一种基于MeanShift的融合词性和句子信息的词表示方法与流程
本发明涉及词向量、深度学习和自然语言处理的技术领域,尤其是指一种基于meanshift的融合词性和句子信息的词表示方法。
背景技术
词向量即使用向量对词进行表示,通常被认为是词的特征表示。主流的词表示技术主要分为:基于矩阵的词表示技术、基于聚类的词表示技术和基于神经网络的词表示技术。其中基于神经网络的表示方法以skip-gram和cbow为代表,其本质思想是:harris在1954年提出的分布假说——上下文相似的词,其语义也相似。词向量能在一定程度上解决语义鸿沟现象。在自然语言处理领域,词向量作为深度学习的特征输入,其质量直接影响上层深度模型的效果。传统的词表示模型在给定窗口的词共现信息上进行训练,而忽略了句子信息对词向量本身的反作用,导致词表示的信息建模不完整。
传统的自然语言处理技术包括:分词、词性标注、命名实体识别、情感分析和文本分类等。其中的分词和词性标注耗费了巨大的资源进行人工标注,取得了较好的成果。词性,作为词表示的重要组成部分,其极大地影响词的语义,将已有词性标注信息融入词向量能从词性的角度对词表示进行建模。
技术实现要素:
本发明的目的在于克服现有词表示技术的缺点与不足,提出了一种基于meanshift的融合词性和句子信息的词表示方法,从词性和句子侧面为词向量表示补充额外的信息,从而使得词向量在单词类比和词相似度方面有较大的提高,进一步缓解词语的语义鸿沟现象。
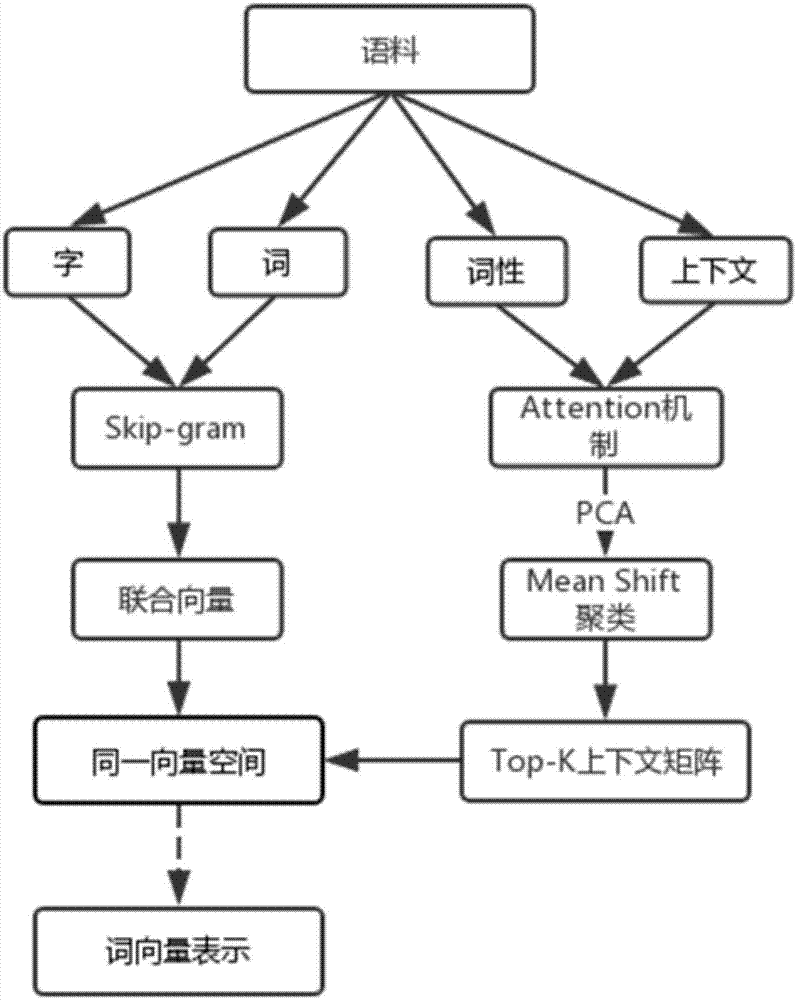
为实现上述目的,本发明所提供的技术方案为:一种基于meanshift的融合词性和句子信息的词表示方法,包括以下步骤:
1)对语料进行分词和词性标注;
2)使用skim-gram、crow方法训练得到字词联合向量;
3)通过使用skim-gram、crow方法训练直接得到词性向量或使用属于同一词性的所有词向量的平均值作为词性向量;
4)用attention机制和词性向量生成句子向量,进行主分析主成分pca;
5)对上下文矩阵进行meanshift聚类,对top-k聚类中心进行加权求和后得到上下文向量;
6)对字词联合向量、词性向量和上下文向量加权求和得到最终的词向量表示。
在步骤1)中,所述的词性标注包括1998年和2014年人民日报标注语料,采用的词性标注工具有jieba、hanlp和nlpir。
在步骤2)中,使用skim-gram、crow方法训练词向量和字向量得到字词联合向量,包括以下步骤:
2.1)进行数据清理,去除步骤1)生成的词序列中的标点符号、特殊字符;
2.2)使用skip-gram或cbow方法分别训练得到词向量wi,字向量ci;
2.3)对步骤2.2)生成的字向量和词向量进行加权求和,得到的字词联合向量:
其中,ui为字词联合向量,wi为词语i的词向量,ci为词语i包含的字向量,|ci|为词语i包含的字的个数,α为模型的超参数,为字向量的占比。
