一种基于配置层的企业识别系统及其实现方法与流程
本发明涉及计算机应用技术领域,特别涉及一种基于配置层的企业识别系统及其实现方法。
背景技术:
随着国家信息化建设不断推进,多个地区已开展数据资源共享和整合的工作。但是,对于政务部门,仍存在多个系统共同工作,并且使用复杂的交互方式进行数据共享的现状。这种现状容易出现数据更新不及时,以及当某个系统停用了导致其他系统数据不更新的问题。以商务局使用的系统为例,企业信息是多个系统的核心内容。但由于企业信息属性多,并且存在变更的需要,一个企业存在的信息变更次数可能是上百次,变更过程还有可能出现人工误录入的场景,企业识别错误的情况会很容易导致围绕企业的其他功能出现问题。这时候就需要一种灵活度高和适用范围广的方法,可以对变更过或者更新不及时的企业信息进行识别,保证基于企业信息的其他功能正常运作。
技术实现要素:
本发明解决的技术问题之一在于针对商务企业数据存在数据更新不及时、数据不更新和数据经人工误录入等企业数据异常的问题,提供一种基于配置层的企业识别系统。
本发明解决的技术问题之二在于提供一种基于配置层的企业识别系统的实现方法;通过将企业数据识别通过配置层的方式分层处理,扩大识别的可操作范围,增加了识别的准确度。针对不同业务系统还可以选择合适的影响因子和每一层的置信区间,保障了企业识别场景的多样性。
本发明解决上述技术问题之一的技术方案是:
所述的系统由配置层和数据分离装置组成,并提供相应的开发和集成接口;
所述的数据分离装置,用于每个配置层的输入输出,对符合输入条件的企业数据接入下一层,对符合输出条件的企业数据返回初始数据来源;
所述的配置层,由来源管理层、因子关系层和数据识别层构成;
所述的来源管理层,管理待识别企业的数据来源,并对可识别的来源进行企业名称标记和二次处理;对处理结果符合来源管理层置信区间的数据接入因子关系层;
所述的因子关系层,根据影响企业识别权重的共有因子,对接入的数据进行权重比例分配以及相似度匹配,汇总的因子匹配数据为数据识别层提供计算依据;
所述的数据识别层,对汇总的因子匹配数据进行加权计算出总分,得出企业识别结果。
所述的来源管理层提供crud访问接口,用于接入和配置企业数据;
所述的因子关系层提供crud访问接口,用于查询和维护企业属性因子及其权重比例;
所述的数据分离装置提供crud访问接口,用于接入和输出层级之间交互的企业数据。
本发明解决上述技术问题之二的技术方案是:
所述的方法包括来源管理层、因子关系层和数据识别层配置;
所述来源管理层配置流程是:
s11,新建自定义识别流程,生成唯一标识流程id;
s12,选择企业数据库内存在的企业表,并标记企业名称属性;
s13,填写[0,100]区间范围内的任意区间作为来源管理层置信区间;
s14,保存识别流程;
s15,日志记录,完成;
所述因子关系层的配置流程是:
s21,选择已有的识别流程;
s22,选择识别流程内企业表共有的企业属性;
s23,对企业共有属性进行权重比例分配,分配比例值为[0,100]区间的任意值,默认值均为0;
s24,填写[0,100]区间范围内的任意区间作为因子关系层置信区间;
s25,保存识别流程;
s26,日志记录,完成;
所述数据识别层的配置流程是:
s31,选择已有的识别流程;
s32,选择数据识别的可接受范围:单笔识别或者多笔识别;
s33,保存识别流程;
s34,日志记录,完成。
所述的来源管理层识别流程具体是:
