一种适用于指导关联算法并行化的分析方法、系统及装置与流程
本发明涉及并行分析技术领域,尤其涉及一种适用于指导关联算法并行化的分析方法、系统及装置。
背景技术:
现有的dot模型的不足之处在于:(1)假设资源是无限的,缺乏现实意义,没有对运行时间成本等进行说明;(2)没有对全局访问数据做矩阵形式化描述;
而p-dot模型的不足之处在于:(a)在时间成本描述上没有考虑因处理器有限带来的任务排队开销;(b)在迭代算法计算过程中的计算节点作为资源调整单位粒度过大,且不够实时灵活。
现在的关联算法并行化缺乏指导模型,且缺乏并行架构内部开销的形式化描述和分析,即网络通信开销、数据及任务加载开销等。
技术实现要素:
为了解决上述技术问题,本发明的目的是提供一种描述更全面,适用于指导关联算法并行化的分析方法、系统及装置。
本发明所采取的技术方案是:
一种适用于指导关联算法并行化的分析方法,包括以下步骤:
根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
对并行化算法模型进行性能分析。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,还包括以下步骤:
根据性能分析的结果,判断其是否满足预设的要求,若是,则不再进行优化计算;反之,则再次对并行化算法模型进行迭代优化。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,所述的根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,这一步骤具体包括:
根据预设的sdgot模型优化原则的矩阵表达形式,判断关联算法中是否有不必要的数据扫描或重复操作,若是,则按照dot模型所给策略进行合并;
判断关联算法中是否存在迭代场景,若是,则按照p-dot模型所给的策略,对不同迭代阶段的问题规模,动态调整分区数目;
判断关联算法中是否存在全局访问数据,若是,则根据数据大小或计算复杂度对其进行分布式缓存或广播操作,得到并行计算模型。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,所述的对并行化算法模型进行性能分析,这一步骤具体包括:
根据并行化算法模型,计算总计算复杂度和总通信复杂度;
根据总计算复杂度和总通信复杂度,计算得到时间成本函数;
根据时间成本函数,计算模型效率、问题规模和额外开销时间。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,进行分布式缓存后得到的并行计算模型为:
进行广播操作后得到的并行计算模型为:
其中,gi(i=1,2,…,n)表示分布式缓存,gg表示全局只读变量,矩阵d[d1d2…dn]表示n个工作节点中的分区数据,矩阵o表示n个工作节点执行并发操作,矩阵t表示并行数据传输矩阵,tm,n表示第n个节点第m个分区的数据,tm表示第m个分区的数据。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,所述总计算复杂度的计算公式为:
φ∑cp=p×o(w/na+na);
所述总通信复杂度的计算公式为:
φ∑cm=p×o(na);
其中,φ∑cp表示总计算复杂度,φ∑cm表示总通信复杂度,p表示处理阶段的数量,w表示取任务初始的问题规模,na表示任务中多次迭代分区数目的平均值,o(na)表示矩阵o(na),o(w/na+na)表示矩阵o(w/na+na)。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,所述时间成本函数的计算公式为:
φt=φ∑cp+φ∑cm=p×o(w/na+na)+p×o(na)=p×o(w/na+2na);
其中,φt表示时间成本函数,o(w/na+2na)表示矩阵o(w/na+2na)。
作为所述的一种适用于指导关联算法并行化的分析方法的进一步改进,所述模型效率的计算公式为:
e=1/(1+t0/w);
所述问题规模的计算公式为:
