一种基于标签优化的图像再识别系统及损失函数确定方法与流程
本发明涉及机器学习技术领域。更具体地,涉及一种基于标签优化的图像再识别系统及损失函数确定方法。
背景技术:
当今再识别技术通过使用不同的深度学习网络架构(如cnn,resnet和vggnet等)和复杂算法(如rbm,adam和rmsprop等),加上在日渐先进的硬件条件(gpu)帮助下已经达到了很高的准确度,但是有一种最简单的方法,通过增大数据集来让网络学到更加准确的数据特征提高准确度。但是获得有标签的数据是比较昂贵的,所以就通过增加没有标签的数据集来进行训练。
增加没有标签的数据方式比较多也比较容易,如直接从网络上下载,对有标签的数据去标签等,如今最新的方法就是使用生成对抗网络(generativeadversarialnets,gan)生成没有标签的图片,原因是省去了从网上下载数据的工作,并且gan生成图片来自于原始图片,故这些图片会尽量和原始图片来自于同一个分布。对gan生成的没有标签的数据集,现有三种方法处理:1)allinone:把所有没有标记的图片当作一个类;2)pseudolabel:每一张没有标签的图片求得对所有类的概率,有最大的概率的类就将这个类的标签分配给图片;3)lsro(labelsmoothingregularizationforoutliers):一个标签可能来源是其他所有类的线性组合,没有标签的图片不属于任何一类,是所有类的线性组合,且系数都是1/k,k是有标签数据的类的总数,在损失函数中,每个标签是每个类概率的log形式的均匀分布,但是,当有标签的图片过少时易出现过拟合的情况。
技术实现要素:
本发明的一个目的在于提供一种基于标签优化的图像再识别损失函数确定方法,本发明的另一个目的在于提供一种基于标签优化的图像再识别系统,解决有标签的图片不多时易出现的过拟合现象,提高再识别准确度。
为达到上述目的,本发明采用下述技术方案:
本发明一方面公开了一种基于标签优化的图像再识别损失函数确定方法,包括
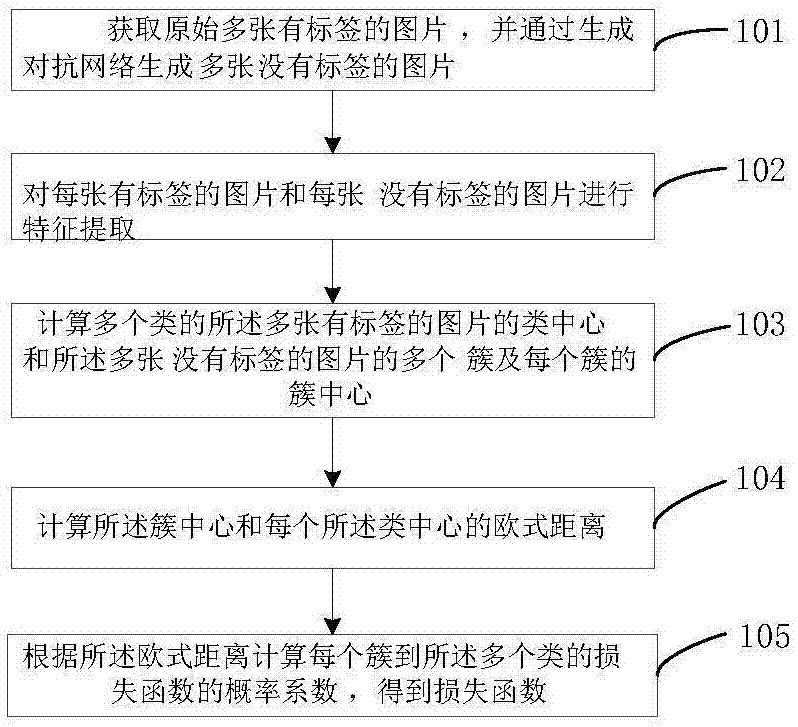
获取原始多张有标签的图片,并通过生成对抗网络生成多张没有标签的图片;
对每张有标签的图片和每张没有标签的图片进行特征提取;
计算多个类的所述多张有标签的图片的类中心和所述多张没有标签的图片的多个簇及每个簇的簇中心;
计算所述簇中心和每个所述类中心的欧式距离;
根据所述欧式距离计算每个簇到所述多个类的损失函数的概率系数,得到损失函数。
优选地,所述对每张有标签的图片和每张没有标签的图片进行特征提取具体包括:
所述有标签的图片和没有标签的图片为rgb图片;
每张图片特征提取后表示为
x=[mean_r,mean_g,mean_b,mean_dot]
其中,mean_r是图片的r通道所有像素的平均值,mean_g是图片的g通道所有像素的平均值,mean_b是图片的b通道所有像素的平均值,mean_dot是mean_r、mean_g和mean_b的加权平均值。
优选地,每个类的类中心为该类的有标签的图片的特征的和与该类所有图片的数量的比值。
优选地,所述类中心centroid为
其中,k为有标签的图片的数量。
优选地,计算所述多张没有标签的图片的多个簇及每个簇的簇中心具体包括:
计算各图片间的相似矩阵;
计算所述相似矩阵的对角矩阵;
计算laplacian矩阵及laplacian的最优解特征向量;
将所有没有标签的图片的最优解特征向量形成求解矩阵并对矩阵中的每一行做归一化处理;
对归一化处理后的求解矩阵通过k-means算法进行聚类得到多个簇及每个簇对应的多张没有标签的图片;
计算每个簇的簇中心。
优选地,所述类中心为
其中,k’为没有标签的图片的数量。
