一种包含缺失数据的化工过程故障检测方法与流程
本发明属于化工生产过程控制领域,尤其涉及一种包含缺失数据的化工过程故障检测方法。
背景技术
在现代化工业中,随着机器学习、大数据的热度越来越高,而这些理论在工业控制方面已取得了一些进展,且分布式控制系统的广泛运用,使多元统计过程检测(mspm)成为了控制系统中不可或缺部分。对于一个现代化学工业过程,像温度、压力、流量等测量变量基于时间间隔采样,所以具有强烈的自相关性,于是需要进行动态过程建模。
为了提取测量变量的自相关性,传统的动态模型有采用扩展矩阵方法的动态主成分分析(dpca)。在这项创新性的工作之后,扩展矩阵就成为了许多动态模型的常用方法,比如动态ica、动态pls、动态fa等。
在这些传统的基于扩展矩阵的方法中,变量的自相关性可以被提取,但是它们仍然存在一些缺陷,即未将反映数据结构的互相关性建模。为了解决这个问题,提出了自回归动态隐变量模型(ardlv),自回归模型和隐变量模型来分别提取数据的动态和静态特性。
目前基于概率生成模型的迭代自回归动态隐变量模型仅仅提取了采样数据集的高斯信息,而未将数据中的非高斯信息进行建模。而且没考虑缺失数据的问题,检测效率低,稳定性差。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种包含缺失数据的动态过程故障检测方法。
针对现有技术存在的问题,本发明提出了一种基于独立成分分析与迭代自回归动态隐变量模型。首先对带有缺失值的数据集进行处理,得到缺失值的初值并获得完整训练数据集;然后利用独立成分分析(ica)对训练集进行建模以提取非高斯信息;最后将ica处理过后的残差基于迭代自回归动态隐变量模型建模,提取数据中的高斯信息。
本发明的目的是通过以下技术方案来实现的:
一种包含缺失数据的化工过程故障检测方法,包括以下步骤:
(1)收集待检测化工过程在正常运行时的数据,得到带有缺失值的原始数据集yo,yo∈rk×n,其中:k为采样总数,n为变量总数;
(2)对原始数据集yo进行白化预处理,得到白化预处理后的数据集
(3)对数据集
(4)基于得到的数据集yen,构建独立成分分析模型,得到独立成分矩阵s0,
(5)根据构建的独立成分分析模型,得到残差数据集
(6)基于残差数据集
(7)根据建立的迭代自回归动态隐变量模型,估计训练样本的隐变量的期望值t(tnormal),隐变量的方差var-1(t|x)(var-1(tnormal|xnormal))和模型预测误差e,构建相应的t2和spe统计量的控制限;
(8)收集新的化工生产过程中的样本数据作为测试样本,并进行归一化处理;
(9)根据步骤(4)构建的独立成分分析模型以及步骤(6)得到的迭代自回归动态隐变量模型,计算归一化后的测试样本的i2、t2、spe统计量,判断其是否超过对应的控制限,得到当前该化工生产过程的在线监测结果。
步骤(1)中,利用集散控制系统采集的正常生产过程运行下的数据作为建模使用的训练样本集,而该训练集通常存在一定量的缺失值,给定带有缺失值的原始数据集yo:
其中ym表示缺失值,采样总数为k,变量总数为n;
对于某一化工过程来讲,设定时间内,采样总数一般与采用频率有关;变量总数一般与化工过程的性质主要影响因素有关。常见的变量包括但不限于:温度、压力、底物浓度、产物浓度、重量、酸碱度等等中的一种或多种。
