一种CCMI文本特征选择方法与流程
本发明属于计算机数据分析与挖掘领域,尤其涉及一种ccmi文本特征选择方法。
背景技术:
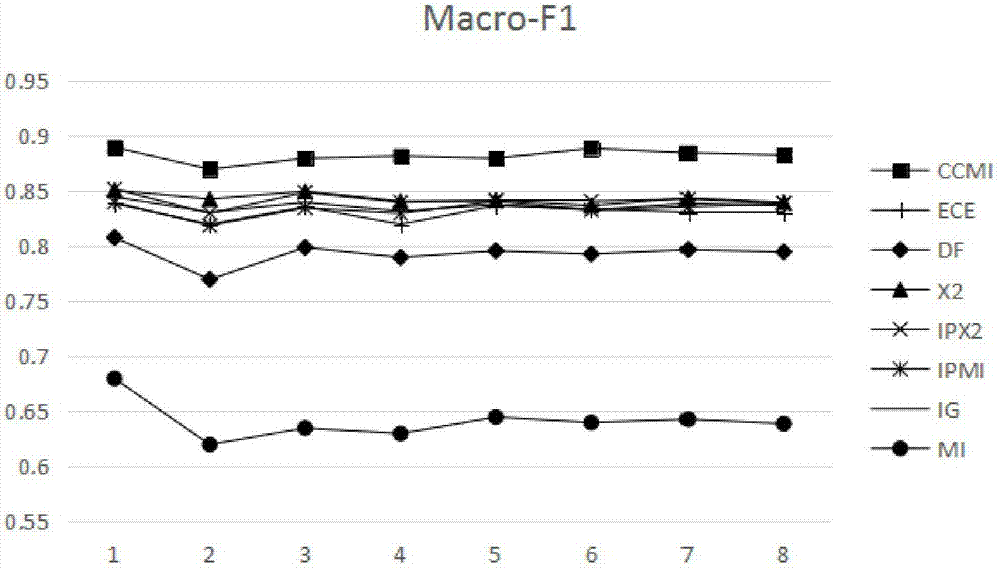
:文本分类领域面临的挑战之一是“维度灾难”问题。语料库较大时,特征维数通常高达上万维甚至几十万维,此时分类器面临的是一个语料库文本数×特征维数的巨大矩阵,在单机下给分类器带来了巨大的运算压力,甚至无法完成运算。同时,如此高维的特征中,包含不少噪声数据,不仅给分类器带来了较高的计算复杂度,也可能给分类效果带来负面影响。所以,尽量移除对分类没有贡献或者贡献极小的特征,是特征降维的关键。常用的特征选择算法依据其是否使用类别标签,分为两种,一种是无监督的特征权重,典型代表有特征频率(termfrequency,tf)、文档频率(documentfrequency,df),tf-idf(termfrequency-inversedocumentfrequency)等;另一种是有监督的特征权重,典型代表有期望交叉熵(expectedcrossentropy,ece)、几率比(oddsratio,or)、信息增益(informationgain,ig)、χ2统计量(chi-square)、互信息(mutualinformation,mi)等。研究表明:通常情况下,有监督的特征权重效果优于无监督的特征权重,参见文献1:batali,hauskrechtm.boostingknntextclassificationaccuracybyusingsupervisedtermweightingschemes[c]//proceedingsofthe18thacmconferenceoninformationandknowledgemanagement.acm,2009:2041-2044。同时,将无监督的词频信息加入有监督的特征权重内,也属于有监督的特征权重范畴,如tf×ig,tf×χ2统计,tf×mi等。目前,针对现有的特征选择算法,国内外的学者已有了不少改进,大致分为两个方向:第一种,将现有的降维算法与其他的降维算法相结合,以期相互扬长避短;第二种,针对目前特征选择算法的固有缺陷,提出改进方案,以达到优化效果。但是面对不同性质、不同规模、不同非平衡度的数据集,目前仍然没有形成统一的评价特征选择算法优劣的标准。文献指出,性能优异的特征选择算法应具有如下特点:选取优质的特征、算法复杂度低,且在低维就可以达到较好的分类性能,适用于不同类型语料库(平衡、非平衡),适用于不同分类器。技术实现要素:发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种有效的的文本特征选择方法。技术方案:基于χ2统计和互信息的ccmi文本特征选择方法,包括以下步骤:步骤1,从语料库中提取所有的特征,构成原始特征集合f;步骤2,选择改进的χ2统计ipx2和改进的互信息ipmi并将二者联合作为评估函数,对原始特征集合f中的每个特征计算其评估函数值;步骤3,对原始特征集合f中的特征根据其评估函数值以从高到低的顺序进行排序,选择前k(k小于原始特征集合f的特征数量)个特征构成新的特征集合,形成降维后的特征空间v。步骤2包括如下步骤:步骤2-1,针对χ2统计量在非平衡数据集上表现不佳的问题,引入类内频度、集中度、分散度,并对其进行改进,使其适合于非平衡数据集。假定特征变量t和类别变量ci相互独立,特征变量t和类别变量ci的分布如表1所示。表1相关变量表定义m表示训练集中文本的总数,m=a+b+c+d。