一种数据标签方法和装置与流程
本发明实施例涉及计算机大数据领域,尤其涉及一种数据标签方法和装置。
背景技术:
随着大数据逐步走过了探索阶段、市场启动阶段,大数据已经进入从概念到实际应用的关键转折期。大数据在接受度、技术、应用等各个方面趋于成熟,开始步入产业的快速发展阶段。大数据巨大的应用价值带动了大数据行业的迅速发展。
随着各类行业大数据整合的逐步推进,许多问题有待解决,如:如何从海量数据中有效提炼有效信息和整合数据?如何基于已有的数据分析技能自助式地灵活分析和应用知识?如何将自身业务经验数字化,将经验转化为知识?数据分析人员如何基于业务经验积累进行数据创新和迭代优化?数据不等于知识,如果缺乏有效的“知识”提炼和整合,用户将快速淹没在海量数据中。因此,一种可以从海量数据中有效提取和整合数据,并以标签形式为基础构建的管理工具有待提出。
技术实现要素:
本发明实施例提供了一种数据标签方法和装置,以实现对海量数据的提炼和整合和标签化处理。
第一方面,本发明实施例提供了一种数据标签方法,包括:
获取海量行为日志数据;
从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性;
依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合;
将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。
第二方面,本发明实施例还提供了一种数据标签装置,包括:
数据获取模块,用于获取海量行为日志数据;
数据提取模块,用于从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性;
数据整合模块,用于依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合;
数据打标模块,用于将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。
本发明实施例通过获取海量行为日志数据,从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性,并依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合,将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。实现了对海量数据的提炼、整合和标签化处理,可以帮助业务人员通过数字化手段加深对数据的理解、刻画及精准识别。
附图说明
图1为本发明实施例一中的一种数据标签方法的流程图;
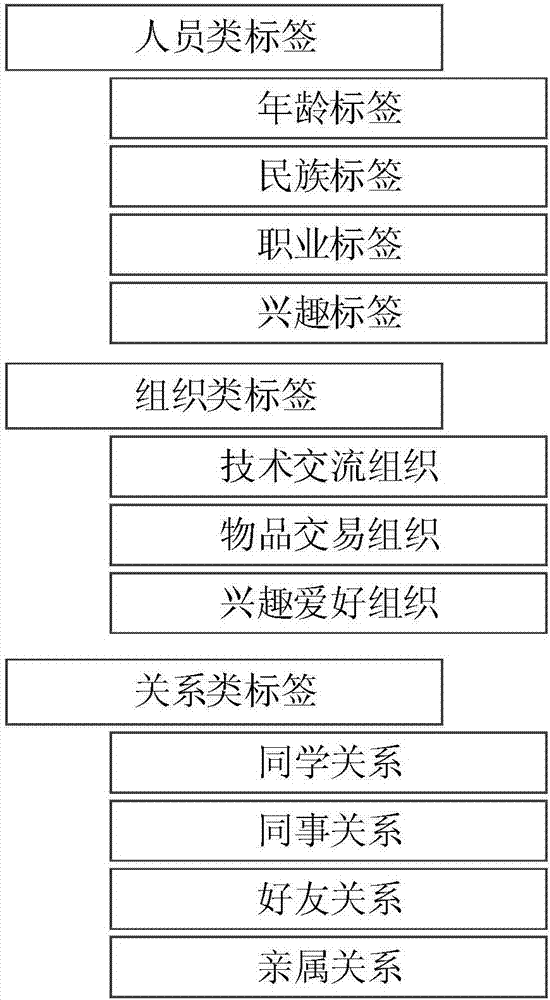
图2为本发明实施例一中的一种标签分类组织图;
图3为本发明实施例二中的一种数据标签方法的流程图;
图4为本发明实施例三中的数据处理的完整过程图;
图5为本发明实施例三中的流式环节的初始化过程图;
图6为本发明实施例三中的离线环节的初始化过程图;
图7为本发明实施例三中的数据提取和整合功能组成图;
图8为本发明实施例三中的数据提取过程图;
图9为本发明实施例三中的数据整合过程图;
图10为本发明实施例三中的数据提取和整合的处理流程图;
图11为本发明实施例三中的数据标签计算的功能组成图;
图12为本发明实施例三中的数据标签计算的技术实现图
图13为本发明实施例三中的数据标签计算的处理流程图;
图14为本发明实施例三中的数据入库的功能组成图;
图15为本发明实施例四中的一种数据标签装置的结构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一中的一种数据标签方法的流程图,本实施例可适用于对数据进行标签处理的情况,该方法可以由一种数据标签装置来执行,具体包括如下步骤:
步骤110、获取海量行为日志数据。
具体的,当前大多数网络应用或设备每天都会产生大量的行为日志数据,首先获取这些海量的行为日志数据,为后续的数据处理做准备。
步骤120、从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性。
在本实施例中,行为主体为上述网络应用或设备的使用者,如应用的账户或群号码等。
具体的,各行为主体的标识以及属性可以通过提取策略来实现,所述提取策略为根据不同的数据预先设置的提取规则,可以自行设置。
步骤130、依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合。
具体的,同一行为主体标识的属性的合并可以通过整合策略来实现,形成一个更为完整和序列化的信息集合,所述整合策略为根据不同类型的数据预先设置的整合规则,可以自行设置。