本发明针对的缺失值是随机、偶然产生,一行或者一列观测数据中,可以包含一个或者多个。
本发明中,步骤(2)中对原始数据集yo进行白化预处理时,按列处理,对于某一列,如果该列数据中包含缺失值,则移除(或者说是忽略)所有缺失值,对剩下的数据进行白化预处理。
本发明中,步骤(2)中,所述的“移除”所有缺失值,仅仅是在数据处理过程中移除,数据处理后的数据集
本发明中,步骤(2)中的白化处理,也可以称作归一化处理,即减去均值然后除以方差,最终使得数据集均值为零,方差为1。
本发明中,步骤(3)中利用独立成分分析算法对缺失值进行估计。
作为优选,对缺失值进行估计的步骤具体包括:
(3-1)基于数据集
(3-2)基于数据集yr建立独立成分分析模型,求得其对应的混合矩阵j,
yr=sjt(3)
其中,
步骤(3)中的r2和步骤(4)中的r1可以相同,也可以不同,为方便计算,作为优选,r1=r2。
(3-3)利用规则数据集yr以及求得的混合矩阵j,求得缺失值的得分st;
某行观测值假设为y=[y1…yj_1yjyj+1…yn],定义yj为缺失值(当然缺失值也可以是多个,这里以一个为例),为了估计采样数据的缺失值,利用规则数据集来估计缺失数据的得分,其公式如下:
(3-4)利用得分st以及混合矩阵j得到缺失值的估计值;
其中,
缺失样本的估计值可以用如下公式计算:
pj为j的第j行;
利用步骤(3-1)~(3-4)得到
骤(5),根据构建的独立成分分析模型,提取完整的训练数据集yen的非高斯信息。即求得训练数据集yen的残差数据集
同时,根据建立的独立成分分析模型,模型收敛后计算得到的独立成分矩阵s0获得训练样本独立成分inormal,构建i2统计量如下:
i2=inormalt×inormal(9)
将i2从小到大顺序排列,取i2统计量的控制限为第(0.95×k)处数值。
作为优选,步骤(6)中,对上述独立成分分析模型的残差数据集
作为优选,步骤(6)中,构建迭代自回归动态隐变量(r-ardlv)模型的步骤包括:
(6-1)初始化模型参数(a、c、q、r);
(6-2)基于当前的残差数据集
xk=azk_1+wk(10)
yk=cxk+vk(11)
其中:yk∈rb为k时刻的观测值,b为yk的维度,yk由残差数据集
为了后续计算简便,将上述动态隐变量模型等价交换,得到:
其中
(6-3)利用期望最大化算法对模型的隐变量进行估计,并计算似然函数,计算似然函数的更新值lognew与其原似然函数值logold的差异,判断似然函数是否收敛||lognew-logold||2<ε1:若是,跳转到步骤(6-4);若否,更新模型参数,跳转到步骤(6-2);ε1为似然函数收敛阈值;
(6-4)根据步骤(3)中记录的缺失值的位置,基于已构建的迭代自回归动态隐变量模型,对缺失值重新预测,更新残差数据集
(6-5)基于更新残差数据集
其中,步骤(6-3)中,在e步利用卡尔曼滤波由当前模型参数估计隐变量的后验概率;之后在m步中由似然函数分别针对各个参数求一阶偏导,令偏导为0,获取模型参数的更新值;最后,反复迭代e步和m步直至达到收敛条件。
在e步中由卡尔曼滤波计算:
其中
计算模型当前似然函数:
其中logp(x,y)为x,y的联合对数似然函数;μl为均值的初始值;vl为方差的初始值;zl为动态因子的初始值;constant是指常数项;
