一种分合闸线圈故障电流波形识别方法和系统与流程
本发明涉及电力系统领域,尤其涉及一种断路器分合闸线圈故障电流波形识别方法和系统。
背景技术
高压断路器是电力系统的重要设备,在电力系统中起到两方面的作用:第一,电网的调度控制作用,即根据电网的运行状态投切线路;第二,电网的保护作用,即当电力系统出现故障时,迅速动作,切除故障线路。因此,高压断路器的可靠性对于电力系统的安全稳定运行有重要的意义。高压断路器拒动是电力系统最严重的故障类型之一,其中以断路器拒分故障的危害尤为严重,会造成严重的电网事故,带来巨大的经济损失。
分合闸线圈电流不仅能够反映分合闸线圈自身的缺陷,而且对于断路器机构故障,例如铁芯卡涩、分合闸掣子润滑不足等,有很好指示作用。通过对分合闸线圈电流的分析,找出在故障条件下分合闸线圈电流波形的变化规律,设计故障识别算法,识别故障电流波形,对于及时的发现断路器机构故障,预防断路器拒动有重要的意义。在现有技术中,对分合闸线圈故障电流波形识别的方法主要是通过传感器测量分合闸操作时分合闸线圈的电流信号,然后提取电流波形特征量进行人为的故障诊断,但是人为诊断的方法不够准确,导致故障识别的错误率较高。
技术实现要素:
本发明实施例的目的是提供一种分合闸线圈故障电流波形识别方法和系统,能够提高分合闸线圈的故障故障诊断的准确率。
为实现上述目的,本发明实施例提供了一种分合闸线圈故障电流波形识别方法,包括:
采集分合闸线圈的电流波形;
对所述电流波形进行数据处理,提取所述电流波形的特征参数;
根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果;
其中,所述随机森林分类器的建立方法包括:
采集若干个分合闸线圈的电流波形;
获取第一预设数量的所述电流波形作为训练集;
从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据,根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成。
与现有技术相比,本发明公开的分合闸线圈故障电流波形识别方法通过采集分合闸线圈的电流波形;对所述电流波形进行数据处理,提取所述电流波形的特征参数;根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果。解决了现有技术对分合闸线圈故障电流波形识别的方法主要是通过传感器测量分合闸操作时分合闸线圈的电流信号,然后提取电流波形特征量进行人为的故障诊断,但是人为诊断的方法不够准确,导致故障识别的错误率较高的问题,能够提高分合闸线圈的故障故障诊断的准确率。
作为上述方案的改进,所述随机森林分类器的建立方法还包括:
获取第二预设数量的所述电流波形作为测试集;
通过所述测试集对所述随机森林分类器进行交叉验证;
当所述随机森林分类器不满足预设准确率时,对所述随机森林分类器进行参数调整,直至所述随机森林分类器满足预设准确率。
作为上述方案的改进,所述根据所述样本数据的构造决策树具体包括:
构造所述样本数据的信息熵;
根据所述电流波形的特征参数对所述样本数据进行样本分类,将所述样本数据分为若干个子样本,得到分类后的样本数据的信息熵;
根据所述样本数据的信息熵和所述分类后的样本数据的信息熵计算所述样本数据的信息增益。
作为上述方案的改进,所述样本数据的信息熵为:
其中,h(x)为所述样本数据的信息熵,x为所述样本数据,c为所述样本数据中的数据个数,pi为第i个样本在x中所占比例,i=1,2…c。
作为上述方案的改进,所述分类后的样本数据的信息熵为:
其中,ha(x)为所述分类后的样本数据的信息熵,a为所述电流波形的特征参数,x为所述样本数据,n为所述样本数据中的子样本数目,pj为第j个子样本占所述样本数据总数的比例,xj为第j个子样本,j=1,2…n。
作为上述方案的改进,所述样本数据的信息增益为:
g(x,a)=h(x)-ha(x)公式(3);其中,g(x,a)为所述样本数据的信息增益,h(x)为所述样本数据的信息熵,ha(x)为所述分类后的样本数据的信息熵。
为实现上述目的,本发明实施例还提供了一种分合闸线圈故障电流波形识别系统,包括:
数据采集单元,用于采集分合闸线圈的电流波形;
数据处理单元,用于对所述电流波形进行数据处理,提取所述电流波形的特征参数;
分类单元,用于根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果;
