一种用于期刊PDF文件中文章内容的解析方法与流程
本发明属于内容解析方法,具体涉及一种用于期刊pdf文件中文章内容的解析方法。
背景技术
在文件处理技术领域,已存在针对pdf文件内容的读取技术,比如现有工具中pdfbox、itext、itextsharp都可以读取pdf文档中文本内容,也有不少关于pdf内容识别的专利文献,主要包括字符识别和提取类(cn200710177673.4、cn200910076809.1、cn201210455707.2、cn201710760650.x、cn201710067220.x、cn201310088513.8),图表识别和提取类(cn201710095978.4、cn201610887631.9、cn201610025529.8、cn201210142082.4、cn201010293736.4、cn201710209497.1),文档格式转换类(cn201010136399.8、cn201110213555.0、cn201010206401.4、cn201510386691.8、cn201110377021.1),其他类(cn201210163436.3、cn201710576555.4)。这些对pdf文档进行识别和处理的技术大大方便了科技人员对文档的阅读和处理。
但是现有技术仍存在不可克服的缺陷,主要集中在不能直接对期刊pdf文件中文章内容的特定信息片段抽取。具体的说,当pdf文档中存在大体版面格式,且文档中存在分栏和片段转接和情况时,现有技术的处理都会出现这样或者那样的错误。如果pdf文档中存在图表公式或特别字符,或者由于pdf压缩时产生的文字行高不一致的情况,现有技术更加无法对文章进行处理,造成文本片段内容的读取难度,容易引起读取的文章内容顺序错位的情况较多。
技术实现要素:
本申请针对现有技术的缺陷,提供一种用于期刊pdf文件中文章内容的解析方法。
本申请是这样实现的:一种用于期刊pdf文件中文章内容的解析方法,包括下述步骤:
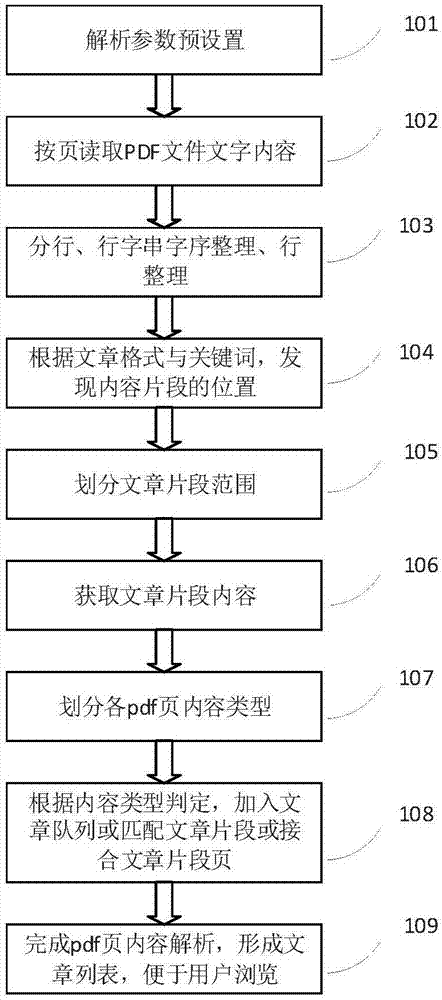
步骤一:解析参数预设值
针对学术期刊类文献解析和普通杂志类文章解析两类期刊,分别进行解析参数预设值;
步骤二:读取pdf文字内容
按页读取出pdf文件中的文字块,并且携带的起止位置坐标信息,将文字块存于字块列表中,在保存的时候,记录字符的起止点x坐标值,在后续处理中,根据起止点x坐标值,计算出字大小的特征;
步骤三:整理并接合
对步骤二读取的文字块逐级整理、接合,直到形成文章;
步骤九:形成文章列表
将前面步骤形成的文章插入文章列表,直到所有文字块都处理完毕。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的步骤三包括整理、定位片段位置、划分片段范围、获取文章片段内容、划分pdf页内容类型、接合五个步骤,
其中,整理步骤包括构建字串,字串包括以常用词为单位的词,以及该词的起止(x,y)坐标值,构建时首先在字块中用文字的y值判断是否同行,同行文字构建在一个字串内,不同行的文字构建为不同字串,然后同行文字中以文字的x值判断文字顺序,按照x值的顺序构建字串,按照上述顺序整理全部字块。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,步骤四定位片段位置,包括
根据格式中规定的关键词来发现内容片段位置,多个字块构成行字串对象即行,多行构成片段,通过关键词检索的方式实现片段定位,本步骤所述的关键词是指文献规定的特定词,本步骤的片段是指文章不同构成的意思,即标题、摘要、关键词、正文、参考文献为不同片段。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的步骤五:划分片段范围,包括根据文章格式关键词行索引值划分主要文章片段,本步骤的片段是指文章不同构成的意思,即标题、摘要、关键词、正文、参考文献为不同片段。