步骤140、将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。
需要说明的,还可以将各行为主体的属性集合和/或行为日志数据与预设的标签规则进行匹配。
在本实施例中,所述标签规则为标签的存储格式,可以包括:标签id、标签类别、标签名称、规则条件、创建人员、创建时间、使用状态以及备注说明等,所述标签规则可以在知识库中进行设置,且采用普通关系型数据库进行存储管理,例如:mysql、oracle等数据库。
所述知识库主要用于标签规则设置,是用户将业务经验转化为标签的技术手段之一。用户在添加标签规则时,可以引用知识库。本实施例中知识库包括:人员类、物品类(比如:违禁物品、易燃易爆物品等)、地点类(盗窃高发地、易爆高发地)、关键词(黄色关键词)、网站及app库(黄色网站、翻墙工具)等。
示例性的,一个标签规则的内容组成如表1所示。
表1标签规则的内容组成示例表
具体的,在将各行为主体的属性集合与预设的标签规则进行匹配之前,首先要对标签进行分类,标签的分类组织采用两级分类的管理方式,具体的分类可以自行设置。示例性的,图2为一种标签分类组织图,其中标签先进行第一级分类,分为人员类标签、组织类标签和关系类标签,再对上述各第一级分类进行第二级分类,如人员类标签分为年龄标签、民族标签、职业标签和兴趣标签。
在本实施例中,在将各行为主体的属性集合与预设的标签规则进行匹配之前,还包括标签维护,所述标签维护具体包括上述标签分类和标签规则的增删改查。
具体的,将各行为主体的属性集合与预设的标签规则中的内容一一进行匹配,若与标签规则中的一个内容匹配上,则为相应的行为主体添加此内容的标签。一个行为主体可以添加多个标签规则中的内容标签,一个内容标签下也可以有多个行为主体。
需要说明的是,在为各行为主体添加标签后,还包括数据入库,所述数据入库可以对添加过标签后的各类数据进行存储,通过存储策略来设定数据的存储位置、存储周期、库表名称,存储策略可以自行设置。
需要说明的是,在为各行为主体添加标签后,还包括设置标签魔方,所述标签魔方可以实现通过标签快速筛选和查找对象数据的功能,根据标签信息获取中标对象信息。
本发明实施例通过获取海量行为日志数据,从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性,并依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合,将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。实现了对海量数据的提炼、整合和标签化处理,可以帮助业务人员通过数字化手段加深对数据的理解、刻画及精准识别。
实施例二
图3为本发明实施例二中的一种数据标签方法的流程图,本实施例在上述实施例的基础上,进一步优化了上述数据标签方法。相应的,如图3所示,本实施例的方法具体包括:
步骤210、获取海量行为日志数据。
步骤220、通过清洗策略对获取的行为日志数据进行清洗。
在本实施例中,对获取的行为日志数据进行清洗是对数据的预加工处理,可以通过清洗策略来实现,所述清洗策略为根据不同的数据预先设置的清洗规则,可以自行设置。
步骤230、从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性。
步骤240、依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合。
步骤250、将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。
在本实施例中,对行为主体添加标签的方式包括基于行为主体的基本信息、基于不同行为主体之间的关联关系和基于行为主体的行为信息,当基于不同行为主体之间的关联关系进行标签的添加时,执行步骤251;当基于行为主体的基本信息进行标签的添加时,执行步骤252;当基于行为主体的行为信息进行标签的添加时,执行步骤253。
步骤251、基于不同行为主体之间的关联关系进行标签的添加。
对数据基于不同行为主体之间的关联关系进行标签添加的具体步骤包括:
步骤2511、依据各行为主体的属性集合确定不同行为主体之间的关联关系。
具体的,所述不同行为主体之间的关联关系包括存在关联和不存在关联,存在关联时具体的关联关系类型可以有很多种。
需要说明的是,不同行为主体之间的关联关系还可以直接从行为日志数据中提取。
步骤2512、将不同行为主体之间的关联关系与预设关联关系标签中的关系类型进行匹配,并依据匹配结果确定不同行为主体的关联关系标签。