所述额外开销时间的计算公式为:
其中,e表示模型效率,w表示问题规模,t0表示额外开销时间,tie表示并行系统第i个处理器的有效计算时间、tio表示并行系统第i个处理器的额外开销时间,k表示处理器数量。
本发明所采用的另一个技术方案是:
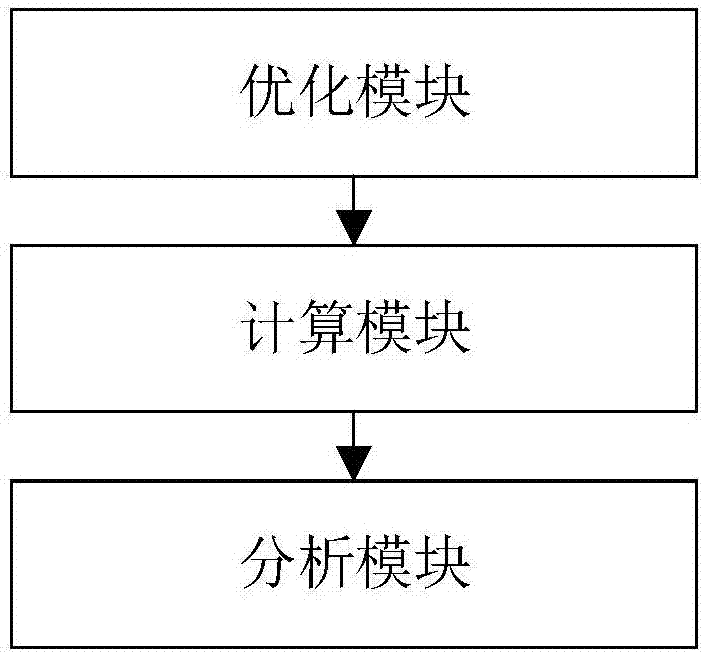
一种适用于指导关联算法并行化的分析系统,包括:
优化模块,用于根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
计算模块,用于对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
分析模块,用于对并行化算法模型进行性能分析。
本发明所采用的再一个技术方案是:
一种适用于指导关联算法并行化的分析装置,包括:
存储器,用于存放程序;
处理器,用于执行所述程序以用于:
根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
对并行化算法模型进行性能分析。
本发明的有益效果是:
本发明一种适用于指导关联算法并行化的分析方法、系统及装置,利用优化设计的sdgot模型提供的时间成本函数对并行架构内部开销如数据加载、任务排队和数据通信开销进行形式化描述,弥补了以往分析并行算法时不能量化这几类开销的不足,解决了算法在并行计算过程中的并行架构内部开销的量化问题。而且本发明对关联算法的并行计算设计提供设计、优化和分析等系列参考方案,加快智能时代中利用关联算法检测相关事物的速度,满足消费市场价格分析、网络安全领域的入侵检测技术、运维告警分析等高性能计算要求。
附图说明
下面结合附图对本发明的具体实施方式作进一步说明:
图1是本发明一种适用于指导关联算法并行化的分析方法的步骤流程图;
图2是本发明一种适用于指导关联算法并行化的分析系统的模块方框图。
具体实施方式
参考图1,本发明一种适用于指导关联算法并行化的分析方法,包括以下步骤:
根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
对并行化算法模型进行性能分析。
进一步作为优选的实施方式,还包括以下步骤:
根据性能分析的结果,判断其是否满足预设的要求,若是,则不再进行优化计算;反之,则再次对并行化算法模型进行迭代优化。
其中,当性能分析的结果满足预设的要求时,表示当前的并行化算法模型已符合要求,不需再进行优化;反之,则表示并行化算法模型还不符合要求,需要继续迭代优化。
进一步作为优选的实施方式,所述的根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,这一步骤具体包括:
根据预设的sdgot模型优化原则的矩阵表达形式,判断关联算法中是否有不必要的数据扫描或重复操作,若是,则按照dot模型所给策略进行合并;
判断关联算法中是否存在迭代场景,若是,则按照p-dot模型所给的策略,对不同迭代阶段的问题规模,动态调整分区数目;
判断关联算法中是否存在全局访问数据,若是,则根据数据大小或计算复杂度对其进行分布式缓存或广播操作,得到并行计算模型。
进一步作为优选的实施方式,所述的对并行化算法模型进行性能分析,这一步骤具体包括:
根据并行化算法模型,计算总计算复杂度和总通信复杂度;
根据总计算复杂度和总通信复杂度,计算得到时间成本函数;
根据时间成本函数,计算模型效率、问题规模和额外开销时间。
进一步作为优选的实施方式,进行分布式缓存后得到的并行计算模型为:
进行广播操作后得到的并行计算模型为:
其中,gi(i=1,2,…,n)表示分布式缓存,gg表示全局只读变量,矩阵d[d1d2…dn]表示n个工作节点中的分区数据,矩阵o表示n个工作节点执行并发操作,矩阵t表示并行数据传输矩阵,tm,n表示第n个节点第m个分区的数据,tm表示第m个分区的数据。
进一步,当指导算法为迭代类型时,则上述矩阵表示某次迭代的计算模型。上述两个矩阵中,前一个矩阵中分布式缓存,g分为n部分,后一个矩阵是广播变量,g相当于复制多份并分发到各个节点中。