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的步骤六:获取文章片段内容,包括根据文章相邻格式关键词区分文章主要片段内容,所述的格式关键词是指按序出现的“摘要:”“关键词:”“中图分类号:”“参考文献”,相邻格式关键词之间的内容为这两个格式关键词中前一个格式关键词的内容,按照上述原则将文章全部内容归类到不同格式关键词下。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的步骤七:划分pdf页内容类型,文章解析类别有:一头一尾,只无尾的,无头无尾的,只无头页存在1个参考文献,只无头页存在两个参考文献,有头有多尾,有头有另一文献尾,无头一个其他尾;判断上述八种情况的标准为:1、pdf文件中的一个pdf页,有一篇文章标题,也有一个参考文献,就判定为一头一尾;2、pdf文件中的一个pdf页,有一篇文章标题,但没有参考文献,就判定为只无尾的;3、pdf文件中的一个pdf页,没有文章标题,也没有参考文献,就判定为无头无尾;4、pdf文件中的一个pdf页,没有文章标题,有一个参考文献,就判定为只无头页存在1个参考文献;5、pdf文件中的一个pdf页,没有文章标题,有两个参考文献,就判定为只无头页存在两个参考文献;6、pdf文件中的一个pdf页,有一篇文章标题,有两个参考文献,就判定为有头有多尾;7、pdf文件中的一个pdf页,有一篇文章标题,有转接页标识,之后有一个参考文献,就判定为有头有另一文献尾;8、pdf文件中的一个pdf页,没有文章标题,有转接页标识,之后有一个参考文献,就判定为无头一个其他尾。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的步骤八:接合,包括文章解析类别与文章结尾拼接处理方法,如果一页中一同存在标题和参考文献,将以就近匹配识其为一篇完整文章,如果存在有转接页的情况,根据转接页接合,加入完整文章队列;所述的完整文章队列是解析后判定为完整文章的队列,文章队列是解析完后的队列,解析完后完整和不完整的队列都会加入到文章队列里;否则如果是文章起始页加入非完整文章队列,不完整队列中的文章会待找到最近的结尾片段或者指定转接页码的结尾片段。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的学术期刊类文献需要设置的解析参数预设值包括:期刊名、是否小标题、起始页码、标题位置、期刊英文名、接转设置、年月日、第几期、摘要分侧、分栏情况、特定字符过滤;所述的分栏情况包括无分栏、左右两栏、左中右三栏三种情况。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的普通杂志类文章需要设置的解析参数预设值包括:杂志名、是否小标题、起始页码、杂志英文名、年月日、第几期、同行误差值、标题最小行、特定字符过滤。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的用文字的y值判断是否同行,是首先设定阈值,然后判定字块起止y坐标值的差是否小于阈值,小于则判定为同行,否则判定为不同行。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述的阈值范围为5-15。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,所述阈值的优选值为10。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,标题的发现,从下述有两种方法中任选其一,第一种是根据摘要的发现来确定存在标题,用关键词“摘要”遍历字块,将“摘要”所在字块之前的字块全部取出,用步骤三的方法判断字串行中的字大小,并排除已知过滤项,所述的已知过滤项是指文献中规律出现的非标题字符,经过上述操作,得到的字串即为标题;第二种是根据对比各个字串行中字大小并排除已知过滤项来发现标题,