从表1得到:由于特征与类别ci相互独立,则特征在所有类别的文本中等概率出现,从表1得到特征t出现的概率p(t)为:文本类别为ci的概率p(ci)为:在类别ci的文本中出现特征t的概率p(t|ci)为:步骤2-2,所有属于类别ci的文本中,出现特征t的理论文本数量e11为:步骤2-3,所有不属于类别ci的文本中,出现特征t的理论文本数量e12为:步骤2-4,所有属于类别ci的文本中,未出现特征t的理论文本数量e21为:步骤2-5,所有不属于类别ci的文本中,未出现特征t的理论文本数量e22为:步骤2-6,属于类别ci的所有文本中含有特征t的实际文本数和理论文本数的偏离程度d11为:步骤2-7,不属于类别ci的文本中含有特征t的实际文本数和理论文本数的偏离程度d12为:步骤2-8,属于类别ci的所有文本中未出现特征t的实际文本数和理论文本数的偏离程度d21为:步骤2-9,不属于类别ci的所有文本中未出现特征t的实际文本数和理论文本数的偏离程度d22为:步骤2-10,特征t与类别ci的偏离程度χ2(t,ci)为:χ2统计量的计算公式表明:当ad-bc>0时,特征t与类别ci正相关,表示特征出现时,文本可能属于类别ci,且属于类别ci的可能性与χ2统计量的大小成正比;当ad-bc<0时,特征t与类别ci负相关,表示特征t出现时,文本不可能属于类别ci,且不属于类别ci的可能性与χ2统计量的大小成正比;当ad-bc=0时,说明特征t与类别ci相互独立。公式(12)存在缺陷:χ2的评估函数只考虑了特征的文档频率,而忽略了特征的词频等重要信息,故而在文档频率相同的情况下,某类别中词频较高的特征对文本分类的贡献没有体现出来,导致文档频率较高的特征会被优先选择,而文档频率低但词频较高的特征可能具有更强的类别信息的情况被忽视,这可能会导致分类性能不佳;对于集中分布于某一类别的不同特征,类内分布相对均匀的特征对文本分类的贡献比分布不均匀的特征要高,而的评估函数并未考虑特征在类内的分布差异,这也是导致分类性能不佳的原因之一;在非平衡数据集中,正类样本中的特征由于文档频率低,常被负类样本中的特征淹没,利用的评估函数选择的特征在正类上的分类效果较差。步骤2-11,针对χ2统计量在非平衡数据集上表现不佳的问题,引入类内频度、集中度、分散度,并对其进行改进,得到特征t的改进的χ2的评估函数ipx2,使其适合于非平衡数据集。步骤2-12,计算特征t与类别ci之间的统计关联程度,即互信息mi(t,ci);步骤2-13,计算特征t在类别间的区分度diff(t,ci,cj);步骤2-14,基于区分度diff(t,ci,cj),根据改进的互信息ipmi计算公式计算特征t的互信息ipmi(t);步骤2-15,将特征t的改进的χ2的评估函数ipx2和互信息ipmi(t)结合,计算原始特征集合f中的每个特征t的评估函数值ccmi(t)。步骤2-11中,通过如下公式计算类内频度fi(t,ci):其中,tfci(t)表示类别ci中,特征t出现的次数;nci表示类别ci中文本总数。公式(13)对类内频度取对数主要目的是起平滑作用,即当遇到平衡度较大的数据集时抑制负类中词频过高的特征。步骤2-11中,通过如下公式计算集中度ci(t):其中,ci(t)表示类别ci中含有特征t的文本数量。步骤2-11中,通过如下公式计算分散度di(t):步骤2-11中,得到特征t对于类别ci的改进的χ2的评估函数ipx2(t,ci)为:特征t对于整个语料库中所有文本类别的改进的χ2的评估函数ipx2(t)为:其中,m为整个语料库中所有文本类别数量。在概率论和信息论中,两个随机变量的互信息是变量间相互依赖性的量度。在文本分类中,互信息(mutualinformation,mi)衡量的是特征与类别之间的统计关联程度,步骤2-12中,通过如下公式计算特征t与类别ci之间的互信息mi(t,ci):p(t,ci)表示属于类别ci的文本且出现特征t的概率,其中p(t,ci)=p(ci)·p(t|ci)(19)。从公式(18)中容易发现:互信息受p(t)的影响较大,即具有相同条件概率p(t|ci)的特征,稀有特征具有较大的mi值,夸大了稀有特征对于文本分类的贡献程度;再者,互信息并未考虑词频信息对于文本分类的影响,所以在非平衡数据集下效果不佳。