标签生成方法、装置、服务器和计算机可读存储介质与流程
本发明涉及数据分析技术领域,具体而言,涉及一种标签生成方法、一种标签生成装置、一种服务器和一种计算机可读存储介质。
背景技术:
相关技术中,标签系统是基于规则和人工的方式建立包括软标签和硬标签,其中,硬标签为人工上传的固定标签,需要耗费大量人力成本,另外,软标签也存在诸多技术缺陷:
(1)软标签给出了一些灵活的规则信息,作为目标数据的标签,但是,由于目标数据的属性是随时间变化的,因此,软标签无法对目标数据进行持久化地抓取分析;
(2)如果软标签时刻都在发生动态变化,因此,软标签需要对目标数据进行实时的快照采集,因此导致了大量的数据压力。
技术实现要素:
本发明旨在至少解决现有技术或相关技术中存在的技术问题之一。
为此,本发明的一个目的在于提供一种标签生成方法。
本发明的另一个目的在于提供一种标签生成装置。
本发明的另一个目的在于提供一种服务器。
本发明的另一个目的在于提供一种计算机可读存储介质。
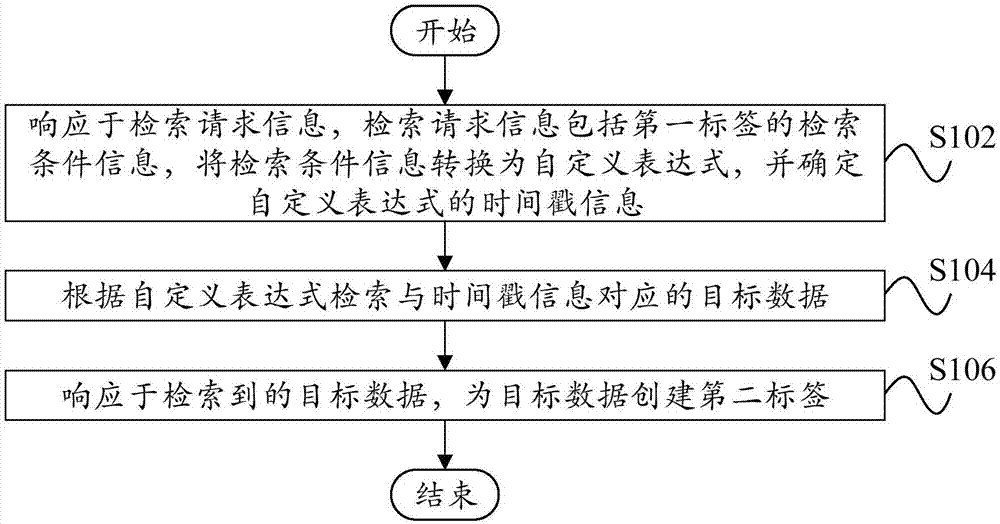
为了实现上述目的,本发明的第一方面的技术方案,提供了一种标签生成方法包括:响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;根据自定义表达式检索与时间戳信息对应的目标数据;响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,响应于检索请求信息时将检索条件信息转换为自定义表达式,可以通过json语言实现上述转换操作,进一步地,确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述技术方案中,优选地,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,具体还包括:在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,根据自定义表达式检索与时间戳信息对应的目标数据,具体包括:加载导出快照任务至存储有目标数据的数据库;触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,响应于检索到的目标数据,并为目标数据创建第二标签,具体包括:响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,标签生成方法还包括:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
本发明的第二方面的技术方案,还提出了一种标签生成装置,标签生成装置包括:响应单元,用于响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;检索单元,用于根据自定义表达式检索与时间戳信息对应的目标数据;创建单元,用于响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,通过响应于检索请求信息时将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述任一项技术方案中,优选地,标签生成装置还包括:解析单元,用于在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建单元还用于:创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,标签生成装置还包括:加载单元,用于加载导出快照任务至存储有目标数据的数据库;触发单元,用于触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,标签生成装置还包括:写入单元,用于响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;上传单元,用于将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;创建单元还用于:为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,写入单元还用于:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
本发明的第三方面的技术方案提出了一种服务器,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器用于执行存储器中存储的计算机程序时实现上述任一项标签生成方法的步骤。
在该技术方案中,服务器包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器用于执行存储器中存储的计算机程序时实现如本发明的第一方面的任一项标签生成方法的步骤,因此具有如本发明的第一方面的任一项标签生成方法的全部有益效果,在此不再赘述。
根据本发明的第四方面的实施例,还提出了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述任一项标签生成方法的步骤。
在该技术方案中,计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现如本发明的第一方面的任一项标签生成方法的步骤,因此具有如本发明的第一方面的任一项标签生成方法的全部有益效果,在此不再赘述。
本发明的附加方面和优点将在下面的描述部分中给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了根据本发明的一个实施例的标签生成方法的示意流程图;
图2示出了根据本发明的一个实施例的标签生成装置的示意框图;
图3示出了根据本发明的一个实施例的服务器的示意框图;
图4示出了根据本发明的另一个实施例的标签生成方法的示意流程图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例1:
图1示出了根据本发明的一个实施例的标签生成方法的示意流程图。
如图1示出了根据本发明的一个实施例的标签生成方法,包括:步骤s102,响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;步骤s104,根据自定义表达式检索与时间戳信息对应的目标数据;步骤s106,响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,响应于检索请求信息时将检索条件信息转换为自定义表达式,可以通过json语言实现上述转换操作,进一步地,确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述技术方案中,优选地,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,具体还包括:在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,根据自定义表达式检索与时间戳信息对应的目标数据,具体包括:加载导出快照任务至存储有目标数据的数据库;触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,响应于检索到的目标数据,并为目标数据创建第二标签,具体包括:响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,标签生成方法还包括:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
图2示出了根据本发明的一个实施例的标签生成装置的示意框图。
如图2示出了根据本发明的一个实施例的标签生成装置200,包括:响应单元202,用于响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;检索单元204,用于根据自定义表达式检索与时间戳信息对应的目标数据;创建单元206,用于响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,通过响应于检索请求信息时将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述任一项技术方案中,优选地,标签生成装置200还包括:解析单元208,用于在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建单元206还用于:创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,标签生成装置200还包括:加载单元210,用于加载导出快照任务至存储有目标数据的数据库;触发单元212,用于触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,标签生成装置200还包括:写入单元214,用于响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;上传单元216,用于将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;创建单元206还用于:为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,写入单元214还用于:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
图3示出了根据本发明的一个实施例的服务器的示意框图。
如图3示出了根据本发明的一个实施例的服务器300,包括存储器302、处理器304及存储在存储器302上并可在处理器304上运行的计算机程序,处理器304用于执行存储器302中存储的计算机程序时实现如本发明的第一方面的任一项标签生成方法的步骤。
在该技术方案中,服务器300包括存储器302、处理器304及存储在存储器302上并可在处理器304上运行的计算机程序,处理器304用于执行步骤包括:响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;根据自定义表达式检索与时间戳信息对应的目标数据;响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,响应于检索请求信息时将检索条件信息转换为自定义表达式,可以通过json语言实现上述转换操作,进一步地,确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述技术方案中,优选地,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,具体还包括:在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,根据自定义表达式检索与时间戳信息对应的目标数据,具体包括:加载导出快照任务至存储有目标数据的数据库;触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,响应于检索到的目标数据,并为目标数据创建第二标签,具体包括:响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,标签生成方法还包括:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
本发明的实施例还提出了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:响应于检索请求信息,检索请求信息包括第一标签的检索条件信息,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息;根据自定义表达式检索与时间戳信息对应的目标数据;响应于检索到的目标数据,为目标数据创建第二标签,其中,第二标签与自定义表达式相对应。
