一种基于深度卷积神经网络的行人重识别监控系统的制作方法
本发明涉及计算机识别领域,尤其涉及一种基于深度卷积神经网络的行人重识别监控系统。
背景技术
以下陈述仅提供与本发明有关的背景信息,而不必然地构成现有技术。
行人重识别指在没有视角重叠的多台摄像机监控下,对行人目标进行相似度匹配的过程,即给定一个行人目标,在多台不同位置的摄像机不同时刻拍摄的视频中找到并锁定该目标。
在目前的技术当中,由于摄像机分辨率一般较低,较难得到人脸等有辨识度的特征,另外受光照、视角等影响,同一个行人在不同摄像机中有很大差异,同时,高维视觉特性通常难以捕获样本的不变因素,导致传统的行人重识别方法存在难以同时识别多个行人、运算消耗时间、识别效率和正确率偏低等不足。因此,行人重识别方法急需进一步研究。
技术实现要素:
为了克服现有技术的不足,本发明所实现的技术目的是提供一种减少多种对识别稳健性的不利影响因素,从而提高对行人目标进行相似度匹配正确率的基于深度卷积神经网络的行人重识别监控系统。
为达到上述技术目的,本发明所采用的技术方案内容具体如下:
一种基于深度卷积神经网络的行人重识别监控系统,所述系统包括:视频采集装置,识别监控装置和行人数据库;
所述视频采集装置用于采集被测行人图像;
所述行人数据库用于存储目标行人图像;
所述识别监控装置用于从所述视频采集装置获取被测行人图像;从所述行人数据库中获取所述目标行人图像,利用所述目标行人图像应用深度卷积神经网络学习得出目标行人特征;并根据所述目标行人特征匹配判断所述被测行人图像是否为目标行人。
需要说明的是,所述视频采集装置可以包括若干个视频采集点,便于从各个角度位置上采集视频信息,提高系统的可使用性。
为减少多种对识别稳健性的不利影响因素,如分辨率、光照、视角等,从而实现对于识别匹配更准确的技术目的,发明人在本技术方案中利用了深度卷积神经网络学习得出目标行人特征,通过度量学习算法对目标行人特征进行识别;由于所述深度卷积神经网络已经过学习训练,因此能够综合了行人的多种特征信息,从而在后续的识别中能够有效克服分辨率、光照、视角等对识别稳健性的不利影响,提高对目标行人进行相似度匹配的正确率。
优选地,所述视频采集装置包括高速网络球机和交换机,所述高速网络球机和交换机通过无线网络连接。
优选地,所述识别监控装置还包括输入装置;所述识别监控装置还用于从所述输入装置中获取所述目标行人描述后,通过自然语言处理所述目标行人描述并筛选出目标行人关键信息,然后利用所述目标行人关键信息应用深度学习得出目标行人特征。
需要说明的是,所述目标行人关键信息指的是颜色、性别及年龄段等,在此技术步骤中,仅需输入相关行人描述,通过自然语言处理之后会自动筛选出相关信息,系统根据这些信息利用视频采集装置进行采集,并进行行人识别匹配。
优选地,所述识别监控装置还用于利用所述视频采集装置采集所述目标行人的运动视频和运动轨迹,并将所述目标行人的运动视频和运动轨迹信息对所述目标行人的未来运动轨迹进行预测。
更优选地,所述识别监控装置还用于在预测所述目标行人的未来运动轨迹后将所述未来运动轨迹进行可视化显示。