在步骤3)中,使用两种方法生成词性向量,方法一是直接对词性标注序列,使用skim-gram、crow方法训练词性向量,训练参数设置和步骤2)一致;方法二是使用步骤2)生成的字词联合向量,对于每一类词性使用属于该词性的所有词的向量的平均值作为该词性的向量表示;方法一和方法二得到的词性向量记为:pos(ui)。
在步骤4)中,统计词对应的上下文,用attention机制和词性向量生成句子向量,对句子向量进行主分析主成分pca,得到低维的上下文矩阵,包括以下步骤:
4.1)计算词对应的上下文矩阵,矩阵中的每一行代表一个词上下文,计算公式如下:
其中,
4.2)对步骤4.1)生成的每一个词对应的上下文矩阵进行主成分分析pca,提取经过pca后的上下文矩阵的第一主元素,对上下文矩阵中每一个元素进行更新,计算公式如下:
其中,
在步骤5)中,对上下文矩阵进行meanshift聚类,获取top-k聚类中心,对聚类中心进行加权求和后得到词的上下文向量。计算公式如下:
其中,context(ui)为字词联合向量ui对应的上下文向量,
在步骤6)中,对得到的字词联合向量、词性向量和上下文向量使用矩阵汇总保留,矩阵形式如下所示:
其中,wr(wi)为最终保留上下文和概率的词矩阵,u为步骤2)生成的字词联合向量ui,s为步骤5)生成的上下文向量context(ui),r为上下文向量的概率,即步骤5)对应的聚类类别占比rj;
为了转化为常用的词向量形式,设计以下两种方式的降维表示:
方法一:加权求和得到最终的词向量表示;通过更改ρ的比例适应不同的需求,若需要寻找与目标词词性相近的词语则提高ρ2的比例;需寻找上下文相近的词语则提高ρ3的比例;计算公式如下:
其中,wi为最终的词向量表示,ρ1、ρ2和ρ3为模型的超参数,分别为字词联合向量、词性向量和上下文向量的建模比例;
方法二:使用上下文向量的最大值作为词上下文的代表;很多情况下,只关心词在最常用语境下的语义,因此选取出现的上下文概率最大的上下文向量即可;计算公式如下:
其中,rk为聚类类别k的占比,j为最大rk对应的类,
本发明与现有技术相比,具有如下优点与有益效果:
1、本发明将词性标注信息和句子信息融合到词向量表示中,使用同一向量空间表示字、词、词性和上下文,能提高词向量的表示能力。
2、使用pca技术对句子矩阵进行主成分分析,经过meanshift聚类后提取常用的句子语境,本质上的思想就是:去噪,只保留高频使用的top-k种词义,提高了词表示的质量,缓解语义鸿沟现象。
3、本发明可组合不同的词向量,寻找与目标词词性相近的词或上下文相近的词,拓展了词向量的使用场景。
4、本发明显式地保留词的上下文向量及其出现频率,可用于词的歧义消除等后续的自然语言处理任务。
附图说明
图1为本发明方法的流程示意图。
图2为本发明的meanshift聚类图。
图3为本发明的词表示模型图。
具体实施方式
下面结合具体实施例对本发明做进一步说明。
本实施例所提供的基于meanshift的融合词性和句子信息的词表示方法,包括以下步骤:
1)对语料进行人工或者使用词性标注工具进行分词和词性标注;所述的人工词性标注包括:1998年和2014年人民日报标注语料等。词性标注工具包括:jieba、hanlp和nlpir等。
2)使用skim-gram、crow等方法训练词向量和字向量,得到字词联合向量。其中包括以下步骤:
2.1)进行数据清理,去除步骤1)生成的词序列中的标点符号、特殊字符。
2.2)使用同样的skip-gram或cbow等方法分别训练得到词向量wi,字向量ci,指定的调优参数包括:向量维度、负采样率、最低词频和上下文窗口大小等。
2.3)对步骤2.2)生成的字向量和词向量进行加权求和,得到的字词联合向量:
其中,ui为字词联合向量,wi为词语i的词向量,ci为词语i包含的字向量,|ci|为词语i包含的字的个数,α为模型的超参数,为字向量的占比。
3)使用两种方法生成词性向量,方法一是直接对词性标注序列,使用skim-gram、crow等方法训练词性向量,训练参数设置和步骤2)一致;方法二是使用步骤2)生成的字词联合向量,对于每一类词性使用属于该词性的所有词的向量的平均值作为该词性的向量表示。方法一和方法二得到的词性向量记为:pos(ui)。
4)统计词对应的上下文,用attention机制和词性向量生成句子向量,对句子向量进行主分析主成分(pca),得到低维的上下文矩阵,包括以下步骤:
4.1)计算词对应的上下文矩阵,矩阵中的每一行代表一个词上下文,计算公式如下:
其中,
4.2)对步骤4.1)生成的每一个词对应的上下文矩阵进行主成分分析(pca),提取经过pca后的上下文矩阵的第一主元素,对上下文矩阵中每一个元素进行更新,计算公式如下:
其中,
5)对上下文矩阵进行meanshift聚类,获取top-k聚类中心,对聚类中心进行加权求和后得到词的上下文向量。计算公式如下:
其中,context(ui)为字词联合向量ui对应的上下文向量,
6)对得到的字词联合向量、词性向量和上下文向量使用矩阵汇总保留,使用矩阵的形式显式地保留。矩阵形式如下所示:
其中,wr(wi)为最终保留上下文和概率的词矩阵,u为步骤2)生成的字词联合向量ui,s为步骤5)生成的上下文向量context(ui),r为上下文向量的概率,即步骤5)对应的聚类类别占比rj。
为了转化为常用的词向量形式,设计了以下两种方式的降维表示:
方法一:加权求和得到最终的词向量表示。通过更改ρ的比例适应不同的需求,如需要寻找与目标词词性相近的词语则提高ρ2的比例;需寻找上下文相近的词语则提高ρ3的比例。计算公式如下:
其中,wi为最终的词向量表示,ρ1、ρ2和ρ3为模型的超参数,分别为字词联合向量、词性向量和上下文向量的建模比例。
方法二:使用上下文向量的最大值作为词上下文的代表。很多情况下,只关心词在最常用语境下的语义,因此选取出现的上下文概率最大的上下文向量即可。计算公式如下:
其中,rk为聚类类别k的占比,j为最大rk对应的类,
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!