通过动态地传送存储器范围分配的负载平衡的制作方法
本公开的实施例通常涉及数据储存。更具体地,本公开的方面涉及通过动态地传送范围分配来驱动负载平衡。
背景技术:
许多应用需要长期的数据储存并且典型地需要高度的数据完整性。典型地,这些需求由非易失性数据储存装置满足。非易失性储存器在不需要持续的电力供应的情况下储存数据。非易失性储存器或持久性的介质可以由各种装置提供,最常用地,由硬盘驱动器(HDD)和固态驱动器(SSD)提供。
HDD在旋转的可写磁盘表面上记录数据的磁性图案,然而SSD使用非易失性固态电子电路而没有使用可移动的机械零件储存数据。为了读取或写入信息至HDD或者SSD,软件应用或者操作系统可以指定数据的位置。通常,信息被储存在被称为区块的特定长度的位的集合中,其一次读取和写入全部的区块。通常,由操作系统的文件系统组件来抽象一次一区块的信息的储存,用于应用的使用,并且文件系统向储存装置指定要读取和写入哪个区块。
指定数据区块的一个常用的方案是逻辑区块地址(LBA),其使用线性地址空间,其中可寻址的储存空间作为单一的相邻地址空间出现。在LBA中,每个线性基底地址识别单一的区块并且这些基底地址可以传送至更低级别的系统、诸如驱动控制器中,其可以实现处理LBA到储存机制的物理映射的间接系统。
随着应用的复杂性和数量的增加,对于储存系统的需求也已经增加及演变。所需要的是用于在可用资源上分布该工作负载的技术,以便以可扩展和灵活的方式更好地管理工作负载。
因此,需要通过动态地传送范围分配的负载平衡的方法。
技术实现要素:
本公开通常涉及通过跨处理器动态地传送范围分配的负载平衡的方法。更具体地,通过将整个储存范围分割为更小的范围并且跨处理器分配这些更小的范围,诸如SSD的储存装置上的工作负载可以是跨多个处理器平衡的负载。寻址于特定范围的命令然后可以被指引至与特定范围相关联的专用处理器。在一些实施例中,范围可以在处理器之间借用,并且在一些实施例中,范围可以被重新分配至不同的处理器以帮助平衡跨处理器的负载。
本公开的某些方面提供用于通过动态地传送范围分配的负载平衡的方法。该方法通常包含从主机设备接收指向两个或更多储存地址处的存取请求,基于两个或更多储存地址中的第一储存地址分配存取请求至储存装置的两个或更多处理器中的第一处理器,基于第一储存地址获得本地存储器锁定,基于两个或更多储存地址中的第二储存地址确定第二储存地址被分配到两个或更多处理器中的第二处理器,基于第二储存地址从第二处理器获得远程存储器锁定,并且处理存取请求。
在一些实施例中,可以调整处理器分配。在这些实施例中,该方法还包括确定从用于分配储存地址至两个或更多处理器的第一算法改变为第二算法,发布变换阻挡命令至两个或更多处理器的每个处理器,从两个或更多处理器的每个处理器接收对于变换阻挡命令的响应,并且在从所有处理器接收响应后发布变换阻挡完成信息至每个处理器。
一个或多个示例的细节在附图和以下描述中阐述。其他特征、目的和优势将从描述和附图以及从权利要求书中显而易见。
附图说明
可以通过参考实施例对以上简短总结的本公开进行更特定的描述,使得能够详细地理解本公开的上述特征所采用的方式,其中一些实施例在附图中说明。然而,应当注意,附图仅说明了本公开的典型实施例,并且因为本公开可以允许其他等同有效的实施例,因此不应被视为限制其范围。
图1是根据本公开的方面说明示例储存环境的方框图,其中储存装置可以作为主机装置的储存装置运行。
图2是根据本公开的方面说明示例存储器装置的方框图。
图3是根据本公开的方面说明示例控制器的方框图。
图4是根据本发明的方面说明用于获得锁定的技术的示意流程图。
图5是根据本发明的方面说明用于调整处理器范围分配的技术的示意流程图。
图6A-6D是根据本发明的方面说明用于在调整处理器范围分配时获得锁定的技术的示意流程图。
图7是根据本发明的方面说明用于释放存储器锁定的技术的示意流程图。
图8A-8C是根据本公开的方面说明示例处理器范围调整操作的调用流程图800。
为了有助于理解,在可能的情况下,使用相同的附图标记来指定图中公共的相同元件。可以预期,在一个实施例中公开的元件可以有利地用于其它实施例,而无需指定说明。
具体实施方式
在下文中,参考本公开的实施例。然而,应当理解,本公开不限于指定描述的实施例。反而,考虑以下特征和元件的任何结合,无论是否与不同的实施例相关,以实现和实践本公开。此外,虽然本公开的实施例可以实现在其他可能的解决方案上和/或在现有技术上的优势,但是通过给定实施例是否实现特定优势不是对本公开的限制。因此,以下方面、特征、实施例和优势仅仅是说明性的,并且不被认为是所附权利要求的元素或限制,除非在权利要求中明确地叙述。同样地,涉及“公开”不应被解释为本文所公开的任何发明主题的概括,并且不应被认为是所附权利要求的要素或限制,除非在权利要求中明确地叙述。
本公开的某些方面提供用于通过动态地传送范围分配的负载平衡的方法。该方法通常包含从主机设备接收指向两个或更多储存地址处的存取请求,基于两个或更多储存地址中的第一储存地址分配存取请求至储存装置的两个或更多处理器中的第一处理器,基于第一储存地址获得本地存储器锁定,基于两个或更多储存地址中的第二储存地址确定第二储存地址被分配到两个或更多处理器中的第二处理器,基于第二储存地址从第二处理器获得远程存储器锁定,并且处理存取请求。