优选地,所述簇中心和每个所述类中心的欧式距离为
||xclustering_centroids-xcentroids||.2
其中,xcentroids为类中心的坐标,xclustering_centroids为簇中心的坐标。
优选地,所述概率系数为
其中,xcentroids为类中心的坐标,
优选地,所述损失函数为
其中,k为没有标签的图片的数量,当计算没有标签的图片时,z=1,计算有标签的图片时,z=0,p(y)为有标签的图片分布,p(k)为没有标签的图片分布。
本发明另一方面公开了一种基于标签优化的图像再识别系统,包括无监督学习模块、数据集融合模块、半监督学习模块和测试模块;
所述无监督学习模块用于对有标签的图片进行无监督的训练,生成没有标签的图片;
所述数据集融合模块用于将有标签的图片和没有标签的图片进行随机融合;
所述半监督学习模块用于对随机融合的图片根据如上所述的损失函数进行训练,得到测试模型;
所述测试模块用于根据所述测试模型进行再识别,输出识别结果。
本发明的有益效果如下:
本发明提供的这种将gan生成的没有标签的图片使用在半监督的行人再识别的baseline进行训练方法,重点解决了当有标签的数据不够多时,如何使用没有标签的数据进行训练的问题。由于训练的数据增多了,根据机器学习理论可知,有效的减少了过拟合现象的发生。本方法不仅限于行人再识别,将对一系列再识别,如车再识别等问题又具有一定的适用性,具有广泛的前景。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的说明。
图1示出本发明一种基于标签优化的图像再识别损失函数确定方法一个具体实施例的示意图。
图2示出普通的聚类算法的聚类结果。
图3示出本发明谱聚类算法的聚类结果。
图4示出当原始有标签的图片数量少时本发明谱聚类算法的聚类结果。
图5示出ploss函数的曲线图。
图6示出本发明用于行人再识别原理图。
图7示出本发明一种基于标签优化的图像再识别系统一个具体实施例的示意图。
具体实施方式
为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。附图中相似的部件以相同的附图标记进行表示。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。
如图1所示,基于本发明的一个方面,公开了一种基于标签优化的图像再识别损失函数确定方法,本实施例中,所述方法包括:
s101:获取原始多张有标签的图片,并通过生成对抗网络生成多张没有标签的图片。
s102:对每张有标签的图片和每张没有标签的图片进行特征提取。将有标签的图片和没有标签的图片进行简单的特征提取,把每张rgb图片分成4个特征[mean_r,mean_g,mean_b,mean_dot],mean_r是图片的r通道所有像素的平均值,mean_g是图片的g通道所有像素的平均值,mean_b是图片的b通道所有像素的平均值,mean_dot是前三个特征的加权平均值,比如:mean_r=178,mean_g=225,mean_b=78,那么权值就是w=[0.4,0.5,0.1],将权值和前三个特征做内积作为第四个特征,这样做的理由是,行人再识别数据集中,每个类是同一个人再不同摄像头下的不同抓拍景象,那么这个类中所有图片的rgb三个通道值就会很类似,第四个特征指示的是,某张图片某个通道的值大,那这张图片的像素加权平均值就会靠近那个通道的值,从而可以更好表示某个类的特征。
例如,对于一张有标记的128×128×3的图片x:
其中,i是图片的第i个像素,r,g,b分别代表r,g,b通道。
mean_dot=[mean_r,mean_g,mean_b]*wt.
