随机化的间隙和振幅估计的制作方法
本发明涉及量子计算中的本征相位确定。
背景技术:
相位估计是一种对量子计算具有根本重要性的技术。其不仅针对shor(秀尔)因子分解算法中的指数加速是必要的,而且还是量子模拟中的二次性能改进的原因。相位估计的目标是估计与输入本征态相关联的本征值,或者更一般地,从本征值进行采样以支持输入状态向量。该过程通过使用以量子叠加准备的控制寄存器来工作,并且然后其本征值被寻求的酉被应用于被控制由控制寄存器的值指定的多次的系统。有几种方法可以执行这个过程,但它们之间的共同点是所有这些方法都需要至少一个量子位来控制该过程以及执行酉演化的受控变体的能力。
对外部控制的需求基本上限制了相位估计在现有硬件上的使用,这不仅是因为辅助(ancilla)量子位的额外成本,而且是因为受控操作通常比对应的不受控制的操作更难以执行。另一方面,如果这样的实验是可能的,则诸如未知rabi(拉比)频率的表征等很多任务可以使用二次地较少的实验时间和指数级更少的测量来执行。
技术实现要素:
本公开涉及用于酉或哈密顿算子的本征值和本征相位估计的量子方法和电路。将随机或伪随机酉应用于初始量子态,并且然后应用目标酉。然后应用随机或伪随机酉的逆,之后是所得到的量子态相对于初始状态的测量。测量结果用于提供贝叶斯估计的更新。通常,允许目标酉进行时间演化(对于哈密顿算子),或者在应用随机酉的逆之前多次应用目标酉。初始状态可以对应于零状态,但是可以使用其他初始状态。可以使用多个不同的随机或伪随机酉。应用包括确定控制图和确定时间相关的哈密顿量中的本征值间隙。
量子计算系统包括至少一个量子位和实现随机或伪随机酉以及实现随机酉的逆的对应的一组酉的一组量子电路。实现目标酉的量子电路耦合到实现随机酉的所选择的量子电路,使得目标酉被应用于对应的随机量子态。实现所选择的量子电路的逆的量子电路在对应的随机量子态演化以产生输出量子态之后被应用于至少一个量子位。测量电路耦合到至少一个量子位,以便接收和测量相对于至少一个量子位的初始状态的输出量子态。通常,使用贝叶斯估计使用测量的值来更新本征值或本征相位估计;但是也可以应用其他推断程序。
下面参考附图阐述本公开的这些和其他特征和方面。
附图说明
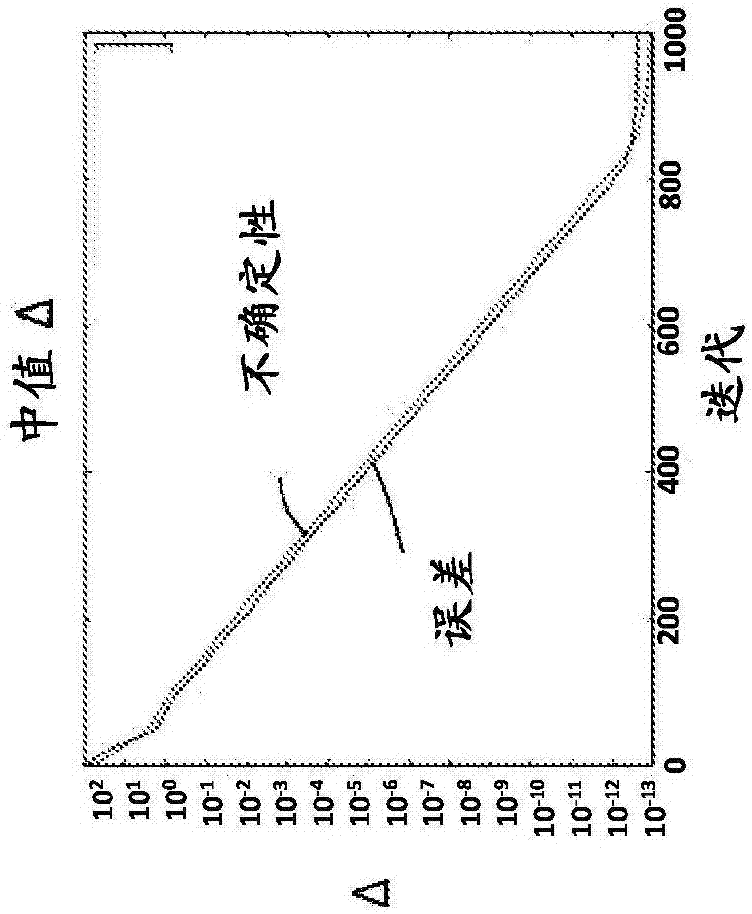
图1a至1c示出了在分别使用具有从高斯酉系综抽取的本征能谱的2级、3级和4级的哈密顿量的抑制滤波来确定哈密顿量本征相位中的间隙的中值误差和不确定性。
图2示出了估计本征相位间隙的代表性方法。
图3示出了用于估计本征相位间隙的代表性量子电路系统。
图4示出了基于时间演化哈密顿量的子空间来估计本征相位间隙的代表性方法。
图5示出了估计被应用于grover算子的本征相位间隙的代表性方法。
图6示出了确定控制图的代表性方法。
图7是包括用于随机化间隙图和振幅估计并且定义相关联的量子电路和操作的经典和量子处理代表性计算环境的框图。
图8示出了被配置为定义用于随机化间隙和振幅估计并且处理贝叶斯推断的量子测量的量子电路的代表性的经典计算机。
具体实施方式
本文中公开了可以用于在不需要辅助量子位的情况下学习未表征的设备中的能谱间隙的替代的相位估计方法。然而,由于这种间隙的数目通常随着系统中的量子位的数目而呈指数增长,所以所公开的方法通常应用于小型系统。所公开的方法和装置通常使用随机操作提取关于系统的基础动态的信息。还公开了用于就地振幅估计和量子器件校准的应用。
如在本申请和权利要求中所使用的,除非上下文另有明确说明,否则单数形式“一个(a)”、“一个(an)”和“该(the)”包括复数形式。另外,术语“包括(include)”表示“包括(comprises)”。此外,术语“耦合”不排除耦合项之间存在中间元素。
本文中描述的系统、装置和方法不应当被解释为以任何方式进行限制。相反,单独地并且以彼此的各种组合和子组合,本公开内容涉及各种公开的实施例的所有新颖和非显而易见的特征和方面。所公开的系统、方法和装置不限于任何特定方面或特征或其组合,所公开的系统、方法和装置也不要求存在任何一个或多个特定优点或者解决问题。任何操作理论都是为了便于解释,但是所公开的系统、方法和装置不限于这种操作理论。
尽管为了方便呈现而以特定的顺序次序描述了一些所公开的方法的操作,但是应当理解,除非下面阐述的特定语言需要特定排序,否则这种描述方式包括重新排列。例如,顺序描述的操作在某些情况下可以重新排列或同时执行。此外,为了简单起见,附图可能未示出所公开的系统、方法和装置可以与其他系统、方法和装置结合使用的各种方式。另外,该描述有时使用诸如产生和提供等术语来描述所公开的方法。这些术语是执行的实际操作的高级抽象。对应于这些术语的实际操作将根据具体实现而变化,并且本领域普通技术人员可容易地辨别。