但是互信息中的携带的强类别信息是值得借鉴的:如果一个特征能很好地区分某一类别与其他所有类别,那么我们认为这类特征具有很强的类别代表性。而一个特征区分两个类别的能力可以用互信息差值的绝对值予以表示,且由于文本的多分类问题可以转化为多个二类关系,则特征区分某一类别与其他所有类别的能力就可以用任意两个类别间的互信息差值的绝对值的和进行表示。将以上表述称之为特征在类别间的区分度diff(t,ci,cj),它可以用来甄别特征的强类别信息,因此步骤2-13中,通过如下公式计算特征t在类别间的区分度diff(t,ci,cj):diff(t,ci,cj)=p(t|ci,cj)·|mi(t,ci)-mi(t,cj)|(20)其中,p(t|ci,cj)表示特征t在ci、cj组成的整体中出现的概率,cj表示语料库文本所有类别中的任意一个与类别ci不同的类别。步骤2-14中,根据如下改进的互信息ipmi计算公式计算特征t的互信息ipmi(t):针对传统χ2统计量和互信息的不足,分别提出改进方案,改进后的算法分别称为ipx2和ipmi,并将ipx2和ipmi相结合提出基于统计量和互信息的联合特征选择算法ccmi(collectivechi-squareandmutualinformation)。ccmi在具备ipmi的强类别信息的同时也适用于非平衡数据集,步骤2-15中,根据如下公式计算原始特征集合f中的每个特征t的评估函数值ccmi(t):ccmi(t)=λ·ipx2(t)+(1-λ)·ipmi(t),0≤λ≤1(22)。χ2统计量(chi-square)是用于衡量特征与类别之间的相关联程度的一种算法。文本分类的应用中,它的主要思想是假设特征与类别之间符合具有一阶自由度的χ2分布。χ2统计就是统计样本的实际观测值与理论推断值之间的偏离程度,由实际观测值与理论推断值之间的偏离程度决定χ2统计量的大小。χ2统计量越大,表示实际观测值与理论推断值间的偏离程度越大,越不符合实际情况;χ2统计量越小,表示实际观测值与理论推断值间的偏离程度越小,越趋于符合实际情况;当两个值完全相等时,χ2统计量为0,表示实际观测值与理论推断值完全符合。从χ2统计量的分析可知:χ2统计量的缺点之一是偏向于词频较低的特征。在实际语料库中,词频较低的特征中很多都是噪声词,在χ2统计量的计算中也是属于负相关的情况,因此选择这些特征会给χ2统计量的计算带来负面影响。借鉴于期望交叉熵对于信息增益的改进,考虑特征不出现的情况对于文本的贡献远小于其带来的噪声,本文在χ2统计量的计算中也去除特征与类别负相关的情况。特征的词频信息是常用的特征选择指标之一,该指标认为:在某一类别中某个特征出现的频率越高,对文本分类的贡献越大,且具有更强的类别信息。但是,在非平衡数据集中,简单地使用某一类别中的词频信息表现并不好。其原因是正类中文本数量较少,可能会出现正类中的高频词的词频还没有负类中的低频词的词频高的情况,此时正类的特征很可能会被负类的特征淹没,例如常用的reuters-21578语料、复旦大学语料库等均是高度非平衡的语料,负类的文本数量可能是正类的上百倍。在互信息中,稀有特征通常被赋予较大的值。其优点是提取出了具有强类别信息的词作为特征,但是缺点也很明显,即当稀有特征只在某个类别的少数文本中出现时,这些特征通常会被提取出来,但是实验证明其中的大部分特征在该类别中并不具有代表性,不能代表这个类别,甚至可能是噪声数据,会给分类带来负面的影响。但是互信息中的携带的强类别信息是值得借鉴的:如果一个特征能很好地区分某一类别与其他所有类别,那么认为这类特征具有很强的类别代表性。而一个特征区分两个类别的能力可以用互信息差值的绝对值予以表示,且由于文本的多分类问题可以转化为多个二类关系,则特征区分某一类别与其他所有类别的能力就可以用任意两个类别间的互信息差值的绝对值的和进行表示。