图1是根据本公开的一个或多个技术说明具有主机装置的储存装置102的示例计算环境100的概念上和示意性的方框图。例如,主机装置104可以利用包括在储存装置102中的非易失性存储器装置,以储存和检索数据。在一些示例中,计算环境100可以包括可以作为储存阵列操作的多个储存装置,诸如储存装置102。例如,计算环境100可以包括配置为便宜/独立磁盘的冗余式阵列(RAID)的多个储存装置102,该多个储存装置作为主机装置104的大容量储存装置共同运行。
计算环境100可以包含主机装置104,该主机装置可以储存和/或检索数据至诸如储存装置102的一个或多个储存装置,并且/或者从诸如储存装置102的一个或多个储存装置储存和/或检索数据。如图1所示,主机装置104可以包含在主机OS 110的上下文中执行控制代码108的一个或多个处理器106。主机OS 110可以产生用于一个或多个LBA地址的请求、诸如读取或写入请求、或者范围。该请求经由控制代码108传送至处理器106,其可以发布请求至储存装置102。在一些示例中,控制代码108可以是硬件驱动器。主机装置104可以经由接口112与储存装置102通信。主机装置104可以包括宽范围的装置中任一个,包含电脑服务器、网络附连储存(NAS)单元、台式电脑、笔记本电脑(即膝上型电脑)、平板电脑、机顶盒、诸如所谓的“智能”电话的电话手机、所谓的“智能”平板、电视机、照相机、显示装置、数字媒体播放器、视频游戏控制台、视频流装置等。主机装置104可以使用逻辑或虚拟地址、诸如LBA范围来识别储存在储存装置102中的数据。
如图1所示,储存装置104可以包含控制器114、非易失性存储器阵列116(NVMA 116)、电力供应118、易失性存储器120和接口112。在一些示例中,为了清楚起见,储存装置102可以包含图1中未示出的附加的组件。例如,储存装置102可以包含印刷板(PB),储存装置102的组件被机械地附连到该印刷板,并且该印刷板包含电互联储存装置102的组件等的导电迹线。在一些示例中,储存装置102的物理尺寸和连接器配置可以符合一个或多个标准形状因素。一些示例标准形状因素包含但不限于,3.5”硬盘驱动器(HDD)、2.5”HDD、1.8”HDD、外围组件互连(PCI)、PCI扩展(PCI-X)、PCI快车(PCI Express,PCIe)(例如,PCIe×1、×4、×8、×16、PCIe迷你卡、迷你PCI等)。在一些示例中,储存装置102可以直接耦合(例如,直接焊接)于主机装置104的母板。
储存装置102可以包含用于与主机装置104进行接口的接口112。接口112可以包含用于与主机装置104交换数据的一个或多个数据总线和用于与主机装置104交换命令的一个或多个控制总线。接口112可以根据任何适当的协议操作。例如,接口112可以根据以下协议的一个或多个操作:高级技术附件(ATA)(例如,串行ATA(SATA)和并行-ATA(PATA))、光纤通道、小型计算机系统接口(SCSI)、串行附连SCSI(SAS)、外围组件互连(PCI)和PCI-快车。接口112(例如,数据总线、控制总线或者两者)的电连接被电连接于控制器114,在主机装置104和控制器114之间提供电连接,允许数据在主机装置104和控制器114之间交换。在一些示例中,接口112的电连接也可以许可储存装置102从主机装置104接收电力。例如,如图1所示,电力供应118可以经由接口112从主机装置104接收电力。
储存装置102可以包含电力供应118,其可以向储存装置102的一个或多个组件提供电力。当以标准图案操作时,电力供应118可以使用由诸如主机装置104的外置装置提供的电力,向一个或多个组件提供电力。例如,电力供应118可以使用经由接口112从主机装置104接收的电力,向一个或多个组件提供电力。在一些示例中,电力供应118可以包含一个或多个电力储存组件,该一个或多个电力储存组件配置为当在停机图案时,诸如在停止从外置装置接收电力的情况下,向一个或多个组件提供电力。以这种方法,电力供应118可以作为机上备用电源运行。一个或多个电力储存组件的一些示例包含但不限于电容器、超级电容器、电池等。在一些示例中,由一个或多个电力储存组件所储存的电量可以是一个或多个电力储存组件的价格和/或大小(例如,面积/体积)的函数。换言之,随着一个或多个电力储存组件所储存的电量增加,一个或多个电力储存组件的价格和/或大小(例如,面积/体积)也增加。
储存装置102包含一个或多个控制器114,其可以包含一个或多个处理器130a-130n。在一些情况下,处理器130可以是多核处理器的核心。控制器114可以管理储存装置102的一个或多个操作。例如,控制器114可以管理从一个或多个存储器装置140读取数据和/或向一个或多个存储器装置140写入数据。如本文所通常使用的,即使处理器是指储存装置的控制器的处理器,即使在一些情况下,但是可以由诸如主机处理器的通用处理器进行本文所描述的技术,例如,执行控制代码。
储存装置102可以包含易失性存储器120,其可以由控制器114用于储存信息。在一些示例中,控制器114可以使用易失性存储器作为高速缓存。例如,控制器114可以储存在易失性存储器120中的高速缓存的信息,直到高速缓存的信息被写入到存储器装置140中。如图1所示,易失性存储器120可以消耗从电力供应118接收的电力。易失性存储器120的示例包含但不限于随机存取存储器(RAM)、动态随机存取存储器(DRAM)、静态RAM(SRAM)和同步动态RAM(SDRAM(例如,DDR1、DDR2、DDR3、DDR3L、LPDDR3、DDR4等)。在一些示例中,易失性存储器120可以在多个处理器之间分享,并且每个处理器可以使用易失性存储器120的离散部分。在其他示例中,每个处理器可以使用分别的易失性存储器。