在一些示例中,值、过程或装置被称为最低、最佳、最小等。应当理解,这样的描述旨在表明可以在很多使用的功能替代方案中进行选择,并且这种选择不需要更好、更小或以其他方式优选于其他选择。在一些示例中,酉算子(“酉”)被称为随机的,但是如本文中使用的,这种随机酉包括伪随机酉。酉具有振幅为1的本征值,但可以具有可以称为本征相位的各种相位。如本文中使用的,除非另有说明,否则本征值或本征相位差一般被称为本征值差。
下面公开了提供相位估计的方法和装置,其使用贝叶斯推断和随机实验来学习酉运算的能谱间隙而无需外部量子位或良好校准的门。还提供了所公开方法的若干应用,诸如振幅估计和控制图确定。
贝叶斯推断
贝叶斯推断可以用于从系统提取信息。贝叶斯推断的目标是在给定证据e和关于假设的一组先验信念的情况下计算假设为真的概率。这些先验信念被表示为在本文中称为先验的概率分布。这个先验以及证据e可以被认为是推断算法的输入。算法的输出是后验分布p(x|e),其由贝叶斯定理给出:
其中p(e|x)已知为似然函数。这个过程输出的后验分布然后被用作在线推断算法中的先验分布,并且使用贝叶斯定理生成新的先验分布的这个过程被称为贝叶斯更新。
如果p(x)在无限多个点上具有支持,则精确的贝叶斯推断通常是难以处理的并且可以使用离散化。这种离散化包括粒子滤波方法和顺序montecarlo(蒙特卡罗)方法。在所公开的示例中,使用抑制滤波器推断。抑制滤波器推断可以非常快速,易于并行化,并且可以使用比粒子滤波器或顺序montecarlo方法少得多的存储器来实现。
抑制滤波器推断使用抑制采样来执行更新。在这样的方法中,抑制采样用于将来自先验分布的样本系综转换为来自后验分布的较小样本集合。
具体地,如果观察到证据e并且从先验分布中抽取样本并且以等于p(e|x)的概率接受样本,则根据贝叶斯定理,假设x被接受作为样本的概率是:
p(e|x)p(x)∝p(x|e)(2)
因此,通过抑制滤波器的样本根据后验分布被分布。
尽管该过程允许从后验分布中采样,但是效率不高。平均而言,每次更新都会抑制恒定分数的样本。这表示,保留的样本数目将随着更新次数呈指数缩小。该过程可以通过以下方式变得更有效:将这些样本拟合到一个分布族并且然后从该模型分布中抽取一组新样本用于下一次更新。这种再生样本的能力允许抑制滤波推断以避免这种对后验的近似的支持的丧失。
存在很多可以考虑的用于先验和后验的模型。为方便起见,在本文中公开的一些示例中使用单峰高斯分布。也可以使用高斯混合模型,但是通过允许多模态先验和后验分布而提供的略微改进的稳定性通常不会补偿这种模型的增加的复杂性。
用于后验分布的高斯模型提供了很多优点。首先,它们通过后验均值和协方差矩阵进行参数化,其给出真实假设和相关联的不确定性的估计。此外,这些量通常易于从接受的样本估计并且可以递增地计算,以允许使用接近恒定的存储器来执行计算。
下面详细描述量子系统中的参数推断的若干应用,包括1)缺乏良好表征的门的量子系统的本征能谱估计,2)无辅助振幅估计,以及3)小量子器件的控制图学习。这个最后的应用在量子自举(bootstrapping)的上下文中令人关注,因为它提供了一种在自举协议开始时校准一组一个和两个量子位门的廉价方法。
随机间隙估计
用于学习哈密顿量的本征能谱的常规方法需要辅助量子位和良好表征的门。本文中公开了可以有效地估计没有辅助量子位并且可能使用表征不良的门的小系统的本征能谱的方法和装置。除了确定可表示为hermitian(厄米特)矩阵的哈密顿量或其他算子的本征能谱,可以为任意酉算子确定本征相位和本征相位之间的间隙。
随机间隙估计使用贝叶斯推断与随机演化一起来推断酉或其他算子的本征相位之间的间隙。在估计哈密顿算子h的本征值之间的间隙的一个示例中,第一步涉及准备预定状态,诸如:
其中|vk>是以任意顺序的对应于哈密顿算子h的本征值λk的本征向量,并且uj是随机酉。在等式(3)中,βk是未知参数,其不仅取决于所选择的随机酉,而且还取决于h的本征基(eigenbasis)。在这个示例中,状态|0>是为了方便使用,但是可以使用任何其他本征态组合。
对于低维度系统,已知根据haar(哈尔)测量均匀地抽取uj的精确方法。例如,对于单个量子位系统,uj具有欧拉角分解
uj=rz(φ)rx(θ)rz(ψ)(4)
直到不相关的全局相位。
接下来,允许状态|ψ>根据用户选择的t的e-iht进行演化。这导致了状态
e-iht|ψ>=e-ihtuj|0>(5)
为了评估任意酉v,代替时间演化(即,e-iht),向状态|ψ>应用酉v用户选择的次数m。
接下来,应用酉
更一般地,如果使用除了|0>之外的初始状态来评估应用m次的任意酉v(类似于允许哈密顿算子e-iht的时间演化),则测量和所得到的概率可以表示为:
其中|φ>是任意状态。然而,作为方便的示例,本文中通常参考e-iht描述间隙估计。
