生成式多轮闲聊对话方法、系统及计算机可读存储介质与流程
本发明涉及一种生成式多轮闲聊对话方法、系统及计算机可读存储介质。
背景技术:
对话系统,也被称为智能对话体或者聊天机器人,已经被广泛应用于各种生活场景中,包括客服、娱乐闲聊、情感陪护、知识共享等等。
从用途上,对话系统可以大致分为闲聊对话系统和以任务为导向的对话系统。从技术上,对话系统可以分为基于规则、基于检索、基于生成的对话系统,其中,基于规则的对话系统需要耗费大量的人力资源来设计规则,基于检索的对话系统严重依赖于语料库的质量和大小,并且基于规则或者检索的对话系统严重限制了生成回复的多样性。基于生成的对话系统能够生成更灵活的回复,也是近年来研究人员重点努力的一个方向。
基于生成的闲聊对话系统包括单轮对话闲聊系统和多轮对话闲聊系统。单轮对话的闲聊系统主要的实现技术是基于编码器-译码器框架,利用人人对话语料来训练一个神经网络,将对话语料组织成提问-回复对,将提问、回复分别作为模型的输入和输出来训练网络模型。单轮对话系统面临的一个问题是模型忽略了对话历史对当前回复的影响。
虽然有很多研究工作提高了多轮对话闲聊系统的表现,但是它仍面临一些问题,其中一个较为突出的问题是多轮对话闲聊系统经常生成无意义回复的问题。比如,对话系统经常生成“我不知道”、“我也是”等无意义回复。这种无意义回复的生成主要是因为在语料库中这种回复所占的比例较高,使得训练的模型倾向于生成较为普遍的无意义回复。
技术实现要素:
为了解决现有技术的不足,本发明提供了一种生成式多轮闲聊对话方法、系统及计算机可读存储介质;
作为本发明的第一方面,提供了一种生成式多轮闲聊对话方法;
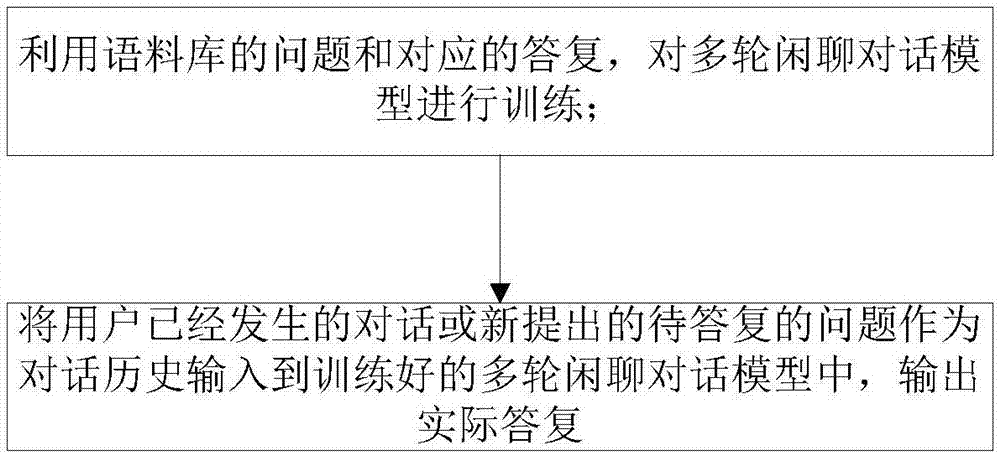
一种生成式多轮闲聊对话方法,分为两个阶段:
阶段一:利用语料库的对话,对多轮闲聊对话模型进行训练;
阶段二:将用户已经发生的对话或新提出的待答复的问题作为对话历史输入到训练好的多轮闲聊对话模型中,输出实际答复。
所述利用语料库的对话,对多轮闲聊对话模型进行训练,包括:
步骤(1):构建多轮闲聊对话模型,所述多轮闲聊对话模型包括:关键词抽取模块、宽度通道、全局通道、深度通道和解码器;所述宽度通道和深度通道并列设置,全局通道的输出分别作为宽度通道和深度通道的输入;所述宽度通道内设置有基于注意力机制的循环神经网络;所述全局通道内设置编码器;所述深度通道内设置深度神经网络;所述宽度通道和深度通道的输入端均与关键词抽取模块连接;所述宽度通道、全局通道和深度通道的输出端均与解码器连接,所述解码器内设有基于注意力机制的循环神经网络;
步骤(2):将语料库中的对话分为历史对话和当前答复,所述历史对话和当前答复是相对而言的,所述历史对话,是指当前答复之前的对话内容;历史对话发生的时刻在当前答复发生的时刻之前;所述历史对话包括已知的若干组对话;然后,抽取历史对话的关键词;