传统χ2统计量有偏向于词频低特征的缺陷,且未考虑文本中特征的分布信息;而传统互信息选取的稀有特征由于包含大量的噪声区分类别的能力并不理想,存在更大的改善空间;同时尤其面对非平衡度较大的数据集时,传统特征选择算法在准确率、召回率、f测量值等评价指标上的表现均不理想。有益效果:本发明的一种ccmi文本特征选择方法与现有方法相比优点在于:在宏平均、微平均上均得到了不错的分类效果,不仅降低了特征空间的维度,提取出强类别代表性的特征,而且同时适用于平衡数据集与非平衡数据集。附图说明下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。图1为本发明主要流程图。图2为在knn算法的不同的k值下,各特征选择算法上的宏平均f1。图3为在knn算法的不同的k值下,各特征选择算法上的微平均f1。图4为在knn算法中,取k=5,在不同维度下,各特征选择算法上的宏平均f1。图5为在knn算法中,取k=5,在不同维度下,各特征选择算法上的微平均f1。图6为各特征维度下,svm分类器上的宏平均f1。图7为各特征维度下,svm分类器上的微平均f1。具体实施方式下面结合附图及实施例对本发明做进一步说明。首先从预处理过后的语料库中提取所有的特征,构成原始特征集合f,降维后的特征空间v。如图1所示,本发明的步骤为:步骤一,从预处理过后的语料库中提取所有的特征,构成原始特征集合f;步骤二,选择改进的χ2统计(ipx2)和改进的互信息(ipmi)并将二者联合作为评估函数,对原始特征集合f中的每个特征计算其评估函数值;步骤三,对原始特征集合f中的特征根据其评估函数值以从高到低的顺序进行排序,选择前k(k小于原始特征集合f的特征数)个特征构成新的特征集合,形成降维后的特征空间v。表1是特征变量t和类别变量ci的分布。表2和表3是测试使用的数据基本信息。复旦大学李荣陆教授收集整理的中文文本语料库是国内使用较多且具有权威性的中文文本语料库。该语料库已经划分好了文本的类别,共有20个类别,含中文文本19637篇,其中训练集有文本9804篇,测试集有文本9833篇。从中选取两个语料库进行实验。a类语料库为类别分布均匀的语料库,b类语料库为类别分布不均匀的语料库,非平衡度最高为32:1,对于文本的预处理工作主要是中文分词及去停用词,本文采用的分词工具是中科院计算技术研究开发的汉语分词系统nlpir(又名ictclas)。考虑到噪声词汇带来的负面影响,本文对于特征的提取利用了nlpir的词性标注功能,只提取其中的名词(不包含人名)、动词以及形容词特征,并且滤除停用词593个,语料库a共提取93030个特征,语料库b共提取86657个特征。表2语料库a艺术历史航空计算机环境农业经济运动训练集510466500510520516507510测试集365368411427406288407415表3语料库b艺术历史航空计算机环境农业经济运动训练集510466500510515161600510测试集36536841142751288407415鉴于特征选择算法中有监督的特征选择算法的研究,分别实现以下特征选择算法,即文档频率(df)、信息增益(ig)、期望交叉熵(ece)、χ2统计量(x2)、互信息(mi)、基于χ2统计量的改进(ipx2)、基于互信息的改进(ipmi)以及最终的ccmi算法。通过设定不同的特征维度,选择平衡/非平衡数据集以及设置不同的分类器分别进行对比实验,证明算法的有效性。采用向量空间模型作为文本的表示模型,采用的特征权重为文本分类领域广泛使用的tf-idf权重。tf-idf是一种统计方法,用于评估特征词对一个语料库中文本的重要程度,其中词的重要性与它在文本中的词频成正比,与它在语料库中出现的文档频率成反比;同时为了规避特征权重偏向于长文本的情况,通常对tf做归一化处理。