注意,由于βi和βj项未知,不能从该表达式容易地学习间隙δij=λi-λj。haar平均为这个问题提供了解决方案。
假定在电路中使用未知的haar随机酉uj,则测量0的似然由条件概率定律给出:
p(0|δ;t)=∫p(0|δ;t,u)μ(u)du,(7)
其中μ是对u(n)的haar测量。该概率不同于在用户知道或可能计算所使用的特定uj的p(0|h;t,uj)的情况下将使用的似然。
将δ定义为矩阵使得δi,j:=λi-λj,则haar平均值评估为
等式(8)提供可以用于执行贝叶斯推断的似然函数。具体地,贝叶斯规则指出,如果执行二元实验,其中只有两个结果是|0>和|υ≠0>,则后者以概率1-p(0|h;t)出现。如果将本征值的先验分布定义为p(λ),则假定记录测量值0,贝叶斯规则表明后验分布是
其中p(0)是归一化因子。因此,贝叶斯推断允许从这些实验中学习间隙。上面的算法1说明了以这种方式学习本征值间隙的代表性方法。
由于在(9)中观察到“0”的似然与n成反比,因此学习能谱所需要的实验数目应当至少随着n线性增长。cramér-rao(克拉美-罗)界限允许确定确保δij的方差足够小所需要的最小实验数目和/或实验时间。假设r个实验被执行,每个实验的结果为d∈o(1)和演化时间至少为t,则fisher(费希尔)矩阵的元素是
其通过使用cramér-rao界限表示在所有r个实验之后δij的任何无偏估计量的方差至少缩放为ω(n2/r2t2)。
虽然这表明学习间隙所需要的实验数目至少随着n线性增长,但最佳无偏估计量中的不确定性也收缩为ω(1/t),其中t是总的演化时间。因此,误差缩放比从统计采样预期的二次地较小。这为小量子器件提供了非常高精度频率估计的似然。
进一步的挑战是,不能从间隙中唯一地学习本征值。实际上,从间隙推断本征能谱相当于公知的收费公路(turnpike)问题,该问题具有0或2的整数幂个可能解,上限为o(n2.465)。但是,在典型情况下,最多有2个解。需要额外的实验来选择合适的解,但是间隙是明确确定的。
虽然预期推断问题对于大型系统而言变得快速难以处理,但是贝叶斯推断可以快速估计一个和两个量子位系统中的未知频率。图1a-1c示出了在分别使用具有从高斯酉系综抽取的本征能谱的2级、3级和4级的哈密顿量的抑制滤波来确定哈密顿量本征相位中的间隙中的中值误差和不确定性。如下所示,绝热演化可以用于在总的hilbert(希尔伯特)空间的子空间上应用haar随机酉以允许大量子器件的无辅助间隙估计。
估计与酉v的本征相位相关联的间隙的代表性方法200在图2中进一步示出。在202处,评估间隙估计的不确定性以确定间隙估计是否令人满意。如果间隙估计令人满意,则在204处返回间隙的后验。否则,在206处,准备诸如“0”状态等预定状态。在208处,向预定状态应用随机酉运算u。预定状态可以是“0”状态或可能方便的其他状态。在一些示例中,预定状态在一小组量子位中建立,通常少于2、4、8或10个量子位,但是可以使用更多数目的量子位。在210处,向预定状态应用m次酉v。如果酉基于哈密顿量h,则允许预定状态演化一段时间t,以有效地应用算子e-iht。
在多次应用v(或时间演化)之后,在212处,应用随机酉u的逆w,并且相对于预定状态测量所得到的状态。基于该测量,在214处,获取已更新先验。在202处,评估已更新先验,以确定是否需要额外的处理。
用于与图2的方法一起使用的代表性量子电路在图3中示出。多个量子位302以预定状态被准备并且耦合到量子电路304,量子电路304实现从一组随机酉306中选择的随机酉u。对于哈密顿量,量子电路输出的状态允许时间演化为e-iht,而其他酉v由一个或多个电路308应用m次。在310处,应用随机酉u的逆并且利用测量设备312测量量子位的状态。在314,经典或其他处理系统基于测量来执行贝叶斯推断。通过从集合306抽取不同的随机酉,可以多次重复电路300的操作。
本征值的绝热消除
量子计算中的大多数本征值估计任务集中于仅学习一部分能谱而不是所有本征值。如果可以仅在该子空间中应用haar随机酉运算,则可以使用随机间隙估计来获取能谱的一部分的本征值。由于哈密顿量的本征向量通常是未知的,所以难以直接这样做。尽管如此,绝热定理提供了一种方法,根据这种方法,通过采用绝热状态准备,可以将这些随机酉应用于适当的子空间。
假设要学习针对哈密顿量hp的给定子空间的能谱,直到加性常数。具体地,令
h(s)=(1-s)h0+shp。(11)
绝热定理表明,对于
等式(12)表明,如果在s0上执行haar随机酉,则所得到的状态可以绝热地变换为s中的haar随机状态,直到每个本征向量上的相位和误差o(1/t)。通过使用边界消除方法,这种误差缩放可以呈指数地改善。
令uj是作用于s0的haar随机酉。则用于估计本征相位的绝热协议是:
这里,
在时间t具有解