在一些示例中,控制器114可以使用易失性存储器120以储存逻辑到物理(或虚拟到物理)的数据地址转换表。在一些实例中,逻辑到物理的数据地址转换表可以包含条目,这些条目包含逻辑数据地址和对应的物理数据地址。在一些示例中,逻辑到物理的数据地址转换表可以包含索引,该索引编码在逻辑到物理的数据地址转换表中的每个条目的相应的逻辑数据地址,而不是包含逻辑数据地址的逻辑到物理的数据地址转换表中的每个条目。在这些示例的一些中,逻辑到物理的数据地址转换表可以不储存具有在逻辑到物理的数据地址转换表中的相应的条目的索引值(或逻辑数据地址)。主机装置104可以是指使用逻辑数据地址的数据的单元,并且控制器114可以利用物理数据地址以指引向存储器装置140写入数据和从存储器装置140读取数据。
根据本公开的一个或多个技术,控制器114可以合并多个逻辑数据地址为逻辑数据地址容器。对于逻辑数据地址容器中的逻辑数据地址的一个,控制器114可以完全指定对应于逻辑数据地址的物理数据地址。通过完全指定物理数据地址,控制器114可以指定所有位置属性,这样使得物理数据地址指向存储器装置140的精确位置(例如,存储器装置140中的精确的一个存储器装置、精确区块(block)202、精确页204等)。对于逻辑数据地址容器中的逻辑数据地址的剩余部分,控制器114可以部分指定对应于每个逻辑数据地址的相应的物理数据地址。部分指定物理数据地址可以包含比完全指定的物理数据地址更少的信息。通过部分指定相应的物理数据地址,控制器114可以指定充分的地址信息,使得与一个逻辑数据地址的完全指定的物理数据地址相结合地,完全指定相应的物理数据地址。然而,单独地部分指定物理数据地址不可以充分指向存储器装置140的精确位置。
以这种方法,通过减少逻辑到物理的数据地址转换表中的条目的至少一些所需要的位的数量,可以减少由逻辑到物理的数据地址转换表所消耗的存储器。如上所述,在一些示例中,控制器114可以使得逻辑到物理的数据地址转换表被储存在易失性存储器120中。通过减少由逻辑到物理的数据地址转换表消耗的存储器,储存装置102可以包含更少量的易失性存储器120。
储存装置102可以包含NVMA 116,其可以包含多个存储器装置
140aA-140nN(统称为“存储器装置140”)。存储器装置140的每一个可以被配置为储存和/或检索数据。例如,存储器装置140的存储器装置140xx可以从控制器114接收数据和信息,该控制器指导存储器装置140xx进行储存数据。相似地,存储器装置140的存储器装置140xx可以从控制器114接收信息,该控制器指导存储器装置进行检索数据。在一些示例中,存储器装置140的每一个可以被称为裸芯。在一些示例中,单一物理芯片可以包含多个裸芯(即,多个存储器装置140)。在一些示例中,存储器装置140x的每一个可以被配置为储存相对大量的数据(例如,128MB、256MB、512MB、1GB、2GB、4GB、8GB、16GB、32GB、64GB、128GB、256GB、512GB、1TB等)。
在一些示例中,存储器装置140可以包含任何类型的非易失性存储器装置。存储器装置140的一些示例包含但不限于闪存装置、相变存储器(PCM)装置、电阻随机存取存储器(ReRAM)装置、磁阻随机存取存储器(MRAM)装置、铁电随机存取存储器(F-RAM)、全息存储装置以及任何其他类型的非易失性存储装置。
闪存装置可以包含基于NAND或NOR的闪存装置,并且可以
基于在每个闪存单元的晶体管的浮置栅极中含有的电荷来储存数据。在
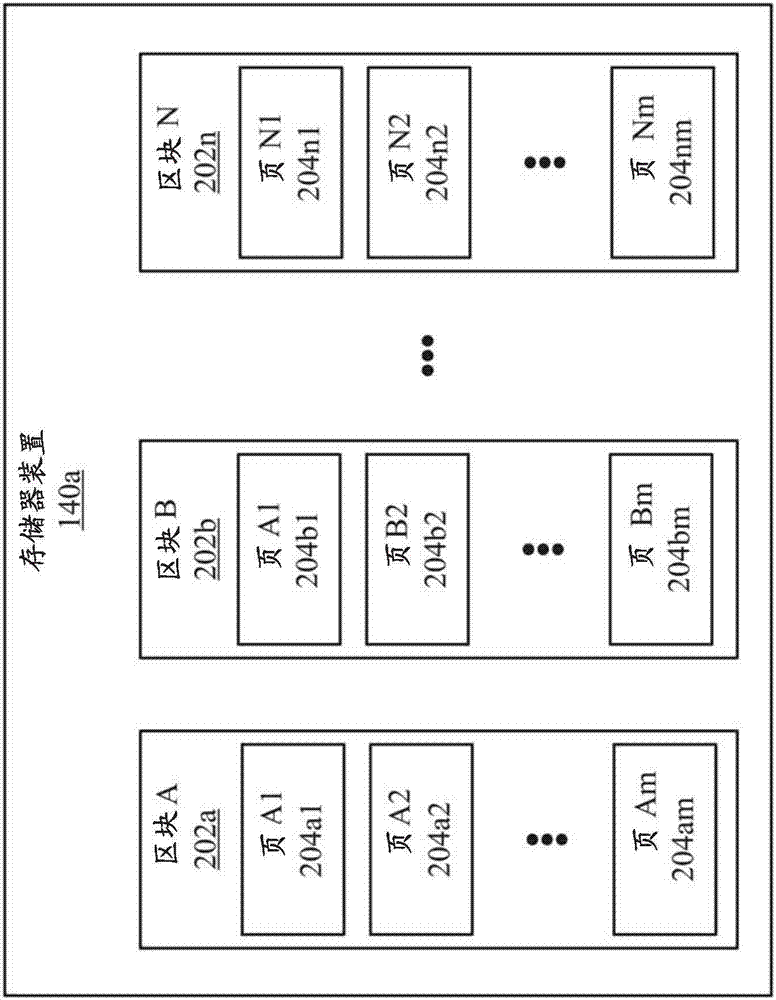
NAND闪存装置中,闪存装置可以被分割为多个区块,该区块的每一个可以被分割为多个页。图2是说明示例存储器装置140a的概念上的方框图,其包含多个区块202a-202n(统称为“区块202”),该区块的每一个被分割为多个页204a1-204am(统称为“页204”)。在特定存储器装置(例如,存储器装置104a)内的页204的每一页可以包含多个闪存单元。在NAND闪存装置中,闪存单元的行可以使用字线进行电连接,以限定多个页204的页。页204的每一个中的相应的单元可以电连接于相应的位线。控制器114可以在页级别向NAND闪存装置写入数据并且在页级别从NAND闪存装置读取数据,并且在区块级别从NAND闪存装置擦除数据。
在一些示例中,控制器114被分别连接于存储器装置140的每个存储器装置140xx可能是不实际的。正因为如此,可以复用存储器装置140和控制器114之间的连接。作为示例,存储器装置140可以被分组为通道(channel)150A-150N(统称为“通道150”)。例如,如图1所示,存储器装置140aA-140nA可以被分组为第一通道140A,并且存储器装置140aN-140nN可以被分组为第N通道150N。分组为通道150的每一个的存储器装置140可以分享控制器114的一个或多个连接。例如,分组为第一通道140A的存储器装置140可以附连到公共I/O总线和公共控制总线。储存装置102可以包含用于通道的每个相应的通道的公共I/O总线和公共控制总线。在一些示例中,通道150的每个通道150x可以包含芯片使能(CE)线的集合,该芯片使能线可以用于复用每个通道上的存储器装置。例如,每个CE线可以连接于存储器装置140的相应的存储器装置140xx。以这种方法,可以减少在控制器114和存储器装置140之间的分别连接的数量。此外,由于每个通道具有连接于控制器114的独立集合,连接的减少可能不会显著地影响数据吞吐率,因为控制器114可以同时向每个通道发布不同的命令。
