基于神经网络文本检测识别的医疗票据类文字提取方法与流程
本发明涉及文字提取技术领域,尤其涉及一种基于神经网络文本检测识别的医疗票据类文字提取方法。
背景技术
保险公司处理医疗类保险案件时,需要用户提供相关的报销票据,这些票据有的是拍摄的图片,有的是票据复印件。对于这图片或者复印件,这部分工作需要大量的人力;随着信息化的发展,保险公司开始使用目前比较成熟的基于神经网络的ocr识别,但是由于票据本身的复杂环境:票据文本间有很多的遮挡、印刷的文字与后打印上去的文字有水平和竖直上的偏移等,即使是目前效果较好的文字识别,在医疗票据上的表现也有很多不足的地方。
卷积神经网络(convolutionalneuralnetwork,cnn)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现;其包括卷积层(convolutionallayer)和池化层(poolinglayer)。
文字识别方法:只有将文档图片识别成文字后,才能进行信息提取;因而,文字识别在其中也至关重要。文字识别的方法也分传统方法和深度学习方法。深度学习的方法是,深度卷积神经网络进行文字检测,深度循环网络进行文字串识别。识别结果准确高,处理简单,泛化能力强。深度学习文字方法包含以下模型:
文字检测的模型:fasterrcnn,east,rrcnn,textboxes
文字识别的模型:rcnn
现有文字提取方法存在的缺点为:
1、采用人工录入的办法,则成本极高,录入耗时过长;
2、若是直接使用神经网络识别出来的文本信息,需要根据不同的票据专门写对应的票据信息提取,样式过多,难以实现;
3、若是票据信息不做矫正处理,由于票据本身文本环境的恶劣导致部分数据的错误率极高。
技术实现要素:
针对上述问题中存在的不足之处,本发明提供一种基于神经网络文本检测识别的医疗票据类文字提取方法。
为实现上述目的,本发明提供一种基于神经网络文本检测识别的医疗票据类文字提取方法,包括:
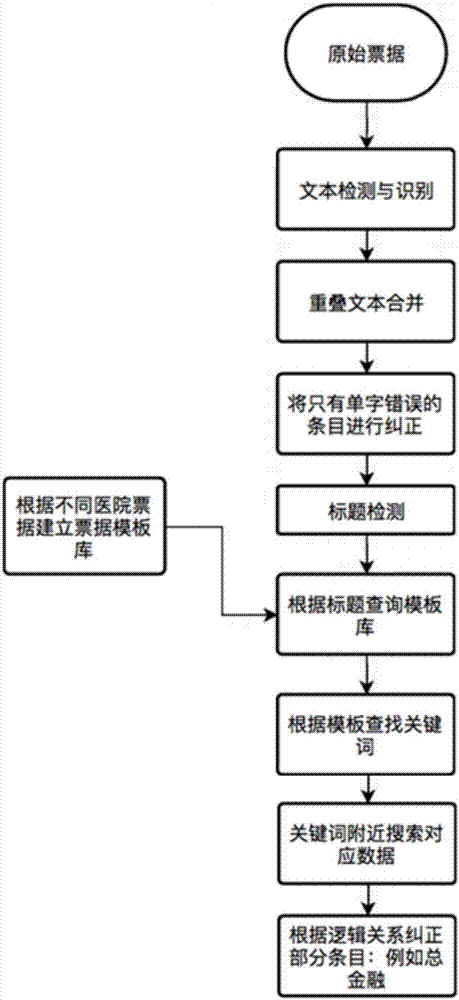
步骤1、获取原始票据;
步骤2、对票据进行文本检测和文本识别;
步骤3、对文本中出现的重叠的文本框进行文本融合;
步骤4、对只有单字错识或漏识的条目进行纠正;
步骤5、对票据进行标题检测和识别;
步骤6、根据标题在票据模板库中查询该标题所对应的票据模板;
步骤7、根据模板查找关键词;
步骤8、在关键词附近搜索对应数据;
步骤9、根据逻辑关系纠正部分条目。
作为本发明的进一步改进,所述步骤3包括:
检查重叠的两个文本框中靠左文本框的后半部分与靠右文本框的前半部分是否有重复内容,若有则合并为一。
作为本发明的进一步改进,在步骤4中:
将错识或漏识频率高的字添加到字典,用于条目纠正过程中的文字替换。
作为本发明的进一步改进,在步骤8中:
金额部分如果有相应的大写文本,则优先使用大写文本识别。
作为本发明的进一步改进,在步骤9中:
相互辅助的关键词所对应的数据,可互相校验;若出现不符合,则根据文本识别的置信度进行排错。
与现有技术相比,本发明的有益效果为:
本发明结合了基于神经网络的ocr方法识别的文本,对文本进行了数据提取,以修正部分ocr导致的错识或者漏识;同时针对不同样式不同模板的票据,提供通用或者独特的票据模板解析方法,该方法在文本检测和文本识别中能获取较高的准确率。
