基于增强型深度卷积神经网络的行人再识别方法与流程
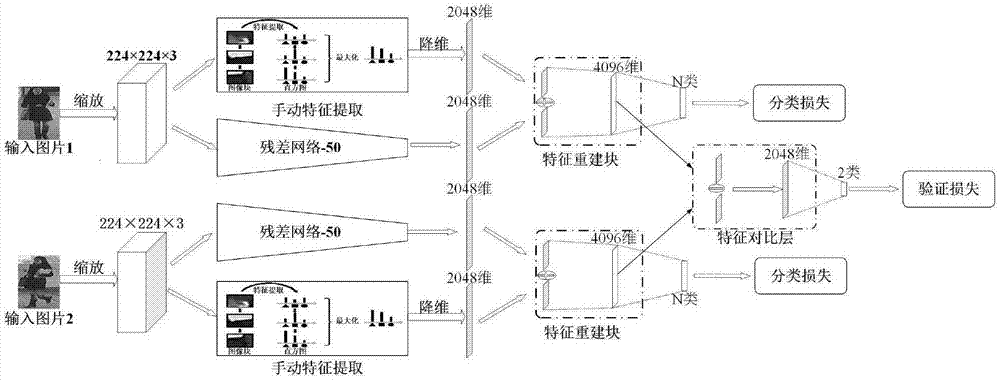
本发明属于计算机视觉行人再识别
技术领域:
,尤其是一种基于增强型深度卷积神经网络的行人再识别方法。
背景技术:
随着社会安全的需要以及科技的发展,机场、车站、商场和学校等公共场所布置了大量的摄像头网络。这些地理空间跨度大、监控区域不重叠的摄像头给后续处理系统提供了大量的视频数据。在这一背景下,依赖人工处理这些数据变得效率低下且不可行,必须依赖先进的机器算法进行智能处理,通过机器算法自动地分析这些视频数据不仅能提高效率还能显著提升监控的质量。行人再识别是监控数据处理中的一个重要研究方向,其主要目的是匹配非重叠摄像机视角中具有相同身份类别的行人图像,使计算机能够自动筛选出特定身份的行人,从而节省人力资源。同时,这是一项具有挑战性的任务,因为行人的视觉外观会因为行人姿势变化、摄像机视角不同、光照差异、遮挡和背景干扰而在不同的摄像机中有显著的变化。传统的行人再识别研究主要集中在如下两个方面:特征提取和度量学习。特征提取的目标是提取一种鲁棒且有辨识能力的特征,来对行人进行表示。目前已经有很多图像特征被用于解决行人再识别问题,例如elf特征、sdalf特征、gabor特征、lomo特征和colornames特征。通常,单个初级图像特征对图像的表示能力较弱,融合多个初级特征可以获得更好的性能。特征提取完成后,需要使用度量学习方法把提取出的行人特征映射到另一个空间,使得同一行人特征之间的距离更小,不同行人特征之间的距离更大。当前性能较好,使用范围较广的度量方法包括itml、kissme、prdc、lmnn和lfda等。近几年,卷积神经网络(cnn)已经被用于行人再识别。深度学习提供了一种强大且自适应的方法来处理计算机视觉问题,无需过多的人工干预就可以提取出性能优良的图像特征。反向传播算法动态地调整cnn中的参数,从而在单个网络中统一特征提取和度量匹配过程。由于深度学习方法的优异性能和端到端的处理方式,该方法在行人再识别研究领域得到了广泛的关注。借助卷积神经网络强大的学习能力,在提取出的图像特征性能上,深度学习方法较大幅度优于传统手工提取方法。一些专门设计用于克服交叉视角外观变化的手工提取的传统特征在光照变化或行人外观颜色变化严重情况下,有着其独特的优良性能。因此,如何结合这两种图像特征的优点,获取更适合实际应用场景条件的行人图像特征以提高行人再识别准确率是目前迫切需要解决的问题。技术实现要素:本发明的目的在于克服现有技术的不足,提出一种设计合理且识别准确的基于增强型深度卷积神经网络的行人再识别方法。本发明解决其技术问题是采取以下技术方案实现的:一种基于增强型深度卷积神经网络的行人再识别方法,包括以下步骤:步骤1、使用基础深度学习卷积神经网络模型提取行人图像的基础深度特征,同时使用传统手动特征提取方法提取行人图像的手动特征并降维;步骤2、应用特征重建模块将基础深度特征和手动特征融合成增强型深度特征;步骤3、在获取成对输入两张图像的增强型深度特征后,通过特征比较预测两张图像中行人是否为同一个人;步骤4、联合使用分类损失函数和验证损失函数对输入图像进行分类和异同验证,以最小化联合损失为目标来训练网络,使得网络生成更有判别力的行人图像特征。所述步骤1的具体实现方法包含以下步骤:⑴将行人图像缩放到统一尺寸224×224,以resnet50卷积神经网络架构作为预训练的基础卷积神经网络并去除其最后的全连接层;⑵将缩放后的行人图像输入到修改后的resnet50卷积神经网络架构中,图像经过一系列卷积、批量归一化、池化、relu操作后,最终输出2048维的基础深度特征;⑶使用传统特征提取方法提取缩放后的行人图像的手动特征(例如hsv颜色直方图,lbp特征和lomo特征等),将其降维至2048维。所述手动特征为sv颜色直方图、lbp特征和lomo特征。