需要说明的是,本监控系统还能在识别匹配出目标行人后,利用视频采集装置收集目标行人的运动视频和运动轨迹;所述运动视频可以通过视频采集装置的视频采集功能进行采集,而运动轨迹则需要结合视频采集装置的定位进行采集,因此在实现本技术方案时,视频采集装置中的各个视频采集点的位置是已知的,根据这些已知的位置,结合行人的行进轨迹,即可实现对行人运动轨迹的采集。而结合所述运动视频和运动轨迹,识别监控装置还能进一步对所述目标行人的未来运动轨迹进行预测。更进一步地,在得出预测结果之后,系统还能结合已有的地图对所述预测结果进行可视化展示,提高本系统的适用性。
优选地,所述深度卷积神经网络的构建方法是利用在imagenet上预训练好的alexnet神经网络,并利用所述行人数据库中的数据集进行训练得出。
需要说明的是,为实现对深度卷积神经网络的构建和学习训练,一方面在构建的时候采用在imagenet上预训练好的alexnet神经网络作为基础,由于alexnet神经网络已综合多种图像特征信息,因此可以方便后续进行训练;进一步地,alexnet网络模型有超过6000万个参数,因此需要大量样本进行训练。imagenet数据集的训练集大约有1000个分类,每类大约有1000张图片,应用imagenet训练alexnet网络,可得到较好的训练效果;另一方面,系统还利用所述行人数据库中的数据集对所述神经网络进行学习训练,相较于传统行人重识别需先进行行人特征识别,深度卷积神经网络直接数据集进行训练,训练过程综合利用了行人的多特征信息,结果使得多特征信息融合,提高了数据集的利用率。因此在后续的识别匹配过程中,采用已训练的神经网络提取行人特征,从而克服光照、视角等的影响,能够有效提高对目标行人进行相似度匹配的正确率。
更优选地,所述行人数据库的数据集包括带有标签的公共数据集和不带有标签的真实数据集。
需要说明的是,在进行行人重识别训练时,需要有预处理过的行人图像作为训练图像和测试图像。由于真实数据集整理难度较高,周期较长,所以在本技术方案中,一方面采用己经存在的公共数据集进行行人重识别训练,另一方面在对公共数据集训练后结合真实数据集再结合训练,可以使得训练出的神经网络更为全面地考虑到各种因素。
在一些实施方式中,所述公共数据集包括viper、cuhk01、ilids中的一种或多种。
需要说明的是,在本技术方案中采用的是上述数据集中的一种或多种。
需要说明的是,viper(viewinvariantpedestrianrecognition)是由加利福利亚大学的gray等人采集完成的,是目前最具有挑战性的行人重识别数据库。数据集共有632个行人图像,每个行人有两张在不同摄像机下的不同角度的图像,一共有1024张图像。数据集包含了不同拍摄视角下的行人图像,存在着姿势、光照等变化,且大多数图片存在较大的视角转换。viper数据集将每幅图像统一处理成128*48的大小,便于特征的提取。
需要说明的是,cuhk01数据集是由香港中文大学研究团队建立的,该数据集包含971个不同行人在两台摄像机下的共3884张图像。平均每个行人有4张图像,其中两张是由摄像机a捕获的行人的正面和背面图像,另外两张是由摄像机b捕获的行人的侧面图像。每个行人在同一摄像机下拍摄的两张图像只存在姿态上的少许变化,在不同摄像机下拍摄的图像在姿态、视角、光照上都有比较明显的变化。