随机森林分类器建立单元,用于建立所述随机森林分类器;
其中,所述随机森林分类器建立单元包括:
电流波形获取模块,用于采集若干个分合闸线圈的电流波形;
训练集获取模块,用于获取第一预设数量的所述电流波形作为训练集,并从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据;
决策树构造模块,用于根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成。
与现有技术相比,本发明公开的分合闸线圈故障电流波形识别系统,首先通过数据采集单元采集分合闸线圈的电流波形;然后数据处理单元对所述电流波形进行数据处理,提取所述电流波形的特征参数;最后分类单元根据随机森林分类器建立单元预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果。解决了现有技术对分合闸线圈故障电流波形识别的方法主要是通过传感器测量分合闸操作时分合闸线圈的电流信号,然后提取电流波形特征量进行人为的故障诊断,但是人为诊断的方法不够准确,导致故障识别的错误率较高的问题,能够提高分合闸线圈的故障故障诊断的准确率。
作为上述方案的改进,所述随机森林分类器建立单元还包括:
测试集获取模块,用于获取第二预设数量的所述电流波形作为测试集;
交叉验证模块,用于通过所述测试集对所述随机森林分类器进行交叉验证;
参数调整模块,用于当所述随机森林分类器不满足预设准确率时,对所述随机森林分类器进行参数调整,直至所述随机森林分类器满足预设准确率。
作为上述方案的改进,所述决策树构造模块包括:
样本数据的信息熵获取模块,用于构造所述样本数据的信息熵;
分类后的样本数据的信息熵获取模块,用于根据所述电流波形的特征参数对所述样本数据进行样本分类,将所述样本数据分为若干个子样本,得到分类后的样本数据的信息熵;
样本数据的信息增益获取模块,用于根据所述样本数据的信息熵和所述分类后的样本数据的信息熵计算所述样本数据的信息增益。
作为上述方案的改进,所述样本数据的信息熵为:
其中,h(x)为所述样本数据的信息熵,x为所述样本数据,c为所述样本数据中的数据个数,pi为第i个样本在x中所占比例,i=1,2…c;
所述分类后的样本数据的信息熵为:
其中,ha(x)为所述分类后的样本数据的信息熵,a为所述电流波形的特征参数,x为所述样本数据,n为所述样本数据中的子样本数目,pj为第j个子样本占所述样本数据总数的比例,xj为第j个子样本,j=1,2…n;
所述样本数据的信息增益为:
g(x,a)=h(x)-ha(x)公式(3);其中,g(x,a)为所述样本数据的信息增益,h(x)为所述样本数据的信息熵,ha(x)为所述分类后的样本数据的信息熵。
附图说明
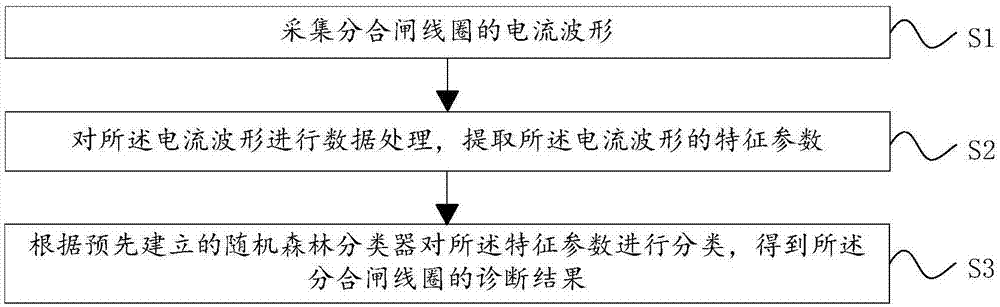
图1是本发明实施例提供的一种分合闸线圈故障电流波形识别方法的流程图
图2是本发明实施例提供的一种分合闸线圈故障电流波形识别方法中建立随机森林分类器的流程图;
图3是本发明实施例提供的一种分合闸线圈故障电流波形识别方法中构造决策树的流程图;
图4是本发明实施例提供的一种分合闸线圈故障电流波形识别方法中交叉验证误差率的曲线图;
图5是本发明实施例提供的一种分合闸线圈故障电流波形识别系统的结构框图;
图6是本发明实施例提供的一种分合闸线圈故障电流波形识别系统中随机森林分类器建立单元4的结构框图;
图7是本发明实施例提供的一种分合闸线圈故障电流波形识别系统中决策树构造模块43的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
参见图1,图1是本发明实施例提供的一种分合闸线圈故障电流波形识别方法的流程图;包括:
s1、采集分合闸线圈的电流波形;优选的,可以通过使用单匝穿心式霍尔电流传感器来采集所述分合闸线圈的电流波形。
s2、对所述电流波形进行数据处理,提取所述电流波形的特征参数;
s3、根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果。具体的,根据所述随机森林分类器对所述分合闸线圈的电流波形进行分类,能够判断所述电流波形是电压异常电流波形、铁芯间隙异常电流波形或铁芯卡涩故障电流波形,从而能够得到所述分合闸线圈是处于何种故障。