所述步骤2的具体实现方法包含以下步骤:⑴构造由一个级联器和一个全连接层组成的特征重建模块;⑵通过级联器将手动特征和基础深度特征在维度上级联起来,构成一个4096维的融合特征;⑶通过全连接层重建级联后的特征,获得4096维的增强型深度特征。所述步骤3的具体实现方法包含以下步骤:⑴同时提取两张图像的增强型深度特征;⑵对两张图像的增强型深度特征进行按位相减和平方操作,获得对比特征:⑶将对比特征通过一个全连接层,该全连接层的输出作为后续预测两张图像异同的输入。所述步骤4的具体实现方法包含以下步骤:⑴将每张行人图像的增强型深度特征进行分类,预测行人身份,并采用分类损失表示分类准确度;⑵将行人图像对的对比特征进行二分类,预测该图像对是否具有相同身份标签,采用验证损失表示预测精确度;⑶通过后向传播算法,以最小化分类损失和验证损失为目标来监督网络参数的更新,使得网络生成更有判别力的行人图像特征。本发明的优点和积极效果是:1、本发明设计合理,首先将手动特征引入到卷积神经网络模型之中,使得由此增强型卷积神经网络产生的特征同时具有手动特征的专有优点和普通深度特征的高性能优势;并且通过特征重建模块将手动特征和深度特征以一种学得的更高效的方式融合成增强型特征;最后通过联合使用分类损失和验证损失函数来帮助网络学得更适合得嵌入空间。本发明在公开数据集上进行了测试,并与目前主流得行人再识别算法进行了比较,结果表明提出的方法在性能上优于目前大多数行人再识别算法。2、本发明设计合理,充分利用了手动特征和深度特征之间的互补性,结合深度学习卷积神经网络对图像的强大的表示能力以及传统手动特征特有的优点,构建了用于行人再识别的增强型卷积神经网络,提出了联合使用分类损失和验证损失函数用于监督网络训练的策略,获得了良好的性能,有效地提高行人再识别准确率。附图说明图1为本发明提出的行人再识别算法网络框架图;图2为本发明提出的特征重建模块原理框图;图3为本发明提出的特征对比层原理框图。具体实施方式以下结合附图对本发明实施例做进一步详述。如图1所示,一种基于增强型深度卷积神经网络的行人再识别方法,首先基于深度学习resnet50卷积神经网络架构提取图像的基础深度特征,该基础深度特征的维度为2048维,使用具体的手动特征提取方法提取图像的手动特征,并采用pca降维方法降至与基础深度特征匹配的2048维;然后通过特征重建模块将获得的基础深度特征和手动特征级联重建成增强型深度特征,增强型深度特征的维度为4096维;考虑成对输入图像,在提取两张图像各自的增强型深度特征之后,通过特征对比层获得图像对的对比特征;最后联合使用分类损失和验证损失函数,以最小化两个损失之和为目标帮助网络学得更适合得嵌入空间,提取更加具有判别力的行人图像特征,得到最终行人再识别的结果。在本实施例中,一种基于增强型深度卷积神经网络的行人再识别方法,包括以下步骤:s1、使用基础的深度学习卷积神经网络模型提取行人图像的基础深度特征,同时使用传统手动特征提取方法提取行人图像的手动特征并降维。本实施例的步骤s1进一步包括:s1.1、首先将行人图像缩放到统一尺寸224×224,以残差网络resnet50作为预训练的基础卷积神经网络并去除其最后的全连接层;s1.2、将缩放后的行人图像输入到修改后的resnet50中,图像经过一系列卷积、批量归一化、池化、relu等操作后最终输出2048维的基础深度特征;s1.3、使用传统特征提取方法提取缩放后的行人图像的手动特征(例如hsv颜色直方图,lbp特征和lomo特征等),将其降维至2048维。s2、应用特征重建模块将基础深度特征和手动特征融合成增强型深度特征。如图2所示,本实施例的步骤s2进一步包括:s2.1、构造特征重建模块,该模块由一个级联器和一个全连接层组成,分别起融合和重建作用;s2.2、通过级联器将手动特征和基础深度特征在维度上级联起来,构成一个4096维的融合特征;s2.3、最后通过全连接层重建级联后的特征,获得4096维的增强型深度特征。