需要说明的是,ilids数据集是由两个非重叠的相机视图根据i-lids多摄像机跟踪观察行人方案(mcts)创建的数据集,通过多摄像机的监控网络在机场到达大厅进行拍摄的。它包括300个不同个体的600个图像序列,每个人从两个相机视图中得到一对图像序列。每个图像序列具有从23到192帧图像的可变长度,平均数量为73。ilids视频数据集中服装相似人的照明和姿态的变化、杂乱的背景和随机遮挡物都为识别增加了挑战性。为了便于评估基于单镜头的人对该数据集的重新识别方法,ilids数据集还通过从每个人的图像序列中随机选择一个图像来提供基于静态图像的版本。
因此采用上述公共数据集中的一种或多种,优选为三种进行训练,可以考虑到图像特征的各种因素,使得后续的识别匹配更为准确。
需要说明的是,真实数据集由监控系统的视频采集装置获取,由于需要考虑到光照、视角等环境因素以及分辨率、焦距等系统因素对视频效果的影响,监控系统的视频采集系统的采集点需要布置在实际人流密集的场合,对实验目标的人体姿势及行为姿态的数据集进行收集标注,建立行人重识别数据集(真实数据集),并存储于系统中。
在一些实施方式中,所述深度卷积神经网络的构建方法还包括数据集迁移学习,即利用所述公共数据集的训练标签,并利用所述公共数据集迁移到真实数据集中训练神经网络。
需要说明的是,考虑公开数据集与真实数据集之间的差异,从而导致在公开数据集上训练好的模型在现实数据上性能表现不佳的问题,因此需要统筹各个数据集的合理使用。
由于不同数据集合之间视角、环境等之间的差异,在一个数据集合上训练的模型直接应用于另外一个数据集合时,re-id性能可能会出现大幅度的下降。为此,本技术方案采用learningviatranslation框架,利用已有标签的公开数据集,获得监控系统数据集的训练标签,从而利用监控系统数据集训练神经网络,避免不同数据集差异造成的re-id性能下降。
更进一步地,所述迁移学习的具体方法包括:
假设所述公共数据集为给定源域s上带标签的数据集合,所述真实数据集为目标域t上没有带标签的数据集合,首先,将s域上带标签的训练数据的风格迁移到t域的风格之上;然后,利用风格迁移后的训练数据,训练出一个re-id模型。
需要说明的是,由于该模型利用风格为t域上的数据训练得到,故能较好地适应t域的特征,相对于s域在t域上更具备适应性,从而实现在s域上训练的re-id模型能很好地应用于t域。
更进一步地,所述迁移学习所采用的算法是相似度循环一致对抗生成网络源-目标迁移算法。
需要说明的是,该算法采用自相似和区域相作为迁移指标。自相似以同一数据集中的同一图像迁移前后的特征距离来衡量,特征距离需要越近越好。区域相异以不同数据中的两张图像的特征距离来衡量,特征距离需要越远越好。基于上述两点,嵌入无监督暹罗网络,采用对比损失来进行训练。从而实现迁移后图像的风格要和目标域的风格一致,并且图像迁移前后图像行人区域不变。
与现有技术相比,本发明的有益效果在于:
1、本发明的行人重识别监控系统,利用了深度卷积神经网络学习得出目标行人特征,通过度量学习算法对目标行人特征进行识别,综合了行人的多种特征信息,从而在后续的识别中能够有效克服分辨率、光照、视角等对识别稳健性的不利影响,提高对目标行人进行相似度匹配的正确率;
2、本发明的行人重识别监控系统,在构建神经网络的时候采用在imagenet上预训练好的alexnet神经网络作为基础,可以方便后续进行训练也能达到较好的训练效果;
3、本发明的行人重识别监控系统,在对数据集进行训练时,一方面采用己经存在的公共数据集进行行人重识别训练,另一方面在对公共数据集训练后结合真实数据集再结合训练,可以使得训练出的神经网络更为全面地考虑到各种因素;