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,副标题的发现根据破折号判定如果是副标题则单独存储,否则判断是否是人名、单位。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,进行作者、单位等的判断按照下述方法进行。首先判断字符串之间是否存在两个或两个以上规律的逗号或者空格,如果存在则判定其为作者,如果不存在则判断是否存在特殊字符,如果存在特殊字符则从起始位置重新执行,如果没有特殊字符则通过特殊关键词判断是否是单位,所述的特殊关键词包括“中心”、“教育”、“医院”、“学院”、“学校”、“大学”、“中学”、“小学”、“局”、“公司”、“区”、“省”、“市”,如果包含上述特殊关键词,则判定该字符串为单位,前序字符串为作者。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,摘要片段的识别方法,用特殊摘要字符串进行“摘要”的匹配,所述的特殊摘要字符串包括中文摘要字符串和英文摘要字符串。其中中文摘要字符串是“\s*【?[?\[?摘\s*要\s*\]?]?】?:?:?\s*\w*”,英文摘要字符串是“\s*【?[?\[?(abstract|abstract)\s*\]?]?】?:?:?院?\s*”。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,关键词的识别方法,用特殊关键词字符串进行“关键词”的匹配,特殊关键词字符串包括两个,分别为“\s*【?[?\[?关\s*键\s*词\s*\]?]?】?:?:?\s*\w*”和“\s*【?[?\[?关\s*键\s*字\s*\]?]?】?:?:?\s*\w*”。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,分栏的识别处理方法是根据相邻字块在同行并且两字块之间存在一定的距离,比一般相邻字块距离要大3倍以上,所述的相邻字块的距离是指后一字块起点的x坐标与前一字块终点x坐标的差。
如前所述的一种用于期刊pdf文件中文章内容的解析方法,其中,分隔的识别按照下述方法进行:根据比对字串行的多项行高差值,发现其行高值超出一般行高差值,并且是跨栏的,被判定为存在内容分隔。
本申请的显著效果是:本发明提供了一种用于期刊pdf文件中文章内容的解析方法,抽取文章内容片段:标题、作者、单位信息、摘要、关键词、中图分类号、文献标志码、文章编号、正文、参考文献。解析发现分栏、分隔的内容片段、顺序转接的接合文章内容。对关键词临近的个别标点乱码具有容错处理,对大部分常规格式期刊中文献文章片段具有识别处理。
附图说明
图1是本申请用于期刊pdf文件中文章内容的解析方法的流程示意图;
图2是文献中关键词来源的示意图;
图3是分栏的示意图;
图4是分隔的示意图;
图5是格式多样化的示意图;
图6是片段的示意图。
具体实施方式
一种用于期刊pdf文件中文章内容的解析方法,包括下述步骤:
步骤一:解析参数预设值
期刊pdf文件总体解析类型包括:学术期刊类文献解析和普通杂志类文章解析。普通杂志没有学术期刊的关键词及其内容片段的固定格式。普通杂志类文章处理主体流程与学术期刊的主体流程大体一致,在细节上有所不同,普通文章依另篇文章起头判定结束,没有内容转接。另外,杂志类文章多出了目录部分解析处理。
学术期刊文献的pdf格式文件解析,内容大体格式相同,但格式细节多样,因此一次配置针对性的解析一本期刊。学术期刊类文献解析的设置参数包括:期刊名、是否小标题、起始页码、标题位置、期刊英文名、接转设置、年月日、第几期、摘要分侧(默认不分)、分栏(无分栏、左右两栏、左中右三栏)、特定字符过滤。
普通杂志类文章的pdf格式文件解析,杂志内容大体格式没有固定,但格式细节更加多样,因此一次配置针对性的解析一本杂志。杂志中文章标题部分所在的页面位置没有固定,文章结束文章特定的标识,版面多样。占有篇幅半篇的片段内容,一般会按页面紧接到该篇文章前部分。杂志版面多样,有不分栏、分两栏、分三栏或分四栏的,一本杂志也会有多种分栏存在。普通杂志类文章解析的设置参数包括:杂志名、是否小标题、起始页码、杂志英文名、年月日、第几期、同行误差值、标题最小行、特定字符过滤。
步骤二:读取pdf文字内容
