一种基于数据信息互通的微型服务系统及其实现方法与流程
本发明涉及数据信息通信领域,尤其涉及一种基于数据信息互通的微型服务系统及其实现方法。
背景技术:
传统的应用系统,都是由系统开始,到数据结束,在大数据和云计算的模式下,数据将不再是问题,问题是在于,应用如何利用这些数据,传统的应用系统,只会产生数据,不能将数据的价值发挥的极致。虽然某些特别的软件或者工具在部分特定情况下可以完成类似这种数据定义软系统的这项工作,但是其带来的工作是繁琐复杂的,并且工作量巨大,同时人员的精力与时间的消耗也是相当巨大的。传统的数据融合,只是简单的将数据保存在一个地方,但是无法将数据进行横向、纵向的关联,对于异构数据,更是无法做到有效的整合。
技术实现要素:
有鉴于此,本发明的目的在于克服现有技术的不足,提供一种基于数据信息互通的微型服务系统及其实现方法。
为实现上述目的,本发明采用以下技术方案:
一种基于数据信息互通的微型服务系统,包括
数据融合端(datafusionserver,简称d-fusion),用于通过开放的api接口从源端服务器抽取数据,并对抽取的数据进行标准化处理,形成标准化数据;
数据互通端(datainterflowserver,简称d-interflow),用于同步所述标准化数据,并对所述标准化数据实现数据的打散与重组,得到重组数据;并通过唯一的标识来确认所述重组数据位置与信息,得到标识数据;
微型应用端(micappsserver,简称mapp),用于获取所述标识数据,并作为所述标识数据的应用端。
优选的,所述数据融合端上内置有基于开放数据库连接(opendatabaseconnectivity,简称odbc)的融合数据库,作为cigql;所述cigql用于将异构数据以及数据文件库融合,并以新的方式呈现数据。
进一步优选的,所述cigql支持多种操作系统的模块;操作系统的模块包括linux操作系统模块,ibm小型机aix系统,虚拟层模块如vmwareesx模块,hyper-v模块和xenserver模块。
进一步优选的,所述cigql支持多种云端操作操作系统,包含微软云microsoftazure、亚马逊云aws和阿里云。
进一步优选的,所述cigql支持多种数据库系统的模块,包含oracle模块,ms-sql模块和postgresql模块。
进一步优选的,所述cigql支持对crm,erp业务系统的模块,支持大数据的dfs/hdfs,nosql模块。
一种基于数据信息互通的微型服务的方法,包括如下步骤:
s1,通过ip地址和数据源端服务器的授权用户账号,连接所述数据源端服务器,在验证通过后,根据所述数据源端服务器中的数据结构,匹配数据模块并对所述数据源端服务器中的源端数据进行抽取,抽取后的数据作为抽取数据;
s2,将所述抽取数据写至本地缓存/内存;按照缓存fifo(firstinputfirstoutput的缩写,先入先出队列,一种传统的按序执行方法)方式,将处于缓存/内存底端字节存储的数据移至本地;
s3,抽取后的数据在本地缓存/内存中按照cigql的标准进行数据标准化转换,形成cigql专有的、通用的数据结构数据文件,作为hash数据,并将所述hash数据,根据情况(按照数据主题)存放在本地数据库中,并同步到数据互通端中;
s4,在数据互通端中,将缓存中接收到的数据按照fifo方式写入后端外置存储中以供数据交互使用;
s5,微型应用端通过所述后端外置存储实现数据的交互使用。
优选的,cigql的标准进行数据标准化转换的方法包括如下步骤:
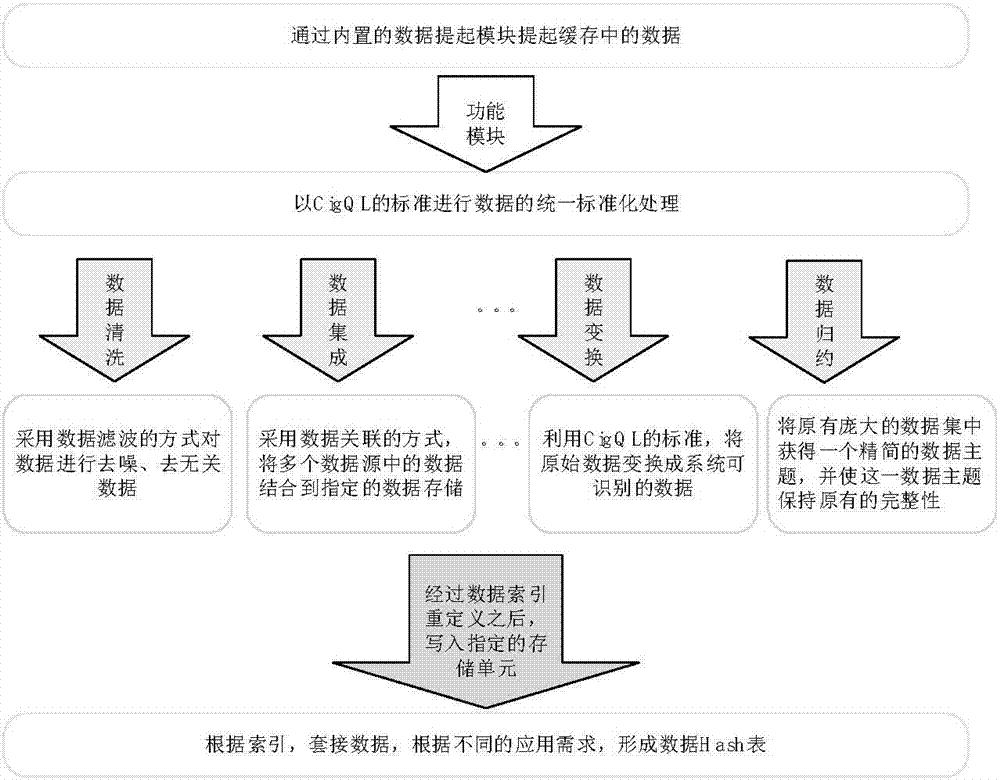
s31,将抽取后的数据采用数据滤波的方式对数据进行去噪,筛掉无关数据,形成过滤数据;
s32,将所述过滤数据采用数据关联的方式结合到预设的数据存储(1)中,作为关联数据;
s33,将所述关联数据按照预设数据标准,变换为可识别数据;
s34,为所述可识别数据建立数据主题索引,作为索引数据;
s35,将所述索引数据存储到预设的数据存储(2)中,作为标准数据;
