基于相关滤波以及深度孪生网络的鲁棒长程目标跟踪方法与流程
本发明涉及计算机视觉技术,具体涉及基于相关滤波以及深度孪生网络的鲁棒长程目标跟踪方法。
背景技术:
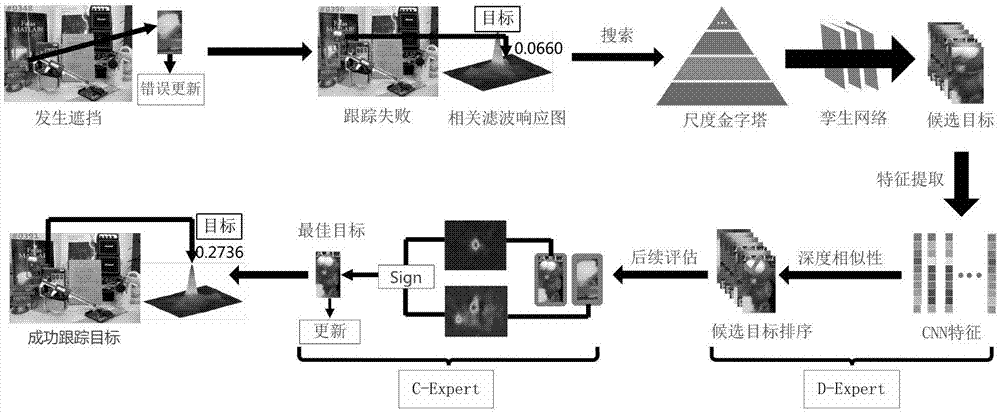
作为计算机视觉领域一个基础性的研究课题,目标跟踪在视频监控、人机交互、虚拟现实、智能机器人以及自动驾驶等领域,均有着广泛的应用。经过长时间的研究,目标跟踪领域涌现出了大量优秀的目标跟踪算法。根据要处理的视频长短进行划分,目标跟踪算法可分为短程的目标跟踪算法以及长程的目标跟踪算法。在实际应用中,由于目标经常会经历长时间的遮挡,旋转以及光照等挑战,使得短程的目标跟踪算法无法长时间准确的跟踪目标。因此,研究出一个鲁棒的长程跟踪算法,能有效的处理遮挡、消失视野等挑战,使得跟踪器能长时间准确的跟踪目标,具有重要的现实意义。近几年,基于相关滤波的目标跟踪算法研究取得了显著的进展。在2010年,bolme首先提出了基于相关滤波的moose跟踪算法,通过傅里叶变换将求解岭回归问题切换到频域进行,极大地提升了计算速度。heriques在2012年提出了csk算法,利用循环位移矩阵来构建训练样本,进一步提高了跟踪速度。在2014年,heriques又提出了kcf跟踪算法,使用多通道的hog特征替换了在csk中使用的灰度特征,有效地提升了跟踪的准确度。虽然上述方法都均能达到远超实时的跟踪速度,但是他们的跟踪转确度仍较低,难以满足实际要求。为了进一步提升跟踪精度,一些基于cnn特征的相关滤波跟踪算法在近两三年被相继提出。ma于2015年提出了hcf跟踪算法,在kcf跟踪框架下,使用更为鲁棒的cnn特征替换了hog特征,大幅提升了相关滤波跟踪的准确度。danelljan通过解决相关滤波的边界效应问题以及在相关滤波跟踪框架下引入cnn特征,使得相关滤波跟踪更为准确。2016年,qi提出使用一种改进的hedge算法,来融合多个使用不同cnn特征训练得到的相关滤波模型,使其得到更为鲁棒的跟踪结果。同年,danelljan提出c-cot跟踪算法,通过训练连续的卷积核,来有效地融合不同分辨率的cnn特征图,达到了较高的跟踪精度。为了进一步提高c-cot的跟踪精度以及速度,danelljan于2017年提出了一种更为有效的卷积操作,解决了原先卷积操作带来的特征稀疏问题,大大提升了跟踪精度以及速度。虽然基于cnn特征的相关滤波跟踪算法具有一定鲁棒性,但他们仍然无法处理长视频中的长时间遮挡、消失视野等挑战,在目标发生遮挡后,跟踪器长时间的错误更新导致他们最终丢失目标。为了更为鲁棒的处理长视频中存在的挑战,具有代表性的一个算法是kalal在2010年提出的tld算法,与传统的跟踪算法不同,tld包含跟踪器和检测器两部分。跟踪器使用光流法进行目标定位,检测器使用随机蕨分类器,前者为后者提供在线训练样本,后者用于跟踪失败后重定位目标并初始化跟踪器。这样的结构一定程度上解决了短时间的目标遮挡、消失视野等问题。2015年,ma提出了一个基于相关滤波的长程跟踪算法(lct),其结构与tld相类似,lct使用相关滤波作为跟踪器,随机蕨分类器作为检测器,由于相关滤波能对物体表观变化更有效建模,因此在对非刚体的跟踪中,lct比tld具有更好的效果。然而,由于lct和tld中的跟踪器以及检测器均需要在线更新,在遇到长视频中目标长时间遮挡或消失视野的情况,其跟踪器以及检测器均有可能因为长时间地错误更新导致失效,造成跟踪失败。因此,如何设计一个鲁棒的长程跟踪算法,能有效地处理长视频中目标长时间的遮挡或消失视野,具有重大的意义。深度学习在近几年被广泛的运用于计算机视觉的研究。