进一步作为优选的实施方式,所述总计算复杂度的计算公式为:
φ∑cp=p×o(w/na+na);
所述总通信复杂度的计算公式为:
φ∑cm=p×o(na);
其中,φ∑cp表示总计算复杂度,φ∑cm表示总通信复杂度,p表示处理阶段的数量,w表示取任务初始的问题规模,na表示任务中多次迭代分区数目的平均值,o(na)表示矩阵o(na),o(w/na+na)表示矩阵o(w/na+na)。
进一步作为优选的实施方式,所述时间成本函数的计算公式为:
φt=φ∑cp+φ∑cm=p×o(w/na+na)+p×o(na)=p×o(w/na+2na);
其中,φt表示时间成本函数,o(w/na+2na)表示矩阵o(w/na+2na)。
进一步作为优选的实施方式,所述模型效率的计算公式为:
e=1/(1+t0/w);
所述问题规模的计算公式为:
所述额外开销时间的计算公式为:
其中,e表示模型效率,w表示问题规模,t0表示额外开销时间,tie表示并行系统第i个处理器的有效计算时间、tio表示并行系统第i个处理器的额外开销时间,k表示处理器数量。
参考图2,本发明一种适用于指导关联算法并行化的分析系统,包括:
优化模块,用于根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
计算模块,用于对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
分析模块,用于对并行化算法模型进行性能分析。
本发明一种适用于指导关联算法并行化的分析装置,包括:
存储器,用于存放程序;
处理器,用于执行所述程序以用于:
根据预设的sdgot模型优化原则,对关联算法进行并行化优化处理,得到并行计算模型;
对优化后的并行计算模型进行并行计算,并进行并行化迭代优化,得到并行化算法模型;
对并行化算法模型进行性能分析。
本发明实施例中,基于spark计算框架,结合dot模型和p-dot模型,本发明从apriori算法角度抽象出sdgot并行计算模型,主要解决全局数据在迭代计算场景中的访问问题,其中全局数据包括静态数据和动态数据。
本发明预设的sdgot模型包含了spark计算框架的主要特性,采用矩阵形式描述了待处理数据集、全局数据、并行数据操作和并行数据传输等关系,可以对基于spark计算框架的常见关联算法并行化过程及其优化提供形式化描述方案。区别于dot模型中描述的大数据计算模型场景,sdgot模型借鉴apriori算法的设计与实现,做了如下修改:
dot模型中的d表示分布在各个工作节点的数据,例如输入数据d分成n个子数据集,则d1到dn分别分布在n个工作节点中。sdgot模型中,d表示分区数据,此时输入数据d分成n份的时候,表示d1到dn不一定均匀地分布在m个工作节点,其中m可以不等于n。
dot模型中的o表示n个工作节点执行并发操作,彼此之间没有数据依赖,计算单位是工作节点。sdgot模型中,o表示n个处理器执行并发操作,彼此之间可能存在数据依赖,计算单位是处理器或核,具体取决于工作节点是否为逻辑多核。
dot模型中没有对计算过程中的全局数据进行形式化描述。sdgot模型中,增加了g表示计算过程中o访问的全局数据,其具体含义为,在算法执行过程中,例如apriori算法的迭代过程,需要访问动态全局数据候选项集和静态全局数据事务数据库,此时g表示分布在各个节点的全局数据,表现形式可以是各个节点中的分布式缓存数据,也可以是各个节点中的多备份全量数据。
对比dot模型,sdgot模型从各个定义和概念上,针对spark计算框架特点以及关联算法实践过程中的表现,都进行了适当的完善。主要体现在:
数据粒度由大到小,并且可以借助sparkapi提供更丰富的实践策略;例如shuffle操作、计算过程中的分区数目调整操作等。
处理单位从工作节点变为处理器,实现了更加合理、更加灵活的计算资源配置,并且利用spark固有的api,实现了dot模型从概念到落地的快速转换,为原有模型提供了更加丰富的潜在的改进方案。同时,对于p-dot模型,也实现了不同阶段计算资源的自由配置,而不局限于需要通过调整工作节点数目的方案来提高任务运行,同时提供了更快速的资源调整优化操作,如通过现有算子对分区数目的调整比对工作节点数目的调整要更加快速。