s36,将多个所述标准数据进行组合,生成hash表。
进一步优选的,在数据互通端中,将缓存中接收到的数据按照fifo方式写入后端外置存储中以供数据交互使用时还根据数据属性,按照不同的主题对数据进行分类处理,具分类处理的方法为:
s41,根据数据字段的相关性,将有强相关的数据作为一级分类,弱相关的作为二级分类,存放到指定位置,并生成所述hash表;所述hash表包含数据字段名称代码、位置代码、大类别代码、小类别代码或事件代码中的一种以上的属性;
s42,通过s41中的属性的数据字段构建与hash表关联的索引,作为dataindex;
s43,微型应用端通过所述dataindex和hash表实现数据应用。
优选的,所述数据互通端完成同步数据后,还对同步数据进行是否为首次同步判断;
s43.1,若为首次同步,则将首次同步数据进行打散数据、构建数据主题、构建关联属性和构建数据关联表;
s43.2,若非首次同步,则将非首次同步数据进行打散数据,判断数据属性并将判断完属性的数据追加数据关联表中。
优选的,微型应用端通过所述dataindex和hash表实现数据应用的方法具体为:
s51,当所述数据互通端接到所述微型应用端数据请求时,所述数据互通端根据所述微型应用端数据请求给予所述微型应用端发送所述数据请求对应的数据;
s52,所述微型应用端接收并确认所述数据请求对应的数据后,所述数据互通端通过索引及hash表构建新的数据文件;
s53,所述数据互通端将新的数据文件反馈给所述微型应用端,并存储到预设的存储位置。
进一步优选的,所述数据请求包括数据查询请求和数据读写请求;
s51.1,当所述数据请求是数据查询请求时,所述数据互通端根据数据查询请求生成新的数据文件,存放到预设的dataquery区;
s51.2,当所述数据请求是数据读写请求时,所述数据互通端根据数据读写请求生成新的数据文件,存放到预设的dataswitch区;
s53,所述数据互通端在处理所述微型应用端的数据请求时,按照fifo的方式,将数据写入预设的datastorage中,在数据互通端中,使用ssd或者分布式部署。
本发明具有的优点和积极效果是:由于采用上述技术方案,本申请具有如下特点:
本发明解决了大数据时代下,数据繁琐复杂、难于交互、的问题;
本发明采用直连或者网络连接的方式,连接本地和网络中的数据,经过标准格式转化模块,将数据转化成统一国际标准格式后,进行数据关联性操作。
本发明解决异构数据的之间关联问题的同时,为新型应用构建了良好的数据基础。
本发明是逆向行为,以数据为基础,反向推演应用系统。本发明以数据为基础,实现综合的应用系统。
由于数据异构性特点本质,本发明,将非标准化格式的数据转换成统一规范的数据,能够轻松简单的解决大数据环境下的异构数据汇聚融合以及新型应用设计的难题。
附图说明
图1为本发明的数据融合端数据融合汇聚流程示意图;
图2为本发明的数据格式标准化转换原理示意图;
图3为本发明的数据融合端与数据互通端数据融合汇聚同步工作原理示意图;
图4为本发明的数据互通端与微型应用端的数据构建工作原理示意图;
图5为本发明的基于数据信息互通的微型服务系统工作原理示意图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本发明是一项基于数据的信息互通、微型应用设计的技术。本发明解决了大数据时代下,数据繁琐复杂、难于交互、的问题,传统的数据融合,只是简单的将数据保存在一个地方,但是无法将数据进行横向、纵向的关联,对于异构数据,更是无法做到有效的整合。本发明采用直连或者网络连接的方式,连接本地和网络中的数据,经过标准格式转化模块,将数据转化成统一国际标准格式后,进行数据关联性操作。