2012年,krizhevsky使用alexnet以绝对的优势赢得了imagenet的比赛,点燃了人们对深度学习的研究热情。在接下去的几年,深度学习被成功运用于目标检测、显著性检测、语义分割、度量学习以及行人再识别等各个领域。但是,与此相比,深度学习在目标跟踪领域中的运用具有一定的局限性,主要原因有两方面:(1)在线训练样本量的缺少;(2)在线训练模型非常的耗时。两方面的原因制约着深度学习在目标跟踪中的应用。最早使用深度学习来实现目标跟踪的是wang于2013年提出的dlt跟踪算法,其使用粒子滤波来在线采集正负样本,以此训练网络。随后的几年,各种基于卷积神经网络的目标跟踪算法如so-dlt、fcnn、mdnet以及sanet被相继提出,这类算法通过采集跟踪过程中的正负样本来进行网络的训练,虽然能达到更高的精度,但是远未达到实时跟踪的要求。2016年,bertinetto提出使用深度孪生网络来进行目标跟踪,该网络在ilsvrc数据集上进行离线的训练。在跟踪时,仅使用第一帧作为目标模版,在测试帧中找到与目标模版最为相似的区域作为跟踪结果。此方法能达到远超实时的跟踪速度,但由于缺少线上的更新,当目标表观剧烈变化时,跟踪效果不甚理想。技术实现要素:本发明的目的在于提供通过将相关滤波以及深度孪生网络结合在一个统一的跟踪框架下,能够有效处理长视频中目标遮挡、消失视野等挑战,所提出的基于d-expert以及c-expert的专家评估机制能有效地对相关滤波以及深度孪生网络共同产生的目标候选位置进行评估筛选,得到最佳的目标跟踪结果,使用该结果来更新相关滤波跟踪器,能有效避免相关滤波跟踪器被被错误样本影响,对长视频中存在的各类挑战较为鲁棒,能够长时间稳定跟踪目标的基于相关滤波以及深度孪生网络的鲁棒长程目标跟踪方法。本发明包括以下步骤:1)给定一帧训练视频,以目标为中心划定训练区域,该训练区域完全包含目标以及部分的背景区域;在步骤1)中,所述划定训练区域的方法可为:以目标为中心,构建一个矩形的训练区域,所述矩形的训练区域的长宽分别为目标的长宽;若矩形的训练区域超出训练视频帧,则使用平均像素进行填充。2)使用预训练好的vgg-net-19模型对步骤1)中得到的训练区域提取cnn特征;在步骤2)中,所述使用预训练好的vgg-net-19模型对步骤1)中得到的训练区域提取cnn特征具体过程可为:对步骤1)中得到的矩形的训练区域使用双线性插值方法,改变其大小,使其大小变为网络要求的输入大小(224×224×3),并取其l层(对应于vgg-net-19模型中的conv3-4,conv4-4以及conv5-4层)的输出,作为提取的cnn特征,记为xl,其中m,n和d分别为特征图的长宽以及通道数。3)使用步骤2)中得到的cnn特征训练相关滤波模型,公式(1)如下:其中,λ为正则化参数,y(m,n)是一个连续性的高斯标签,其中σ表示线性核的带宽,公式(1)是一个典型的岭回归,求解可得:其中,为训练得到的相关滤波模型,为的共轭,和y分别为以及高斯标签y的离散傅里叶变换,为点乘运算;在步骤3)中,所述λ=10-4,σ=10-1。4)给定一帧测试视频,利用训练好的相关滤波模型对搜索区域进行响应,得到响应图,响应图中响应值最大的位置确定为目标初始位置;在步骤4)中,所述响应图中响应值最大的位置确定为目标初始位置的具体过程可为:提取测试视频中搜索区域在vgg-net-19模型中l层的cnn特征,记为zl,zl和xl大小相同,相关滤波模型在zl上的响应图可通过以下公式(3)计算:其中,fl表示相关滤波模型在l层特征的响应图,f-1表示逆傅里叶变换,为的离散傅里叶变换;为了提升跟踪的鲁棒性,可使用vgg-net-19模型提取不同层的特征来进行目标定位,给定共l层的特征图通过公式(3),可以得到相关滤波模型在不同层特征上的响应图,记为则相关滤波模型估计的初始目标位置可计算为:其中,为相关滤波模型估计的目标位置,γl为在l层特征上的响应图的权重。