神经网络及在移动感知设备上部署神经网络的方法与流程
本发明属于人工神经网络领域,具体涉及一种神经网络及在移动感知设备上部署神经网络的方法。
背景技术:
由于移动设备(例如智能手机、手表和眼镜)及其配备丰富的机载传感器(如照相机、加速度计、陀螺仪、无线模块等)的日益普及,如今移动感知在各种应用设计中成为一种极具有发展潜力的技术。虽然它们提出的技术细节在不同的应用程序之间可能有很大的不同,但大多数都有一个通用的设计原则即:利用移动传感器收集有关感测目标的感知数据,进一步应用学习技术来正确的识别或分类目标,以满足应用需求。
随着移动传感器硬件技术已经成熟,影响移动感知和识别性能的一个主要因素是如何应用学习技术对感知数据进行有效的分类。传统的机器学习的方法主要依赖于手动地从数据中进行特征提取,这样导致系统的准确性和可靠性极大地依赖于选取的特征的质量。
近年来取得巨大成功的深度学习可以有效地避免这种情况,并且在许多计算领域中展现了其独特优势。并且,目前已经有一些早期的工作尝试利用深度学习来改进移动传感应用设计。虽然将深度学习和移动感知结合起来看似是一种新兴的且十分具有发展潜力,但这种技术组合存在下面所阐述的问题,而这些问题会极大地限制系统的整体性能。
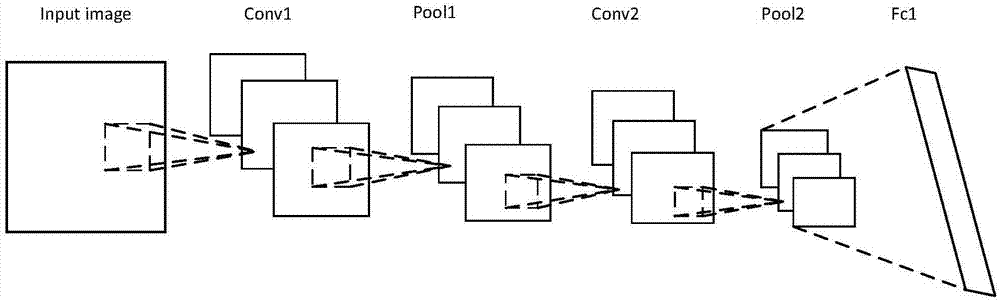
现有技术通常采用的是图1所示的卷积神经网络(cnn)进行深度学习,该卷积神经网络(cnn)中卷积层、激活函数层和池化层依次重复串联叠加,根据所需分析对象的不同,需要的重复叠加数不同,通常情况下,重复叠加数越多则卷积神经网络越深,分析精度越高。
采用深度学习进行目标识别的系统通常具有目标数据庞大的特点,例如,在认知辅助工具和健康系统中分别需要识别许多日常对象和活动,现有技术通常的解决方案是采用非常深的卷积神经网络,这样会导致巨大的训练开销和执行延迟。更重要的是,在日常生活中常用的处理平台,例如利用邻近的台式机或笔记本处理接收到的感知数据,这些资源有限的设备可能无法完全承担这样的开销,也无法满足应用程序的严格的延迟要求,例如其要求设备系统必须在300ms内完成执行过程方可避免明显的视觉滞后。然而,如果盲目地缩小深度学习模型(例如,大小和深度),感知结果可能变得不可靠和不准确,例如压缩模型无法提供可靠的感知能力来区分太多的识别目标;另一方面,也缺乏一种定量的方式来判断在减少资源消耗的前提下是否依然能够满足系统执行的需求。
技术实现要素:
针对现有技术存在的不足,本发明的目的在于,提供一种神经网络及在移动感知设备上部署神经网络的方法,解决现有技术中无法将神经网络部署在移动感知设备上的问题。
为了解决上述技术问题,本发明采用如下技术方案予以实现:
一种神经网络,所述卷积层包括两个子卷积层,其中输入信号依次通过两个子卷积层;
设子卷积层的卷积核为f,则子卷积层的卷积核尺寸f满足
进一步地,所述激活函数层的激活函数为
进一步地,所述激活函数层为三个,三个激活函数层按照输入信号的方向分别为第一激活函数层、第二激活函数层和第三激活函数层,其中第一激活函数层和第二激活函数层的激活函数均为
进一步地,所述卷积层为三个,三个卷积层按照输入信号的方向分别为第一卷积层、第二卷积和第三卷积层,其中第一卷积层包括两个子卷积层。
本发明还提供了一种在移动感知设备上部署神经网络的方法,包括:
构建本发明所述的神经网络;
选取移动感知设备经常出现的场景图片集作为训练图像集;
将训练图像集输入神经网络中进行训练,得到训练后的神经网络;
向训练后的神经网络输入待分析图片,所述待分析图片不属于训练图像集。