优选的,在本发明实施例中,所述电流波形包括第一次峰值i1、第一次达到峰值的时间t1、第一次谷值i2、第一次达到谷值的时间t2、最大值i3和达到最大值的时间t3、第一次达到谷值的时间与第一次达到峰值的时间的差值δt、第一次峰值和第一次谷值的电流差值δi。所述特征参数包括t1、t2、δt=t2-t1、i1、i2、δi=i1-i2。
优选的,参见图2,图2是本发明实施例提供的一种分合闸线圈故障电流波形识别方法中建立随机森林分类器的流程图。具体的,所述随机森林分类器为预先建立的,具体包括:
s31、采集若干个分合闸线圈的电流波形;
s32、获取第一预设数量的所述电流波形作为训练集;
s33、从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据,根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成;
s34、获取第二预设数量的所述电流波形作为测试集;
s35、通过所述测试集对所述随机森林分类器进行交叉验证;
s36、当所述随机森林分类器不满足预设准确率时,对所述随机森林分类器进行参数调整,直至所述随机森林分类器满足预设准确率。
具体的,在步骤s31~s32中,本发明实施例的所述训练集共使用电流波形300条,其中正常电流波形100条,故障电流波形200条。故障电流波形包含电压异常电流波形70条、铁芯间隙异常电流波形60条,铁芯卡涩故障电流波形70条。
优选的,本发明实施例的随机森林算法分类任务使用matlab的statisticsandmachinelearningtoolbox软件包进行分析。软件包中包含大量机器学习算法,是数据挖掘方便的工具。matlab软件包中treebagger即是随机森林算法,建立模型时,需要对samplewithreplacement(控制是否有放回抽样)、inbagfraction(建立每棵决策树抽取的数据占数据总量的比例)和numpredictorstosample(每个节点分裂时抽取的特征的个数)三个参数进行设置。其中,设置samplewithreplacement为选择有放回抽样;设置inbagfraction为0.6(即所述预设比例);设置numpredictorstosample默认为总的特征个数的平方根。
具体的,在步骤s33中,从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据,根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成。随机森林算法是bagging算法和随机子空间算法的组合,基本构成单元是决策树,多棵决策树投票共同进行决策,从而使分类的准确率有很大提高。
具体的,在步骤s34中,获取第二预设数量的所述电流波形作为测试集;比如一共有电流波形1000条,采用60%的训练集进行训练,则剩余的40%的训练集测试所述随机森林分类器的准确率,则此时所述第一预设数量为600,所述第二预设数量为400。
具体的,在步骤s35~s36中,通过所述测试集对所述随机森林分类器进行交叉验证,如果交叉验证精度没有达到预设准确率,是需要重新调整参数的。在本发明中,所述参数包括决策树的棵树、每次抽取样本数占总样本的比例和每次抽取特征数占总特征的比例。经过反复测试,本发明选择建立100棵决策树,每次抽取样本数占总样本的比例为0.6,每次抽取特征数为总特征数的平方根。
优选的,参见图3,图3是本发明实施例提供的一种分合闸线圈故障电流波形识别方法中构造决策树的流程图;包括:
s331、构造所述样本数据的信息熵;
s332、根据所述电流波形的特征参数对所述样本数据进行样本分类,将所述样本数据分为若干个子样本,得到分类后的样本数据的信息熵;
s333、根据所述样本数据的信息熵和所述分类后的样本数据的信息熵计算所述样本数据的信息增益。
值得说明的是,决策树是一种描述对数据集进行分类的树形结构。决策树由节点和有向边组成。节点分为内部节点和叶节点,其中内部节点表示数据集的一个特征或属性,叶节点表示一个类。一个数据集的纯度可以用其熵值来表示,据信息论中的熵值定义,信息熵越大表示数据的纯度越低。
具体的,在步骤s331中,所述样本数据x的信息熵为:
其中,h(x)为所述样本数据的信息熵,x为所述样本数据,c为所述样本数据中的数据个数,pi为第i个样本在x中所占比例,i=1,2…c。
其中,h(x)越大,表示数据集越混乱;h(x)越小,则数据集越纯净。