本步骤读取pdf文字内容,读取的技术可以使用现有技术中的任何一种技术,例如cn200910076809.1中公开的技术就是可以使用的。
本发明按页读取出pdf文件中的文字块,每个字块字数不固定,并且携带的起止位置坐标信息,将文字块存于字块列表中。在保存的时候,记录字符的起止点x坐标值,在后续处理中,可以根据起止点x坐标值,计算出字大小的特征。
步骤三:整理
构建字串,其中字串包括以常用词为单位的词,以及该词的起止(x,y)坐标值。例如“校内勤工助学是高校资助育人的重要平台”,获取出来文字会是多个字块如:“校内”、“勤工助学”、“是”、“高校”、“育人”、“资助”、“的重要平台”,其中每个字块会携带有它的这部分文字的起止(x,y)坐标值,y值判定同行,程序中会以此判定行字串对象是否存在,不存在就构造创建行字串对象(即字串构造),在按发现顺序遍历插入这些字块到行字串对象中:“校内”、“勤工助学”、“是”、“高校”、“育人”、“资助”、“的重要平台”,是根据携带的x坐标值(增值方向是由左到右)判定字块顺序的,比如获取顺序“育人”先于“资助”字块,“育人”先填入行字串对象,程序会根据x坐标值将“资助”插入到“育人”的左边。这样就形成行字串对象中有序的一行文字。
根据字块起止y坐标值的差判定是否是同行,具体的说是首先设定阈值,该阈值一般取10,然后判定字块起止y坐标值的差是否小于阈值,小于则判定为同行,否则判定为不同行。该阈值用于识别字符是否同行,因为在pdf识别的时候,即使同行的文字,也可能因为扫描角度,文字大小,字体,行间距(1.15倍间距、1.5倍间距等)等因素被识别为不同行。使用该阈值后,文字识别过程中的一般错位差值都能够被解决。如果在判断中发现不同字块的高度差小于阈值,则判定两个字块属于同一行。当然对于不同文档,该阈值是可以调整的,这里给出的阈值10是一个典型值,一般来说这个阈值的取值范围为5-15。
前述构建字符串的过程,对每个字块按照从上至下,从左至右的顺序整理字块,读取的字块首先存储在字块列表中,字块先后顺序有错位情况。构建行字串,是为了屡出字块顺序。当一个字块整理完成后,按照上述顺序整理全部字块。
步骤四:定位片段位置
根据格式中规定的关键词来发现内容片段位置。多个字块构成行字串对象即行,多行构成片段。通过关键词检索的方式实现片段定位。本步骤所述的关键词是指文献规定的特定词,例如“摘要”、“关键词”、“文献标志码”、“文章编号”等,如附图2所示。通过这些特定的关键词可以在步骤二中的字块列表中定位出内容片段。
标题的发现,有两种方法。第一种是根据摘要的发现来确定存在标题。用关键词“摘要”遍历字块,将“摘要”所在字块之前的字块全部取出,用步骤三的方法判断字串行中的字大小,并排除已知过滤项。所述的已知过滤项是指文献中规律出现的非标题字符,例如页眉和页脚中出现的期刊名称、文献所属板块、页码等。对于不同文献其已知过滤项是不同的,但是对于一个具体的文献其已知过滤项是唯一确定,且是可以提前预知的。这些已知过滤项在步骤一中可以被解析出来,作为本步骤的输入参量。经过上述操作,得到的字串即为标题。当然在某些文献中没有“摘要”,此时只需要根据文献特点,选取特定关键词即可完成上述功能。第二种是根据对比各个字串行中字大小并排除已知过滤项来发现标题。字串行中字大小用步骤三的方法判断,已知过滤项与前相同。
根据破折号判定次行是否是副标题,如果是副标题则拼单独存储,否则判断是否是人名、单位。
两方法共有的办法是:由于标题的字大小比一般内容都大,按其字大小及行高判断大可能是标题,同时排除页眉部分行高较大的文字干扰。这样仅能以较大几率获得标题,如果此时识别仍出现错误,则在后期人工校对中加以修正。
进行作者、单位等的判断按照下述方法进行。首先判断字符串之间是否存在两个或两个以上规律的逗号或者空格,如果存在则判定其为作者,如果不存在则判断是否存在特殊字符,如果存在特殊字符则从起始位置重新执行,如果没有特殊字符则通过特殊关键词判断是否是单位,所述的特殊关键词包括“中心”、“教育”、“医院”、“学院”、“学校”、“大学”、“中学”、“小学”、“局”、“公司”、“区”、“省”、“市”,如果包含上述特殊关键词,则判定该字符串为单位,前序字符串为作者。