所述给定一帧测试视频可使用相关滤波模型来估计目标位置,包括以下子步骤:a.公式(4)使用的cnn特征层数l被设为3,分别为vgg-net-19模型中的conv3-4,conv4-4以及conv5-4层;b.公式(4)conv3-4,conv4-4以及conv5-4层特征对应的权重分别被设为0.5,1,0.02。5)在测试视频中,以上一帧目标为中心,构建搜索尺度金字塔;在步骤5)中,所述构建搜索尺度金字塔的具体过程可为:以上一帧目标为中心,在上一帧目标尺度的基础上,构建q个尺度因子,并与原有目标尺度相乘,得到q个不同尺度的搜索区域,并使用双线性差值将其大小变为等大小(255×255×3),记为所述q=36。6)使用预训练好的深度孪生网络,以第一帧视频中的目标为模板,在步骤5)中得到的每个尺度上进行模板的匹配,得到每个尺度下置信度最高的候选目标位置,并以置信度进行排序,得到置信度最高的k个候选目标位置,计算过程如下:其中,o为目标模板,s(,)为深度孪生网络离线学习得到的相似性度量函数,度量结果返回为相似性图,记为目标模板在q搜索尺度下的最佳相似性值,对进行排序,可以得到前k个候选目标位置,记为集合令集合u用以表示所有候选目标位置,则在步骤6)中,所述深度孪生网络的参数k设置为1(见文献:lucabertinetto等人在2016年eccvworkshop上提出)。7)使用基于深度相似性的d-expert对步骤6)中得到的候选目标位置进行评估,得到最佳候选目标位置;在步骤7)中,所述使用基于深度相似性的d-expert对步骤6)中得到的候选目标位置进行评估,得到最佳候选目标位置的具体过程可为:构建在线目标表观模型,所述在线目标表观模型主要包括三类样本:(1)第一帧中的目标样本;(2)跟踪过程中收集的置信度较高的目标样本;(3)前一帧中的目标样本。使用vgg-net-19模型提取这三类样本的全连接层特征,分别记为以及使用集合v来表示这三类样本,则同样的,对u中的候选目标提取全连接特征,记为对于ek∈e,d-expert计算其在v上的累积相似度距离:通过比较累计相似度距离,深度孪生网络搜索得到的最佳候选目标可通过以下公式(7)计算:e-expert进一步对相关滤波估计的目标位置以及孪生网络在不同尺度范围内搜索得到的最佳候选目标进行评估:其中,rd为d-expert的评估值,sign(·)为符号函数,若rd等于1,则孪生网络搜索得到的最佳候选目标在表观模型上的累计距离小于相关滤波估计的候选目标,前者更为可靠,此时再进行后续评估;否则,相关滤波估计的候选目标作为最终跟踪结果;所述在线目标表观模型大小可设置为|v0|=|v1|=|v2|=1。8)使用基于相关滤波的c-expert分别对步骤3)中得到的目标位置以及步骤6)中得到的最佳候选目标位置进行评估,得到最佳目标跟踪结果,完成跟踪;c-expert使用两个相关滤波模型来进行评估,记为和前者仅在第一帧视频进行训练,保留了原有的目标模型,后者在整个跟踪过程中都有训练更新,考虑了物体的形变;令rt(m,n)和r1(m,n)分别表示相关滤波模型及在位置(m,n)处的响应值;c-expert对相关滤波模型估计的目标位置以及深度孪生网络搜索得到的最佳目标位置进行评估:其中,rc为c-expert的评估值。若rc为1,则选择为最终跟踪结果;否则,作为最终跟踪结果;若表明深度孪生网络搜索得到的最佳位置考虑了更多物体的形变,更为可靠;若则表明相关滤波模型很可能已经被错误的更新,深度孪生网络得到的结果在中有更高的响应值,置信度更高,因此选择此结果作为最终跟踪结果。