在一些示例中,储存装置102可以包含若干存储器装置140,其被选择以提供大于主机装置104可存取的容量的总容量。这被称为过度供应。例如,如果储存装置102被通告包含240GB的用户可存取储存容量,则储存装置102可以包含足够的存储器装置140以给出256GB的总储存容量。主机装置104或主机装置104的用户可能不能存取16GB的存储器装置。相反,储存装置102的过度供应的部分可以提供附加区块以有助于写入、垃圾收集、磨损均衡等。另外,过度供应的储存装置102可以提供附加区块,如果一些区块充分地磨损以变得不可用并且退出使用,则可以使用这些附加区块。附加区块的出现可以允许在不引起主机装置104可用的储存容量中的改变的情况下磨损区块的退出。在一些示例中,过度供应的数量可以被限定为p=(T-D)/D,其中p是过度供应率,T是储存装置102的总储存容量,并且D是主机装置104可存取的储存装置102的储存容量。
图3是说明控制器114的示例细节的概念上和示意的方框图。在一些示例中,控制器114可以包含一个或多个处理器320a-320n(统称为“处理器320”)。处理器320可以包含但不限于微处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其他数字逻辑电路。在一些示例中,处理器320和/或控制器114可以是片上系统(SoC)。在一些示例中,处理器320可以包含地址转换模块320、写入模块304、维护模块306、读取模块308、调度模块310和多个通道控制器312a-312n(统称为“通道控制器312”)。在另一个示例中,控制器114可以包含附加模块或硬件单元,或者可以包含更少的模块或硬件单元。例如,通道控制器312可以位于与处理器320分离并且电连接于处理器320的芯片上。在另一个示例中,通道控制器312可以从处理器320分离,但是依然位于具有处理器320的SoC上。在一些示例中,通道控制器312可以由处理器320的每个处理器寻址。
控制器114可以经由接口112与主机装置104接合,并且管理向存储器装置104储存数据以及从存储器装置104检索数据。例如,控制器114的写入模块304可以管理对存储器装置140的写入。例如,写入模块304可以经由接口14从主机装置104接收信息,指导储存装置102储存与逻辑数据地址和数据相关联的数据。
写入模块304可以管理向存储器装置140的数据的写入。例如,写入模块304可以与地址转换模块302通信,其管理在由主机装置104用以管理数据的储存位置的逻辑数据地址和由写入模块304使以指引向存储器装置140写入数据的物理数据地址之间的转换。控制器114的地址转换模块302可以利用逻辑到物理的数据地址转换表,该转换表将由存储器装置140储存的数据的逻辑数据地址(或逻辑区块地址)关联至由存储器装置140储存的数据的物理数据地址(或物理区块地址)。例如,主机装置104可以以对储存装置6的指令或信息的形式利用由存储器装置140储存的数据的逻辑数据地址,同时写入模块304利用数据的物理数据地址以控制向存储器装置140写入数据。相似地,读取模块308可以利用物理数据地址以控制从存储器装置140读取数据。物理数据地址对应于存储器装置140的实际的物理位置。在一些示例中,地址转换模块302可以储存易失性存储器120中的逻辑到物理的数据地址转换表。
以这种方法,可以允许主机装置104使用静态逻辑数据地址用于数据的某些集合,然而数据实际被储存的物理数据地址可以改变。地址转换模块302可以维持逻辑到物理的数据地址转换表,以将逻辑数据地址映射于物理数据地址,以允许静态逻辑数据地址被主机装置104使用,然而数据的物理数据地址可以例如由于磨损均衡、垃圾收集等而改变。在一些示例中,逻辑到物理的数据地址转换表可以是单层表,这样使得通过向从主机装置104接收的逻辑数据地址施加散列(hash)信号,地址转换模块302可以直接检索对应的物理数据地址。
如以上所讨论的,控制器114的写入模块304可以进行一个或多个操作,以管理向存储器装置140的数据的写入。例如,通过选择在存储器装置140内的一个或多个区块,写入模块304可以管理向存储器装置140的数据的写入,以储存数据并且使得包含选择的区块的存储器装置140的存储器装置实际地储存数据。如以上所描述的,写入模块304可以使得地址转换模块302基于选择的区块更新逻辑到物理的数据地址转换表。例如,写入模块304可以从主机装置104接收包含数据单元和逻辑数据地址的信息,选择在存储器装置140的特定存储器装置内的区块和页以储存数据,使得存储器装置140的特定存储器装置实际地储存数据(例如,经由对应于特定存储器装置的通道控制器312的通道控制器),并且使得地址转换模块302更新逻辑到物理的数据地址转换表,以表明逻辑数据地址对应于在存储器装置140的特定存储器装置内的所选择的物理数据地址。
在一些示例中,除了使得数据由存储器装置140储存以外,写入模块304可以使得存储器装置140储存如下信息,该信息可以用于在一个或多个区块失效或者成为损坏的情况下恢复数据单元。奇偶信息可以用于恢复由其他区块储存的数据。在一些示例中,奇偶信息可以是由其他区块储存的数据的XOR。