4、本发明的行人重识别监控系统,利用已有标签的公开数据集,获得监控系统数据集的训练标签,从而利用监控系统数据集训练神经网络,避免不同数据集差异造成的re-id性能下降。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1为本发明的行人重识别监控系统一种较优选实施方式的结构示意图;
图2为本发明的行人重识别监控系统视频采集装置的一种优选实施方式的框架原理示意图;
图3为本发明的行人重识别监控系统中输入装置输入行人描述的一种优选实施方式的界面示意图;
图4为本发明的行人重识别监控系统中对行人未来运动轨迹进行预测的一种优选实施方式的界面示意图;
图5为本发明的行人重识别监控系统中对行人运动轨迹进行检测的一种优选实施方式的界面示意图;
图6为本发明的行人重识别监控系统监控识别过程中一种优选实施方式的流程示意图;
图7为本发明的行人重识别监控系统获取真实数据集过程的一种优选实施方式的框架原理示意图;
其中,各附图标记为:11、高速网络球机;12、交换机;2、主控计算机;3、存储服务器;4、数字矩阵。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明的具体实施方式、结构、特征及其功效,详细说明如下:
实施例1
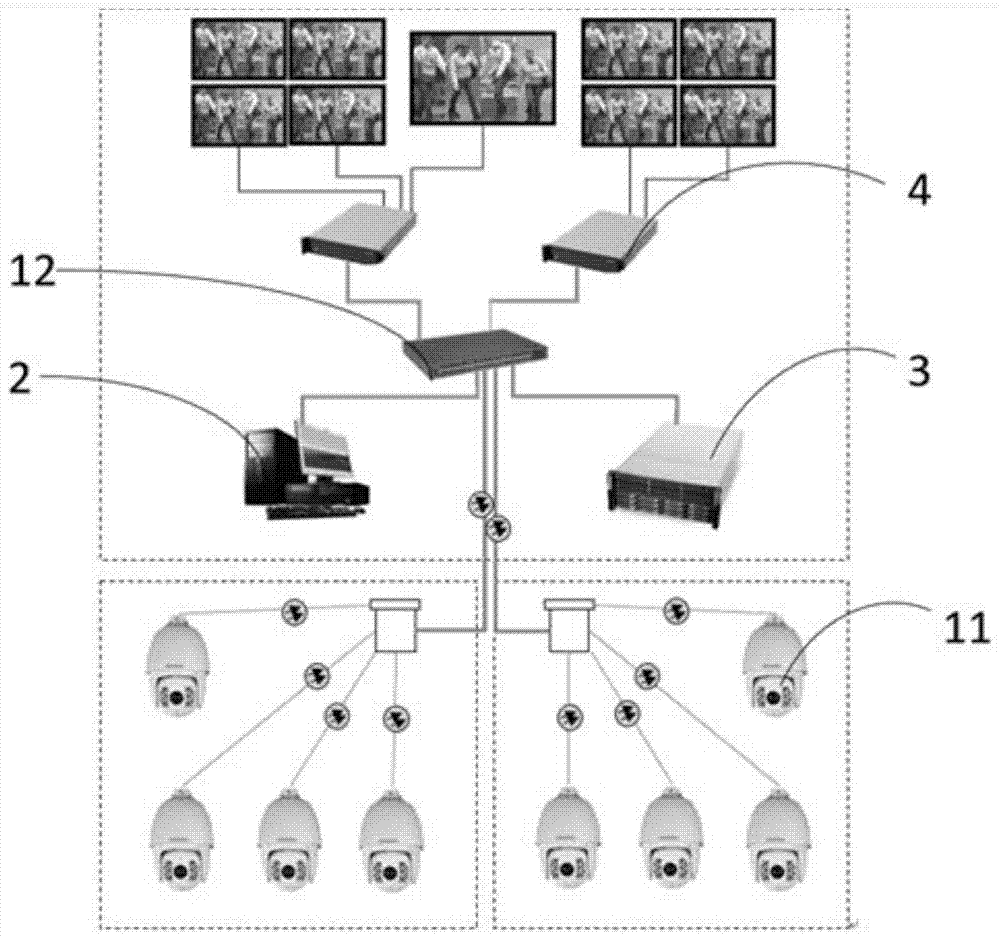
本发明提供一种基于深度卷积神经网络的行人重识别监控系统,如图1所示,所述系统包括:
作为视频采集装置的摄像机网络,所述摄像机网络是若干高速网络球机11应用wifi与交换机12形成的;所述视频采集装置用于采集被测行人图像;
作为识别监控装置的,具有识别监控功能的主控计算机2;
存储有行人数据库的存储服务器3;所述行人数据库用于存储目标行人图像;
所述识别监控装置用于从所述视频采集装置获取被测行人图像;从所述行人数据库中获取所述目标行人图像,利用所述目标行人图像应用深度卷积神经网络学习得出目标行人特征;并根据所述目标行人特征匹配判断所述被测行人图像是否为目标行人。
交换机上连接主控计算机和存储服务器。
需要说明的是,主控计算机可以是高性能深度学习专用服务器,以满足训练模型的计算量需求。在更具体的优选实施方式中,其硬件配置为gpu:nvidiagtx1070(2张),其中每张显卡单精度浮点运算性能约5.7tflops,显存共8g,拥有1920个流处理器核心,cpu:i7920,2.66ghz,四核八线程,ram:18g。服务器采用可裁剪的ubuntu16.04操作系统,并配置专用开发包和开发框架,安装开发框架相关依赖库、opencv及cuda8.0,以形成caffe框架等的开发环境。
需要说明的是,视频采集装置可以通过控制外接的usb网络球机摄像头实现,并在dsp芯片上进行视频压缩处理,最终通过控制外接的无线网卡将打包好的数据传输出去。网络球机为自主开发,如图2所示为高速网络球机结构组成框图为满足高速化需求,选用arm处理器作为数据处理核心,配合usb数据接口、wifi数据接口等,形成高速化的网络摄像头。在视频监控客户端负责与服务器交互传递息,实现控制和显示等功能。嵌入式处理器是视频前端的核心部分,它决定整个视频的采集处理与传输能力大小,从而间接影响整个系统的流畅和稳定。
