阵。
如图4所示,一种基于gpu并行加速的单应矩阵估计方法,包括:
(1)对多个图像,提取每个图像的特征点,基于特征点利用匹配算法得到每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息,定义图像对匹配列表中相互匹配的1对特征点为匹配对,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号,以便于查找;
(2)由于显存容量的限制,每次只从具有匹配关系的所有图像对中选取m个图像对进行并行计算,对于m个图像对并行产生m*256(此时n=256)组随机采样序列,每组随机采样序列包含4(此时c=4)个随机数,每个随机数为相应图像对中匹配对的索引编号;
(3)对于每组随机采样序列,基于索引编号对应的匹配对利用双视图几何中平面的单应性(即hx=x′,
(4)在属于同一个图像对的256个候选单应矩阵中获取内点数量最大的候选矩阵为初始单应矩阵,这样,从m*256个候选矩阵中可以获取m个初始单应矩阵,对这m个初始单应矩阵进行优化得到图像对最终的单应矩阵。
进一步的,步骤(1)还包括:
(1-1)对多个图像,利用sift算法提取每个图像的特征点;
(1-2)基于特征点利用hash匹配算法构建图像对之间特征点的对应关系,生成每个图像对的匹配列表,匹配列表包含图像对之间特征点的匹配信息;
(1-3)具有匹配关系的图像对存储时会按照一定的顺序排列,排列规则为先对图像对中的左边图像进行升序排列,若左边图像序号相同,则对图像对中的右边图像进行升序排列;
(1-4)按照图像对的排列顺序依次将每个图像对匹配列表中特征点位置信息存储为一维数组,根据每个图像对匹配列表中匹配对数量构建索引,得到索引编号。
进一步的,步骤(1-4)的具体实现方式为:
以单个图像对(i,j)为例,其匹配列表mij中的每一个元素都表示一个匹配对(如元素(p,k),表示图像i中的第p个特征点与图像j中的第k个特征点相互匹配),此时,在建立的一维数组l和r中,按照匹配列表中元素的排列顺序将左边图像(即图像i)和右边图像(即图像j)的特征点位置分别存入数组l和r,当所有图像对的匹配列表按此方式都依次存储到l和r中后,再根据每个图像对匹配列表中特征点匹配对数量构建索引,得到索引编号,以便于查找。
进一步的,步骤(2)还包括:
(2-1)因为计算机显存容量的限制,在大规模的图像匹配数据中所有图像对的并行计算可能不能一次性完成,在此可以根据显存的大小每次从图像对列表中选取m个图像对进行并行计算,在每个图像对中采集4*256个匹配对,4为利用双视图几何中平面的单应性计算单应矩阵时需要的匹配对数量,256为此时随机采样一致性算法(ransac)的最大迭代次数,利用线性同余算法并行地产生m*256组随机采样序列,每组随机采样序列包含4个随机数。具体的实现方法是在gpu上分配m*256个线程,每个线程以线程id为起点利用线性同余算法产生一组随机采样序列,则m*256个线程共产生m*256组随机采样序列,每组随机采样序列包含4个随机数,每个随机数为相应图像对中匹配对的索引编号,属于同一组随机采样序列的4个随机数均不相同。
(2-2)将所有的随机采样序列按照图像对的排列顺序线性存储。
进一步的,步骤(3)包括:
(3-1)在gpu中分配m*256个线程,每个线程获取一组随机采样序列基于索引编号对应的匹配对;
(3-2)根据m*256组随机序列对应的匹配对,并行地利用双视图几何中平面的单应性得到m*256个候选单应矩阵,其中每256个候选单应矩阵对应于同一个图像对;
(3-3)遍历候选单应矩阵所对应图像对的匹配列表,并行地计算图像对匹配列表中匹配对的投影误差,并将投影误差与预先设定的阈值比较后得到每个候选单应矩阵的内点数量,最终得到m*256个候选单应矩阵和m*256个相应的内点数量。
进一步的,如图5所示,所述步骤(4)包括:
(4-1)根据步骤(3)每个图像对得到256个候选单应矩阵及对应的256个内点数,在属于同一个图像对的256个矩阵模型中获取内点数最大的候选单应矩阵为初始单应矩阵;
(4-2)从m*256个候选单应矩阵中可以获取m个初始单应矩阵,这m个初始单应矩阵与m个图像对一一对应,在gpu上通过计算投影误差的方法并行地获取这m个初始单应矩阵的内点;
(4-3)先在各自内点上利用cminpack库中的dgelsy线性最小二乘法优化多个图像对的初始单应矩阵,得到优化单应矩阵;
(4-4)然后在各自内点上利用cminpack库中的lmdif非线性最小二乘法对多个图像对的优化单应矩阵进行并行优化,得到每个图像对最终的单应矩阵。
本发明涉及到sift特征点提取算法、hash匹配算法、线性同余算法、ransac算法、归一化八点法、线性最小二乘法dgelsy和非线性最小二乘法lmdif,在计算基础矩阵和单应矩阵的过程中根据gpu的并行计算特点,转换匹配数据的存储结构,并对计算流程加以优化,其中包括用并行地计算多个随机采样序列所对应的矩阵来替代经典的ransac算法中多次随机采样计算矩阵、对基础矩阵和单应矩阵计算以及非线性最小二乘优化三个过程进行并行加速,最终达到大幅度减少基础矩阵和单应矩阵计算时间的目的。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!