为了将具有0的逻辑值的位(充电的)写入具有1的先前逻辑值的位(未充电的),使用大电流。该电流可能足够大以使得其可能导致相邻的闪存单元的电荷的无意改变。为了保护免受无意改变,在将任何数据写入区块内的单元之前,可以将闪存单元的整个区块擦除至1的逻辑值(未充电的)。因此,闪存单元可以在区块级别擦除,以及在页级别写入。
因此,为了写入甚至将消耗少于一页的数据量,控制器114可能导致整个区块被擦除。这可能导致写入放大,该写入放大是指从主机装置104接收到的被写入存储器装置140的数据量与实际写入存储器装置140的数据量之间的比率。写入放大带来比将在没有写入放大时所发生的更快的闪存单元的磨损。由于用于擦除闪存单元的相对高的电压,在闪存单元被擦除时可能发生闪存单元的磨损。在多个擦除周期中,相对高的电压可能导致闪存单元的改变。最终,闪存单元可能耗尽,这样使得数据可能不能再被写入单元。写入放大可能由于使用更大的区块和/或页加剧。
控制器114可以实现减少写入放大以及闪存单元的磨损的一种技术包含将从主机装置104接收的数据写入未使用的区块或部分使用的区块。例如,如果主机装置104发送数据至储存装置102,该储存装置仅包含来自由储存装置102已经储存的数据的小的改变。控制器然后可以将旧数据标记为过时或不再有效。随着时间的推移,与擦除保持旧数据的区块并将更新的数据写入相同区块相比,这可以减少被暴露于擦除操作的区块的数量。
响应于从主机装置104接收写入命令,写入模块304可以确定在存储器装置140的哪个物理位置处写入数据。例如,写入模块304可以从地址转换模块302或者维护模块306请求如下一个或多个物理区块地址,这些物理区块地址是空的(例如,没有储存数据)、部分空的(例如,只有区块的一些页储存数据)或者储存至少一些无效的(或过时的)数据。在接收到该一个或多个物理区块地址时,写入模块304可以选择如上所述的一个或多个区块,并且传输使得通道控制器312将数据写入所选择的区块的消息。
相似地,读取模块308可以控制从存储器装置104读取数据。例如,读取模块308可以从主机装置104接收信息,该主机装置104请求具有关联的逻辑数据地址的数据。地址转换模块302可以使用闪存转换层或表将逻辑数据地址转换为物理数据地址。读取模块308然后可以控制通道控制器312中的一个或多个以从物理数据地址检索数据。相似于写入模块304,读取模块308可以选择一个或多个区块并且传输信息,以使得通信控制器312从选择的区块读取数据。
通道控制器312的每个通道控制器可以连接于通道150的相应的通道150x。在一些示例中,控制器114可以包含与储存装置102的通道150的数量相同的数量的通道控制器312。例如在写入模块304、读取模块308和/或维护模块306的控制之下,通道控制器312可以进行对连接于相应的通道的存储器装置140的寻址、编程、擦除和读取的紧密控制。
维护模块306可以配置为进行与维护性能和扩展储存装置102(例如,存储器装置140)的有用寿命有关的操作。例如,维护模块306可以实现磨损均衡或者垃圾收集的至少一个。
如上所述,擦除闪存单元可以使用相对高的电压,其经过多个擦除操作可能使得闪存单元的改变。在特定数量的擦除操作后,闪存单元可以退化为数据不再可以被写入闪速单元的程度,并且包含这些单元的区块可以是退出的(retired)(不再由控制器114用于储存数据)。为了增加在磨损和退出区块之前可以写入存储器装置140的数据量,维护模块306可以实现磨损均衡。
在磨损均衡中,维护模块306可以跟踪用于多个区块的每个区块或组的向多个区块的区块或组擦除或写入的数量。维护模块306可以使得来自主机装置104的到来的数据被写入多个区块中的经历相对更少的写入或者擦除的区块或组,以尝试对于多个区块的每个区块或组维持写入或者擦除的大致相等的数量。这可以使得存储器装置140的每个区块以大致相同的速率耗尽,并且可以增加储存装置102的使用寿命。
即使这可以通过减少向不同区块擦除和写入数据的数量来减少写入放大和闪存单元的磨损,这也可以导致区块包含一些有效(新的)数据和一些无效(过时)数据。为了解决这个问题,维护模块306可以实现垃圾收集。在垃圾收集操作中,维护模块306可以分析存储器装置140的区块的内容以确定含有高百分比的无效(过时)数据的区块。维护模块306然后可以将有效数据从该区块重写至不同区块,并且然后擦除区块。这可以减少由存储器装置140储存的无效(过时)数据的数量并且增加空闲区块的数量,但是也可能增加写入放大和存储器装置140的磨损。
控制器114的调度模块310可以调度由存储器装置140进行的操作。例如,调度模块310可以基于从控制器114的其他组件接收的请求,使得存储器装置140中的一个或多个进行一个或多个操作。在一些示例中,调度模块310可以使得存储器装置140的特定存储器装置通过使得对应于特定存储器装置的通道控制器输出命令至特定存储器装置而进行一个或多个操作。作为一个示例,调度模块310可以许可通道控制器312a输出使得存储器装置140储存数据的命令。
通过动态地传送存储器范围分配的示例负载平衡
本公开的方面提供用于通过动态地传送范围分配的负载平衡的技术。通常,用户正在运行越来越渐增地复杂的应用,每个应用可能触发储存装置的大量读取和写入操作。该工作负载通常消耗大量的处理器资源。随着工作负载增加,所消耗的处理器资源的数量也会增加,并且可能需要将该负载发散到多个处理器上,以分布工作负载并且避免单个处理器的过载。