然后,使用hp|λj>=λj|λj>这一事实,从(13)和(15)可以明显看出
因此,如果在计算基础中为对角线的哈密顿量与问题哈密顿量之间存在间隙绝热路径,则可以使用绝热演化对本征值的指定子空间执行相位估计。代表性过程被示出为算法2。这表明,在可能进行这种绝热演化的情况下,可以克服困扰该方法的维度问题。
图4示出了对指定子空间的相位估计的方法400,示出了与图2的方法的相似性。在402,应用随机酉算子,但是该随机酉作用于指定子空间。在404处,基于绝热演化的哈密顿量来演化由随机酉产生的量子态,诸如上面的(12)至(15)所示。在406,应用随机酉的逆。
实现随机酉
上述方法和系统使用随机酉。在低维度系统中,有很多方法可以用于执行随机或伪随机酉运算。最直接的方法是利用u(n)的欧拉角分解来生成酉。例如,对于u∈su(2),这种酉可以实现为
u=rx(β)ry(γ)rz(δ)。(17)
为了根据haar测量来均匀地挑选这样的酉,足够的是,挑选根据以下概率密度函数选择的θ:=γ/2∈[0,π/2],φ:=(β+δ)/2mod2π∈[0,2π)知ψ:=(β-δ)/2mod2π∈[0,2π):
dp(φ,θ,ψ)=sin(2θ)dφdθdψ。(18)
这种构造对于更高维度的系统也是已知的。
实际上,haar随机酉矩阵难以在量子计算机上精确地实现。在未校准的设备中,这个任务可能更具挑战性。幸运的是,用于实现伪随机酉的有效方法是公知的。为方便起见,本文中简要描述了一些代表性方法。这里,我们使用dankert等人在physicalreviewa,0(1):012304(2009)中给出的t设计的定义,其中n维上的酉t设计被认为是一组有限的酉运算,使得在矩阵元素中至多t度和它们的复共轭中的至多t度的任何多项式函数的平均值与haar平均值相一致。具体地,令p(t,t)(uk)成为这样的多项式函数,并且假设在这个设计中有k个元素,则
其中μ是haar测量。
更一般地,还可以考虑∈近似t设计的概念。这个概念与t设计的不同之处在于,不需要严格的平等,并且允许在钻石距离中最多∈的差异。具体地,令
该定义表示,可以使用2设计找到项的haar期望值,因为所有这些项在uj的矩阵元素及其复共轭中是二次的。剩下的问题是如何形成这样的设计。
dankert等人提出,随机clifford(克利福德)运算可以分别用于形成成本为o(n2)和o(nlog(1/∈))的精确和∈近似2设计。这些结果在设备能够访问良好表征的clifford门的设置中是足够的。如果系统没有这样的门,则可以应用harrow和low的结果(参见harrow和low的randomquantumcircuitsareapproximate2-designs,communicationsinmathematicalphysics,291(1):257-302(2009)),以表明∈近似t设计可以从取自任何通用门集合的随机门序列中形成。这很重要,因为这个结果的成立不需要知道门。在这种情况下,生成这种伪随机酉所需要的门的数目是o(n(n+log(1/∈))),其中乘法常数取决于所使用的通用门集合的细节。
振幅估计
随机间隙估计还提供振幅估计的重要简化,振幅估计是量子算法,其中通过组合来自振幅放大和相位估计的想法来估计结果发生的概率。该算法很重要,因为它允许从montecarlo算法中学习答案所需要的查询数目的二次减少。
具体地,假设给定以下形式的未知量子态
其中
为了理解其如何工作,考虑grover搜索算子
qj|ψ>=sin([2j+1]θa)|φ>+cos([2j+1]θa)|φ⊥>,(21)
其中θa:=sin-1(a)。然后清楚的是,q在这个二维子空间中实现了旋转并且具有本征向量
其中
与其正交的空间中的所有其他本征向量具有本征值±1。
可以使用随机间隙估计找到这些相位。最重要的变化是,这里的t(对应于上面讨论的演化时间)必须被视为整数,因为尚未假设grover黑匣子的分数应用。(相比之下,哈密顿量的演化可以基于t的任意值。)在这种情况下,本征值在集合{-2θa,0,2θa,π}中,这表示|δi,j|取值{0,±2θa,4θa,π±2θa}。这表示,如果t是偶数或奇数,则间隙估计过程具有非常不同的似然。因为cos([π±2θa](2p+1))=-cos(2θa(2p+1)),对于整数p,如果t是奇数,则(8)中的很多项抵消。因此,针对这个应用,最好选择t为偶数,在这种情况下,似然函数为
根据(10),当n→∞时,这样的实验通常不特别适合,并且通常需要另外的方法来使大的n实例易于处理,除非根据haar测量的采样仅可以在相关的子空间内进行。
然而,在没有针对小n的修改的情况下,该方法非常适合。为了说明这一点,考虑n=2的情况,其中似然函数简化到