在m步中,通过最大化似然函数的方式来更新模型参数,其公式如下:
其中
步骤(6-4)中,根据步骤(3)中记录的缺失值的位置,利用卡尔曼滤波对相应缺失值进行估计并更新;计算模型参数的更新值θnew与其原模型参数θold的差异,判断模型参数是否收敛:||θnew-θold||2<ε2,若是,则模型训练完毕,下一步进行在线监测;若否,跳转到(6-2),其中ε2为模型参数收敛的阈值,具体操作如下:
在当前模型参数下,通过ardlv模型预测缺失值,卡尔曼滤波作为精确的一步预测,缺失值由下列公式计算得到:
其中
步骤(7)中,构建相应的t2和spe统计量监测统计限具体步骤为:
根据步骤(6)中模型收敛后计算得到的
利用隐变量的期望值tnormal,可构建t2统计量如下:
t2=tnormaltvar-1(tnormal|xnormal)tnormal(33)
t2统计量的控制限
其中,g为隐变量的个数。
同时,基于模型的预测误差,还可构建spe统计量以反应模型残差空间的变化:
进一步推导可得:
spe=etvar-1(e|xnormal)e(36)
spe统计量的控制限估计方法为:
gh=mean(spe)(37)
2g2h=var(spe)(38)
其中g、h为卡方分布参数,mean()为均值运算符号,var()为方差运算符号。
步骤(8)中,具体为:采用基于独立成分分析与迭代自回归动态隐变量模型对测试化工过程进行在线监测,计算测试样本的i2、t2、spe统计量,判断其是否超过统计限,得到当前该化工生产过程的在线监测结果,其具体过程如下:
当测试数据集ytest(测试集)被采集后,输入至独立成分分析模型:
构建i2统计量如下:
将独立成分分析模型处理后的残差
其中xk_test为当前时刻测试集的动态隐变量;
利用隐变量的期望值ttest构建
ttest2=ttesttvar-1(ttest|xtest)ttest(42)
其中var-1(ttest|xtest)为隐变量的方差。
同时,基于模型的高斯预测误差,还可构建spetest统计量以反映模型
高斯残差的信息:
其中,yk_test为当前时刻测试集的观测;
进一步推导可得:
spetest=etesttvar-1(etest|xtest)etest(44)
判断其是否超过统计限,得出化工生产过程的在线监测结果。
在实际的工业过程中,测量变量或多或少存在缺失值,本发明在处理动态过程时利用了ardlv的优点,提出了一种新颖的基于概率框架下的递归方法来估计缺失值和模型参数,因此即使采集到的数据集存在缺失值,仍能够对动态过程进行准确建模。
本发明描述了一种包含缺失数据的化工过程故障检测方法,以带有缺失值的数据集为建模样本,提取样本间的自相关、互相关信息,并在此模型的基础上建立了故障检测方法,以实现化工生产过程的过程监控。
本发明的有益效果是:通过将化工生产过程中采样的带有缺失值的数据矩阵,首先对缺失值进行初值填补,然后利用独立成分分析(ica)提取数据集的非高斯信息,将非高斯信息提取后的残差矩阵按照时间轴方向拓展为新的扩展数据矩阵,以提取性动态自相关特性建立迭代自回归动态隐变量模型,利用期望最大化算法与卡尔曼滤波,较为准确的估计模型参数及缺失值,获得数据中高斯信息。相比目前其它的化工过程监测方法,本发明不仅可以处理带有缺失值的采样数据集,并且能完整的提取数据中的非高斯与高斯信息,极大的提高化工生产过程故障检测的效果,降低了故障的误报率与漏报率,同时很大程度上改善了模型的预测能力,提升了基于此发明的故障检测方法的科学性和有效性。