步骤(3):将语料库中的历史对话输入到全局通道的编码器中进行编码,生成上下文向量;
步骤(4):将步骤(2)得到的历史对话的关键词和步骤(3)得到的上下文向量,输入到宽度通道的基于注意力机制的循环神经网络,输出用来拓宽话题的预测关键词,并将预测关键词编码为对应的预测关键词的编码向量;
步骤(5):将步骤(2)得到的历史对话的关键词和步骤(3)得到的上下文向量,输入到深度通道的深度神经网络,输出历史对话中关键词的权重,基于权重得到加权后的历史对话关键词编码向量;
步骤(6):将步骤(3)得到的上下文向量、步骤(4)得到的预测关键词的编码向量和步骤(5)得到的加权后的历史对话关键词编码向量均输入到解码器的基于注意力机制的循环神经网络中,输出回复结果;
步骤(7):将步骤(6)得到的回复结果,与步骤(2)中的当前回复进行比较,计算交叉熵,得到损失函数,利用梯度下降算法对多轮闲聊对话模型进行优化,得到训练好的多轮闲聊对话模型。
作为本发明的进一步改进,
阶段二所执行的步骤与阶段一所执行的步骤(2)-(6)是一样的,只是阶段二中将用户已经发生的对话或新提出的待答复的问题视为历史对话。
阶段二的步骤(6)得到的回复直接输出,反馈给用户。阶段二中不执行步骤(1)和步骤(7)。
作为本发明的进一步改进,所述步骤(2)中:
所述语料库,是指新浪微博中文语料库和dailydialog多轮对话语料库。
作为本发明的进一步改进,所述步骤(2)的步骤为:
将语料库中的每组历史对话作为一个文件,将整个语料库看成文件集;
采用tf-idf算法计算每个词对于每个文件的权重;
从每组历史对话的所有词中筛选权重高于设定阈值的词作为每组历史对话的关键词。
作为本发明的进一步改进,所述步骤(3)中:
对历史对话进行分词处理,将历史对话看成一组词的序列,利用循环神经网络对每组词的序列进行编码,编码成一个上下文向量;
作为本发明的进一步改进,所述步骤(3)中:
c={w1,w2…wt}
其中c代表词的序列,wi表示历史对话中的第i个词,t是指整个历史对话共包含t个词。
f是由循环神经网络单元构成的非线性函数;
ht是循环神经网络的在t时刻的隐状态向量,
ht-1是循环神经网络的在t-1时刻的隐状态向量;
编码结束时,t时刻的隐状态向量ht就是最后编码成的上下文向量。
其中,词的编码向量是在语料库上预训练得到的,每个词的编码向量的维度是100,词的编码向量作为训练参数是可以在训练过程中根据损失函数更新的;
作为本发明的进一步改进,所述步骤(4)中:
基于注意力机制的循环神经网络,例如:dzmitrybahdanau,kyunghyuncho,andyoshuabengio.2014.neuralmachinetranslationbyjointlylearningtoalignandtranslate.arxivpreprintarxiv:1409.0473(2014).