该似然函数仅产生比用于迭代相位估计p(0|θa;t)=cos2(2θat)的信息略少的信息,因为它们相对于θa的导数最多相差2/3倍。这一观察结果与不需要额外量子位的事实相结合表示,使用这种方法,可以在单个量子位器件中就地实际应用振幅估计(没有辅助)。
如图5所示,方法500包括在502对groves算子使用随机相位估计执行振幅估计。在504,找到不等于2的唯一本征值间隙,并且在506,返回本征值间隙的一半的正弦(sin)。
在大规模容错量子计算机中,预期额外的辅助量子位的成本最小,因此可能不需要这种方法。然而,目前这种辅助量子位价格昂贵,并且使用二次地较少的测量来学习振幅的能力可以是有价值的。
控制图学习
所公开的方法和装置的一个重要应用是量子器件的校准。为了理解为什么这可能是一个问题,想象一下要校准量子位,使得能够在误差10-5内执行x门。为了验证误差是这样小,需要进行大约1010次实验。对于系统中的每个量子位,也必须重复该过程,这很容易导致校准小的容错量子器件所需要的数太字节(terabyte)的数据。所公开的方法可以指数地减少控制这种量子位所需要的测量次数,并且多项式地减少所需要的实验时间。
作为示例,考虑学习控制图的问题。控制图被定义为一组实验控制(由矢量c指定)与系统哈密顿量之间的映射。具体地,如果我们对于一组哈密顿量hi定义
x=gc+x0,(26)
其中矩阵g被称为控制图。为简单起见,我们只考虑下面的x0=0的线性情况。一般情况通过首先学习x0来处理,并且在wiebe等人的"quantumbootstrappingviacompressedhamiltonianlearning,"newjournalofphysics17(2):022005(2015)中讨论。
已经提出量子自举以有效地学习这样的映射,其中使用可信量子模拟器来推断不可信设备的控制。虽然这可以允许使用多重对数数目的实验来学习控制图,但是必须使用交换门,交换门将设备耦合到用于表征它的可信模拟器。这表示,验证可信模拟器是否正常工作仍然需要指数数目的测量(即使在局部性假设下)。这很重要,因为可信模拟器中的误差对可以获取的误差设置了下限。
值得注意的是,尽管贝叶斯推断没有正确地推断系统的真实控制图,但是它确实推断出精确地模仿可信模拟器的一组控制。在这个意义上,学习任务可以被认为是机器学习任务,其中不可信设备使用“可信”模拟器的输出被训练以最大化其输出的保真度,其中输出状态可以被认为是用于问题的训练数据。因此,拥有良好校准的可信设备以利用量子自举的全部能量是至关重要的。构建可信模拟器的第一步是校准单量子位门。
两级示例
假设哈密顿量具有以下形式
h([α,β,γ])=αx+βy+γz。(27)
x、y和z是pauli(泡利)门。由于这三个操作反对易(anti-commute),所以很容易看出这个哈密顿量的本征值为
因此,可以从不同实验的本征能谱中推断出关于α、β和γ以及进而g的信息。具体地,
控制图学习的最简单示例是对角线情况。如果控制图是对角线,则
在这种情况下,使用如上所述的三个随机相位估计过程的序列(其中c=[1,0,0]、[0,1,0]和[0,0,1])确定本征值间隙,可以学习控制图,直到gij的符号。使用辅助实验可以廉价地学习符号,因为只需要单个比特的信息。因此,凭经验,使用随机相位估计学习g所需要的实验数目的上限为常数次数log(1/∈)。
要考虑的下一最简单的情况是以下形式的具有正对角线的上三角形控制图
很清楚,使用先验实验,可以使用随机间隙估计直接学习g00。但是,必须从不同的随机间隙确定中推断出其余元素。对于c=[1,1,0]并且c=[0,1,0],则
在对两个等式进行平方和减法之后,
其可以针对g01唯一地求解,因为g00是已知的。一旦g01已知,则可以使用g11≥0这一事实从(33)中明确地学习g11。
在这些步骤之后,已经获取了g的前两列。类似地,通过执行在c=[0,0,1]、[1,0,1]和[0,1,1]的情况下三个随机间隙估计实验,可以学习剩余的列,得到
然后,通过从(36)中减去(37)的平方而获知g02,从中,通过将结果代入(35)而获知g12。然后,通过从(35)减去(36)的平方,代入g02的值并且使用g22≥0,可以获知g22。
更一般地,该方法提供关于g的任何两列之间的内积的信息。不能通过这种测量提取关于g的更多信息。也就是说,可以获知gtg,但g本身只能被确定直到正交变换g′=qg,它保留了其列的内积。只有在对g施加额外约束的情况下才能确定矩阵q。例如,如果g是上三或下三角形并且具有正对角线,则在这种测量值中它是唯一的,并且q是如上所述的酉矩阵。
2乘2的单量子位控制图
如上所述,单独的间隙估计实验通常不足以唯一地指定控制图。实际上,需要本征基中的状态的振幅。这提出了是否可以使用振幅估计以使用o(log(1/∈))测量值来从这些系数中收集必要信息的问题。