在分布工作负载时,命令可以被分配至具有可用容量的任何处理器,无论命令所指向的LBA。通过允许命令被分布于任何可用处理器,工作负载可以在多个处理器上动态地平衡。然而,因为每个处理器可能能够寻址相同的LBA,因此需要多个处理器上的全局锁定,因为不同处理器可能尝试无序地执行寻址于相同LBA的不同命令。例如,对专用LBA的写入命令可以被分配到处理器1,并且对相同专用LBA的读取命令可以被分配到处理器2,其中读取命令旨在在写入命令后执行。然而,没有全局锁定机制,处理器2可能在写入命令之前无序地执行读取命令,导致由读取命令返回意外的数据。应该注意到,虽然本公开涉及LBA和LBA范围,但是本公开的方面可以应用于用于寻址储存装置的一个或多个区块的其他技术。
也可以通过向每个处理器分配LBA的固定或静态的范围来分布处理器,这样使得每个处理器处理寻址于在分配给每个处理器的LBA的范围内的LBA的命令。虽然固定的范围是有效的并且可以解决命令排序的问题,但某些工作负载图案可能被次优地处理。例如,集中于小范围的LBA的工作负载可能不能高效地在处理器上分布。
根据本公开的方面,为了帮助分布工作负载,诸如读取或写入请求的储存存取命令可以基于所请求的地址范围被分布在多个处理器上。例如,可以分割LBA范围,这样使得处理器0可以被分配一个以0x0XX和0x8XX结束的地址的范围,处理器1可被分配一个以0x1XX和0x9XX结尾的地址的范围,依此类推,直到所有LBA范围已经被分配。每个LBA范围可以由任何已知的技术来确定。例如,该范围可以LBA的单一的连续范围、多个连续的LBA范围、基于用于确定多个连续的LBA范围的散列或范围分割算法而确定的单独的LBA。在使用给定处理器的多个连续的LBA范围的情况下,跨越多个LBA的命令可以被完全包含在单个处理器的子集内,同时仍然允许具有一些空间局部性的LBA存取图案(pattern)被分布在多个处理器上。在LBA范围已经确定后,主机装置可以发布在LBA 0x94E处开始的读取命令,并且该读取命令然后将被指向至处理器1。
根据本公开的方面,可以为被分配给处理命令的处理器的该命令的储存范围获得本地锁定,并且可以为被分配给其他处理器的命令的储存范围获得借用锁。图4是说明根据本发明的方面的用于获得锁定的技术的示意流程图400。在操作402处,由储存装置从主机接收诸如读取、写入或者删除命令的用于存取的命令。该命令包含被存取的一个或多个区块的关联的LBA或LBA范围。在操作404处,可以将第一LBA与分配给处理器的范围进行比较,以确定LBA将被分配给哪个特定处理器。可以由例如命令分布器进行这个确定,该命令分布器可以是多个处理器的处理器。在操作406处,LBA被分配到专用处理器,并且在操作408处,专用处理器检查是否已经为与命令相关联的所有LBA获得锁定。这可以例如通过循环遍历与命令相关联的所有LBA并且检查是否已经处理了命令的最后的LBA来进行。在操作410处,在没有为与命令相关联的所有LBA获得锁定的情况下,如果被处理的LBA是与命令相关联的第一LBA,则在操作412处获得LBA上的本地锁定,并且执行返回到操作408以处理下一个LBA。在与命令相关联的整个LBA范围被分配给特定处理器的情况下,根据需要采取本地锁定,确保针对关联的LBA范围的命令的执行的执行顺序和原子性。在操作414中,如果被处理的LBA不是与命令相关联的第一LBA,则以相似于在操作404中描述的方式,被处理的LBA可以与分配给处理器的范围相比较,以确定被处理的LBA被分配到哪个特定处理器。在操作416处,如果被处理的LBA被分配给当前处理器,则然后在操作412处获得对LBA的本地锁定。如果被处理的LBA被分配给另一个处理器,则然后在操作418处,当前处理器可以做出请求以从其他处理器借用LBA。可以通过将请求放置于分配了LBA的其他处理器以将本地锁定放置在LBA上,来由当前处理器借用该LBA。在由其他处理器成功放置锁定并且执行返回操作408以处理下一个LBA后,该请求可以被确认。一旦所有LBA被处理并且获得了锁定,可以在操作420处执行命令。
根据本公开的方面。储存装置可以监控处理器的工作负载,并且如果工作负载被确定为在处理器上不平衡,则可以调整处理器之间的地址范围分割。例如,如果大部分的LBA存取正由少部分的处理器进行,则可以调整分配给每个处理器的LBA范围。
图5是说明根据本发明的方面的用于调整处理器范围分配的技术的示意流程图500。在操作502处,确定在多个处理器上的工作负载是不平衡的。可以例如通过监控在一个或多个处理器上执行的处理,来进行这个确定。这个监控处理可以是调度模块的一部分或者一个分离的模块。在操作504处,可以选择新的范围分割算法,用于确定哪些范围被分配到哪些单独的处理器。这个新算法可以是与当前使用的算法不同的算法。该算法可以从用于在各种条件下优化负载平衡的任何算法中选择。
在操作506处,发送变换阻挡命令至多个处理器中的每个处理器。这个变换阻挡命令表明范围分割算法切换正在进行,并且可以包含将使用的新的范围分割算法。例如,可以由在一个或多个处理器上执行的作为调度模块的部分的分布实体,发送变换阻挡命令。在接收变换阻挡命令后,在每个处理器在接收变换阻挡命令前已经完成实时执行所有命令后,每个处理器可以用完整的指示进行回复。在操作508处,如果已经从每个处理器接收回复,表明自发布了变换阻挡命令以后已经执行所有命令、并且已经没有新的命令被接收,则变换阻挡完成命令可以被发送至每个处理器,表明在操作516处已经实现新的范围分割算法。在操作510处,在发送变换阻挡完成命令后但在发送变换阻挡完成命令之前,可以从主机接收新的命令。在操作512处,基于使用新的范围分割算法所确定的范围,以相似于在操作404中所描述的方式确定该命令被分配到哪个特定处理器。在操作514处,基于该确定,命令被发送至特定处理器,且执行返回508。