附图说明
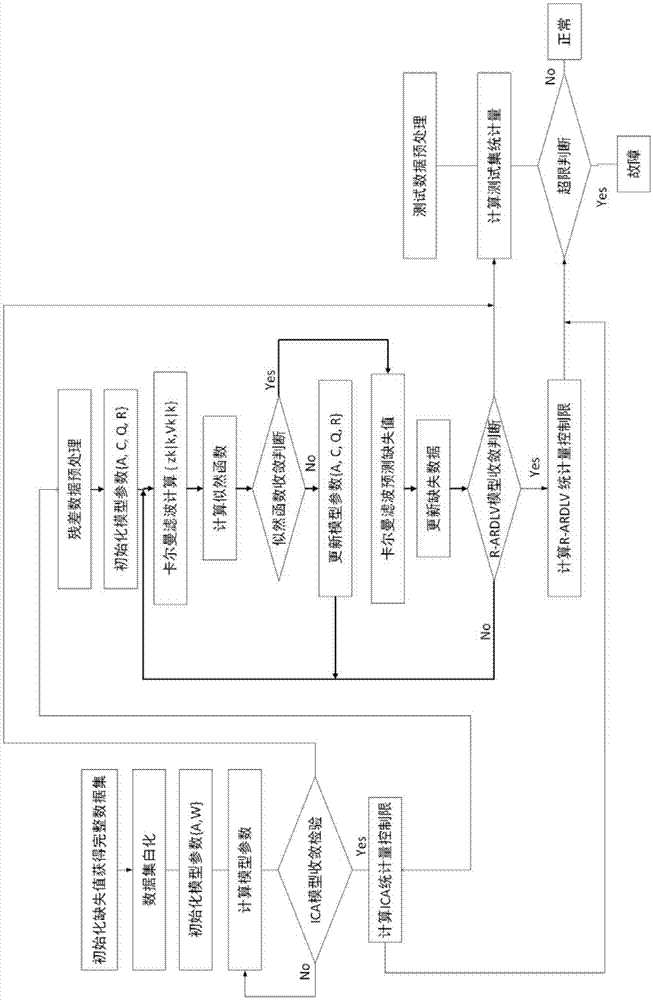
图1为本发明包含缺失数据的化工过程故障检测方法流程图。
具体实施方式
参考图1,本方法是一种包含缺失数据的化工过程故障检测方法,该方法针对化工过程的故障检测问题,首先利用集散控制系统收集正常工况下带有缺失值的数据,建立独立成分分析与迭代自回归动态隐变量模型,即:独立成分分析-递归自回归动态隐变量模型(或者独立成分分析-迭代自回归动态隐变量模型)。该模型结构由期望最大化算法估计得到。在此基础上,基于该模型构建了三个监测统计量i2、t2、spe及其对应的统计限
本发明一种包含缺失数据的化工过程故障检测方法,包括以下步骤:第一步:利用集散控制系统收集化工生产过程正常运行的带有缺失值(造成数据缺失的原因很多,多是偶然因素造成或者设备故障造成,所以,本发明中一个时刻采集的数据中(一行),缺失值可以是一个或者多个;同一变量采集的数据中(一列),缺失值也可以是一个或者多个)的数据,组成训练样本数据集进行建模,假定采集到带有一定量缺失数据的正常样本,定义为原始数据集yo:
其中ym表示缺失值,采样总数为k,变量总数为n;
第二步:对上述yo进行白化预处理:
将上述数据集yo按列(即变量)处理,假定某列的观测值为yv=[y1…yj-1ymyj+1…yk]t,则将该列所含有缺失值ym移除,得到
第三步:对第二步得到的白化预处理后的数据集中存在的缺失值进行估计并填补:
去掉所有带有缺失值的所在时刻采集的数据(即去掉所有带有缺失值的行),得到规则数据集:
其中m为不存在缺失数据的行数。
基于数据集yr建立独立成分分析模型:
yr=sjt(3)
其中,
求取模型参数j、s、w。
某行观测值y=[y1…yj_1yjyj+1…yn],定义yj为缺失值,即yj=ym,为了估计采样数据的缺失值,利用规则数据集来估计缺失数据的得分st,其公式如下:
其中,
缺失样本的估计值可以用如下公式计算:
pj为j的第j行;
用上式计算所得yj填补yo中对应的缺失值,同理,用该方法估计每一存在缺失值的行,得到完整的训练数据集yen,其中yen∈rk×n,同时记录下缺失值位置;
第四步:利用独立成分分析(ica)算法,提取完整的训练数据集yen的非高斯信息。
对完整的训练数据集yen进行中心化处理,使其均值为0,得到y0∈rk×n,选择需要估计的独立分量的个数r1;
然后建立独立成分分析模型,得到模型的独立成分矩阵
第五步:根据第四步建立的独立成分分析模型,模型收敛后计算得到的独立成分矩阵s0获得训练样本独立成分inormal,构建i2统计量如下:
i2=inormalt×inormal(8)
将i2从小到大顺序排列,取i2统计量的控制限为第(0.95×k)处数值。
同时,计算模型的预测误差
第六步:对上述独立成分分析模型的残差数据集
第七步:对上述非高斯模型的残差数据集
(1)初始化模型参数;
(2)基于当前的残差数据集
xk=azk-1+wk(10)
yk=cxk+vk(11)
其中:yk∈rb为k时刻的观测值,b为yk的维度,yk由残差数据集
为了后续计算简便,将上述动态隐变量模型等价交换,得到:
其中