采用其中的knn算法和svm算法分别在复旦大学语料库上进行对比实验,验证算法的有效性及朴素性。knn算法是已经被证明的文本分类领域最有效的方法之一,故采用knn算法对特征选择算法进行研究。knn算法的研究的核心问题主要在于两方面:距离函数的设定以及最近邻个数的选择。对于距离函数的设定,本文采用余弦距离度量文本之间的相似度;对于最近邻个数的选择,本文通过实验的方法,观察最近邻个数对文本分类的影响,最后选取效果较佳的最近邻个数。为了验证算法的朴素性,在保证同一数据集、同一特征维度的基础上,利用台湾大学林智仁教授等开发设计的libsvm分类器对χ2统计量、互信息、基于χ2统计量的改进、基于互信息的改进以及最终的ccmi算法进行的实验,观察实验效果;其中svm参数设置如下:核函数选择使用线性核函数,其余参数均采用默认参数。图2和图3分别展示了在语料库a上、特征维度为500时,各种特征选择算法在最近邻个数k值上宏平均和微平均的比较。可以看出,各种特征选择算法在宏平均和微平均上基本符合相同的趋势。在各种特征选择算法上,最近邻个数k值的选择对分类的宏平均和微平均并没有造成太大的影响,只在k值等于1到2值之间略有波动。其主要原因是k值选取太小时,噪声数据会对k-最近邻分类产生较大的影响,因此k值不宜取值太小;而当k值大于等于3时,k-最近邻分类器均保持比较平稳的分类效果,且取值在5到6之间时,分类效果相对较佳。故下面的实验中,最近邻个数k值均选择为5;传统的特征选择算法中,df的效果比较一般,宏平均和微平均都是接近0.8,适合作为评判其他评估函数的标准。ig和χ2是目前比较优秀的分类选择算法,相比于df的分类效果,将宏平均和微平均提高了近3-4个百分点。而ece作为ig的优化版本,只考虑特征出现时给文本带来的信息量,效果和ig相当,且有小幅波动,也是优秀的特征选择算法之一。而mi的分类效果最差,宏平均和微平均均只有0.65左右,其主要原因是选择的稀有特征部分是噪声数据;在平衡数据集下,本文提出的基于χ2统计量的改进ipx2主要在去除了特征对于文本类别负相关的情况,因此ipx2相对于传统χ2效果并不明显,分类效果基本处于持平状态,略有提升;而本文提出的基于互信息的改进ipmi效果提升非常明显,在k值等于8时,ipmi相比于mi提升了将近20个百分点,证明了ipmi的有效性;从整体而言,本文提出的将改进的χ2统计量与改进的互信息相结合的特征选择策略ccmi具有最好的分类效果,宏平均和微平均最高可达将近89%,明显高于上述所有算法。下面将就本文提出的ccmi算法,在特征维度、数据集的非平衡度、分类器的选择上进行具体阐述,从实验角度证明算法的有效性。图4和图5为选取k=5,语料库a上,不同特征维度下,对于x2、ipx2、mi、ipmi、ccmi在宏平均和微平均的比较。可以看出:(1)单从宏平均和微平均来看,ccmi的分类效果明显最优,ipx2的分类效果略高于x2和ipmi,而ipmi极大地改进了mi,证明本发明提出的改进算法效果明显;(2)在特征维度在区间[400,800]时,降维效果明显,且分类效果较好。故在未加入语义特征的前提下,维度在此区间会取得较好的分类效果,且降低了计算复杂度;(3)当特征维度降低到200维时,由于不仅缺失了特征之间的语义信息,而且缺失了分类信息,各种特征选择算法效果均未达到最佳;当特征维度保持在1000以上时,各种特征选择算法的效果趋于相同,且略低于特征维度在[400,800]区间时分类效果。这个现象说明:当特征维度增加时,虽然增加了分类信息,但同时带来了噪声信息,导致分类效果降低,并且增加了不必要的计算开销,侧面证明了特征降维的必要性;由上述分析可得出结论:特征维度处于区间[400,800]时,本文提出的算法ccmi具有最佳的分类效果,故设置最佳特征维数为600维。