本发明的另外一个特点是,通过本技术规范手段可以轻松解决异构数据的之间关联问题的同时,为新型应用构建了良好的数据基础。传统的应用系统,都是由系统开始,到数据结束,本发明的特点,是逆向行为,以数据为基础,反向推演应用系统。换句话说,以数据为基础,实现综合的应用系统。在大数据和云计算的模式下,数据将不再是问题,问题是在于,应用如何利用这些数据,传统的应用系统,只会产生数据,不能将数据的价值发挥的极致。虽然某些特别的软件或者工具在部分特定情况下可以完成类似这种数据定义软系统的这项分析工作,但是其带来的工作是繁琐复杂的,并且工作量巨大,同时人员的精力与时间的消耗也是相当巨大的。由于数据异构性特点本质,本技术,将非标准化格式的数据转换成统一规范的数据,能够轻松简单的解决大数据环境下的异构数据汇聚融合以及新型应用设计的难题。
传统的应用系统都是一个独立的系统,每个应用系统基本上都是跨系统时,会出现数据与应用不匹配的问题,但是就单一系统而言,逻辑又是非常清晰。然而,如果要跨系统获得数据结论,这将可能需要大费周章的去梳理与整合数据。
如图1所示,本发明数据融合汇聚部分通过现有开放的api接口技术从源端服务器抽取数据(此过程中数据不加密,不压缩)。通过加密通道将抽取过来的数据传输至d-fusion,由d-fusion对数据进行标准化处理。
d-fusion利用开放的api接口(odbc),通过ip或者光纤网络与datasourcesserver相连;d-fusion内置基于odbc的融合数据库cigql,将绝大多数异构数据以及数据文件库能够融合在一起,并以新的方式呈现数据。支持各类操作系统的模块,包含微软操作系统客户端模块,linux操作系统模块,ibm小型机aix系统,虚拟层模块如vmwareesx模块,hyper-v模块,xenserver模块;支持各类云端操作操作系统,包含微软云microsoftazure、亚马逊云aws、阿里云等;各类数据库系统的模块,包含oracle模块,ms-sql模块,postgresql模块等;以及对sap等crm,erp业务系统的模块,和针对大数据的dfs/hdfs,nosql模块等。
d-fusion将通过ip地址和源端服务器的授权用户账号,连接源端服务器,在验证通过后,根据源端的数据结构,启动相对应的功能模块对源端数据进行抽取。按照cigql的标准将数据进行统一规范化处理,并写入datastorage中,同时将统一标准后的数据同步至d-interflow。
如图2所示,d-fusion数据融合汇聚的流程示意,datasources接收到d-fusion的数据融合汇聚请求后,在datasources的缓存中整理数据,并对d-fusion开放权限,供其执行操作。整个过程对数据不加密、不压缩。在融合和汇聚数据的同时,会在数据上做标识,来区分该数据是否已经被抽取,并在d-fusion的数据库cigql中添加索引。由于源端数据的结构存在不同,故d-fusion发出融合汇聚指令也不相同,利用的采集融合的模块也不相同。
d-fusion将所抽取的源端数据写至本地缓存或内存,按照缓存fifo方式,将处于缓存/内存底端字节存储的数据移至本地。该磁盘将包含ssd,sas,sata等标准。
抽取后的数据在d-fusion的cache中按照cigql的标准进行数据标准化转换,形成cigql专有的、通用的数据结构数据文件,并将该数据文件根据情况(按照数据主题)存放在本地datastorage中,并同步到d-interflo。
如图3、图4所示,d-fusion数据格式标准化转换的工作原理,d-interflow将缓存中接收到的数据按照fifo方式写入后端外置存储(datastorage)以供数据交互使用。支持绝大多数的主流存储。
以上的过程是d-fusion对源端数据反向抽取以及对数据进行标准换处理,并同步至d-interflow的实现方式。整个过程中,每次抽取,传输对数据均不加密,不压缩。但是,数据是在一个加密的通道中进行传输的。所以,在数据安全性上有绝对的保障。
如图5所示,数据信息互通时,数据信息互通既可以通过d-fusion来实现,也可以通过d-interflow来实现。由于整个发明中,d-fusion的资源主要用于数据融合与汇聚,如果互通也交于d-fusion的话,资源消耗的很严重,同时d-interflow需要为后端的mapp提供数据服务。所以,在本发明中,数据信息互通交于d-interflow来实现。