处理数据从批处理到迭代处理,再到引入全局数据的形式化表示,对以往相关模型进行了完善,使模型可以表示更多问题场景。
所以,sdgot模型不是从概念上对dot模型进行简单改造,而是从现有的并行算法设计和实践中提取的适用于实际场景的有效模型。
p-dot模型对dot模型中内存无限的假设做了限定,并通过时间成本函数描述了机器数目与问题规模之间的关系,但是其中没有对处理器数目和问题规模之间的关系进行描述,即评估了有限内存而忽略了有限核数的情况。基于spark计算框架的sdgot模型在描述计算复杂度的同时,考虑了在给定处理器数目的前提下,任务的并行分区数目过大所带来的影响,并相应地给出形式化描述。
基于spark计算框架,结合dot模型和p-dot模型,本发明提出了sdgot模型,以补充dot模型中关于迭代算法场景中静态数据的重复性访问的情况。sdgot模型中的g指代迭代计算中每次待访问的静态数据,其余的变量满足dot模型中的描述。
sdgot模型的一般矩阵形式表示如下:
在sdgot模型中,g可以根据使用场景灵活使用,作为分布式缓存gi(i=1,2,…,n)或全局只读变量gg存放在各个工作节点。对于操作矩阵o,可以根据使用场景表示为普通矩阵或对角矩阵,如在某些并行算法中,矩阵o作为对角矩阵存在,矩阵t则作为普通矩阵存在,这都可以依据具体场景进行灵活设定。普通矩阵或对角矩阵的设定依据主要是查看步骤中是否存在shuffle操作,如类似map操作则采用对角矩阵表示,如类似reduce操作则采用普通矩阵表示。
根据上面的表示,对于使用分布式缓存存储事务数据库的算法的某次迭代,sdgot模型的矩阵形式表示如下:
同理,对于使用广播变量存储事务数据库的算法的某次迭代,sdgot模型的矩阵形式表示如下:
本发明中基于常见关联算法的sdgot模型的时间复杂度由计算复杂度和时间复杂度组成,下面对其相关定义进行说明。假设某个进行频繁项集挖掘的计算任务由p个处理阶段组成,w1为初始输入数据规模,wq为对应阶段q的输入数据规模,nq为对应处理阶段q的分区数目,其中q∈[1,p]。
定义1对于sdgot模型表示的关联算法计算任务,在每个迭代阶段的计算操作o和通信操作t,其处理数据为常数,所以其时间复杂度也为常数。此外,全局数据在缓存和广播时,由于处理数据规模为常数,所以它的计算复杂度也是常数,表示为o(1)。
引理1根据sdgot模型中关于计算部分的形式化描述,如式子(1)所示,计算部分包括集群节点的数据加载、基于节点的分区计算以及基于分区的线程计算。由于数据在加载的时候已经固定为常数,所以每个节点的计算时间为o(1)。由于分区内的每个任务处理数据固定为常数,所以每个任务的计算时间为o(1)。
定义2对于一个能用sdgot模型表示的并行关联算法,处理阶段q主要分为合并和剪枝操作,则wq表示处理阶段q候选集输入和频繁集输入,其中q∈[1,p]。在大多数任务中,输入数据固定,分配给每个分区的数据大小在数量级上相同,即o(wq/nq)=o(wq+1/nq+1)。在少数组合数据大量增长情况下,当wq变化的时候,可以适当调整处理阶段q内的分区数目nq使等号成立,这时有nq∈[ne,nx],其中ne表示执行器数目(默认同工作节点数),nx表示最大分区数目。
定义3对于一个能用sdgot模型表示的并行关联算法,它的时间成本函数的限制条件包括问题规模、工作节点内存大小、工作节点处理核数、分区数目、执行器数目、每个执行器包含的处理核数等。本发明默认执行器数目与工作节点数目相同,分区数目取多次迭代的平均值,某个处理阶段的问题规模wq和初始数据输入规模相同。
从工作节点的资源粒度来看,如果在任务开始或shuffle阶段,输入数据超过内存大小,则分k次加载。此时,在处理阶段q有
其中m为阶段内存大小,是常数,此时有o(kql)=o(wq/nq)。此时有式子(3),如下:
从工作分区的资源粒度来看,由于spark计算框架使用容器(container)作为资源的抽象,即容器将内存、核数等资源抽象出来作为一个单位提供给执行器运行任务,每个执行器里面可以运行多个任务(task),多个任务共享容器里面的资源,一个任务运行结束,容器不释放资源,下一个任务接着运行,所以基于工作分区的并行上面,当分区数目大于集群总共的可利用处理核数目的时候,任务需要分多次加载。此时,在处理阶段q有
其中,每一个分区(partition)对应一个任务,每个执行器的处理核心数目nc是常数,nr为分区数目,同nq,ne是执行器数目,在standalone模式下默认同工作节点数目,假设分区数目取平均值na,此时有o(kqe)=o(na),q∈[1,p]。从实践角度看,分区数目多于可利用核心数目,计算任务需要分kqe次进行加载计算,并以fifo或fair方式进行调度,kqe的数目与分区数目nr、执行器数目ne以及每个执行器的处理核心数目nc有关。另外,在集群管理器如hadoopyarn、apachemesos的管理下,如果某个节点的任务处理缓慢,等待任务可能被分配至其余执行器中运行。
所以,给定一个能用sdgot模型表示的大数据任务,根据引理1,它的节点内的数据加载和分区内的任务执行的操作都为o(1),结合kql和kqe的定义,sdgot模型在处理阶段q内的计算复杂度表示为:
φcp=kql×o(1)+kqe×o(1)=o(kql)+o(kqe)(5)
其中,在具体算法分析过程中,各个任务的执行时间需要根据相应的算法时间复杂度进行分析,如对详细的关联算法并行性能分析,这里根据引理1进行时间复杂度的分析。在q处理阶段的计算行为可以可做是一个kql×nq维的矩阵d、nql×nq维的矩阵g、nql×mq维的矩阵o进行相乘,由于全局数据gq或
根据矩阵运算规则,式子(5)表示了kql×n次乘法、kql×(n-1)次加法的运算。根据式子(3),模型中每一次的乘法表示di,j(i∈[1,kq],j∈[1,kql])和gi(i∈[1,nql])加载到相应的节点内存,并进行计算;每一次的加法表示数据的合并操作,并进行输出。根据定义1,由于处理数据固定,每个乘法和每个加法的开销都为o(1)。同时,由于乘法和加法都是在n个分区并行计算上,所以有
φcp=[kql×n×o(1)+kql×(n-1)×o(1)]/n+o(kqe)=o(kql)+o(kqe)(7)
同理,假设类似地从理论上分析得到处理阶段q内的通信复杂度为:
φcm=o(max(n,m))(8)
其中n和m为相邻阶段在数据通信时候的分区数目。从实际操作来看,如果发生shuffle操作,则数据从上一个阶段的n个分区传输至下一个阶段的m个分区,根据定义1,每个分区由于数据大小在数量级上为常数,所以在操作上其时间复杂度记为o(1)。由于通信时间和传输数据大小、传输分区数目有关,所以有φcm=o(1)×max(n,m)=o(max(n,m))。此外,在具体算法分析过程中,每个任务的操作时间还需要根据对应的算法时间复杂度进行分析,这里根据定义1进行时间复杂度的分析。
根据上述描述,关于sdgot模型在某个阶段的时间复杂度可以产生如下两条定理:
定理1对于一个能用sdgot模型表示的并行关联算法,假设该算法有p个处理阶段,则在q(q∈[1,p])处理阶段的计算复杂度为φcp=o(kql)+o(kqe),其中kql为q处理阶段数据全部加载到内存所需次数,kql为q处理阶段每个分区的任务数目。
定理2对于一个能用sdgot模型表示的并行关联算法,假设该算法有p个处理阶段,则在q(q∈[1,p])处理阶段的通信复杂度为φcm=o(max(n,m)),n,m∈[1,p],其中n和m为相邻阶段的分区数目。
根据定理1、式子(2)和式子(4),使用sdgot模型表示的任务的总计算复杂度为
以sdgot模型表示的apriori算法并行化为例,wq表示处理阶段q用于剪枝操作的候选集输入或用于合并操作的频繁集输入,其中q∈[1,p]。根据定义2,p×o(w/nx+na)<φ∑cp<p×o(w/ne+na),取任务初始的问题规模w和任务中多次迭代分区数目的平均值na,则
φ∑cp=p×[o(w/na)+o(na)]=p×o(w/na+na)(10)