具体的,当不同行为主体之间存在关联时,将此关联关系与预设的关联关系标签中的关系类型进行匹配,判断是否匹配成功,若与一种关系类型匹配成功,则为相关的行为主体添加此关联关系的标签。
步骤252、基于行为主体的基本信息进行标签的添加。
对数据基于行为主体的基本信息进行标签添加的具体步骤包括:
步骤2521、依据各行为主体的属性集合确定各行为主体的基本信息。
在本实施例中,所述行为主体的基本信息包括行为主体的文本类基本信息和非文本类基本信息,若行为主体的基本信息为文本类基本信息,则执行步骤2522;若行为主体的基本信息为非文本类基本信息,则执行步骤2523。
步骤2522、将各行为主体的文本类基本信息与预设的关键词标签规则中的关键词进行匹配,并依据匹配结果确定各行为主体的关键词标签。
具体的,将各行为主体的文本类基本信息与预设的关键词标签规则中的关键词进行匹配,所述匹配通过关键词匹配算法进行,具体的算法可以自行设置。若与一个关键词匹配成功,则对相应行为主体添加此关键词的标签。
步骤2523、将各行为主体的非文本类基本信息与数据属性标签规则中的字段取值进行匹配,并依据匹配结果确定各行为主体的数据属性标签。
具体的,将各行为主体的非文本类基本信息与数据属性标签规则中的字段取值进行匹配,若行为主体的字段取值符合一种数据属性标签规则条件,则匹配成功,对相应的行为主体添加此数据属性标签。
步骤253、基于行为主体的行为信息进行标签的添加。
对数据基于行为主体的行为信息进行标签添加具体步骤包括:
步骤2531、依据各行为主体的属性集合确定行为主体的行为信息。
在本实施例中,所述行为主体的行为信息反应行为主体的行为规律,首先确定上述行为信息。
步骤2532、将行为主体的行为信息与预设行为规律标签中的行为规律特征进行匹配,并依据匹配结果确定行为主体的规律标签。
具体的,将行为主体的行为信息与预设行为规律标签中的行为规律特征进行匹配,若行为主体的行为信息符合预设的一个规律标签中的行为规律特征,则匹配成功,并对相应的行为主体添加此规律标签。
本发明实施例通过获取海量行为日志数据,并对数据进行清洗,从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性,并依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合,将各行为主体的属性集合与预设的标签规则进行匹配,并基于行为主体的基本信息、基于不同行为主体之间的关联关系和基于行为主体的行为信息的方式为各行为主体添加标签。实现了对海量数据的提炼、整合和不同方式的标签化处理,可以帮助业务人员通过数字化手段加深对数据的理解、刻画及精准识别。
实施例三
上述各实施例的基础上,本实施例提供具体地对数据标签方法基于spark计算框架进行进一步说明。
spark计算框架是一个基于内存计算的开源的分布式集群并行计算框架,是一种快速处理大规模数据的通用引擎。spark将中间数据放到内存中,对于迭代运算效率比较高。spark生态圈以sparkcore为核心,从hadoop分布式文件系统(hadoopdistributedfilesystem,hdfs)和hadoop分布式存储系统(hadoopdatabase,hbase)等持久层读取数据,以hadoop另一种资源管理器(yetanotherresourcenegotiator,yarn)为资源管理调度job完成spark应用程序的计算,主要包括:sparkshell/sparksumbit的批处理、sparkstreaming的实时处理应用、sparksql的即席查询、mlib/mlbase的机器学习、graphx的图处理和sparkr的数学计算等等。
示例性的,图4为本发明实施例三中的数据处理的完整过程图。如图4所示,数据处理的完整过程包括:开始、任务初始化过程、数据提取和整合、数据标签计算、数据入库和结束。
具体的,所述任务初始化过程在流式环节和离线环节有所不同,流式环节从kafka中读取数据然后逐条处理,离线环节从hdfs中读取数据,然后逐条处理。图5为本发明实施例三中的流式环节的初始化过程图,图6为本发明实施例三中的离线环节的初始化过程图。在本发明实施例中,通过sparkstreaming来完成海量数据的流式环节的处理,通过sparksumbit来完成海量数据的离线环节的处理。任务初始化完成后,流式环节和离线环节的数据提取和整合、数据标签计算以及数据入库的处理逻辑基本一致。
示例性的,图7为本发明实施例三中的数据提取和整合功能组成图。如图7所示,数据提取和整合包括从kafka读取数据、数据预加工处理、数据提取、数据整合和数据入库。