表4、表5、表6分别为选取k=5,特征维度为600维,非平衡语料库b上,利用传统的χ2统计量、互信息以及本文提出的算法ccmi,比较每个类别上查全率、查准率以及整个语料库上的分类效果(最优的分类效果加粗显示)。从数据比较上可以观察到:(1)从整体的分类效果上来看,本文提出的ccmi算法均具有最优的分类效果,均明显优于传统χ2统计量和互信息,且无论是宏平均还是微平均上,ccmi都能有较大的改进;(2)非平衡语料库b中,经济类别属于负类,有1600个训练文本以及407个测试文本,而环境类别属于正类,训练文本和测试文本均只有51个,在传统的χ2统计量和传统互信息上,环境类别受负类影响,分类效果明显不佳,查准率分别只有0.6和0.3571,而ccmi在保证其他类别分类精度的基础上,极大地提高了正类样本的查准率,达到0.9,同时也提高了查全率,证明本算法同样适用于正类;表4是在语料库b上,传统的χ2分类效果,表4表5是在语料库b上,传统mi分类效果,表5表6为在语料库b上,ccmi分类效果,表6图6和图7为选取svm分类器,在语料库a上,不同的特征维度下,对于x2、ipx2、mi、ipmi、ccmi在宏平均和微平均上的比较。从分类效果的总体走势可以发现,各种特征选择算法在svm分类器上的分类效果和上文k-最近邻分类器效果相近,ccmi算法比传统χ2统计量在宏平均和微平均上高出近3个百分点,且明显优于传统的互信息特征选择算法,从而证明了ccmi算法的朴素性。在语料库a、b上的实验证明:ccmi算法在宏平均f1、微平均f1上均得到了不错的分类效果,该算法通过提取出强类别代表性的特征,降低了特征空间的维度,提升分类精度和泛化效果,改善性能,节省存储和计算开销,并且同时适用于平衡数据集与非平衡数据集。实施例本发明很好的解决了在法律领域中法律文本分类问题。随着《最高人民法院裁判文书上网公布暂行办法》的审议通过和全面实施,最高法发生法律效力的判决书、裁定书、决定书开始在互联网上予以公布,这为文本分类在裁判文书领域的应用提供了契机。一方面,越来越多半结构化的裁判文书在中国裁判文书网上发布,是优质的有标签的数据来源;另一方面,互联网上传播的形形色色的案件也急需统一的规则来进行组织和管理。目前中国裁判文书网增加了根据“案由”、“审理法院”、“文书类型”和“裁判时间”进行检索的功能。其中,后三项对于限制查询结果、精确查询范围非常有帮助。而“案由”的查询方式则对于法官和律师而言非常便利,他们只需要依照最高法院颁布的相应的“案由规定”进行查询即可。由此可以看到案由自动分类重要的现实意义。基于此背景,本发明将应用于裁判文书数据集,实现案由自动分类功能。采用的语料库是中国裁判文书网上手动采集的裁判文书,共有16个类别,共含中文裁判文书6974篇,其中训练集有文本4788篇,测试集有文本2186篇。对于中文裁判文书的预处理工作主要是中文分词及去停用词,考虑到噪声词汇带来的负面影响,特征提取利用了nlpir的词性标注功能,只提取其中的名词、动词以及形容词特征,其中名词中人名特征用于实体识别,此过程中滤除停用词593个,共提取26562个特征。分词工具采用的是汉语分词系统nlpir。在26562个特征组成的原始特征集合f中,对每一个特征,用ccmi文本特征选择方法得到它的评估值,并将每一个特征的评估值按从大到小的顺序进行排列,选取前k(k<26562)个最大评估值所对应的特征组成f的子特征空间集v,用相同的分类算法分别在f和v上进行分类实验,发现在v上的分类效果要优于在f上的分类效果,而且当k在13000左右时,分类效果最佳,分类精度比在f上分类精度要高出11%。本发明降低了法律文本语料库中原始特征空间的维度,提升分类精度和泛化效果。本发明提供了一种ccmi文本特征选择方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1