所以每张图片就由如下特征表示:
x=[mean_r,mean_g,mean_b,mean_dot].
s103:计算多个类的所述多张有标签的图片的类中心和所述多张没有标签的图片的多个簇及每个簇的簇中心。
对于有标签的图片求出类中心,具体的是,将所有是一个类的图片对应特征进行求和,除以这个类所有图片的数量,作为这个类的类中心。
具体的,如某一类的有标签的图片共有k张,那么这一类的类中心就是:
这样做的理由是根据行人再识别数据集的特殊性,每个类应该是紧密的,因为每个类中包含一个人在不同视角下的不同景象,每个人的姿势和穿着都是很接近的。这样求出的有标签图片的类中心离这个类中任何一个样本都应该是接近的。
对于没有标签的图片,首先使用谱聚类的方法,将图片聚类成和有标签图片相同数量类的簇,求出簇中心。
具体的,首先先执行谱聚类,谱聚类是一种基于laplacian矩阵的聚类方式,目的是将原来不易分数据,变成和类别数相同大小维度的紧密的簇,这样做可以使得聚类结果更加准确。
具体的,
(1)先求出相似矩阵
以上就是图片i到图片j的相似度,σ是带宽,为超参数。直观上解释,如果两个样本点之间的距离越远,那么它们的相似度就越低,相反,如果样本点越近,相似度就越高。
(2)进一步,求对角矩阵w,w对角线上的每个元素是相似矩阵s每行元素的和,即
(3)进一步,求laplacian矩阵l=w-s。l的性质:对于任何向量
其中,l是对称半正定laplacian矩阵,fi和fj的含义为向量
0≤λ1≤λ2≤…≤λn
聚类的思想就是通过不同样本之间的相似性来将样本点进行分割,理想情况下,聚类的结果是各个簇中的相似性应该很大,而每个簇间的相似性应该很小,这就是graphcut理论。故,目标就是
其中,ai表示第i个簇,目标就是找出一种分割形式,这种形式使分割簇间相似性尽量减小。
现在将目标优化成
其中|ai|指的是ai中所有连接的数量。这样做不仅使得簇间的相似性最
小,同时使得簇内的相似性最大。
当k=2时,目标就是
令
其中,vi是指簇a中第i个点。
根据(3)有
同时,注意到
又
所以问题就可以写成
求解过程中,可以发现,最优解f就是l的次小特征值对应的特征向量。
(4)进一步,通过使用拉格朗日最优化问题求解特征向量,将l的特征向量按列组成矩阵u,对矩阵u的每一行做归一化处理,具体形式为
其中,k为聚类的簇的个数。
(5)进一步,对u的每一行做k-means算法,完成聚类,这样做的目的是,当求得列向量时,每列都有数据集大小个维度,也即,每一个样本点完全可以用一个k维的向量表示,且由于u为正交矩阵,所以u的每列是正交的,故每个特征值之间是互相垂直的,也就是数据的每个维度都不相关,此时就将数据表示成在簇中比较紧致的结果,也即簇间相似性很小,簇内相似度很大。
(6)计算每个簇的簇中心。因为要计算簇中心到类中心的距离,但类中心的维度并不是簇中心的k维,在这里使用的方法是将聚类好的簇中的所有的gan图片求均值得到的结果作为新的簇中心,由于gan图片来自原始图片,故理论上,使用谱聚类完成的聚类结果应该是和原始有标签图片形成的簇是接近的,同理,原始图片的类中心和聚类结果的簇中心不应有太大差距。
故,求得簇中心的公式为:
其中k指的是某簇中所有gan图片的数量。
公开了谱聚类的一个例子,一般的k-means等普通的聚类算法是不能精准完成的聚类,如图2所示,但是谱聚类可以完成的是,通过graphcut原理,将每个样本点和其他的样本点连接,求得它们的相似性,理论上,聚类的理想结果是,聚类的每个簇中样本点相似性很大,簇间的相似性却很小,通过求解这样的优化问题,发现求解问题可以优化为求laplacian矩阵的前k(k为聚类的簇的个数)个特征值对应的特征向量按列组成矩阵u,这样的
s104:求聚类结果的簇中心和原始有标签图片的每个类的类中心的欧式距离。
||xclustering_centroids-xcentroids||.2
其中,xcentroids为类中心的坐标,xclustering_centroids为簇中心的坐标。
s105:以距离作为变量求每个簇到原始有标签图片的所有类的损失函数的概率系数。直觉上,我们假设每个簇中的所有gan图片到一个类的概率系数相同,称为cluster_probabiltiy,这样做的原因是,gan图片来自原始图片,理想情况下,聚类之后相同簇中的gan图片应该是一类,一类到本类的概率系数是相同的。另外,如果一张gan图片离有标签的图片越远,也就是距离越大,gan图片损失来自那张有标签原始图片所属的类的概率系数越小,相反的,如果一张gan图片离有标签的图片越近,也就是距离越小,gan图片损失来自那张有标签原始图片所属的类的概率系数越大。使用的公式是softmax的概率形式(简写成ploss)。
公式的理解就是,当计算某个gan图片形成的簇在损失函数中来自某个类的概率系数时,距离越大,概率系数越小,相反,距离越小,概率系数越大,而且概率系数之和为1。这种情况,称为normalphase。