图6A-6D是说明根据本发明的方面的用于在调整处理器范围分配时获得锁定的技术的示意流程图600。在操作602处,由储存装置从主机接收诸如读取、写入或者删除命令的用于存取的命令。在操作604处,确定是否调整处理器范围分配。如果不调整处理器范围分配,例如在变换阻挡未被发送的情况下,则执行继续进行图4的操作408。如果调整了处理器范围分配,例如在已经发送变换阻挡的情况下,则在606处,确定与命令相关联的所有LBA是否已经获得本地或远程的锁定。如果对于与命令相关联的所有LBA已经获得锁定,则可以在操作616处执行命令。
如果不是为所有LBA都已经获得锁定,则执行继续进行操作608,并且基于当前(即先前使用的)范围分割算法,以相似于在操作404中所描述的方式确定命令的LBA将被分配给哪个处理器。在操作610处,基于新的(即如在传送阻挡命令中指定的)范围分割算法,以相似于在操作404中所描述的方式确定命令的LBA将被分配给哪个处理器。在调整范围分配时,每个处理器将在新的和当前的范围分割算法两者下确定LBA应该被分配到哪个处理器。如果在操作612处,与命令相关联的LBA在两种算法下被确定为分配到当前处理器,则在操作614处以相似于在操作412中所描述的方式获得LBA上的本地锁定。然后执行循环回到操作606。
如果在操作612处,与命令相关联的LBA在当前和新的算法两者中被确定为不分配到当前处理器,则然后执行继续进行图6B的操作615。在操作615处,在当前算法下确定对LBA是否被分配到另一个处理器以及在新的算法下确定LBA是否被分配到当前处理器。如果是这样,在操作617处,以相似于在操作418中所描述的方式从其他处理器获得在LBA上的远程锁定。在操作618处,以相似于在操作412中所描述的方式获得本地锁定。然后执行循环回到操作606。
如果在操作615处,在当前算法下LBA被确定为不被分配到另一个处理器或者在新的算法下LBA被分配到当前不同的处理器,则然后执行继续进行图6C的操作620。在操作620处,在当前算法下确定LBA是否被分配到当前处理器以及在新的算法下确定LBA是否被分配到另一个处理器。如果是这样,在操作622处,以相似于在操作412中所描述的方式获得本地锁定。在操作624处,以相似于在操作418中所描述的方式从其他处理器获得在LBA上的远程锁定。然后执行循环回到操作606。
如果在操作620处,在当前算法下LBA被确定为不被分配到当前处理器或者在新的算法下LBA被分配到当前处理器,则然后执行继续进行图6D的操作626。在操作626处,在当前算法下确定LBA是否被分配到另一个处理器以及在新的算法下确定LBA是否被分配到第三处理器。如果是这样,在操作628处,以相似于在操作418中所描述的方式从其他处理器获得在LBA上的远程锁定。在操作630处,以相似于在操作418中所描述的方式从第三处理器获得在LBA上的远程锁定。然后执行循环回到操作606。如果在操作626处,在当前算法下LBA被确定为不被分配到另一个处理器并且在新的算法下LBA被分配到第三处理器,则可以返回错误,并且执行循环回到操作606。
图7是说明根据本发明的方面的用于释放存储器锁定的技术的示意流程图700。如以上所描述的,存储器的部分、诸如由LBA所引用的部分可以由处理器锁定,同时在存储器的这些部分上执行命令。在操作702处命令的执行完成后,可以释放锁定。在操作704处,如果不是所有存储器锁定已经被释放,则在操作706处,检查锁定以确定锁定是本地锁定还是远程锁定。在操作708处,释放本地锁定。在操作710处,通过将释放锁定的指示发送至保留锁定的处理器来释放远程锁定。在释放锁定后,执行返回到操作704以确定是否已经释放与命令相关联的所有存储器锁定。在当正调整处理器范围分配时获得锁定并且在(然后)当前和新的算法两者下获得锁定的情形下,可以释放这两个集合的锁定。在已经释放与命令相关联的所有锁定后,进行在操作712处的检查,以确定是否当前正在调整处理器范围分配以及是否已经执行了在接收变换阻挡之前由处理器接收的所有命令。这个检查防止多个处理器范围调整操作同时发生。如果两个条件都是正确的,则在操作714处,处理器可以将处理器在接收变换阻挡命令前已经完成执行实时(in flight)的所有命令的指示发送至例如分布实体。
图8A-8C是说明根据本公开的方面的示例处理器范围调整操作的调用流程图800。调用流程图800说明在四个处理器802A-802D之间的调用流程,其中处理器802A作为分布实体运行,并且其他三个处理器802B-802D处理命令。在初始状态中,LBA 0x1000被分配给处理器802B。在存取从主机接收的LBA 0x1000的命令后,随着LBA 0x1000被分配至处理器802B,处理器802A在流程804处可以将第一命令(CMD A)发送至处理器802B以进行处理(CMD A处理)。在流程806处,在处理命令中的处理器802B请求用于LBA 0x1000的本地存储器锁定。在流程808处,确定不存在进行中的处理器范围调整操作。在流程810处,基于当前处理器范围分配算法,确定LBA被分配至处理器802B,并且在流程812处,本地锁定请求被授权。