第一步,根据识别流程配置的企业名称属性提取配置表的所有企业名称;
第二步,对企业名称数据进行分词并提取高频词;
第三步,对每笔带企业名称的数据生成唯一企业id、筛选标志和名称备注栏位;
第四步,对企业名称栏位进行高频词过滤,并将过滤结果放入名称备注栏位;
第五步,根据每张企业表的名称备注栏位,对企业表进行备注名称的相似度匹配,得出[0,100]范围内的相似度,并根据来源管理层置信区间对符合条件的企业数据筛选标志置1,否则置0;
第六步,结束识别流程,接入数据分离装置;
第七步,日志记录,完成。
所述因子关系层识别流程是:
第一步,获取数据分离装置接入的企业标记数据;
第二步,根据配置的因子比例范围对不同表间同因子进行相似度匹配;
第三步,根据每张企业表的因子属性,对企业表进行属性的相似度匹配,得出[0,100]范围内的相似度,并根据因子关系层置信区间对符合条件的企业数据筛选标志置1,否则置0;
第四步,对标记为1的企业数据添加因子备注栏位,栏位属性为json格式数据,存储内容为{因子1:相似度1,因子2:相似度2,…因子n:相似度n};
第五步,结束识别流程,接入数据分离装置;
第六步,日志记录,完成。
所述数据识别层识别流程是:
第一步,获取数据分离装置接入的企业标记数据;
第二步,根据因子备注栏位以及权重比例进行加权累计,算出企业表间每笔企业记录对应其他表企业记录的权重总分;
第三步,根据数据识别层配置的识别范围,当选择单笔识别时,选出权重总分最高的一笔记录筛选标志置1,其他记录置0;当选择多笔识别时,对权重总分进行分类处理,高分数据标记为优类,低分数据标记为差类;对优类数据的筛选标志置1,其他置0;
第四步,结束识别流程,输出筛选标志为1的企业数据;
第五步,日志记录,完成。
本发明针对涉及企业数据的商务政务系统,来源管理层对企业数据进行标记和初次筛选,因子关系层动态维护企业表的关联权重,数据识别层根据权重比分得出最优数据集。各个配置层紧密结合,将企业识别形成动态可维护的识别链路,保证了系统的灵活性和扩展性。
附图说明
下面结合附图对本发明进一步说明:
图1是本发明的总体结构图;
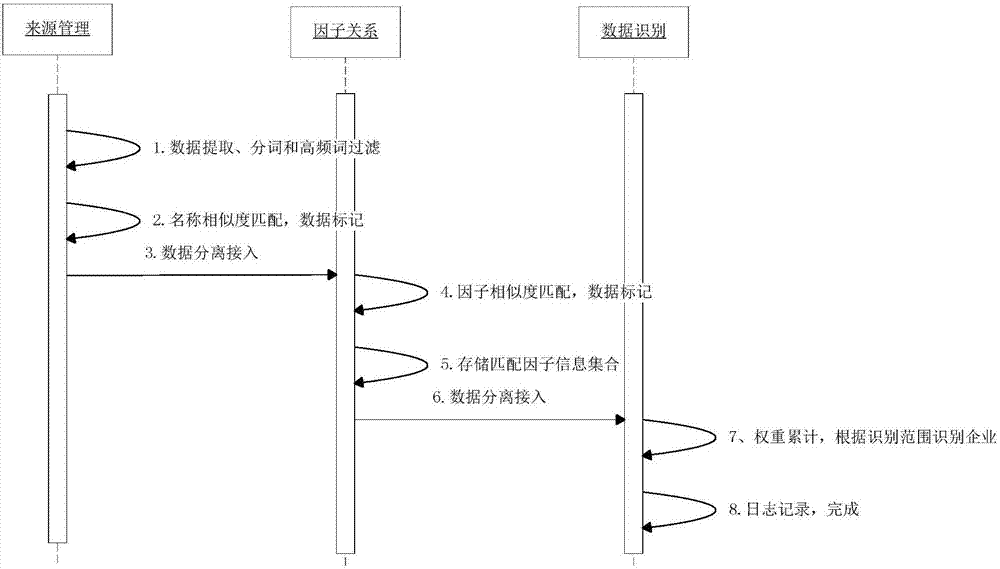
图2是本发明来源管理、因子关系和数据识别的序列图;
图3是本发明配置层配置信息维护的活动图。
具体实施方式
本发明解决的技术问题在于针对商务企业数据存在数据更新不及时、数据不更新和数据经人工误录入等企业数据异常的问题,提供了一种基于配置层的企业识别系统。通过将企业数据识别通过配置层的方式分层处理,扩大了识别的可操作范围,增加了识别的准确度。针对不同业务系统还可以选择合适的影响因子和每一层的置信区间,保障了企业识别场景的多样性。
图1表示了本发明的总体结构图,由配置层和数据分离装置组成,并提供相应的开发和集成接口;
配置层,由来源管理、因子关系和数据识别三层组成;
来源管理层,管理待识别企业的数据来源,并对可识别的来源进行企业名称标记以及名称备注栏位匹配;相似度匹配的规则是:当企业名称为“abcd”和“cd”两家企业进行匹配时,相似度标记为50;当企业名称为“abcd”和“bcd”两家企业进行匹配时,相似度标记为75;处理结果符合来源管理层置信区间的数据可接入因子关系层;因子关系层,根据影响企业识别权重的共有因子,对其进行权重比例分配以及相似度匹配,汇总的因子匹配数据为数据识别层提供计算依据;数据识别层,通过汇总的因子匹配数据进行加权计算出总分,得出企业识别结果;每个因子的权重分y=因子权重*相似度;权重总分为所有因子的权重分之和;数据分离装置,用于每个配置层的输入输出,对符合输入条件的企业数据接入下一层,对符合输出条件的企业数据返回初始数据来源。