第八步:利用期望最大化(em)算法对动态隐变量进行估计并计算似然函数,计算似然函数的更新值lognew与其原似然函数值logold的差异,判断似然函数是否收敛||lognew-logold||2<ε1,若是,转到第九步;若否,更新模型参数并跳转到第八步,其中ε1为似然函数收敛的阈值:
其中,期望最大化(em)算法来更新模型参数,在e步利用卡尔曼滤波由当前模型参数估计隐变量的后验概率;之后在m步中由似然函数分别针对各个参数求一阶偏导,令偏导为0,获取模型参数的更新值;最后,反复迭代e步和m步直至达到收敛条件。
在e步中由卡尔曼滤波计算:
其中
计算模型当前似然函数:
其中logp(x,y)为x,y的联合对数似然函数;μl为均值的初始值;vl为方差的初始值;zl为动态因子的初始值;constant是指常数项;
在m步中,通过最大化似然函数的方式来更新模型参数,其公式如下:
其中
第九步:根据第二步记录的缺失值的位置,利用卡尔曼滤波对相应缺失值进行估计并更新;计算模型参数的更新值θnew与其原模型参数θold的差异,判断模型参数是否收敛:||θnew-θold||2<ε2,若是,则模型训练完毕,下一步进行在线监测;若否,跳转到第七步,其中ε2为模型参数收敛的阈值,具体操作如下:
在当前模型参数下,通过ardlv模型预测缺失值,卡尔曼滤波作为精确的一步预测,缺失值由下列公式计算得到:
其中
第十步:根据建立的迭代自回归动态隐变量模型,估计训练样本的隐变量的期望值t,隐变量的方差var-1(t|x)和模型预测误差e,构建相应的t2和spe统计量监测统计限:
根据第八步模型收敛后计算得到的
利用隐变量的期望值tnormal,可构建t2统计量如下:
t2=tnormaltvar-1(tnormal|xnormal)tnormal(33)
t2统计量的控制限由χ2分布估计如下:
其中,g为隐变量的个数。
同时,基于模型的预测误差,还可构建spe统计量以反应模型残差空间的变化:
进一步推导可得
spe=etvar-1(e|xnormal)e(36)
spe统计量的控制限估计方法为:
gh=mean(spe)(37)
2g2h=var(spe)(38)
其中g、h为卡方分布参数,mean()为均值运算符号,var()为方差运算符号。
第十一步:收集新的化工生产过程中的样本数据作为测试数据集,并进行预处理和归一化;
第十二步:采用基于独立成分分析与迭代自回归动态隐变量模型对测试化工过程进行在线监测,计算测试样本的i2、t2、spe统计量,判断其是否超过统计限,得到当前该化工生产过程的在线监测结果,其具体过程如下:
当测试数据集ytest被采集后,输入至独立成分分析模型:
构建i2统计量如下:
将独立成分分析模型处理后的残差
其中xk_test为当前时刻测试集的动态隐变量;
利用隐变量的期望值ttest构建
ttest2=ttesttvar-1(ttest|xtest)ttest(42)
其中var-1(ttest|xtest)为隐变量的方差。
同时,基于模型的高斯预测误差,还可构建spetest统计量以反映模型
高斯残差的信息:
其中,yk_test为为当前时刻测试集的观测;
进一步推导可得:
spetest=etesttvar-1(etest|xtest)etest(44)
判断其是否超过统计限,得出化工生产过程的在线监测结果。
- 还没有人留言评论。精彩留言会获得点赞!