从实际角度看,需要考虑中间输入结果过大、分区数目过小导致计算时间过长和分区数目过大导致网络开销过大的情况。同理,对于max(nq,nq+1),假定分区数目取多次迭代中的平均值,根据定理2、式子(8),使用sdgot模型表示的任务的总通信复杂度为
从实际角度看,需要考虑shuffle阶段分区组合问题。根据式子(10)和式子(11),使用sdgot模型表示的时间成本函数为
φt=φ∑cp+φ∑cm=p×o(w/na+na)+p×o(na)=p×o(w/na+2na)(12)
在传统的并行计算模型中,如bsp模型,主要通过纵向扩展来提升性能,但不能做到基于硬件的性能独立、基于中心的数据访问、持续性扩展以及高吞吐量。致力于解决大数据应用的并行计算模型如dot、p-dot通过横向扩展来提升性能,其中包含了两个关注点,第一是如何维持可扩展性,即保证当计算节点和数据规模的增长,数据处理能力也得到一定比例的增长;第二是如何提供强容错机制,即能快速移除错误计算节点,保证任务正常运行结束。研究可扩展性的主要目的是在确定问题规模及并行系统前提下,尽可能地有效利用大量的处理器,确定最优的处理器数目,达到最大的加速比,这对指导并行系统移植、并行算法改进都有着重要的意义。
对于一个大数据作业,可扩展性和容错性的具体定义如下:
定义2.1:可扩展性。可扩展性的定义从以下两个角度进行描述:(a)假设输入数据大小固定为n0,在每个迭代阶段,计算节点的数目以整数α的比例线性增长,作业的吞吐量也是线性增长的,直至每个计算节点的处理数据减至基本的并发数据处理单位。(b)假设输入数据大小初始值为n0,当输入数据以γ的比例增长时,此时输入数据大小为γn0,如果计算节点以α的比例增长,作业的总运行时间不变,则称该并行模型是可扩展的。
定义2.2:容错性。假设每个操作的处理数据都是可用的,如果在工作节点发生错误的情况下,作业仍能完成且生成正确的结果,即该结果与未发生错误的节点运行出来的结果是一致的,则称是可容错的。
简单来说,可扩展性是指在确定问题规模下,并行计算系统、算法或程序的性能随着处理器数目的增加而按比例提高的能力。可扩展性的主要影响因素为处理器数和问题规模,对应到分布式并行计算系统可以是指工作节点数目和输入数据大小,需要根据具体应用场景进行确定。kumar等人[16]提出的等效率函数对并行计算和并行架构提供了描述以及评估方案。本发明对等效率函数等概念的相关定义如下:
定义2.3:问题规模w。一个并行系统的问题规模指的是在单处理器上解决给定问题的最优串行算法的计算运行时间te,其中最优串行算法指的是已知的性能最好的串行算法。
定义2.4:额外开销o。一个并行系统的额外开销指的是并行算法对比单处理器上的最优串行算法所产生的其余开销,这些开销在串行算法中是没有的,如通信、同步以及空闲等待等。额外开销对应的时间记为to。
定义2.5:效率e。加速比s指的是并行算法(或并行程序)的执行速度相对于串行算法(或串行程序)的执行速度加快了多少,效率e指的是一个处理器的计算能力在并行计算中得到有效利用的比率,表示为e=s/k,其中k表示处理器数目。
定义2.6:等效率函数。假设tie、tio分别是并行系统第i个处理器的有效计算时间和额外开销时间,其中额外开销时间包括通信、同步以及空闲等待时间。te、t0、ptp分别为并行系统的有效计算时间、额外开销时间和并行算法运行时间,此时有
ptp=te+t0(2.1)
对应的效率公式为:
e=1/(1+t0/w)(2.2)
其中,开销时间t0表示为:
问题规模w为:
根据上式,假设问题规模w保持不变,处理器数目k增多,额外开销时间t0增大,效率e降低。为了使效率稳定,当处理器数目k增大时,相应地增大问题规模w的值,由此定义的在任务效率e不变的前提下,问题规模w随处理器数目k变化的函数,即为等效率函数。等效率函数的自变量为工作负载w和处理器数目k。
定理3.1对于一个能用sdgot模型表示的任务,假设输入数据d都是存放在永久性存储设备中,且有备用节点可供调度,则输入数据d一直处于可用状态。