本发明通过将相关滤波以及深度孪生网络结合在一个统一的跟踪框架下,能够有效处理长视频中目标遮挡、消失视野等挑战。在该跟踪方法中,所提出的基于d-expert以及c-expert的专家评估机制能有效地对相关滤波以及深度孪生网络共同产生的目标候选位置进行评估筛选,得到最佳的目标跟踪结果,使用该结果来更新相关滤波跟踪器,从而有效避免了相关滤波跟踪器被错误样本更新。本发明提出的目标跟踪方法对长视频中的各类挑战较为鲁棒,能够长时间稳定跟踪目标。附图说明图1为本发明实施例的整体流程示意图。图2为本发明实施例在目标遮挡视频中的定性跟踪结果。其中矩形框为本发明得到的目标跟踪结果。具体实施方式下面结合附图和实施例对本发明的方法作详细说明。参见图1,本发明实施例的实施方式包括以下步骤:1)给定一帧训练视频,以目标为中心划定训练区域,该训练区域完全包含目标以及部分的背景区域。划分方法如下:以目标为中心,构建一个矩形的训练区域,该矩形区域的长宽分别为目标长宽的;若矩形区域超出训练视频帧,则使用平均像素进行填充。2)使用预训练好的vgg-net-19模型对步骤1)中得到的训练区域提取cnn特征。具体过程如下:对步骤1)中得到的矩形训练区域使用双线性插值,改变其大小,使其大小符合网络要求的输入大小(224×224×3),并取其l层(对应于vgg-net-19模型中conv3-4,conv4-4以及conv5-4层)的输出,记为xl,其中m,n和d分别为特征图的长宽以及通道数。3)使用步骤2)中得到的cnn特征来训练相关滤波模型。公式(1)如下:其中,λ为正则化参数,y(m,n)是一个连续性的高斯标签,其中σ表示线性核的带宽。公式(1)是一个典型的岭回归,存在闭式解,求解可得:其中,为训练得到的相关滤波模型,为的共轭,和y分别为以及高斯标签y的离散傅里叶变换,为点乘运算。4)给定一帧测试视频,利用训练好的相关滤波模型对搜索区域进行响应,得到响应图,响应图中值最大的位置确定为目标初始位置。具体过程如下:提取测试视频中搜索区域在vgg-net-19模型中l层的cnn特征,记为zl,zl和xl大小相同。相关滤波模型在zl上的响应图可通过以下公式(3)计算:其中,fl表示相关滤波模型在l层特征的响应图,f-1表示逆傅里叶变换,为的离散傅里叶变换。为了提升跟踪的鲁棒性,不同层的特征来进行目标定位。给定共l层的特征图通过公式(3),可以得到相关滤波模型在不同层特征上的响应图,记为则相关滤波模型估计的初始目标位置可计算为:其中,为相关滤波模型估计的目标位置,γl为在l层特征上的响应图的权重。5)在测试视频中,以上一帧目标为中心,构建搜索尺度金字塔。具体过程如下:以上一帧目标为中心,在上一帧目标尺度的基础上,构建q个尺度因子,并与原有目标尺度相乘,得到q个不同尺度的搜索区域,并使用双线性差值将其大小变为等大小(255×255×3),记为:6)使用预训练好的深度孪生网络,以第一帧视频中的目标为模板,在步骤5)中得到的每个尺度上进行模板的匹配,得到每个尺度下置信度最高的候选目标位置,并以置信度进行排序,得到置信度最高的k个候选目标位置。计算过程如下:其中,o为目标模板,s(,)为深度孪生网络离线学习得到的相似性度量函数,度量结果返回为相似性图。记为目标模板在q搜索尺度下的最佳相似性值,对进行排序,可以得到前k个候选目标位置,记为集合令集合u用以表示所有候选目标位置,则7)使用基于深度相似性的d-expert对f中得到的候选目标位置进行评估,得到最佳候选目标位置。