一种用于自由空间估计、物体检测和物体姿态估计的统一深度卷积神经网络的制作方法
本公开一般涉及车辆视觉系统,并且更具体地涉及在车辆视觉系统中使用神经网络。
背景技术:
视觉系统可以使车辆能够感知前方道路上的物体和障碍物。视觉系统可以使用神经网络来执行物体检测。神经网络可能是计算密集的。神经网络可对车辆的计算能力具有较高要求。
因此,希望能提供一种对车辆的计算能力具有较低要求的神经网络架构。此外,根据随后的本发明的具体实施方式和所附权利要求书,结合本发明的附图和背景技术,本发明的其他期望的特征和特性将变得显而易见。
技术实现要素:
提供了一种车辆中的处理器实现的方法,用于使用深度学习算法在同一网络中同时执行多个车载感测任务。该方法包括接收来自车辆上的传感器的视觉传感器数据,使用卷积神经网络中的多个特征层根据视觉传感器数据确定特征组,并且使用卷积神经网络从由多个特征层确定的特征组中同时估计检测到的物体的边界框、自由空间边界以及检测到的物体的物体姿态。
神经网络可以包括:多个自由空间估计层,其配置为评估特征组以确定视觉传感器数据中相对于车辆的自由空间的边界并且标记边界;多个物体检测层,其配置为评估特征组以检测图像中的物体并估计围绕检测到的物体的边界框;以及多个物体姿态检测层,其配置为评估特征组以估计每个物体的方向。
神经网络可以进一步包括多个特征层,它们配置为确定作为多个自由空间估计层、多个物体检测层和多个物体姿态检测层的输入进行共享的特征组。
可以使用inceptionnet架构来配置特征层。
可以使用stixelnet架构配置自由空间估计层。
可以使用单次多重检测器(ssd)架构来配置物体检测层。
由物体姿态检测层估计的方向可以是量化值。
该方法可以进一步包括使用循环分段线性(pl)损失函数来训练物体姿态检测层。
使用循环pl损失函数训练物体姿态检测层可以包括将0到360度之间的不同值分配给多个bin中的每一个;利用加权因数向具有更接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。
该方法可以进一步包括使用估计的边界框、自由空间边界和物体姿态来估计供车辆使用的当前和未来世界状态。
提供了一种用于训练卷积神经网络以使用深度学习算法在同一网络中同时执行至少三个不同图像感测任务的处理器实现的方法。卷积神经网络至少包括任务层的第一组、第二组和第三组以及特征层的常用组(通常由任务层的第一、第二和第三组中的每一个使用其输出)。训练任务层的第一、第二和第三组中的每一个以分别执行三个不同图像感测任务中的不同的一个。该方法包括训练任务层的第一组和特征层的组以确定使任务层的第一组的损失函数最小化的任务层的第一组中的和特征层中的系数,训练任务层的第二组,同时对固定为它们最后确定的值的特征层中的系数进行保持,以确定使任务层的第二组的损失函数最小化的任务层的第二组中的系数,训练任务层的第三组,同时对固定为它们最后确定的值的特征层中的系数进行保持,以确定使任务层的第三组的损失函数最小化的任务层的第三组中的系数,并使用这些层中的每一个的最后确定的系数作为重新训练的起点,共同重新训练任务层的第一、第二和第三组以及特征层以确定使任务层的第一、第二和第三组的每一个的损失函数最小化的任务层的第一、第二和第三组的每一个中的以及特征层中的系数。
任务层的第一组可以是可用训练数据的数量最大的任务层的组,或者是可用训练数据具有最好的质量的任务层的组。
任务层的第二组可以是可用训练数据的数量第二大的任务层的组,或者是可用训练数据具有次好的质量的任务层的组。
可以选择多个物体检测层作为任务层的第一组,可以选择多个物体姿态检测层作为任务层的第二组,并且可以选择多个自由空间估计层作为任务层的第三组。
可以使用stixelnet架构来配置自由空间估计层。
可以使用单次多重检测器(ssd)架构来配置物体检测层。
训练物体姿态检测层可以包括确定循环分段线性(pl)损失。确定循环pl损失可以包括将0到360度之间的不同值分配给多个bin中的每一个;利用加权因数向具有更接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。
