一种基于语义选择的多变量时间序列分类方法与流程
技术特征:
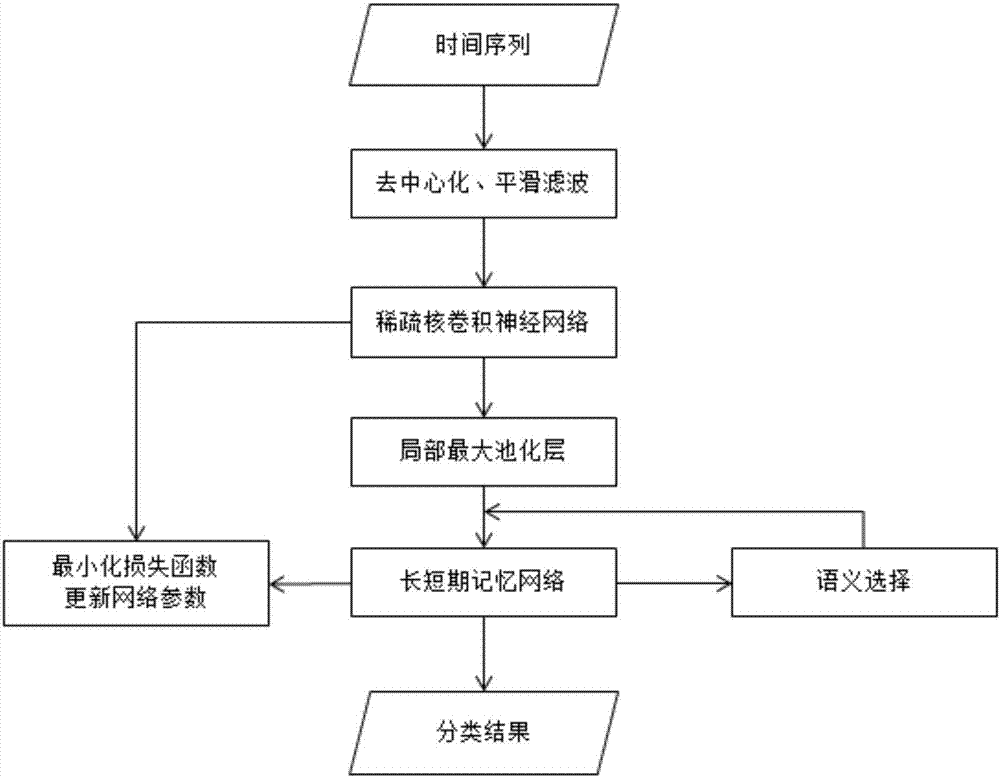
1.一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的多变量时间序列分类方法包括下列步骤:
S1、收集时间序列数据集;
S2、对数据进行预处理操作,然后按照数据集定义的验证方法划分训练集,验证集和测试集;
S3、将一个样本的数据组织成矩阵形式,用稀疏的卷积核来提取语义特征;
S4、对卷积后的特征图谱在时间维度上进行局部最大池化,获取时间段特征;
S5、将步骤S4产生的特征按照时间段顺序输入LSTMs,每一时刻的隐含层状态输入维度等于滤波器个数的Softmax层,并产生下一时刻选择语义概念的注意力权重;
S6、取LSTMs最后时刻的隐含层状态输入维度等于类别个数的Softmax层进行概率归一化;
S7、修改交叉熵损失函数,加入卷积核稀疏项约束,最小化损失函数更新参数并自动学习语义概念;
S8、使用步骤S2中划分的验证集测试训练后的模型,选取在验证集上表现最好的超参数对步骤S2中划分的测试集进行测试,获得最终准确率。
2.根据权利要求1所述的一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的步骤S2中对数据进行预处理操作包括去中心化、平滑滤波、归一化。
3.根据权利要求1所述的一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的步骤S3过程如下:
将每个样本序列组织成矩阵形式,时间序列的属性全集表示为A={αi},i=1,2,…,|A|,所有属性在样本每一时刻的值构成矩阵X,X∈RT×|A|,其中T是帧的数量,|A|是属性的数量,其矩阵形式如下所示:
以稀疏的卷积核来提取时间序列的属性组合特征,每一种组合特征被称为该时间序列的一种语义,卷积核权重矩阵Wk∈Rt×|A|是宽为t的第k个卷积核的参数,当滑动步长为1时,矩阵X将被分成T-t+1个时间窗口:Z1:t,Z2:t+1,···,ZT-t+1:T,因此使用滤波器Wk作用于全部时间窗口的结果为:ck=(c1,k,c2,k,...,cT-t+1,k)T∈RT-t+1,其中cm,k,m=1,2,...,T-t+1为将第k个稀疏卷积核作用于第m个滑动窗口的结果,由于CNNs权重共享的特性,卷积核k在所有时间窗口上提取到相同的语义概念,定义cm,k=f(Wk*Zm:m+t-1+bk),其中f是激活函数,*代表点乘算子,bk代表第k个核的偏置;
通过多个稀疏卷积核获得多种语义概念,同时对相邻行的卷积获得时间序列的短时依赖性。
4.根据权利要求1所述的一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的步骤S4过程如下:
进行局部最大池化,以p代表池化窗口的大小,s代表时间维度上的步长,cm,k代表第m行,第k列的激活值,将步骤S3得到的特征图谱作为池化层的输入,yj,k代表第k个滤波器的第j个池化窗口的输出,局部最大池化层按照下式计算:
式中c*=(1+(j-1)*s,2+(j-1)*s,···,p+(j-1)*s)T,池化后得到矩阵O∈RL×K,K是滤波器数量,ceil(·)是向上取整函数。
5.根据权利要求1所述的一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的步骤S5过程如下:
将每个时间步的隐含层状态输入维度等于滤波器个数的Softmax层,在每个时间步t,模型产生预测向量lt+1∈RK用于选取重要的语义概念,其中,预测向量为注意力权重,向量lt中的每个元素反映对应语义概念的重要程度,获得t时刻的注意力权重后,则下一时刻的输入可以被改写为:其中
代表池化后的矩阵O的第t行,经过LSTMs递归迭代和注意力机制选取语义概念后,得到样本n的最终特征向量
6.根据权利要求1所述的一种基于语义选择的多变量时间序列分类方法,其特征在于,所述的步骤S7过程如下:
加入卷积核稀疏项约束项,因此修改交叉熵损失函数如下:
上式中第一项是最大似然损失函数,u代表训练数据,Cs是数据集中的第s个类,N代表训练集样本数量,δ(·)是Kronecker delta函数,r是样本un的真实标签,概率p(Cs|un)由步骤S6中产生的经过维度为C的Softmax层归一化后产生;上式中第二项是矩阵WT的
范式,用反向传播算法和ADAM梯度优化算法最小化损失函数,更新参数直到收敛。
- 还没有人留言评论。精彩留言会获得点赞!