此外,配置层还提供crud访问接口,用于接入和配置多个渠道的企业数据和维护企业属性因子及其权重比例。
图2表示了来源管理、因子关系和数据识别的序列图,图3表示了配置层配置信息维护的活动图,有关的实现步骤分别如下。
来源管理层识别的流程是:
第一步,根据识别流程配置的企业名称属性提取配置表的所有企业名称;
第二步,对企业名称数据进行分词并提取高频词;
第三步,对每笔带企业名称的数据生成唯一企业id、筛选标志和名称备注栏位;
第四步,对企业名称栏位进行高频词过滤,并将过滤结果放入名称备注栏位;
第五步,根据每张企业表的名称备注栏位,对企业表进行备注名称的相似度匹配,得出[0,100]范围内的相似度,并根据来源管理层置信区间对符合条件的企业数据筛选标志置1,否则置0;
第六步,结束识别流程,接入数据分离装置;
第七步,日志记录,完成。
因子关系层识别的流程是:
第一步,获取数据分离装置接入的企业标记数据;
第二步,根据配置的因子比例范围对不同表间同因子进行相似度匹配;
第三步,根据每张企业表的因子属性,对企业表进行属性的相似度匹配,得出[0,100]范围内的相似度,并根据因子关系层置信区间对符合条件的企业数据筛选标志置1,否则置0;
第四步,对标记为1的企业数据添加因子备注栏位,栏位属性为json格式数据,存储内容为{因子1:相似度1,因子2:相似度2,…因子n:相似度n};
第五步,结束识别流程,接入数据分离装置;
第六步,日志记录,完成。
数据识别层识别的流程是:
第一步,获取数据分离装置接入的企业标记数据;
第二步,根据因子备注栏位以及权重比例进行加权累计,算出企业表间每笔企业记录对应其他表企业记录的权重总分;每个因子的权重分y=因子权重*相似度;权重总分为所有因子的权重分之和;
第三步,根据数据识别层配置的识别范围,当选择单笔识别时,选出权重总分最高的一笔记录筛选标志置1,其他记录置0;当选择多笔识别时,对权重总分进行分类处理,高分数据标记为优类,低分数据标记为差类;对优类数据的筛选标志置1,其他置0;
第四步,结束识别流程,输出筛选标志为1的企业数据;
第五步,日志记录,完成。
来源管理配置流程是:
第一步,新建自定义识别流程,生成唯一标识流程id;
第二步,选择企业数据库内存在的企业表,并标记企业名称属性;
第三步,填写[0,100]区间范围内的任意区间作为来源管理层置信区间;
第四步,保存识别流程;
第五步,日志记录,完成。
因子关系层的配置流程是:
第一步,选择已有的识别流程;
第二步,选择识别流程内企业表共有的企业属性;
第三步,对企业共有属性进行权重比例分配,分配比例值为[0,100]区间的任意值,默认值均为0;
第四步,填写[0,100]区间范围内的任意区间作为因子关系层置信区间;
第五步,保存识别流程;
第六步,日志记录,完成。
数据识别层的配置流程是:
第一步,选择已有的识别流程;
第二步,选择数据识别的可接受范围:单笔识别或者多笔识别;
第三步,保存识别流程;
第四步,日志记录,完成。
本发明将企业识别进行分层处理,具有扩展性好、适用范围广等特点,可有效地应用于多种商务政务系统中。
- 还没有人留言评论。精彩留言会获得点赞!