数据完成同步后,d-interflow对数据做进一步的处理,实现数据的打散与重组,并通过唯一的标识来确认数据位置与信息。
d-interflow根据数据属性,按照不同的主题对数据进行分类处理;
根据数据字段的相关性,将有强相关的数据作为一级分类,弱相关的作为二级分类,存放到指定位置,并生成相应的hash表。hash表至少包含数据字段名称代码、位置代码、大类别代码、小类别代码、事件代码等属性;
通过cigql的规则,固定属性的字段形成dataindex,dataindex能够与hash关联构建新的数据;
d-interflow向mapp开放dataindex以及hash,以便mapp调用。
数据信息互通的实现方式:
当d-fusion完成同步数据后,d-interflow对数据按照统一流程进行处理(首次同步需要这么做),主要有打散数据、构建数据主题、构建关联属性、构建数据关联表这几个流程,在非首次同步时,则流程相对简化:打散数据,判断数据属性、追加数据关联表
当接到后端mapp数据请求时,d-interflow首先判断mapp的数据请求是哪种级别的数据请求(数据查询请求、数据读写请求),发送dataindex以及hash,mapp确认数据请求后,通过不同的dataindex以及hash表进行构建新的数据文件,反馈给后端mapp,并存储到对应的存储位置。
当mapp发出的是数据查询请求时,d-interflow根据数据请求生成新的数据文件,存放到dataquery区;
当mapp发出的是数据读写请求时,d-interflow根据数据请求生成新的数据文件,存放到dataswitch区;
d-interflow在处理mapp的数据请求时,按照fifo的方式,将数据写入指定的datastorage中,在d-interflow中,本发明建议使用ssd,或者d-interflow采用分布式部署。
至此,数据信息互通的微型服务系统的构建已完成。
在整个的过程中,无论是抽取数据的过程,还是为应用生产新的数据文件的过程,都是建立在开放的api接口上,并且,d-fusion、d-interflow以及micappsserver至少要有以下功能:
索引管理器:负责从d-fusion、d-interflow更新索引信息。同时提供其他应用服务器所索要的索引信息。
共享访问接口:负责接管所有共享请求,实施授权监管,统一规范查验及其他访问规则实施。最后反馈所要的数据.
查询系统引擎:搜寻何处可取的所要的数据。根据请求和数据共享服务的整体构架,其请求可能会转发至其他数据分析服务器或中央集成服务器。
数据提起器:基于查询引擎的查询结果获得所需数据的信息源描述,解析出数据的逻辑路径,据此连接到相应的应用系统,通过api接口以获得相应原始数据。若有必要,最后提起所要数据片断。
数据转换器:所要数据提起完成后,如果其格式不是所要的,即将数据转换成通用的标准格式。
本发明解决了大数据时代下,数据繁琐复杂、难于交互、的问题;
本发明采用直连或者网络连接的方式,连接本地和网络中的数据,经过标准格式转化模块,将数据转化成统一国际标准格式后,进行数据关联性操作。
本发明解决异构数据的之间关联问题的同时,为新型应用构建了良好的数据基础。
本发明是逆向行为,以数据为基础,反向推演应用系统。本发明以数据为基础,实现综合的应用系统。
由于数据异构性特点本质,本发明,将非标准化格式的数据转换成统一规范的数据,能够轻松简单的解决大数据环境下的异构数据汇聚融合以及新型应用设计的难题。
本发明不局限于上述最佳实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是具有与本申请相同或相近似的技术方案,均落在本发明的保护范围之内。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!