提供了一种用于确定由车辆检测到的物体的姿态的车辆中的处理器实现的方法。该方法包括使用循环pl损失函数来训练包括多个物体姿态检测层的卷积神经网络,这些层配置为评估从车辆上的传感器接收的视觉传感器数据导出的特征组以估计检测到的物体的方向。使用循环pl损失函数的训练包括将0到360度之间的不同中心值分配给多个bin中的每一个;向具有最接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。该方法进一步包括使用物体姿态检测层来估计从车辆上的传感器接收到的视觉传感器数据中的检测到的物体的物体姿态。
将估计的姿态分配给两个bin可以包括利用加权因数向具有最接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比。
附图说明
当与附图一起阅读时,根据以下具体实施方式可以最好地理解本公开的各方面,其中相同的附图标记表示相同的元件,并且
图1是根据一些实施例的描绘了示例车辆的框图;
图2是根据一些实施例的可使用深度学习算法同时执行多个车载感测任务的示例卷积神经网络的框图;
图3是根据一些实施例的描绘了用于使用深度学习算法在同一神经网络中同时执行多个车载感测任务的示例处理器实现过程的过程流程图;
图4是根据一些实施例的描绘了用于训练卷积神经网络以使用深度学习算法在同一网络中同时执行至少三个不同图像感测任务的示例过程的过程流程图;
图5是根据一些实施例的描绘了用于训练多个姿态估计层的示例架构的框图;并且
图6描绘了根据一些实施例已用从神经网络中同时执行的多个车载感测任务导出的符号进行注释的示例图像。
具体实施方式
以下公开提供了用于实现所提供的主题的不同特征的许多不同实施例或示例。以下具体实施方式本质上仅仅是示例性的,并不旨在限制本发明或本发明的应用和使用。此外,不旨在受到前面背景技术或以下具体实施方式中呈现的任何理论的限制。
本文描述的主题公开了用于使用神经网络在车辆中同时执行多个视觉感测任务的装置、系统、技术和物品。所描述的技术提供了一种网络架构,其中由并发执行的任务层的多个组共享多个特征层。还提供了一种用于训练神经网络的技术。
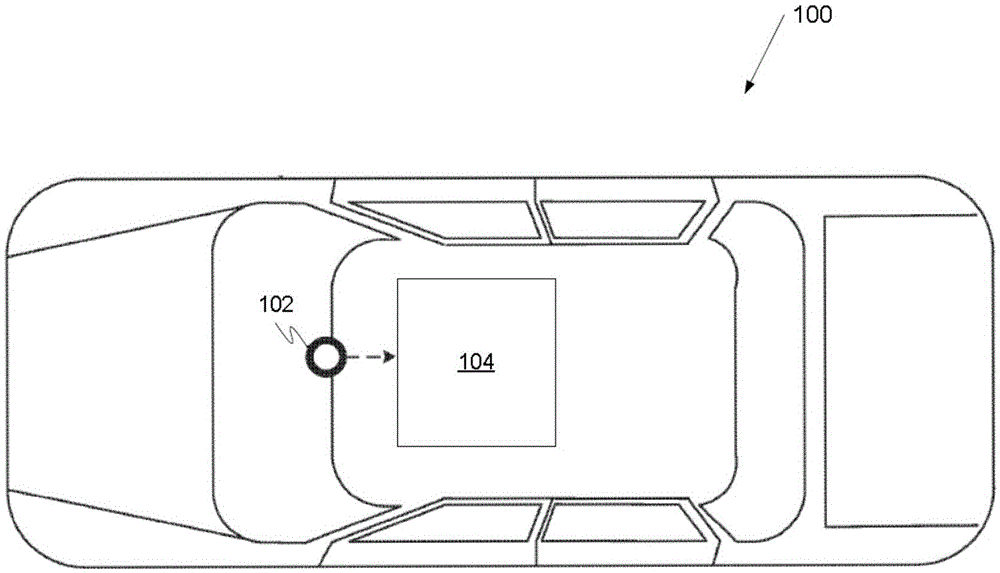
图1是描绘了示例车辆100的框图。示例车辆100可以包含汽车、卡车、公共汽车、摩托车等。示例车辆100包括示例视觉传感器102和示例视觉系统104。示例视觉传感器102感测车辆100附近的可观察状况,并且可以包含摄像头、激光雷达、雷达等。示例视觉传感器102生成由示例视觉系统104使用的视觉传感器数据。在该示例中,示例视觉传感器102是生成图像数据形式的车辆100外部的场景的视觉图像的摄像头。
示例视觉系统104接收图像数据并处理图像数据以执行多个车载感测任务。示例视觉系统104包含车辆内的一个或多个处理器,通过在计算机可读介质中编码的编程指令来配置它们。示例视觉系统104可以使用在计算机可读介质中编码并由一个或多个处理器执行的深度学习算法来在神经网络中同时执行多个车载感测任务。示例视觉系统104执行的示例车载感测任务可以包括物体检测、自由空间检测和物体姿态检测。车辆100中的其他系统可以使用来自由示例视觉系统104执行的车载感测任务的输出来估计当前和未来的世界状态以例如在自主驾驶模式或半自主驾驶模式中辅助车辆100的操作。
每个车载感测任务可以使用不同的计算技术。每个任务都可以使用深度学习算法并竞争计算资源。深度学习(也称为深层结构学习、分层学习或深度机器学习)是一类机器学习算法,其使用非线性处理单元的多层级联来进行特征提取和转换。每个相继层使用前一层的输出作为输入。
图2是可使用深度学习算法同时执行多个车载感测任务的示例卷积神经网络200的框图。示例神经网络200包括多个卷积特征层202,它们从图像传感器(未示出)接收输入图像204,例如以rgb信号的形式。特征层202配置为确定作为多个上层卷积视觉任务层的输入进行共享的特征组。可以使用inceptionnet架构来配置示例特征层202。