其中,fconcat是级联得到的融合特征,和bfc1分别是全连接层的权重和偏置,freconstruct是重建得到的增强型深度特征。s3、考虑成对输入图像,在获取两张图像的增强型深度特征后,通过特征比较预测两张图像中行人是否为同一个人。如图3所示,本实施例的步骤s3进一步包括:s3.1、根据上述增强型深度特征的提取步骤,考虑成对输入图像,同时提取两张图像的增强型深度特征;s3.2、对两张图像的增强型深度特征进行按位相减和平方操作,获得对比特征;fs=(freconstruct1-freconstruct2)2其中,freconstruct1和freconstruct2分别是两张输入图片对应的增强型深度特征,fs是两张输入图片共同的对比特征。s3.3、将对比特征通过一个全连接层,该连接层的输出作为后续预测两张图像异同的输入。s4、联合使用分类损失函数和验证损失函数对输入图像对进行分类和异同验证,以最小化联合损失为目标来训练网络,使得网络生成更有判别力的行人图像特征。本实施例的步骤s4进一步包括:s4.1、将每张行人图像的增强型深度特征进行分类,预测行人身份,并采用分类损失表示分类准确度;s4.2、将行人图像对的对比特征进行二分类,预测该图像对是否具有相同身份标签,采用验证损失表示预测精确度;s4.3、通过后向传播算法,以最小化分类损失和验证损失为目标来监督网络参数的更新,使得网络生成更有判别力的行人图像特征。下面按照本发明的方法进行实验,说明本发明的实验效果。测试环境:matlab2014b;matconvnet框架;ubuntu14.04系统;nvidiagtx1070pgpu测试序列:所选数据集是用于行人再识别的图像数据集market-1501、cuhk03和cuhk01。其中market-1501数据集包含1501个行人的32668张图像,cuhk03数据集包含1467个行人的14097张图像,cuhk01数据集包含971个行人的3884张图像。测试指标:本发明使用rank-i准确率和绝对平均精度(map)作为评价指标,rank-i准确率表示给定查询图像,备选图像按与查询图像相似度由高到低排序后正确备选图像出现在前i位的预期几率;map同时考虑了精确度和召回率,与rank-i指标互补。对当今流行的不同算法计算这些指标数据然后进行结果对比,证明本发明在行人再识别领域得到较好的结果。测试结果如下:表1.本发明与其他算法在market-1501数据集下的性能比较表2.本发明与其他算法在cuhk03数据集下的性能比较方法rank-1rank-5rank-10rank-20maplomo+xqda46.2578.9088.5594.25-dns54.7084.7594.8095.20-gated-cnn68.188.194.6-58.84mrb-cnn63.6789.1594.6697.5-pdc78.2994.8397.1598.43-dictrw71.191.794.798.0-jlml80.696.998.799.2-本发明85.4197.8998.9699.8087.34表3.本发明与其他算法在cuhk01数据集下的性能比较方法rank-1rank-5rank-10rank-20ensembles53.476.484.490.5lomo+xqda63.2183.8990.0494.16mrb-cnn52.8878.0886.3092.63lomo+warca65.6485.3490.4895.04dns69.0986.8791.7795.39personnet71.190.195.098.1本发明73.3590.2894.3097.11通过以上对比数据可以看出,本发明在rank-i准确率和绝对平均精度(map)与现有算法相比有明显的提高。需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1