作为本发明的进一步改进,所述步骤(4)中:
利用步骤(3)得到的隐状态向量对基于注意力机制的循环神经网络进行初始化,
基于注意力机制的循环神经网络的输入值是历史对话关键词的编码向量和由注意力机制对步骤(3)的每一个隐状态向量和历史对话关键词的编码向量加权计算之后的向量。
s0=ht
st是循环神经网络在t时刻的隐状态向量,
st-1是循环神经网络在t-1时刻的隐状态向量,
ct是由注意力机制对步骤(3)的每一个隐状态向量和历史对话关键词的编码向量加权计算之后的向量。
其中,wt是一个转移矩阵,将
eti=η(st-1,hi)i=1,2,…,t
eti=η(st-1,mi)i=t+1,…,t+m
其中η是利用多层感知机实现的非线性函数,激活函数是tanh函数,st-1是t-1时刻循环神经网络的隐状态。
基于注意力机制的循环神经网络的每一步输出经过一个向量变换后得到在全词表上生成每一个词的概率,取最高概率的词作为预测的关键词;所述全词表是指由整个语料库中所有词构成的词表。
向量变换:
作为本发明的进一步改进,所述步骤(5)中:
利用深度神经网络计算历史对话关键词的权重;
深度神经网络的输入是步骤(3)得到的隐状态向量和历史对话的关键词,输出是所有历史对话关键词的权重。
q=mlp(l0)
l0是步骤(3)得到的隐状态向量以及历史对话关键词的编码向量级联起来的一个向量,
将l0输入多层感知机,输出每一个历史对话中关键词的权重q,利用q对历史对话中关键词的编码向量进行加权:
步骤(6)与步骤(4)中预测关键词的基于注意力机制的循环神经网络结构相同,但ct的计算方式不同,与步骤(4)类似,计算得到的隐状态同样经过全连接层投影后由softmax函数计算每一个词的输出概率。ct的计算如下:
其中,n是预测的关键词的数量,
步骤(6)与步骤(4)相同,经过基于注意力机制的循环神经网络,得到的每一步的隐向量经过全连接层变换后得到每一个预测的词,从而得到整个多轮闲聊对话模型的输出回复。
作为本发明的第二方面,提供了一种闲聊多轮对话系统;
一种闲聊多轮对话系统,包括:存储器、处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
作为本发明的第三方面,提供了一种计算机可读存储介质;
一种计算机可读存储介质,其上存储有计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
与现有技术相比,本发明的有益效果是:
通过挖掘对话历史中的关键词、在模型中引入注意力机制,将对话历史中的所有词区别对待,扩大了历史对话中关键词在生成回复时的作用。
通过宽度通道来预测关键词拓宽话题,通过深度通道来预测历史对话中关键词的权重,以此来拓宽和深入当前话题,将两部分得到的话题信息引入解码器中辅助解码,话题信息的引导有效地解决了无意义回复的问题,大大减少了无意义回复的数量。
在开源的微博多轮对话语料和dailydialog多轮对话数据集进行了训练和测试,表1显示了在ppl、bleu、distinct-1指标上我们的模型和当前主流的基准模型的比较,结果显示我们的模型比基准模型表现得更好,并且在distinct-1指标上远远超过了基准模型,说明我们的模型生成了更加多样的回复,减少了无意义回复的生成,大大提高了回复的质量。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1为本发明的流程图;
图2为本发明的模型框架图;
图3为本发明的宽度通道结构图;
图4为本发明的深度通道结构图;
图5为本发明的解码器结构图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
对话系统:对话系统是指人类构建的能够与人进行对话交互的机器系统,包括闲聊系统、以特定任务为导向的对话系统等。
闲聊系统:闲聊系统是指能够与人类进行开放话题的对话交互、以日常闲聊为目的的对话系统。
深度神经网络:深度神经网络是具有多层神经元的人工神经网络,在输入层和输出层之间具有多个隐藏层。每一层神经元之间可以相互传递数据,并且根据网络的函数目标动态调整自身的权重值。