在该示例中,上层视觉任务层包含多个卷积自由空间估计层206、多个卷积物体检测层208,以及多个卷积物体姿态检测层210。多个自由空间估计层206配置为评估特征组以确定输入图像204中相对于车辆的自由空间的边界并标记边界。在该示例中,用stixel标记边界。多个物体检测层208配置为评估特征组以检测图像204中的物体并且估计围绕检测到的物体的边界框。多个物体姿态检测层210配置为评估特征组以估计每个检测到的物体的方向。对物体的方向(即,物体的姿态)的检测可以使得车辆系统能够预测每个检测到的物体的运动。
经由自由空间估计层206、多个卷积物体检测层208和多个卷积物体姿态检测层210来配置示例卷积神经网络200,以根据由共享的特征层202确定的特征组来同时估计检测到的物体的边界框、自由空间边界和检测到的物体的物体姿态。与在不同的神经网络中分别执行自由空间估计任务、物体检测任务和物体姿态任务的架构相比,示例神经网络200的架构可使得计算资源得到更高效的利用。示例神经网络200可以实现使用inceptionnet架构的特征层、使用单次多重检测器(ssd)架构的物体检测层,以及使用stixelnet架构的自由空间检测层。weiliu、dragomiranguelov、dumitruerhan、christianszegedy、scottreed、cheng-yangfu和alexanderc.berg的《ssd:单次多重检测器》(“ssd:singleshotmultiboxdetector”)中提供了ssd架构的一个示例。
stixelnet架构对图像的柱状部分(例如,stixel)起作用。stixelnet架构可以包括五层,其中前两层是卷积的并且后三层是完全连接的。stixelnet架构还可以包含确定分段线性概率损失。在授予danlevi的题为《使用单个移动摄像头的动态stixel估计》(“dynamicstixelestimationusingasinglemovingcamera”)的美国专利申请第15/085082号(其通过引用并入本文);授予danlevi和noagarnett的题为《使用深度学习的stixel估计和道路场景分割》(“stixelestimationandroadscenesegmentationusingdeeplearning”)的美国专利申请第15/092853号(其通过引用并入本文);以及danlevi、noagarnett、ethanfetaya的《stixelnet:用于障碍物检测和道路分割的深度卷积网络》(“stixelnet:adeepconvolutionalnetworkforobstacledetectionandroadsegmentation”,其通过引用并入本文)中提供了使用stixel和stixelnet架构的示例。
提供姿态估计层的目的是最小化循环分段线性损失函数。测量姿态预测结果与地面真实姿态之间的误差来作为角度差。例如,姿态预测结果可以预测检测到的物体指向15度角,而真实姿态是检测到的物体指向18度角。在这种情况下,角度差是3度。
图3是描绘了用于使用深度学习算法在同一神经网络中同时执行多个车载感测任务的示例处理器实现过程300的过程流程图。示例过程300包括从图像传感器接收输入图像(操作302)。图像传感器可以是提供rgb图像作为输入图像的车载摄像头。
估计来自输入图像的特征组(操作304)。可以根据卷积神经网络中的多个特征层来估计该特征组。可以使用inceptionnet架构来实现该多个特征层。
根据该特征组,同时执行多个视觉检测任务。在该示例中,同时执行的视觉检测任务包括估计检测到的选项的边界框(操作306)、估计自由空间边界(操作308),以及估计检测到的物体的姿态(操作310)。可以由可用ssd架构来配置的卷积神经网络中的多个物体检测层来估计检测到的物体的边界框。可以由可用stixelnet架构来配置的多个自由空间边界检测层来估计卷积神经网络中的自由空间边界。