为简单起见,考虑β=0的单个量子位的哈密顿量。因此
h([α,γ])=αx+γz。(38)
和
随机间隙估计可以提供
为了观察如何从振幅估计中获取最后的约束,假设我们可以应用精确z门的时刻。然后,我们将通过在标记|0>状态的同时对以下三个算子应用振幅估计来提供指定g所需要的附加信息,其中这些算子中的每个与c=[0,1],[1,0],[1,1]的对应值相关联,其中算子a定义为:
在上面的等式中,a01=a([0,1]),a10=a([1,0]),并且a11=a([1,1])。
然后,我们可以使用这些算子以使用随机间隙估计来获取以下振幅:
如果g11或g10的符号已知,则这三个量足以明确地求解g11和g10,并且可以使用随机振幅估计来就地学习。然后,可以从(40)中找到控制图的其余元素。如果g11或g10的符号未知,则如果准备状态
在没有校准的z门的情况下,上述振幅估计策略不适用。必要的量|a01|、|a10|和|a11|仍然可以通过统计采样来学习。这样做需要o(1/∈2)个实验,这主导数据采集的成本。然而,随机间隙估计有效地提供e01、e10和e11,这允许我们最佳地提取这些期望值(对于所考虑的实验形式)。为了理解这个,考虑针对任意的t学习|a01|的情况。似然函数为
p(0|g;t)=cos2(e01t)+sin2(e01t)|a01|2(45)
因此,清楚的是,fisher信息在演化时间t=π/(2e01)被最大化。为了相比较,考虑e01tmod2π取自0,2π上的均匀的先验的情况。因此,边缘化的似然是
因此,(10)表明,用于这种实验的fisher信息减少了2倍。这进一步减少了频率估计的推断问题,其中使用采样频率估计|a01|2的非自适应策略是最优的。因此,即使随机间隙估计不会导致这里学习g所需要的实验时间的二次减少,但是它也大大简化了推断问题,并且无需使用多个实验设置来学习这些振幅。
图6示出了获取控制图的代表性方法600。在602处,使用随机间隙估计来学习当每个控制被设置为1时的系统能量。在604处,评估控制图以确定它是上对角线还是下对角线。如果是,则在606处,可以从能量获取控制图。如果不是控制图不是上对角线或下对角线,则在608处,确定是否可以应用z门。如果是,则在610处,使用随机振幅估计来获取控制图。否则,在612处,使用能量来选择要执行以获取控制图的测量。然后,在614处,从能量和所选择的测量中推断出控制图。
以上讨论了具有未校准的x和z交互的单量子位哈密顿量的情况。一般(无迹)单量子位哈密顿量的情况遵循完全相同的推理。首先,应用随机间隙估计来学习与6个线性独立控制组相对应的相关能量。如果z门可用,则通过使用振幅估计测量适当的期望值来找到剩余的3个等式,如果不是,则使用统计采样。
最后,还可以使用该方法学习更高维度的控制图。除非哈密顿量可以分解为一组反对易的pauli算子,否则上面给出的分析讨论不再成立。然而,在这种情况下,可以在数字上应用相同的过程。
独特间隙的收费公路问题
在随机化相位估计中不直接提供本征值。相反,系统的本征值必须从间隙推断。贝叶斯推断用于推断本征值,但在什么情况下它可以成功地从间隙推断出本征值仍然是一个悬而未决的问题。如下所示,对于典型能谱,其中能谱间隙是唯一的,存在可以等效地描述系统的能谱的至多两个简并选择。
定理1.令{λl:=0<λ2<…<λn}是集合,使得对于任何i≠k,(λi+1-λi)≠(λk+1-λk),给定δ:
证明。可以容易地从这个集合中隔离最近的邻居间隙。考虑λi+2-λi=λi+2-λi+1+λi+1-λj。由于λi+2-λi+1和λi+1-λi在δ中,因此可以将这样的间隙分解为这个集合中的间隙的总和。类似地,通过归纳,可以将λi+x-λi分解为对于所有x≥2的最近邻居间隙的总和。相反,最近邻居差λi+2-λi+1不能被分解成其他间隙的总和,因为唯一性的假设。这表下,可以从该数据唯一地标识δ1,即,所有最近邻居间隙的集合。
仍然表明,只有两种方式可以布置这些间隙以形成与δ中的数据自洽的能谱。给定δxy,λn可以从能谱中标识,因为在假设λ1=0的情况下,它只是最大间隙。第二大间隙也可以从该数据中唯一地找到。有两种似然,第二大间隙是λn-1或者是λn-λ2。这可以通过矛盾来看出。想象一下,对于j≥3,λn-λj是第二大间隙。由于λj是单调递增的序列,所以λn-λj≤λn-λ2≤λn。因此它不能是第二大间隙。对于j≥2向λn-1-λj应用相同的论证导致得出结论:λn-1是第二大间隙的唯一其他候选。类似地,对于所有的x≤n-1,λx-λj≤λn-1-λj,因此这些是唯一的两个可能的候选。
假设第二大间隙是λn-1,则
λn-2=(λn-2-λn-1)+λn-1。
寻求矛盾想象,存在对此的替代解决方案,使得
λp-λn-1=(λr-1-λr)。