摘要片段的识别方法,用特殊摘要字符串进行“摘要”的匹配,所述的特殊摘要字符串包括中文摘要字符串和英文摘要字符串。其中中文摘要字符串是“\s*【?[?\[?摘\s*要\s*\]?]?】?:?:?\s*\w*”。该特殊中文摘要字符串充分考虑了,“摘要”、“摘要”、“【摘要】”、“[摘要]”,以及是否有冒号等多种情况,可以适用于几乎所有pdf文档的摘要识别。英文摘要字符串是“\s*【?[?\[?(abstract|abstract)\s*\]?]?】?:?:?院?\s*”。
关键词的识别方法,用特殊关键词字符串进行“关键词”的匹配,特殊关键词字符串包括两个,分别为“\s*【?[?\[?关\s*键\s*词\s*\]?]?】?:?:?\s*\w*”和“\s*【?[?\[?关\s*键\s*字\s*\]?]?】?:?:?\s*\w*”。因为在不同文献中,关键词和关键字均有出现,同时考虑是否包括括号、是否包括空格、是否包括冒号、括号的字体、空格的个数,故使用上述两个特殊关键词字符串。
参考文献的识别方法,它也是文章结尾的判定方法,学术期刊都以“参考文献”为文章结束,不免存在个别没有“参考文献”的情况。发现参考文献,关联最近的没有关联参考文献的文章标题,完结发生文章处理。发现多个参考文献的页分别关联匹配。所述的分别关联匹配是指有转接页时,根据转接页的指示将参考文献匹配到相应文章中。
正文分栏识别处理方法,正文分栏有三类(无分栏、分左右两栏、分左中右三栏)。分栏的识别处理方法是根据相邻字块在同行并且两字块之间存在一定的距离,比一般相邻字块距离要大3倍以上。所述的相邻字块的距离是指后一字块起点的x坐标与前一字块终点x坐标的差。比如相邻字块有“a字块”“b字块”,a字块在b字块左边,它们的距离就是b字块的起点x坐标(startlocation[0])减去a字块的终止点x坐标(endlocation[0])的值。这个距离在指定的预设定分栏参数范围内,表示发现分栏。在对发现的字块放入不同分栏区。比如一篇文章,页面中内容分成两栏或三栏,附图3是分两栏的,分栏是将版面分成几个大的区域,不同区域中有多个行,程序对每个行会创建行字串对象,每个行字串对象中有一个个的字块按x坐标顺序存放。如附图3所示。
正文分隔识别处理方法,正文分隔的识别是根据比对字串行的多项行高差值,发现其行高值超出一般行高差值,并且是跨栏的,被视为存在内容分隔。但是由于期刊的格式多样化,并不能完全确切一定是不同文章的分隔。具体的说,分隔的识别按照下述方法进行:根据比对字串行的多项行高差值,发现其行高值超出一般行高差值,并且是跨栏的,被视为存在内容分隔。如图4中的“4.3防窃电的具体措施”这行与下面的“上接第384页”这行之间的行高差值(依行高差值为特征值计算),比较发现该值超出一般行高差值。在该两之间会识别有分隔。
所述的期刊格式多样化的情况:指的是图片或者公式的情况出现,使得正文内容中字串行间距达到比其他字串行间距都大,如图5所示。
步骤五:划分片段范围
根据文章格式关键词行索引值划分主要文章片段,如附图6,本步骤的片段是指文章不同构成的意思,即标题、摘要、关键词、正文、参考文献为不同片段,步骤四种的片段也是相同的意思。
学术期刊中文章标题部分起头都是另起页的顶部开始,以参考文献为结束部分。存在占有篇幅半篇的片段内容,一般会向下转接到后面某篇文章存在半篇内容的片段页。也有存在向前转接的片段。此情况的片段间距较大,有的存在“上接第几页”字样就以此发现分隔。
步骤六:获取文章片段内容
根据文章相邻格式关键词区分文章主要片段内容。所述的格式关键词是指按序出现的“摘要:”“关键词:”“中图分类号:”“参考文献”,这些是论文文章格式规定的关键词,“摘要:”和“关键词:”就是两个相邻的关键词。相邻格式关键词之间的内容为这两个格式关键词中前一个格式关键词的内容。按照上述原则将文章全部内容归类到不同格式关键词下。
步骤七:划分pdf页内容类型