具体过程如下:构建在线目标表观模型,该模型主要包含三类样本:(1)第一帧中的目标样本;(2)跟踪过程中收集的置信度较高的目标样本;(3)最新的跟踪结果。使用vgg-net-19模型提取这三类样本的全连接层特征,分别记为以及使用集合v来表示这三类样本,则同样的,对u中的候选目标提取全连接特征,记为对于ek∈e,d-expert计算其在v上的累积相似度距离:通过比较累计相似度距离,深度孪生网络搜索得到的最佳候选目标可通过以下公式(7)计算:f-expert进一步对相关滤波估计的目标位置以及孪生网络在不同尺度范围内搜索得到的最佳候选目标进行评估:其中,rd为d-expert的评估值,sign(·)为符号函数。若rd等于1,则孪生网络搜索得到的最佳候选目标在表观模型上的累计距离小于相关滤波估计的候选目标,前者更为可靠,此时再进行后续评估;否则,相关滤波估计的候选目标作为最终跟踪结果。8)使用基于相关滤波的c-expert对步骤3)中得到的目标位置以及步骤7)中得到的最佳候选目标位置进行评估,得到最佳目标跟踪结果,完成跟踪。c-expert使用两个相关滤波模型来进行评估,记为和前者仅在第一帧视频进行训练,保留了原有的目标模型,后者在整个跟踪过程中都有训练更新,考虑了目标的形变。令rt(m,n)和r1(m,n)分别表示相关滤波模型及在位置(m,n)处的响应值。c-expert对相关滤波模型估计的目标位置以及深度孪生网络搜索得到的最佳目标位置进行评估:其中,rc为c-expert的评估值。若rc为1,则选择为最终跟踪结果;否则,作为最终跟踪结果。若表明深度孪生网络搜索得到的最佳位置考虑了更多物体的形变,更为可靠,此时取此为最佳跟踪结果;若则表明相关滤波模型很可能已经被错误的更新,深度孪生网络得到的结果在中有更高的响应值,置信度更高,因此选择此结果作为最终跟踪结果。本发明整体框架图如图1所示。图2为本发明实施例在目标遮挡视频中的定性跟踪结果。其中矩形框为本发明的方法;从图中可以看到,本发明的方法能有效处理长视频中的目标遮挡、消失视野等挑战。表1为本发明与其它11种目标跟踪方法在otb-2013数据集上精度,成功率以及速度的对比。本发明方法在主流的数据集上取得了较为不错的跟踪结果。表1方法精度(%)成功率(%)速度(fps)本发明91.565.68.9cf2(2015)89.160.510.5hdt(2016)88.960.311.1siamfc(2016)80.160.668.1staple(2016)79.360.062.4srdcf(2015)83.862.63.8kcf(2015)74.151.3205.3dsst(2014)74.055.423.6csk(2012)54.539.8458.0ivt(2008)49.935.840.1lct(2015)84.862.821.0ct(2012)40.630.653.9在表1中:kcf对应为j.f.henriques等人提出的方法(j.f.henriques,r.caseiro,p.martins,andj.batista,“high-speedtrackingwithkernelizedcorrelationfilters,”ieeetrans.patternanal.mach.intell.,vol.37,no.3,pp.583-596,2015.)dsst对应为d.martin等人提出的方法(d.martin,g.hager,f.s.khan,andm.felsberg,“discriminativescalespacetracking,”ieeetrans.patternanal.mach.intell.,vol.39,no.8,pp.1561-1575,2016.)staple对应