需要说明的是,监控识别系统里的软件设计可以是在matlab平台上应用matconvnet开发,配合axurerp8设计相应的界面。matconvnet是matlab的一个用于搭建计算机视觉应用的卷积神经网络(cnn)的工具箱。该工具箱中包含了卷积神经网络和计算机视觉相关的函数和类,实现了很多卷积神经常用的算法。matconvnet提供许多己预训练可用于图像分类、分割、面部识别、文本检测的卷积神经网络,通过调用matconvnet函数,研究者可以在其他己完成的成熟算法基础上迅速展开自己的工作。开发环境主要为matlab2015a、matconvnet-l.0-beta64环境下完成,其中部分算法在visualstudio2010中的采用c++辅助完成。
以上是本发明行人重识别监控系统的一种基础实施方式的一些具体实施方案的列举。发明人在本技术方案中利用了深度卷积神经网络学习得出目标行人特征,通过度量学习算法对目标行人特征进行识别;由于所述深度卷积神经网络已经过学习训练,因此能够综合了行人的多种特征信息,从而在后续的识别中能够有效克服分辨率、光照、视角等对识别稳健性的不利影响,提高对目标行人进行相似度匹配的正确率。
结合上述实施方式,在另一种优选的实施方式中,如图1所示,所述系统还包括:交换机上连接的数字矩阵4,使得监测过程实时可见。
实施例2
本实施例是在上述实施例基础实施方式上的一种优选实施方式,本实施例与上述实施例1的区别在于:
在本实施例中所述监控识别系统所述识别监控装置还包括输入装置;所述识别监控装置还用于从所述输入装置中获取所述目标行人描述后,通过自然语言处理所述目标行人描述并筛选出目标行人关键信息,然后利用所述目标行人关键信息应用深度学习得出目标行人特征。所述目标行人关键信息指的是颜色、性别及年龄段等,在此技术步骤中,仅需输入相关行人描述,通过自然语言处理之后会自动筛选出相关信息,系统根据这些信息利用视频采集装置进行采集,并进行行人识别匹配。如图3所示就给出了其中一种实施方式的界面示意图。
结合上述实施方式,在另一个方面,所述识别监控装置还用于利用所述视频采集装置采集所述目标行人的运动视频和运动轨迹,并将所述目标行人的运动视频和运动轨迹信息对所述目标行人的未来运动轨迹进行预测。
结合上述实施方式,在又一个方面,所述识别监控装置还用于在预测所述目标行人的未来运动轨迹后将所述未来运动轨迹进行可视化显示,如图4和图5所示。图4表示了为了增强用户的可视化及进行用户的路径预测,用户在完成行人的再识别后,系统可以通过分布显示将检测到的结果显示到地图中,用户可以通过移动地图或点击出现的地点来具体观看检测点视频的前后10秒回放,方便用户具体了解兴趣目标的出现地。图5表示了用户可以通过路径预测功能可以预测兴趣目标在监测点后的行走路线,并标出相应的概率,供使用者进行判断。
如图6所示是结合了上述三种实施方式时,所述监控识别系统在监控识别操作中的一种优选流程操作实现图。
本实施例的其余优选实施方式与上述实施例相同,在此不再赘述。
实施例3
本实施例是在上述实施例基础实施方式上的一种优选实施方式,本实施例与上述实施例1的区别在于:本实施例是对数据集优选实施方式的一些举例和说明。