如果λp-λn-1不是最近邻居间隙,则具有矛盾,因为最近邻居间隙的集合是已知的并且每个间隙是唯一的,因此可以立即推断出λp不是解,除非p∈{n-2,n}。给定λp-λn-1是最近邻居间隙,必须具有p=n-2或p=n。由于最近邻居间隙是唯一的λn-2-λn-1≠λn-1-λn,并且因为已经知道λn-λn-1,这种困惑是不可能的。此外,最近邻居间隙的唯一性表明,唯一可能的解是r=n-1。因此,λn-2的选择是唯一的。
对于任何p<n,可以使用λp和λp+1重复该过程,并且类似地,该过程必须导致唯一的解。因此,给定第二大间隙是λn-1,能谱是唯一的。
现在假设第二大间隙是λn-λ2。因此,λ2是已知的,因为λn是已知的。通过重复上面使用的完全相同的论证,看到λ3由这两个值和最近邻居间隙的唯一性唯一地确定。可以扩展相同的论证,得出以下结论:如果λ2是λn减去第二大间隙,则能谱也是唯一的。因此,基于该数据,最多有两种可能的能谱。
该方法表明,如果间隙是唯一的,则收费公路问题存在解(直到关于其中点的能谱的反映)。然而,在存在简并间隙的情况下,没有用于求解收费公路算法的有效算法。虽然已知回溯算法通常可以在时间o(n2log(n))找到问题的解,但通常需要时间o(2nnlog(n))。这表明,贝叶斯推断并不总能在n的多项式的时间中找到解,其本身是量子位数的指数。另外,注意,haar随机酉指数上难以准备;然而,这个haar随机酉系综可以用酉2设计来近似,该设计可以使用clifford运算的随机序列来形成。
相位估计中的参数的数目取决于表示输入状态所需要的哈密顿量的本征态的数目。
给定输入状态根据haar测量进行采样,似然的期望值仅取决于哈密顿量的本征能谱中的间隙。因此,我们没有足够的信息来解决系统的实际本征能谱。但是,这仍然有用。例如,可以找到由最小本征值与最大本征值之间的差给出的哈密顿量的能谱范数。此外,发现系统中的最小间隙,其也是地面与第一激发态之间的间隙的下限。这可以用于估计绝热算法的最佳退火计划。
<l>t=0=1(53)
随着更多能量等级,解析参数变得显著更加昂贵。有两个主要影响。首先,随着等级的数目的增加,随机输入状态有效地变为扰乱。对于固定的时间步长t,如果从高斯酉系综中抽取哈密顿量,则似然的期望值随着等级的数目线性地平均下降。因此,假设测量所有等级,解析它所需要的实验数目随着量子位的数目线性地或指数地增加。第二影响是似然函数中的简并。取决于本征能谱,这导致不同参数组的似然的相等值。如果使用单个高斯模型作为模型,如果多个简并在模型的支持范围内,则推断的收敛速度将显著降低,因为它不能正确地解决似然中的多个峰值。一种解决方案是代替地使用多模态混合模型来解析所有峰值。然而,对于每个重新采样步骤,这需要更复杂的重新拟合过程,诸如期望最大化,其本身可能陷入局部最优。
另一种方法是修改模拟中的似然函数以“挑选”全局最优之一,或者至少通过破坏一些对称性来减少简并性。例如,我们可以通过在以下似然函数中引入附加符号项来强制对本征值进行排序和强制本征值为正
其中如果其参数为正,则符号函数为+1,否则为-1。因此,只有当λi>λj时,这种似然才会在所有时间步骤t与实验似然相一致。然而,对于4个或更多个等级,似然仍然是简并的,并且需要添加进一步的非平凡修改来破坏它们。这种修改的另一问题是对于某些参数组,似然可能大于1(unity)或小于0。如果是这种情况,则这里使用的原始解决方法是简单地强制它是物理的,例如<l>←min(max(<l>,0),1)。然而,通过这种方法,如果似然明显超出区间,则推断可能变得不稳定。
量子和经典处理环境
参考图7,用于实现所公开的技术的一些方面的示例性系统包括计算环境700,计算环境700包括量子处理单元702和一个或多个监测/测量设备746。量子处理器执行由经典编译器单元720利用一个或多个经典处理器710预编译的量子电路(诸如图3的电路)。参考图7,编译是将量子算法的高级描述转换成量子电路序列的过程。这种高级描述可以根据具体情况利用一个或多个存储器和/或存储设备762存储在计算环境700外部的一个或多个外部计算机760上,然后根据需要经由一个或多个通信连接750下载到计算环境700中。或者,经典编译器单元720耦合到经典处理器710和过程库721,过程库721包含实现上述方法所需要的一些或所有过程或数据,诸如随机间隙估计和定义诸如图3的那些的随机酉电路。通信总线耦合去往和来自量子处理器702、测量和监测设备746以及经典处理器720的指令和数据。以这种方式,可以传送来自编译器单元720的电路定义或来自测量和监测设备746的测量结果(或其他数据)。