循环神经网络:循环神经网络是利用神经网络结构在时间上进行迭代,允许对于某个序列进行时间上的迭代处理。
tf-idf:tf-idf是一种根据词频和逆向文件频率来计算词语对于整个文件集中某一文件重要性的方法。词语的重要性随着它在该文件中出现的次数成正比增加,但同时会随着它在整个文件集中出现的频率成反比下降。
人在对话聊天的过程中,是经常会拓宽或者深入当前话题,比如说人们在聊到天气的时候,可能会继续聊到下雨,或者由下雨延伸到感冒、发烧。受到这个现象的启发,我们认为拓宽或者深入的话题信息可以指导解码器生成更有意义的回复。因此,我们提出了一个新型的多轮对话闲聊模型(dawnet)。
整个模型分为5个部分,分别是关键词抽取、全局通道、深度通道、宽度通道、解码器。
在关键词抽取部分,模型利用tf-idf从对话历史和回复抽取关键词。
全局通道编码对话历史形成上下文向量。
深度通道利用上下文向量和抽取的对话历史关键词,从对话历史关键词中选择关键词。
宽度通道利用上下文向量和对话历史中的关键词,预测相关话题的关键词。
解码器利用全局通道、宽度通道、深度通道的输出作为输入,解码生成当前回复。
损失函数包括宽度通道、解码器的softmax交叉熵优化函数以及深度通道的sigmoid交叉熵优化函数,以此来优化整个模型。
如图1所示,一种生成式多轮闲聊对话方法,分为两个阶段:
阶段一:利用语料库的对话,对多轮闲聊对话模型进行训练;
阶段二:将用户已经发生的对话或新提出的待答复的问题作为对话历史输入到训练好的多轮闲聊对话模型中,输出实际答复。
如图2所示,对于整个模型,我们利用了开源的新浪微博中文语料库和dailydialog英文语料库分别进行了训练和优化。
s1:关键词抽取
在关键词抽取部分,我们将语料库中的每组对话作为一个文件,将整个语料库看成文件集,利用if-idf来计算每个词对于该组对话的重要性,得到每一个词的权重值,从所有的词中其中筛选权重高于一定阈值的关键词作为对话历史和回复的关键词。
s2:全局通道
我们将对话历史看成一组词的序列,利用循环神经网络对对话历史进行编码,编码成一个上下文向量。
c={w1,w2wn}
其中c代表对话上下文构成的词语序列,f是由循环神经网络单元构成的非线性函数,由grus实现。ht是循环神经网络的在t时刻的隐状态,
s3:宽度通道
如图3所示,宽度通道利用基于注意力机制的循环神经网络预测一系列相关的关键词。网络由全局通道得到的隐状态向量初始化,每次迭代的输入是当前关键词的编码向量和由注意力机制计算得到的历史向量。
st是循环神经网络在t时刻的隐状态,
s4:深度通道
如图4所示,深度通道利用深度神经网络计算对话历史中关键词的权重,对其编码向量进行加权。输入是全局通道编码对话历史最后的隐状态和上下文的关键词,输出是所有上下文关键词的权重。
q=mlp(l0)
l0是全局通道编码最后的隐状态以及对话历史关键词的编码向量级联起来的一个向量,将l0送入多层感知机,输出每一个对话历史中关键词的权重q,利用q对对话历史中关键词的编码向量进行加权。
s5:解码器
如图5所示,解码器是基于注意力机制的循环神经网络,利用全局通道、宽度通道、深度通道的输出作为输入,在每一步解码出回复中的一个词。
我们利用开源的微博多轮对话语料库和开源的dailydialog多轮对话数据集进行了训练和测试,表1显示了在ppl、bleu、distinct-1指标上我们的模型和当前主流的基准模型的比较,结果显示我们的模型比基准模型表现得更好,并且在distinct-1指标上远远超过了基准模型,说明我们的模型生成了更加多样的回复,减少了无意义回复的生成,大大提高了回复的质量。
表1dawnet与基准模型结果比较
除了指标上的对比,我们也对模型进行了人工评价,让人来评判我们的模型和其他基准模型的优劣,结果见表2,可以看出我们模型同样有更好的表现。
表2人工评价结果比较
举例:输入:
用户a:今天的雨实在太大了,简直是暴雨。
用户b:雨伞都没用。
输出:
用户a:雨这么大,都把我淋湿了。(话题深入)得回去喝杯热茶,别晚上感冒了。(话题拓宽)
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!