在一些优选实施方式中,所述行人数据库的数据集包括带有标签的公共数据集和不带有标签的真实数据集。在进行行人重识别训练时,需要有预处理过的行人图像作为训练图像和测试图像。由于真实数据集整理难度较高,周期较长,所以在本技术方案中,一方面采用己经存在的公共数据集进行行人重识别训练,另一方面在对公共数据集训练后结合真实数据集再结合训练,可以使得训练出的神经网络更为全面地考虑到各种因素。
在一些实施方式中,所述公共数据集包括viper、cuhk01、ilids中的一种或多种。在本技术方案中采用的是上述数据集中的一种或多种。更优选地,采用全部这三种公共数据集。
viper(viewinvariantpedestrianrecognition)是由加利福利亚大学的gray等人采集完成的,是目前最具有挑战性的行人重识别数据库。数据集共有632个行人图像,每个行人有两张在不同摄像机下的不同角度的图像,一共有1024张图像。数据集包含了不同拍摄视角下的行人图像,存在着姿势、光照等变化,且大多数图片存在较大的视角转换。viper数据集将每幅图像统一处理成128*48的大小,便于特征的提取。
cuhk01数据集是由香港中文大学研究团队建立的,该数据集包含971个不同行人在两台摄像机下的共3884张图像。平均每个行人有4张图像,其中两张是由摄像机a捕获的行人的正面和背面图像,另外两张是由摄像机b捕获的行人的侧面图像。每个行人在同一摄像机下拍摄的两张图像只存在姿态上的少许变化,在不同摄像机下拍摄的图像在姿态、视角、光照上都有比较明显的变化。
ilids数据集是由两个非重叠的相机视图根据i-lids多摄像机跟踪观察行人方案(mcts)创建的数据集,通过多摄像机的监控网络在机场到达大厅进行拍摄的。它包括300个不同个体的600个图像序列,每个人从两个相机视图中得到一对图像序列。每个图像序列具有从23到192帧图像的可变长度,平均数量为73。ilids视频数据集中服装相似人的照明和姿态的变化、杂乱的背景和随机遮挡物都为识别增加了挑战性。为了便于评估基于单镜头的人对该数据集的重新识别方法,ilids数据集还通过从每个人的图像序列中随机选择一个图像来提供基于静态图像的版本。
因此采用上述公共数据集中的一种或多种,优选为三种进行训练,可以考虑到图像特征的各种因素,使得后续的识别匹配更为准确。
在另一个方面,真实数据集由监控系统的视频采集装置获取,由于需要考虑到光照、视角等环境因素以及分辨率、焦距等系统因素对视频效果的影响,监控系统的视频采集系统的采集点需要布置在实际人流密集的场合,对实验目标的人体姿势及行为姿态的数据集进行收集标注,建立行人重识别数据集(真实数据集),并存储于系统中。所获取的方式可以如图7所示,需要指出的是,图7中的摄像机网络监控平台即为上述所指的视频采集装置的一种具体实施方式。
本实施例的其余优选实施方式与上述实施例相同,在此不再赘述。
实施例4
本实施例是在上述实施例基础实施方式上的一种优选实施方式,本实施例与上述实施例1的区别在于:本实施例是对深度卷积神经网络构建方法具体实施方式的列举和说明。
在一种优选的实施方式中,所述深度卷积神经网络的构建方法是利用在imagenet上预训练好的alexnet神经网络,并利用所述行人数据库中的数据集进行训练得出。
为实现对深度卷积神经网络的构建和学习训练,在一个方面中,在构建的时候采用在imagenet上预训练好的alexnet神经网络作为基础。由于alexnet神经网络已综合多种图像特征信息,因此可以方便后续进行训练;进一步地,alexnet网络模型有超过6000万个参数,因此需要大量样本进行训练。imagenet数据集的训练集大约有1000个分类,每类大约有1000张图片,应用imagenet训练alexnet网络,可得到较好的训练效果。