可以由多个物体姿态检测层来在卷积神经网络中估计物体姿态。可以配置物体姿态检测层来使循环分段线性损失函数最小化。由物体姿态检测层估计的方向可以是量化值。在一个示例中,该方向可以是八个不同的量化值中的一个。可以使用确定循环pl损失的循环分段线性(pl)损失函数来训练物体姿态检测层。确定循环pl损失可以包括将0到360度之间的不同中心值分配给多个bin中的每一个;如果估计的姿态值等于分配给一个bin的值,则将估计的姿态分配给该bin;利用加权因数向具有更接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。
图4是描绘了用于训练卷积神经网络以使用深度学习算法在同一网络中同时执行至少三个不同图像感测任务的示例过程400的过程流程图。在该示例中,卷积神经网络至少包括任务层的第一组、第二组和第三组以及常用的多个特征层,通常由任务层的第一、第二和第三组中的每一个使用常用的多个特征层的输出)。在该示例中,将训练任务层的第一、第二和第三组中的每一个来分别执行三个不同图像感测任务中的不同的一个。
示例过程400包括训练任务层的第一组和特征层(操作402)以确定使任务层的第一组的损失函数最小化的任务层的第一组中的和多个特征层中的系数。完全训练任务层的第一组和多个特征层,就像该神经网络中只含有它们一样。
示例过程400接下来包括训练任务层的第二组,同时对固定为它们最后确定的值的特征层中的系数进行保持(操作404),以确定使任务层的第二组的损失函数最小化的任务层的第二组中的系数。
接下来,示例过程400包括训练任务层的第三组,同时对固定为它们最后确定的值的特征层中的系数进行保持(操作406),以确定使任务层的第三组的损失函数最小化的任务层的第三组中的系数。
最终,使用这些层中的每一个的最后确定的系数作为训练的起点,共同训练任务层的第一、第二和第三组以及特征层(操作408)以确定使任务层的第一、第二和第三组的每一个的损失函数最小化的任务层的第一、第二和第三组的每一个中的以及特征层中的系数。
在示例过程400中,可以选择可用训练数据的数量最大的任务层组作为任务层的第一组。可以选择可用训练数据的数量第二大的任务层组作为任务层的第二组。
在示出的示例中,选择多个物体检测层作为任务层的第一组。选择多个物体检测层来进行训练以检测图像中的物体,并且估计围绕检测到的物体的边界框。
在示出的示例中,选择多个物体姿态检测层作为任务层的第二组。选择多个物体姿态检测层来进行训练以确定检测到的物体的物体姿态。
而且,在示出的示例中,选择多个自由空间估计层作为任务层的第三组。选择多个自由空间估计层来进行训练以评估特征组以确定输入图像中自由空间的边界并标记自由空间边界。
图5是描绘了用于训练多个姿态估计层的示例架构500的框图。向姿态估计层提供了来自图像的特征数据,并且操作姿态估计层来估计图像中的物体的预测姿态502。将预测姿态502与真实姿态信息504进行比较以估计循环分段线性损失函数506中的误差。分段线性损失函数506被用于训练物体姿态检测层508。向物体姿态检测层508提供来自另一个图像的特征数据,并且操作物体姿态检测层来估计新图像中的物体的预测姿态502。再一次,将预测姿态502与真实姿态信息504进行比较以估计循环分段线性损失函数506中的误差,并进而使用分段线性损失函数506来训练物体姿态检测层508。该训练过程可以重复,直到循环分段线性损失函数506的误差估计收敛到可接受的水平。
示例循环分段线性损失函数506类似于分段线性损失函数,因为它们都将测量结果分类到一个或两个bin中。用于训练示例姿态检测层508的示例循环分段线性损失函数506涉及将姿态估计结果分配到bin中。因为将物体的姿态估计为相对于车辆上的点的方向,所以姿态可以具有在0到360度之间的值。在该示例中,提供了用于训练示例姿态检测层508的循环分段线性损失函数506、多个bin,并且为每个bin分配了0到360度之间的不同值。
使用示例循环分段线性损失函数506来估计误差可以涉及将估计的姿态分配到一个或两个bin中。如果姿态估计结果的值等于bin的值,则将姿态估计结果分配给具有相同值的那个bin。如果姿态估计结果具有两个bin值之间的值,则将姿态估计结果分配给具有与姿态估计结果最接近的值的两个bin。给两个bin分配时可以应用加权因数。应用的加权因数可以与估计的姿态值与bin中心值的距离成反比。