具体的,在步骤s332中,经过所述电流波形的特征参数a作用以后,所述样本数据x被分为n个子样本xj(所述样本数据x是指很多条电流波形组成的集合,经过某个电流波形特征参数a作用以后,这个集合被分为若干个子集),所述分类后的样本数据的信息熵为:
其中,ha(x)为所述分类后的样本数据的信息熵,a为所述电流波形的特征参数,x为所述样本数据,n为所述样本数据中的子样本数目,pj为第j个子样本占所述样本数据总数的比例,xj为第j个子样本,j=1,2…n。
具体的,在步骤s333中,所述样本数据的信息增益为:
g(x,a)=h(x)-ha(x)公式(3);其中,g(x,a)为所述样本数据的信息增益,h(x)为所述样本数据的信息熵,ha(x)为所述分类后的样本数据的信息熵。
其中,信息增益越大,说明用特征参数a进行分类的效果越好。
优选的,统计分类结果,绘制分类误差率随决策树的,其交叉验证曲线图如图4所示。随着决策树数量的增加,分类误差率快速下降,最终稳定在1%。至此,所述决策树构造完毕,从而能够建立所述随机森林分类器。
与现有技术相比,本发明公开的分合闸线圈故障电流波形识别方法通过采集分合闸线圈的电流波形;对所述电流波形进行数据处理,提取所述电流波形的特征参数;根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果。解决了现有技术对分合闸线圈故障电流波形识别的方法主要是通过传感器测量分合闸操作时分合闸线圈的电流信号,然后提取电流波形特征量进行人为的故障诊断,但是人为诊断的方法不够准确,导致故障识别的错误率较高的问题,能够提高分合闸线圈的故障故障诊断的准确率。
实施例二
参见图5,图5是本发明实施例提供的一种分合闸线圈故障电流波形识别系统的结构框图;包括:
数据采集单元1,用于采集分合闸线圈的电流波形;优选的,可以通过使用单匝穿心式霍尔电流传感器来采集所述分合闸线圈的电流波形。
数据处理单元2,用于对所述电流波形进行数据处理,提取所述电流波形的特征参数。
分类单元3,用于根据预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果;具体的,根据所述随机森林分类器对所述分合闸线圈的电流波形进行分类,能够判断所述电流波形是电压异常电流波形、铁芯间隙异常电流波形或铁芯卡涩故障电流波形,从而能够得到所述分合闸线圈是处于何种故障。
随机森林分类器建立单元4,用于建立所述随机森林分类器。
优选的,在本发明实施例中,所述电流波形包括第一次峰值i1、第一次达到峰值的时间t1、第一次谷值i2、第一次达到谷值的时间t2、最大值i3和达到最大值的时间t3、第一次达到谷值的时间与第一次达到峰值的时间的差值δt、第一次峰值和第一次谷值的电流差值δi。所述特征参数包括t1、t2、δt=t2-t1、i1、i2、δi=i1-i2。
优选的,参见图6,图6是本发明实施例提供的一种分合闸线圈故障电流波形识别系统中随机森林分类器建立单元4的结构框图;具体包括:
电流波形获取模块41,用于采集若干个分合闸线圈的电流波形;
训练集获取模块42,用于获取第一预设数量的所述电流波形作为训练集,并从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据;
决策树构造模块43,用于根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成;
测试集获取模块44,用于获取第二预设数量的所述电流波形作为测试集;
交叉验证模块45,用于通过所述测试集对所述随机森林分类器进行交叉验证;
参数调整模块46,用于当所述随机森林分类器不满足预设准确率时,对所述随机森林分类器进行参数调整,直至所述随机森林分类器满足预设准确率。
具体的,所述训练集获取模块42获取的所述训练集共使用电流波形300条,其中正常电流波形100条,故障电流波形200条。故障电流波形包含电压异常电流波形70条、铁芯间隙异常电流波形60条,铁芯卡涩故障电流波形70条。
优选的,本发明实施例的随机森林算法分类任务使用matlab的statisticsandmachinelearningtoolbox软件包进行分析。软件包中包含大量机器学习算法,是数据挖掘方便的工具。matlab软件包中treebagger即是随机森林算法,建立模型时,需要对samplewithreplacement(控制是否有放回抽样)、inbagfraction(建立每棵决策树抽取的数据占数据总量的比例)和numpredictorstosample(每个节点分裂时抽取的特征的个数)三个参数进行设置。其中,设置samplewithreplacement为选择有放回抽样;设置inbagfraction为0.6(即所述预设比例);设置numpredictorstosample默认为总的特征个数的平方根。