在该技术方案中,响应于检索请求信息时将检索条件信息转换为自定义表达式,可以通过json语言实现上述转换操作,进一步地,确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
具体地,即根据第一标签包含的检索条件信息将第一标签转换成自定义表达式,自定义表达式是指elasticsearch支持的dsl(domain-specificlanguage,自定义语言)表达式,常见的dsl语言包括html(hypertextmarkuplanguage,超文本标记语言)语言,shell语言,make语言,ant语言,maven语言,rpm语言,dpkg语言,awk语言,正则表达式语言,dc计算机语言等,有些dsl语言又被称为微型语言,也即利用elasticsearch快速检索能力,快速导出满足检索条件信息的目标数据。
其中,elasticsearch为基于lucene的搜索服务器,分布式存储文件为hadoop分布式文件系统(hdfs,hadoopdistributedfilessystem),提供高吞吐量的数据访问,具有高度容错性,具体地,如在hdfs中创建一个新的文件用于存储目标数据,则文件的名字节点将会在editlog中插入一条记录来记录这个改变,而hdfs可以将目标数据导出至第三方服务器或第三方终端进行数据分析。
值得特别指出的是,为了缓解频繁生成快照导致的数据压力,可以设置仅仅在响应于检索请求信息时开始执行上述步骤,本申请的第一标签可以理解为现有技术中的软标签,第二标签可以理解为现有技术中的硬标签。
在上述技术方案中,优选地,将检索条件信息转换为自定义表达式,并确定自定义表达式的时间戳信息,具体还包括:在将检索条件信息转换为自定义表达式后,解析自定义表达式对应的索引信息;创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式。
在该技术方案中,通过创建导出快照任务,导出快照任务的检索导出条件包括索引信息、时间戳信息和自定义表达式,时间戳信息能唯一地表示自定义表达式对应的时间节点,索引信息用于将目标数据上传至分布式文件系统,自定义表达式对应于规则信息。
在上述任一项技术方案中,优选地,根据自定义表达式检索与时间戳信息对应的目标数据,具体包括:加载导出快照任务至存储有目标数据的数据库;触发数据库的异步线程执行导出快照任务,以确定与检索导出条件对应的目标数据。
在该技术方案中,通过加载导出快照任务至存储有目标数据的数据库,触发数据库的异步线程执行导出快照任务,其实质是在数据库中持久化上述导出快照任务,另外,通过异步线程执行导出快照任务,节省了运行时间和空间。
在上述任一项技术方案中,优选地,响应于检索到的目标数据,并为目标数据创建第二标签,具体包括:响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息,命名信息包括索引信息与时间戳信息;将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统;为存储于分布式存储系统的导出文件的目标数据创建第二标签。
在该技术方案中,通过响应于检索到的目标数据,对目标数据所属的导出文件写入命名信息(即上述名字节点),通过将具有命名信息的导出文件按照索引信息上传存储至分布式存储系统,为存储于分布式存储系统的导出文件的目标数据创建第二标签,通过名字节点检测目标数据是否发生变化,在检测到存储的目标数据发生变化后,触发执行导出快照任务对目标数据的更新信息进行跟踪分析。
在上述任一项技术方案中,优选地,标签生成方法还包括:写入第二标签的标签属性信息为固定的只读标签。
在该技术方案中,通过写入第二标签的标签属性信息为固定的只读标签,将灵活可变的第一标签已转换成固定只读第二标签,即将通过软标签检索的目标数据的标签定义为硬标签,再交由第三方(如:apollo执行系统)服务器来做数据分析,同时提供了用户订阅数据分析结果的功能。
实施例2:
图4示出了根据本发明的另一个实施例的标签生成方法的示意流程图。
如图4示出了根据本发明的另一个实施例的标签生成方法,包括:步骤s402,客户对软标签触发生成快照动作;步骤s404,根据检索条件信息生成elasticsearch支持的dsl表达式并异步提交到elasticsearch集群;步骤s406,elasticsearch检索目标数据并导出目标数据;步骤s408,将目标数据上传存储至hdfs,并在标签系统中创建一个新的硬标签。
以上结合附图详细说明了本发明的技术方案,本发明提出了一种标签生成方法、装置、服务器和计算机可读存储介质,响应于检索请求信息时将检索条件信息转换为自定义表达式,可以通过json语言实现上述转换操作,进一步地,确定自定义表达式的时间戳信息,根据自定义表达式检索与时间戳信息对应的目标数据,响应于检索到的目标数据,为目标数据创建第二标签,在利用软标签更准确地检索到目标数据的同时,解决了软标签不能进行目标数据进行持久化分析的问题,降低了快照导致的数据压力,提升了用户的使用体验。
本发明方法中的步骤可根据实际需要进行顺序调整、合并和删减。
本发明装置中的单元可根据实际需要进行合并、划分和删减。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(read-onlymemory,rom)、随机存储器(randomaccessmemory,ram)、可编程只读存储器(programmableread-onlymemory,prom)、可擦除可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、一次可编程只读存储器(one-timeprogrammableread-onlymemory,otprom)、电子抹除式可复写只读存储器(electrically-erasableprogrammableread-onlymemory,eeprom)、只读光盘(compactdiscread-onlymemory,cd-rom)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!