可以通过从真实姿态中减去物体的估计的姿态来计算误差。作为示例,物体的真实姿态可能是17度,估计结果可能是13度,而误差可能表示为4度。当姿态接近0度/360度跨越点时,可能不能直截了当地进行误差计算。作为示例,如果真实的姿态是358度,估计的姿态是4度,那么误差可能只有6度而不是354度。为了解决这个问题,示例循环分段线性损失函数506可允许将估计的姿态放置在具有最接近360度的值的bin中和具有最接近0度的值的bin中。
因此,使用示例循环分段线性损失函数506来训练示例姿态检测层508可以涉及将0度到360度之间的不同值分配给多个bin中的每一个;如果估计的姿态值等于分配给一个bin的值,则将估计的姿态分配给该bin;如果估计的姿态值落在分配给两个bin的值之间,则将估计的姿态分配给这两个bin;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。给两个bin分配时可以应用加权因数。应用的加权因数可以与估计的姿态值与bin中心值的距离成反比。
在图6中描绘了已用从使用深度学习算法在神经网络中同时执行的多个车载感测任务导出的符号进行注释的示例图像600。示例图像600已经用围绕图像600中的检测到的物体的由物体检测层估计的边界框602、定义图像600中的自由空间的边界的由自由空间估计层估计的stixel604,以及标识图像600中的检测到的物体的姿态方向的由物体姿态检测层估计的箭头606进行了注释。
本文描述了用于使用神经网络在车辆中同时执行多个视觉感测任务的技术。所描述的技术提供了一种网络架构,其中由并发执行的任务层的多个组共享多个特征层。还提供了一种用于训练神经网络的技术。
在一个实施例中,提供了一种车辆中的处理器实现的方法,用于使用深度学习算法在同一网络中同时执行多个车载感测任务。该方法包含接收来自车辆上的传感器的视觉传感器数据,使用卷积神经网络中的多个特征层根据视觉传感器数据确定特征组,并且使用卷积神经网络根据由多个特征层确定的特征组同时估计检测到的物体的边界框、自由空间边界以及检测到的物体的物体姿态。
这些方面和其他实施例可以包括以下特征中的一个或多个。神经网络可以包含:多个自由空间估计层,其配置为评估特征组以确定视觉传感器数据中相对于车辆的自由空间的边界并且标记边界;多个物体检测层,其配置为评估特征组以检测图像中的物体并估计围绕检测到的物体的边界框;以及多个物体姿态检测层,其配置为评估特征组以估计每个物体的方向。神经网络可以进一步包含多个特征层,它们配置为确定作为多个自由空间估计层、多个物体检测层和多个物体姿态检测层的输入进行共享的特征组。可以使用inceptionnet架构来配置特征层。可以使用stixelnet架构来配置自由空间估计层。stixelnet架构可以包含五层,其中前两层是卷积的并且后三层是完全连接的。训练stixelnet架构可以包含确定分段线性概率损失。可以使用单次多重检测器(ssd)架构来配置物体检测层。由物体姿态检测层估计的方向可以是量化值。该方向可以包含八个不同的量化值中的一个。该方法可以进一步包含使用循环分段线性(pl)损失函数来训练物体姿态检测层。使用循环pl损失函数训练物体姿态检测层可以包含将0到360度之间的不同值分配给多个bin中的每一个;利用加权因数向具有更接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。bin的数量可以等于八。该方法可以进一步包含使用估计的边界框、自由空间边界和物体姿态来估计供车辆使用的当前和未来世界状态。
在另一个实施例中,提供了一种用于训练卷积神经网络以使用深度学习算法在同一网络中同时执行至少三个不同图像感测任务的处理器实现的方法。卷积神经网络至少包含任务层的第一组、第二组和第三组以及特征层的常用组,通常由任务层的第一、第二和第三组中的每一个使用特征层的常用组的输出。将训练任务层的第一、第二和第三组中的每一个来分别执行三个不同图像感测任务中的不同的一个。该方法包含训练任务层的第一组和特征层的组以确定使任务层的第一组的损失函数最小化的任务层的第一组中的和特征层中的系数,训练任务层的第二组,同时对固定为它们最后确定的值的特征层中的系数进行保持,以确定使任务层的第二组的损失函数最小化的任务层的第二组中的系数,训练任务层的第三组,同时对固定为它们最后确定的值的特征层中的系数进行保持,以确定使任务层的第三组的损失函数最小化的任务层的第三组中的系数,并使用这些层中的每一个的最后确定的系数作为重新训练的起点,共同重新训练任务层的第一、第二和第三组以及特征层以确定使任务层的第一、第二和第三组的每一个的损失函数最小化的任务层的第一、第二和第三组的每一个中的以及特征层中的系数。