但是也有一些例外情况,如当有48000张gan图片产生时,为了做对比实验,随机选择8000张或者更少进行实验,那么实验过程中可能有的属于原始类生成的图片完全没有选到。
假设数据集当中只有两个类,考虑到行人再识别数据集的特殊性:1)一个类中是一个人在不同的摄像头下的不同景象,那么一个类中所有样本点在空间中形成的簇应该是紧凑的;2)同时,由于人的身高,体型相近,甚至不同的人可能穿颜色很近的衣服,再加上背景环境类似,不同类组成的簇是有很大一部分是重叠的。根据算法,算出类中心,如图4中的‘*’,当只使用8000张gan图片进行谱聚类时,某些gan图片没有选择到,就只有如图4中的部分选到,但是现在仍然要把原数据聚类成2类:因为图中部分与原来另外一类是有重叠的,那么它的统计特性会迫使聚类将另外一类的部分分开,那么计算另外一类的聚类中心时,会和原本另外一类的类中心接近,故这些样本点相对于本类的类中心的距离越远,那么损失函数中来自于本类的概率系数应该越大了,与之前距离和概率系数成反比不一致,这种现象称为anomalyphase,故公式为:
为了优化公式并且计算的精确性,注意到,如图5所示,指数函数y=exp(x)的导数仍然是指数函数本身,故,在x<0时,指数函数增长缓慢,而x>0,指数函数增长迅速,当第i个簇中心
其中,dismax是一个gan聚类中心到其他所有原始样本点的类中心距离的最大值。
上述这种现象在gan图片含有的数量很少时占主导地位,否则当gan图片含有的类别数量接近原数据集的类别数时,normalphase占主导地位,anomalyphase现象将不再显著。
故,根据以上论述,lbro算法的完整公式为:
其中,xcentroids为类中心的坐标,
同时注意到,理想情况下,gan图片聚类之后的结果是将尽可能为一类的图片聚在一起,那么,每个簇中的没有标签的模糊图片尽可能会和原来有标签的原始图片的某个类中的所有样本点相类似,所以,gan图片聚类之后的每个簇中的所有样本点到相同的类中心的概率系数相同,称为cluster_probability。
求出概率系数之后,将这个概率系数带入损失函数,作为半监督网络中进行行人再识别baseline训练的损失函数,期望提高系统的准确度,使用的损失函数是
其中,k为没有标签的图片的数量,当计算没有标签的图片时,z=1,计算有标签的图片时,z=0,p(y)为有标签的图片分布,p(k)为没有标签的图片分布。当z=1时,损失函数中只有原始图片,使用的是cross-entropy损失,当z=0,损失函数中只有gan生成的没有标签的图片,使用的损失函数是将以上叙述求得的概率系数乘上每个类别概率的log形式,意思为,不指定任何一张没有标签图片以标签,损失函数是任何一个类的损失的线性组合,线性组合的系数就是ploss。
如图6所示,对于有标签的原始图片,仍然使用的损失函数是softmax形式;对于没有标签的gan生成的图片,损失是其他所有类的线性组合,组合系数就是ploss,如图中gan生成的绿色衣服形状的图片,他到绿衣本类的概率系数应该大,其次是到蓝衣的概率系数和到白衣的概率系数的类相对较小,概率系数之和为1。
如图7所示,基于本发明的另一方面,公开了一种基于标签优化的图像再识别系统,本实施例中,所述系统包括无监督学习模块、数据集融合模块、半监督学习模块和测试模块。
所述无监督学习模块用于对有标签的图片进行无监督的训练,生成没有标签的图片。该模块使用的环境是tensorflow0.12.1,python2.7.13,使用的网络为dcgan,将原始256×256的图片进行随机切割成128×128进行训练,使用的优化算法是adam算法,其中β1=0.5,β2=0.99,epoch=30,batchsize=64。训练结束,将训练出来的模型和原始数据集进行测试,生成没有标签的gan图片。
所述数据集融合模块用于将有标签的图片和没有标签的图片进行随机融合,确保数据分布的一致性。
所述半监督学习模块用于对随机融合的图片根据如本实施例所述的损失函数进行训练,得到测试模型。该模块使用的环境是matlab2016a,数据集是market1501,使用的网络框架是matconvnets,融合图片的尺寸为256×256随机切割为224×224,使用的优化算法为随机梯度下降(stochasticgradientdescent/sgd)和momentum=0.9,正则化方法为dropout=0.75,epoch=50,batchsize=32,学习率(learningrate)=0.002(40轮之后为0.0002)。
所述测试模块用于根据所述测试模型进行再识别,输出识别结果。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定,对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!