图8和以下讨论旨在提供其中可以实现所公开的技术的示例性计算环境的简要的一般描述。尽管不是必需的,但是在由个人计算机(pc)执行的计算机可执行指令(诸如程序模块)的一般上下文中描述所公开的技术。通常,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。此外,所公开的技术可以用其他计算机系统配置来实现,包括手持设备、多处理器系统、基于微处理器或可编程的消费电子产品、网络pc、小型计算机、大型计算机等。所公开的技术还可以在其中任务由通过通信网络链接的远程处理设备执行的分布式计算环境中实践。在分布式计算环境中,程序模块可以位于本地和远程存储器存储设备两者中。通常,经典计算环境耦合到量子计算环境,但是图8中未示出量子计算环境。
参考图8,用于实现所公开的技术的示例性系统包括示例性传统pc800形式的通用计算设备,其包括一个或多个处理单元802、系统存储器804和系统总线806,系统总线806将包括系统存储器804在内的各种系统组件耦合到一个或多个处理单元802。系统总线806可以是若干类型的总线结构中的任何一种,包括使用各种总线架构中的任何总线架构的存储器总线或存储器控制器、外围总线和本地总线。示例性系统存储器804包括只读存储器(rom)808和随机存取存储器(ram)810。包含有助于在pc800内的元件之间传送信息的基本例程的基本输入/输出系统(bios)812存储在rom808中。
如图8所示,随机酉或相关程序的规范存储在存储器部分816中。初始量子态的指令和规范存储在811a处。贝叶斯估计的程序存储在811c处,grove算子规范存储在811b处,并且用于定义用于演化操作的量子电路的处理器可执行指令存储在818处。
示例性pc800还包括一个或多个存储设备830,诸如用于读取和写入硬盘的硬盘驱动器、用于读取或写入可移动磁盘的磁盘驱动器、以及用于读取或写入可移除光盘(诸如cd-rom或其他光学介质)的光盘驱动器。这种存储设备可以分别通过硬盘驱动器接口、磁盘驱动器接口和光盘驱动器接口连接到系统总线806。驱动器及其相关联的计算机可读介质为pc800提供计算机可读指令、数据结构、程序模块和其他数据的非易失性存储。可以存储pc可访问的数据的其他类型的计算机可读介质(诸如磁带盒、闪存卡、数字视频盘、cd、dvd、ram、rom等)也可以在示例性操作环境中使用。
很多程序模块可以存储在存储设备830中,包括操作系统、一个或多个应用程序、其他程序模块和程序数据。用于定义随机间隙估计电路和过程以及配置量子计算机的计算机可执行指令的存储可以存储在存储设备830以及存储器804中或者除了存储器804之外。用户可以通过一个或多个输入设备840将命令和信息输入到pc800中,诸如键盘和指示设备,诸如鼠标。其他输入设备可以包括数码相机、麦克风、操纵杆、游戏手柄、圆盘式卫星天线、扫描仪等。这些和其他输入设备通常通过耦合到系统总线806的串行端口接口连接到一个或多个处理单元802,但是可以通过诸如并行端口、游戏端口或通用串行总线(usb)等其他接口连接。显示器846或其他类型的显示设备也经由诸如视频适配器等接口连接到系统总线806。可以包括其他外围输出设备845,诸如扬声器和打印机(未示出)。在一些情况下,显示用户界面,使得用户可以输入本征值间隙上的先验分布,并且验证真实间隙的成功推断。
pc800可以使用到诸如远程计算机860等一个或多个远程计算机的逻辑连接在联网环境中操作。在一些示例中,包括一个或多个网络或通信连接850。远程计算机860可以是另一pc、服务器、路由器、网络pc或者对等设备或其他公共网络节点,并且通常包括上面关于pc800描述的很多或所有元件,尽管图8中仅示出了存储器存储设备862。个人计算机800和/或远程计算机860可以连接到逻辑局域网(lan)和广域网(wan)。这样的网络环境在办公室、企业范围的计算机网络、内联网和因特网中很常见。
当在lan联网环境中使用时,pc800通过网络接口连接到lan。当在wan联网环境中使用时,pc800通常包括调制解调器或用于通过wan建立通信的其他装置,诸如因特网。在联网环境中,相对于个人计算机800或其部分而描述的程序模块可以存储在远程存储器存储设备或者lan或wan上的其他位置。所示出的网络连接是示例性的,并且可以使用在计算机之间建立通信链路的其他手段。
在一些示例中,可以使用诸如现场可编程门阵列、其他可编程逻辑器件(pld)、专用集成电路等逻辑器件,并且不需要通用处理器。如本文中使用的,处理器通常是指执行可以耦合到逻辑设备或固定在逻辑设备中的指令的逻辑设备。在一些情况下,逻辑设备包括存储器部分,但是存储器可以设置在外部,这可能是方便的。另外,可以布置多个逻辑设备用于并行处理。
尽管已经结合若干示例实施例描述了本发明,但是应当理解,本发明不限于这些实施例。相反,本发明旨在包括可以被包括在由所附权利要求限定的本发明的精神和范围内的所有替代、修改和等同物。
- 还没有人留言评论。精彩留言会获得点赞!