附图说明
图1为本发明一种实施例公开的基于神经网络文本检测识别的医疗票据类文字提取方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图对本发明做进一步的详细描述:
本发明对医疗票据文档图片的ocr识别后的数据做数据提取,以返回票据内部的关键内容。保险公司常见的医疗票据主要分为4个大类:门诊票据、住院票据、结算单、明细单。每个大类下有各个省份各个医院不同样式的小类,小类数量超过上百种,而且不同小类别的票据可能样式差别极大,再加上票据本身的背景较为复杂,导致此任务非常困难。为此,本发明结合了基于神经网络的ocr方法识别的文本,对文本进行了数据提取,以修正部分ocr导致的错识或者漏识;同时针对不同样式不同模板的票据,提供通用或者独特的票据模板解析方法。
如图1所示,本发明提供一种基于神经网络文本检测识别的医疗票据类文字提取方法,包括:
步骤1、获取原始票据,原始票据可为票据原件、票据复印件或图片等。
步骤2、对票据进行文本检测和文本识别;具体的:
使用文本检测方法检测出图片中文本的所在位置,将文本做识别;文字检测的模型:fasterrcnn,east,rrcnn,textboxes;文字识别的模型:rcnn。
步骤3、对文本中出现的重叠的文本框进行文本融合;具体的:
检查重叠的两个文本框中靠左文本框的后半部分与靠右文本框的前半部分是否有重复内容,若有则合并为一。
步骤4、对只有单字错识或漏识的条目进行纠正;具体的:
例如:“个人自费金额”识别为“人自费金额”、或者“个人自费金客”,将出错频率较高的添加到字典,对这部分识别问题直接做文字替换。
步骤5、对票据进行标题检测和识别,查询票据中居中靠上,且高度较大的文本。
步骤6、根据标题在票据模板库中查询该标题所对应的票据模板;具体的:
预先根据不同样式不同模板的票据,填写对应的模板文件。此类模板文件可以由数据公司提供,解析后极可能对不同标题的票据做对应内容填写。模板类文件的构成有:
a)、标题;
b)、用于确定文本各个关键词的锚点:主要是票据类常出现的且固定位置的“项目”、“金额”、“总额”等文本。
c)、每个票据关键条目的真实文本:比如不同的票据的自付项目可能会有:“自付”、“自费”等多个可能。
d)、票据的整体排布:文本的水平或者是竖直等(对于特殊排布的可以做新的自定义)。
步骤7、根据模板查找关键词。
步骤8、在关键词附近搜索对应数据;其中:
金额部分如果有相应的大写文本,则优先使用大写文本识别,因为数字部分容易被遮挡且位置偏移过大时容易误识,可达到细节提升。
步骤9、根据逻辑关系纠正部分条目;其中:
对于部分识别错误:对于出院日期、入院日期和住院天数等可以相互辅助的信息,则可以互相校验,如果出现不符合则根据文本识别的置信度来做排错,可达到细节提升。
进一步,解析用的模板文件,可以替换为脚本生成对应的模板解析代码来解析不同类型票据。
本发明的优点为:
本发明结合了基于神经网络的ocr方法识别的文本,对文本进行了数据提取,以修正部分ocr导致的错识或者漏识;同时针对不同样式不同模板的票据,提供通用或者独特的票据模板解析方法,该方法在文本检测和文本识别中能获取较高的准确率。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!