各pdf页内容类型,即文章解析类别,按文章的一个pdf页内容是否存在标题或参考文献划分文章类别。文章存在的标题为头,存在的参考文献为尾。文章解析类别有:一头一尾(headandfoot),只无尾的(onlyhead),无头无尾的(noheadnofoot),只无头页存在1个参考文献(noheadhavonefoot),只无头页存在两个参考文献(noheadhavetwofoot),有头有多尾(headhavetwofoot),有头有另一文献尾(headhaveotherfoot),无头一个其他尾(noheadhaveotherfoot)。判断上述八种情况的标准为:1、pdf文件中的一个pdf页,有一篇文章标题,也有一个参考文献,就判定为一头一尾;2、pdf文件中的一个pdf页,有一篇文章标题,但没有参考文献,就判定为只无尾的;3、pdf文件中的一个pdf页,没有文章标题,也没有参考文献,就判定为无头无尾;4、pdf文件中的一个pdf页,没有文章标题,有一个参考文献,就判定为只无头页存在1个参考文献;5、pdf文件中的一个pdf页,没有文章标题,有两个参考文献,就判定为只无头页存在两个参考文献;6、pdf文件中的一个pdf页,有一篇文章标题,有两个参考文献,就判定为有头有多尾;7、pdf文件中的一个pdf页,有一篇文章标题,有转接页标识(如:“上接第87页”),之后有一个参考文献,就判定为有头有另一文献尾;8、pdf文件中的一个pdf页,没有文章标题,有转接页标识(如:“上接第87页”),之后有一个参考文献,就判定为无头一个其他尾。
步骤八:接合
文章解析类别与文章结尾拼接处理方法,如果一页中一同存在标题和参考文献,将以就近匹配识其为一篇完整文章,如果存在有转接页的情况,根据转接页接合,加入完整文章队列。所述的完整文章队列是解析后判定为完整文章的队列,文章队列是解析完后的队列,解析完后完整和不完整的队列都会加入到文章队列里。否则如果是文章起始页加入非完整文章队列,不完整队列中的文章会待找到最近的结尾片段或者指定转接页码的结尾片段。比如:有页序的相邻文章a和文章b,文章a占两页半(假设只有页码是7、8、11),文章b占两页半(假设页码是9、10、11),a文章标题所在的页码小于b文章的标题所在的页码,这种情况下文章排版方式会是:a文章的那半页会并入文章b的半页内容的后面,内容凑成一个整页,文章a和文章b会共占5页,而不是6个页。程序来发现出这个凑成一个整页(页码11)的两片段内容(即两个结尾)。上半页(页码11)与文章b最近,文章b开头与这上半页结尾匹配。这个文章b匹配完后,那下半页(页码11)里的文章结尾与没有匹配结尾的文章a最近,文章a开头与这上半页结尾匹配。如果是文章中间内容页,就近接入或者按转接页标识接入相应文章片段中,比如前述的文章a(假设只有页码是7、8、11),其中的页码为8的页种没有标题没有结尾是文章中间内容页,页码为7的这页中有文章标题,这第8页会追加入第7页文章里,其实现方法是程序会给每个pdf页创建文章信息对象(页码为7、8、9、10、11的),文章信息对象中有个属性是文章后续片段的列表,这个列表可以添加后续的文章信息对象,这样在页码为7的这个文章信息对象的文章后续片段列表中加入页码为8、11的文章信息对象,文章a的整篇内容就是从页码为7、8、11的这写文章信息对象里凑出来了。直到后续发现与其相应的参考文献,表示文章结尾页,才完成匹配文章拼接,再移到完整文章队列。
步骤九:形成文章列表
直到期刊中的所有文章读取解析完毕,没有找到参考文献的文章最后列入文章列表。
本发明提供了一种适用于期刊类pdf文件中文章内容的解析方法。通过本发明,可以对常规格式的期刊pdf文件中文章内容的特定片段抽取,发掘出其中的各篇文章。解析出关键性内容项:标题、作者、单位信息、中图分类号、文献标志码、文章编号、摘要、关键词、正文、参考文献。发现并处理分栏、分隔的内容片段、接合文章内容。
本发明基于itextsharp读取出pdf文件中携带坐标信息的文字块。再根据y坐标值区分同行,经过行字串排序方法完成字顺序整理。文章大体上存在固定格式,不同出版社有不同格式细节。根据其中文章的固定格式以及关键词,发现文章片段的起始位置的字行索引值。再根据特定片段一般占有行数,以及前后相邻关键词起始位置的字行索引值,划分文章片段范围,获取文章片段内容。
- 还没有人留言评论。精彩留言会获得点赞!