在命令被发送至处理器802B后的一些时间点,诸如在操作502中所描述的,确定工作负载是不平衡的、且范围分配应该被调整。在流程814、816和818处,变换阻挡命令被分别发送至处理器802B、802C和802D。该变换阻挡命令可以包含新的范围分割算法,用于确定哪个LBA被分配到哪个处理器。在新的算法下,LBA 0x1000将被分配给处理器802C。在流程820和822处,处理器802C和802D分别响应,表明在接收变换阻挡命令之前接收的所有命令的处理都已经完成。
在流程824处,存取LBA 0x1000的第二命令(CMD B)被发送至处理器802C以进行处理(CMD B处理)。在流程826处,请求LBA 0x1000的存储器锁定。在流程828处,确定存在进行中的处理器范围调整操作。在流程830处,基于当前处理器范围分配算法,确定LBA被分配至处理器802B。在流程832处,基于新的第二处理器范围分配算法,确定LBA被分配至处理器802C。在流程834处,处理器802C发布对与CMD B相关联的LBA的远程锁定的请求至处理器802B。在流程836处,处理器802B执行第一命令(CMD A)。在流程838处,发布请求以释放其在与CMD A相关联的LBA上的锁定,并且在流程840处,释放本地锁定。在流程842处,处理器802B向处理器802A表明在接收变换阻挡命令之前接收的所有命令的处理都已经完成。在流程844处,处理器802B授权来自处理器802C的请求以用于对与CMD B相关联的LBA的远程锁定。在流程846处,处理器802C授权对与CMD B相关联的LBA的本地锁定。
在已经接收从处理器802B-802D接收的响应、表明对在接收变换阻挡命令之前所接收的所有命令已经完成处理后,处理器范围调整操作完成。在流程848、850和852处,处理器802A将变换阻挡完成命令分别传送至处理器802B、802C和802D。
可以确定应该进行另一个变换阻挡命令,并且在流程854、856和858处,变换阻挡命令分别被发送至处理器802B、802C和802D。该变换阻挡命令可以包含第三范围分割算法,用于确定哪个LBA被分配到哪个处理器。在第三算法下,LBA 0x1000将被分配给处理器802D。在流程860和862处,处理器802B和802D分别响应,表明在接收变换阻挡命令之前接收的所有命令的处理都已经完成。
在流程864处,存取LBA 0x1000的第三命令(CMD C)被发送至处理器802D进行处理(CMD C处理)。在流程866处,请求LBA 0x1000的存储器锁定。在流程868处,确定存在进行中的处理器范围调整操作。在流程870处,基于第二处理器范围分配算法,确定LBA被分配至处理器802C。在流程872处,基于新的第三处理器范围分配算法,确定LBA被分配至处理器802D。在流程874处,处理器802D发布对与CMD C相关联的LBA的远程锁定的请求至处理器802C。在流程876处,处理器802C执行第二命令(CMD B)。在流程878处,发布用于释放对与CMD B相关联的LBA的远程锁定的请求。在流程880处,处理器802C发布对与CMD B相关联的LBA的远程锁定释放命令至处理器802B,并且在流程881处,释放对LBA的远程锁定。在流程882处,处理器802C响应表明在接收变换阻挡命令之前所接收的所有命令都已经完成处理后,并且处理器范围调整操作完成。在流程883、884和885处,处理器802A将变换阻挡完成命令分别传送至处理器802B、802C和802D。
在流程886处,存取LBA 0x1000的第四命令(CMD D)被发送至处理器802D进行处理(CMD D处理)。在流程887处,请求LBA 0x1000的存储器锁定。在流程888处,确定不存在进行中的处理器范围调整操作。在流程889处,基于第三处理器范围分配算法,确定LBA被分配至处理器802D。在流程890处,处理器802D从处理器802C接收远程锁定响应,授权针对CMD C的远程锁定。在流程891处,对与CMD C相关联的LBA 0x1000发布本地锁定,并且在流程892处,处理器802C执行第三命令(CMD C)。在流程893处,发布用于释放对与CMD C相关联的LBA的远程锁定的请求。在流程894处,处理器802D发布对与CMD C相关联的LBA的远程锁定释放命令至处理器802C,并且在流程895处,释放对LBA的远程锁定。
一旦释放LBA的本地锁定,可以继续进行对第四命令(CMD D)的执行,该第四命令存取与第三命令相同的LBA。在流程896处,与CMD D相关联的本地锁定请求被授权。在流程897处,处理器802D执行第四命令(CMD D),并且在流程898处,释放本地锁定。
可以理解,本文所公开的实施例不限于影响所有可能的LBA的整个范围。本文所公开的实施例也可应用于所有可能的LBA的整个范围的子集。也可以使用被设计为应用于整个范围的子集的算法。调整整个范围的子集的范围可以帮助减少在调整操作期间的中断。
根据本公开的方面,在特定LBA范围跨过多于单一原子单元的情况下,然后命令在原子单元边界处分解。一旦获得原子单元内的锁定,然后命令可以在该原子单元上执行。相似地,一旦命令在这些LBA上完成后,可以释放锁定。
应当理解,虽然本文提供的示例对具有一个或多个LBA的单个命令进行处理,但是本领域技术人员将能够将本公开的内容应用于基于诸如原子单元的其他边界的命令的批处理,或者选择在命令内的LBA以选择性地获得某些LBA上的锁定,同时在其他LBA上进行并行操作。
虽然前述内容涉及本公开的实施例,但是可以在不脱离其基本范围的情况下设计本公开的其他和进一步的实施例,并且其范围由所附权利要求确定。
- 还没有人留言评论。精彩留言会获得点赞!