这些方面和其他实施例可以包括以下特征中的一个或多个。任务层的第一组可以是可用训练数据的数量最大的任务层的组,或者是可用训练数据具有最好的质量的任务层的组。任务层的第二组可以是可用训练数据的数量第二大的任务层的组,或者是可用训练数据具有次好的质量的任务层的组。可以选择多个物体检测层作为任务层的第一组,可以选择多个物体姿态检测层作为任务层的第二组,并且可以选择多个自由空间估计层作为任务层的第三组。可以使用stixelnet架构来配置自由空间估计层。可以使用单次多重检测器(ssd)架构来配置物体检测层。训练物体姿态检测层可以包含确定循环分段线性(pl)损失。确定循环pl损失可以包含将0到360度之间的不同值分配给多个bin中的每一个;利用加权因数向具有更接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。
在另一个实施例中,提供了一种用于同时在视觉传感器数据上同时执行自由空间估计、物体检测和物体姿态估计的车辆中的处理器实现的感测系统。该感测系统包含一个或多个处理器,以及编码有可配置为使得一个或多个处理器执行方法的编程指令的非暂时性计算机可读介质。该方法包含接收来自车辆上的传感器的视觉传感器数据,使用卷积神经网络中的多个特征层根据视觉传感器数据确定特征组,并且使用卷积神经网络进行:使用卷积神经网络中的多个物体检测层同时估计检测到的物体的边界框,多个物体检测层配置为评估特征组以检测图像中的物体并估计围绕检测到的物体的边界框;使用卷积神经网络中的多个自由空间估计层同时估计自由空间边界,多个自由空间估计层配置为评估特征组以确定视觉传感器数据中的相对于车辆的自由空间的边界并且标记边界;并且使用卷积神经网络中的多个物体姿态检测层同时估计检测到的物体的物体姿态,多个物体姿态检测层配置为评估特征组以估计每个物体的方向。
这些方面和其他实施例可以包括以下特征中的一个或多个。该方法可以进一步包含使用估计的边界框、自由空间边界和物体姿态来估计供车辆使用的当前和未来世界状态。
在另一个实施例中,提供了一种用于确定由车辆检测到的物体的姿态的车辆中的处理器实现的方法。该方法包含使用循环pl损失函数来训练卷积神经网络,该卷积神经网络包括多个物体姿态检测层,它们配置为评估从车辆上的传感器接收的视觉传感器数据导出的特征组以估计检测到的物体的方向。使用循环pl损失函数的训练包含将0到360度之间的不同中心值分配给多个bin中的每一个;向具有最接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态;并且如果估计的姿态值高于分配给最高值bin的值,或者如果估计的姿态值低于分配给最低值bin的值,则将估计的姿态分配给最高值bin和最低值bin这两者。该方法进一步包含使用物体姿态检测层来估计从车辆上的传感器接收到的视觉传感器数据中的检测到的物体的物体姿态。
这些方面和其他实施例可以包括以下特征中的一个或多个。将估计的姿态分配给两个bin可以包含利用加权因数向具有最接近估计的姿态值的分配的中心值的多个bin中的两个bin分配估计的姿态,其中加权因数与估计的姿态值和bin中心值的距离成反比。
前面概述了若干实施例的特征,使得本领域技术人员可以更好地理解本公开的各个方面。本领域技术人员应当理解,他们可易于使用本公开作为设计或更改用于贯彻本文介绍的实施例的相同目的和/或实现相同优点的其他过程和结构的基础。本领域技术人员应当认识到,这样的等同结构不脱离本公开的精神和范围,并且他们可在不脱离本公开的精神和范围的情况下在本文中进行各种改变、替换和变化。
- 还没有人留言评论。精彩留言会获得点赞!