具体的,从所述训练集中有放回的随机抽取预设比例的所述电流波形作为样本数据,所述决策树构造模块43根据所述样本数据的构造决策树,得到所述随机森林分类器;其中,所述随机森林分类器由若干个所述决策树组成。随机森林算法是bagging算法和随机子空间算法的组合,基本构成单元是决策树,多棵决策树投票共同进行决策,从而使分类的准确率有很大提高。
具体的,所述测试集获取模块44获取第二预设数量的所述电流波形作为测试集;比如一共有电流波形1000条,采用60%的训练集进行训练,则剩余的40%的训练集测试所述随机森林分类器的准确率,则此时所述第一预设数量为600,所述第二预设数量为400。
具体的,所述交叉验证模块45通过所述测试集对所述随机森林分类器进行交叉验证,如果交叉验证精度没有达到预设准确率,则通过所述参数调整模块46重新调整参数。在本发明中,所述参数包括决策树的棵树、每次抽取样本数占总样本的比例和每次抽取特征数占总特征的比例。经过反复测试,本发明选择建立100棵决策树,每次抽取样本数占总样本的比例为0.6,每次抽取特征数为总特征数的平方根。
优选的,参见图7,图7是本发明实施例提供的一种分合闸线圈故障电流波形识别系统中决策树构造模块43的结构框图,具体包括:
样本数据的信息熵获取模块431,用于构造所述样本数据的信息熵;
分类后的样本数据的信息熵获取模块432,用于根据所述电流波形的特征参数对所述样本数据进行样本分类,将所述样本数据分为若干个子样本,得到分类后的样本数据的信息熵;
样本数据的信息增益获取模块433,用于根据所述样本数据的信息熵和所述分类后的样本数据的信息熵计算所述样本数据的信息增益。
值得说明的是,决策树是一种描述对数据集进行分类的树形结构。决策树由节点和有向边组成。节点分为内部节点和叶节点,其中内部节点表示数据集的一个特征或属性,叶节点表示一个类。一个数据集的纯度可以用其熵值来表示,据信息论中的熵值定义,信息熵越大表示数据的纯度越低。
具体的,所述样本数据的信息熵获取模块431中获取到的所述样本数据x的信息熵为:
其中,h(x)为所述样本数据的信息熵,x为所述样本数据,c为所述样本数据中的数据个数,pi为第i个样本在x中所占比例,i=1,2…c。
其中,h(x)越大,表示数据集越混乱;h(x)越小,则数据集越纯净。
具体的,经过所述电流波形的特征参数a作用以后,所述样本数据x被分为n个子样本xj(所述样本数据x是指很多条电流波形组成的集合,经过某个电流波形特征参数a作用以后,这个集合被分为若干个子集),所述分类后的样本数据的信息熵获取模块432获取到的所述分类后的样本数据的信息熵为:
其中,ha(x)为所述分类后的样本数据的信息熵,a为所述电流波形的特征参数,x为所述样本数据,n为所述样本数据中的子样本数目,pj为第j个子样本占所述样本数据总数的比例,xj为第j个子样本,j=1,2…n。
具体的,所述样本数据的信息增益获取模块433获取到的所述样本数据的信息增益为:
g(x,a)=h(x)-ha(x)公式(3);其中,g(x,a)为所述样本数据的信息增益,h(x)为所述样本数据的信息熵,ha(x)为所述分类后的样本数据的信息熵。
其中,信息增益越大,说明用特征参数a进行分类的效果越好。
优选的,统计分类结果,绘制分类误差率随决策树的,其交叉验证曲线图如图4所示。随着决策树数量的增加,分类误差率快速下降,最终稳定在1%。至此,所述决策树构造完毕,从而能够建立所述随机森林分类器。
与现有技术相比,本发明公开的分合闸线圈故障电流波形识别系统,首先通过数据采集单元1采集分合闸线圈的电流波形;然后数据处理单元2对所述电流波形进行数据处理,提取所述电流波形的特征参数;最后分类单元3根据随机森林分类器建立单元4预先建立的随机森林分类器对所述特征参数进行分类,得到所述分合闸线圈的诊断结果。解决了现有技术对分合闸线圈故障电流波形识别的方法主要是通过传感器测量分合闸操作时分合闸线圈的电流信号,然后提取电流波形特征量进行人为的故障诊断,但是人为诊断的方法不够准确,导致故障识别的错误率较高的问题,能够提高分合闸线圈的故障故障诊断的准确率。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!