定理3.2对于一个能用sdgot模型表示的任务,假设它是基于spark计算框架实现的,则失效数据可以通过谱系图(lineagegraph)重新计算某个分区的数据或在剩余节点自动重建,恢复因故障而丢失的数据,使任务能够最终完成。
可扩展性和容错性是大数据并行计算编程模型中的两项基本要求,sdgot模型的可扩展性和容错性证明如下:
定理3.3对于一个能用sdgot模型表示的并行关联算法具有可扩展性。
证明:根据式子1.12推导的时间成本函数,sdgot模型表示的任务的等效率函数为
根据等效率函数定义,为了维持效率e不变,则需要保持o(n2/w)的值不变,即输入数据规模w随着分区数目n的增长而变化,且是多项式的变化;假定计算节点数目的变化必然引发计算分区数目的变化,此时sdgot模型的等效率函数为o(n2),自变量为分区数目n。根据定义2.1,当问题规模w和分区数目n各自以一定比例增长,其总运行时间不变,证明完毕。
定理3.4对于一个能用sdgot模型表示的并行关联算法具有容错性。
证明:假设一个使用sdgot模型表示的任务在计算过程中有n1个工作节点和n2个分区。
(a)假设在o阶段有k11(1≤k11≤n1)个节点,在t阶段有个k12(1≤k12≤n1)节点失败,根据定理3.1,因为每个节点之间的数据操作没有依赖,且存放在永久性存储设备的数据随时可用(对于分布式文件存储系统hdfs存在多个副本),所以只要用新的节点代替失败的节点,并重新计算o层中失效的k11个节点、t层中的k12个节点的任务即可。
(b)假设在o阶段有k21(1≤k21≤n2)个分区,在t阶段有个k22(1≤k22≤n2)个分区失败,根据定理3.2,在分区内因故障而失败的任务将会通过谱系图重新计算,恢复失效的o层中的k21个分区数据和t层中的k22个分区数据,使任务能够最终完成。
综上,对于一个能用sdgot模型表示的并行关联算法是可容错的。证明完毕。
本发明结合spark关于分区的概念,对dot模型中的关于资源的使用提供了更细粒度和更加灵活的描述和控制,dot模型中的d表示分布在各个工作节点的数据,sdgot模型中的d表示rdd分区中的数据;dot模型中的o表示n个工作节点执行并发操作,计算单位是工作节点;sdgot模型中的o表示n个处理器执行并发操作,计算单位是处理器或逻辑单核;dot模型中没有对计算过程中的全局数据进行形式化描述,sdgot模型中g表示计算过程中o访问的全局数据。对p-dot模型中的时间成本函数增加了因处理器有限带来的任务排队时间成本;本发明提出的sdgot模型,提供了并行架构内部运行开销的说明,分别为数据加载开销、任务排队开销和数据通信开销,使基于该模型实现的算法在并行性能分析过程中具备更接近实际场景的描述和定位。
本发明的可扩展性和容错性的形式化描述和验证方案。其中,可扩展性利用了等效率函数,容错性利用了输入数据通过永久性存储的多备份特性容错、中间数据通过谱系图重新计算容错的证明思路。
从上述内容可知,本发明提出的sdgot模型相对dot模型优点如下:
增加了全局访问数据的矩阵形式描述,即增加了矩阵gi或gg,gi表示分布式缓存的全局访问数据,gg表示广播预加载到各个计算节点的全局访问数据;
基于spark计算框架扩展了dot模型关于并行计算资源的定义,使粒度更细,调整更加快速灵活。
本发明提出的sdgot模型相对对p-dot模型优点如下:
增加了因处理器有限带来的任务排队开销,其中p-dot模型仅考虑了因内存有限带来的数据加载开销;
类似对dot模型的扩展,本发明将dot模型和p-dot模型中,关于o的计算单位由计算节点调整为处理器,关于d的存储单位由计算节点调整为分区。此时,在迭代算法不同阶段,根据p-dot模型提出的优化方法,可以更加快速地通过调整分区数目来匹配处理数据大小,达到更快的运行速度。
本发明的提出sdgot模型,在面对分析并行算法的时间成本过程中,可以利用sdgot模型提供的时间成本函数对并行架构内部开销如数据加载、任务排队和数据通信开销进行形式化描述;弥补了以往分析并行算法时不能量化这几类开销的不足。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!