进一步地,所述移动感知设备包括智能手表和手机。
本发明与现有技术相比,具有如下技术效果:
本发明深度分析了卷积层参数和卷积层所需要的计算量的关系,通过限定卷积层的计算量从而满足了移动设备有限的资源,并根据此给出了如何设计卷积层的参数的方案,可以在满足有限资源的情况下最大化网络的性能;
本发明通过对神经网络进行重新构造,缩短了识别出待分析图片中物体的时间和计算量,实现了在移动设备上识别图片的功能。
附图说明
图1是典型神经网络模型的结构示意图;
图2是本发明神经网络模型的结构示意图;
图3是本发明的结果对比图。
以下结合附图对本发明的具体内容作进一步详细解释说明。
具体实施方式
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
实施例1:
如图2所示,本实施例提供了一种神经网络,包括多个卷积层、多个激活函数层和多个池化层,所述卷积层包括两个子卷积层,其中输入信号依次通过两个子卷积层;
如图2,卷积层conv1分为第一子卷积层conv1a和第二子卷积层conv1b,输入信号首先输入至第一子卷积层conv1a,第一子卷积层conv1a的输出信号作为第二子卷积层conv1b的输入信号,第二子卷积层conv1b的输出信号作为激活函数层的输入信号,激活函数层的输出信号作为池化层的输入信号。
这样将卷积层分为两个子卷积层可以增加整个神经网络模型的深度,但是若盲目地将卷积层分为两个子卷积层可能会增加每次卷积的浮点计算量,故本发明确定了如何进行对两个子卷积层的卷积核进行划分:
单个卷积层每次卷积的浮点计算量为:nflop=wo×wo×d×(f2×c+1),其中wo为经过卷积后生成图片的大小,d为卷积生成图片的数量,f为卷积核的尺寸,c为通道数。
两个子卷积层每次卷积的浮点计算量为:mflop=2×wo×wo×d×(f2×c+1),为了使mflop≤nflop,则
设子卷积层的卷积核为f,则子卷积层的卷积核尺寸f满足
其中,所述激活函数层的激活函数为
在现有技术中激活函数层的激活函数通常为
本实施例中的激活函数层为三个,三个激活函数层按照输入信号的方向分别为第一激活函数层、第二激活函数层和第三激活函数层,其中第一激活函数层和第二激活函数层的激活函数均为
这样将第一激活函数层和第二激活函数层的激活函数设置为elu是为了保护从每一帧高质量图片中提取的特征,第三激活函数层的激活函数设置为relu是为了保持神经网络模型的计算量。
其中,所述卷积层为三个,三个卷积层按照输入信号的方向分别为第一卷积层、第二卷积和第三卷积层,其中第一卷积层包括两个子卷积层。
由于考虑到神经网络模型的计算量,本实施例中的卷积层为三个,且只将第一卷积层分为两个子卷积层,其余两个卷积层均不进行划分。
实施例2:
本实施例提供了一种在移动感知设备上部署神经网络的方法,包括:
构建实施例1提供的神经网络;
选取移动感知设备经常出现的场景图片集作为训练图像集;
将训练图像集输入神经网络中进行训练,得到训练后的神经网络;
向训练后的神经网络输入待分析图片,所述待分析图片不属于训练图像集。
其中,所述移动感知设备包括智能手表、智能眼睛和智能手机。
实验结果分析:
图3是根据本申请的方法进行实验的实验结果图,其中elu代表采用分解卷积层,但是每个卷积层后面都采用elu作为激活函数;relu代表每个卷积层后都采用relu作为激活函数。noseparated代表没有采用分解卷积层策略;除此之外,还进行了池化层的测试。最终的实验结果表明本申请的方法能够取得较为明显的优势。
- 还没有人留言评论。精彩留言会获得点赞!