在另一方面中,系统还利用所述行人数据库中的数据集对所述神经网络进行学习训练,相较于传统行人重识别需先进行行人特征识别,深度卷积神经网络直接数据集进行训练,训练过程综合利用了行人的多特征信息,结果使得多特征信息融合,提高了数据集的利用率。因此在后续的识别匹配过程中,采用已训练的神经网络提取行人特征,从而克服光照、视角等的影响,能够有效提高对目标行人进行相似度匹配的正确率。
本实施例的其余优选实施方式与上述实施例相同,在此不再赘述。
实施例5
本实施例是在上述实施例基础实施方式上的一种优选实施方式,本实施例与上述实施例1的区别在于:本实施例是对深度卷积神经网络的构建方法还包括数据集迁移学习的方式的列举和说明。
在一些实施方式中,所述深度卷积神经网络的构建方法还包括数据集迁移学习,即利用所述公共数据集的训练标签,并利用所述公共数据集迁移到真实数据集中训练神经网络。考虑公开数据集与真实数据集之间的差异,从而导致在公开数据集上训练好的模型在现实数据上性能表现不佳的问题,因此需要统筹各个数据集的合理使用。
由于不同数据集合之间视角、环境等之间的差异,在一个数据集合上训练的模型直接应用于另外一个数据集合时,re-id性能可能会出现大幅度的下降。为此,本技术方案采用learningviatranslation框架,利用已有标签的公开数据集,获得监控系统数据集的训练标签,从而利用监控系统数据集训练神经网络,避免不同数据集差异造成的re-id性能下降。
例如,在一些具体实施方式中,所述过程可以是:
首先使用在imagenet上预训练好的alexnet进行特征提取。然后,设计了一种的卷积神经网络结构,将训练得到的模型用于行人特征提取。接着,使用迁移学习的方法,在有标签的数据集cuhk01、viper和无标签真实数据集xh-001上训练,得到最终模型并在真实数据集xh-001的测试集上进行测试。最后,通过cmc曲线进行效果评估,并将其部署在摄像机网络监控平台上。
在一些更具体的优选实施方式中,所述迁移学习的具体方法包括:
假设所述公共数据集为给定源域s上带标签的数据集合,所述真实数据集为目标域t上没有带标签的数据集合,首先,将s域上带标签的训练数据的风格迁移到t域的风格之上;然后,利用风格迁移后的训练数据,训练出一个re-id模型。由于该模型利用风格为t域上的数据训练得到,故能较好地适应t域的特征,相对于s域在t域上更具备适应性,从而实现在s域上训练的re-id模型能很好地应用于t域。
在一些更具体的优选实施方式中,所述迁移学习所采用的算法是相似度循环一致对抗生成网络源-目标迁移算法。该算法采用自相似和区域相作为迁移指标。自相似以同一数据集中的同一图像迁移前后的特征距离来衡量,特征距离需要越近越好。区域相异以不同数据中的两张图像的特征距离来衡量,特征距离需要越远越好。基于上述两点,嵌入无监督暹罗网络,采用对比损失来进行训练。从而实现迁移后图像的风格要和目标域的风格一致,并且图像迁移前后图像行人区域不变。
本实施例的其余优选实施方式与上述实施例相同,在此不再赘述。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!