为l.bertinetto等人提出的方法(l.bertinetto,j.valmadre,s.golodetz,o.miksik,andp.h.s.torr,“staple:complementarylearnersforreal-timetracking,”inproc.ieeeconf.comput.vis.patternrecognit.,2016,pp.1401-1409.)srdcf对应为m.danelljan等人提出的方法(m.danelljan,g.f.s.khan,andm.felsberg,“learningspatiallyregularizedcorrelationfiltersforvisualtracking,”inproc.ieeeint.conf.comput.vis.,2015,pp.4310-4318.)siamfc对应为l.bertinetto等人提出的方法(l.bertinetto,j.valmadre,j.henriques,a.vedaldi,andp.torr,“fully-convolutionalsiamesenetworksforobjecttracking,”inproc.workshoponeur.conf.comput.vis.,2016,pp.850-865.)cf2对应为c.ma等人提出的方法(c.ma,j.-b.huang,x.k.yang,andm.-h.yang,“hierarchicalconvolutionalfeaturesforvisualtracking,”inproc.ieeeint.conf.comput.vis.,2015,pp.3074-3082.)hdt对应为y.k.qi等人提出的方法(y.k.qi,s.p.zhang,l.qin,h.x.yao,q.m.huang,j.lim,andm.-h.yang,“hedgeddeeptracking,”inproc.ieeeconf.comput.vis.patternrecognit.,2016,pp.4303-4311.)lct对应为c.ma等人提出的方法(c.ma,x.k.yang,c.y.zhang,andm.-h.yang,“long-termcorre-lationtracking,”inproc.ieeeconf.comput.vis.patternrecognit.,2015,pp.5388-5396.)csk对应为j.f.henriques等人提出的方法(j.f.henriques,r.caseiro,p.martins,andj.batista,“exploitingthecirculantstructureoftracking-by-detectionwithkernels,”inproc.eur.conf.comput.vis.,2012,pp.702-715.)ct对应为k.h.zhang等人提出的方法(k.h.zhang,l.zhang,andm.-h.yang,“real-timecompressivetracking,”inproc.eur.conf.comput.vis.,2012,pp.864-877.)ivt对应为d.a.ross等人提出的方法(d.a.ross,j.lim,r.-s.lin,andm.-h.yang,“incrementallearningforrobustvisualtracking,”int.j.comput.vis.,vol.77,no.1,pp.125-141,2008.)当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1