具体的,在kafka集群中缓存着各个前端接入多源异构数据,格式为key+value方式,key为namespace.dataset,value为结构化数据对应的protocolbuffer格式数据。这些数据将在spark的各个计算环节中传递和使用,先根据key获取相应的元数据,然后通过元数据来解释和处理protocolbuffer中的数据。
具体的,在数据预加工处理即数据清洗过程中,任务启动过程时加载dataclean.xml中的所有数据清洗策略内容到datacleanhashlist,根据从日志数据中得到的key(namespace+dataset)快速在datacleanhashlist中找到相应的清洗策略,根据策略中指定的各个字段进行判断,只有符合条件的数据才会传递到下一步骤进一步处理。
图8为本发明实施例三中的数据提取过程图。如图8所示,在数据提取过程中,任务启动过程时加载objectextract.xml中的所有数据提炼策略内容到objectextracthashlist中,根据上一步骤传递过来的key(namespace+dataset)快速在objectextracthashlist中找到相应的提取策略,根据策略中指定的源目标数据集及各个字段的提取方式进行提取,得到相应的各行为主体的标识以及各行为主体的属性。
图9为本发明实施例三中的数据整合过程图。如图9所示,在数据整合过程中,任务启动过程时加载objectmerge.xml中的所有对象数据归并策略内容到objectmergehashlist中,根据上一步骤传递过来的key(namespace+dataset)快速在objectextracthashlist中找到相应的整合策略,根据策略对同一类型的数据进行合并。
示例性的,图10为本发明实施例三中的数据提取和整合的处理流程图,反应数据提取和整合的具体处理流程。示例性的,图11为本发明实施例三中的数据标签计算的功能组成图,图12为本发明实施例三中的数据标签计算的技术实现图,图13为本发明实施例三中的数据标签计算的处理流程图。
具体的,在数据入库过程中,在任务启动过程时加载datastorage.xml中的所有数据存储策略内容到datastoragehashlist中,根据上一环节传递过来的key(namespace+dataset)快速在datastoragehashlist中找到相应的存储策略,根据策略中指定存储位置、存储周期、库表名进行存储。图14为本发明实施例三中的数据入库的功能组成图。
本发明实施例基于spark计算框架通过数据清洗、数据提取和整合、数据标签计算和数据入库,实现了对海量数据的提取、整合和实时/离线标签化处理,提高了处理速度和效率,可以帮助业务人员通过数字化手段加深对数据的理解、刻画及精准识别。
实施例四
图15为本发明实施例四中的一种数据标签装置的结构示意图。如图15所示,所述装置可以包括:
数据获取模块310,用于获取海量行为日志数据。
数据提取模块320,用于从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性。
数据整合模块330,用于依据提取得到的各行为主体的标识,将同一行为主体标识的属性进行合并,得到各行为主体的属性集合。
数据打标模块340,用于将各行为主体的属性集合与预设的标签规则进行匹配,并依据匹配结果为各行为主体添加标签。
进一步的,所述数据打标模块340包括:基本信息打标单元,具体用于:
依据各行为主体的属性集合确定各行为主体的基本信息;
将各行为主体的文本类基本信息与预设的关键词标签规则中的关键词进行匹配,并依据匹配结果确定各行为主体的关键词标签;
将各行为主体的非文本类基本信息与数据属性标签规则中的字段取值进行匹配,并依据匹配结果确定各行为主体的数据属性标签。
示例性的,所述数据打标模块340还包括:关联关系打标单元,具体用于:
依据各行为主体的属性集合确定不同行为主体之间的关联关系;
将不同行为主体之间的关联关系与预设关联关系标签中的关系类型进行匹配,并依据匹配结果确定不同行为主体的关联关系标签。
示例性的,所述数据打标模块340还包括:行为信息打标单元,具体用于:
依据各行为主体的属性集合确定行为主体的行为信息;
将行为主体的行为信息与预设行为规律标签中的行为规律特征进行匹配,并依据匹配结果确定行为主体的规律标签。
示例性的,所述数据提取模块320包括:
数据清洗单元,用于从获取的行为日志数据中提取得到各行为主体的标识以及各行为主体的属性之前,通过清洗策略对获取的行为日志数据进行清洗。
本发明实施例所提供的一种数据标签装置可执行本发明任意实施例所提供的数据标签方法,具备执行方法相应的功能模块和有益效果。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!