一种基于差分隐私保护的谱聚类方法与流程
本发明属于隐私保护技术领域,提供了一种基于差分隐私保护的谱聚类方法。
背景技术:
近年来,随着互联网与信息技术的蓬勃发展,海量数据的产生可以为研究者们提供许多有效的信息资源,对这些海量数据进行挖掘分析可以得到非常有价值的信息,其中聚类分析是有效手段之一。但是在聚类的过程中也存在着隐私泄露的风险。
现如今关于聚类分析在隐私保护方面的应用越来越多,而且聚类作为数据挖掘和机器学习的主要技术之一被广大学者所研究,传统的聚类保护算法如k-means、dbscan、k-medoids动态聚类,传统的聚类算法存在隐私泄露及聚类效果不佳的问题。
技术实现要素:
本发明实施例提供了一种基于差分隐私保护的谱聚类方法,旨在解决传统的聚类算法存在隐私泄露及聚类效果不佳的问题。
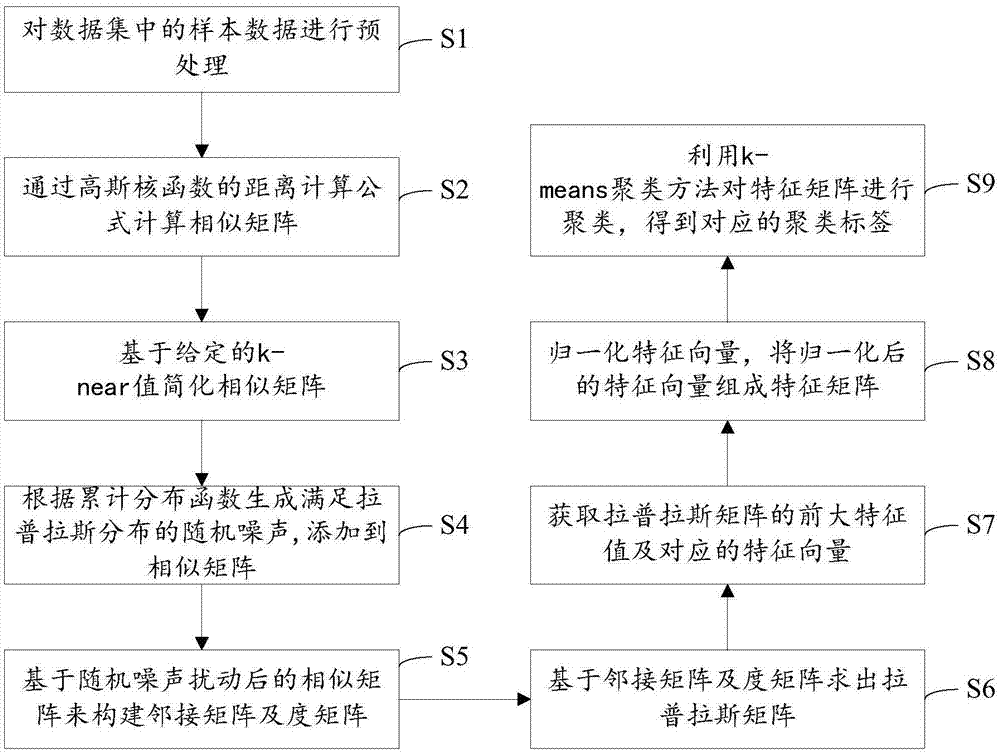
本发明是这样实现的,一种基于差分隐私保护的谱聚类方法,该方法包括如下步骤:
s1、对数据集中的样本数据进行预处理,预处理是指将各属性下的属性值除以所述属性下的最大属性值;
s2、通过高斯核函数的距离计算公式计算相似矩阵;
s3、基于给定的k-near值简化相似矩阵,即将相似矩阵中小于k-near值的元素值设为零;
s4、根据累计分布函数生成满足拉普拉斯分布的随机噪声,添加到相似矩阵中非零元素;
s5、基于随机噪声扰动后的相似矩阵来构建邻接矩阵s及度矩阵d;
s6、基于邻接矩阵s及度矩阵d求出拉普拉斯矩阵l;
s7、获取拉普拉斯矩阵的前m大特征值及对应的特征向量;
s8、归一化特征向量,将归一化后的特征向量组成特征矩阵;
s9、利用k-means聚类方法对特征矩阵进行聚类,得到对应的聚类标签label。
进一步的,所述k-means聚类方法中的k值为标准聚类标签的聚类种类值。
进一步的,在步骤s9之后还包括:
s10、评估步骤s9中所获得的聚类标签label的精准度accuracy。
谱聚类的算法对于数据的实用性更强,对于凸型的空间数据和高纬度的数据不容易陷入局部最优解,因此利用谱聚类算法先计算样本数据间的样本相似性作为数据点之间的权重值,再利用差分隐私算法,对权重值添加拉普拉斯分布的随机噪声,来干扰权重值达到隐私保护的目的,干扰后的数据不仅可以实现隐私保护还保证了聚类的有效性。
附图说明
图1为本发明实施例提供的基于数据流的敏感数据挖掘方法流程图;
图2为本发明实施例提供的参数δ取值对聚类结果的影响图;
图3为本发明实施例提供的数据集liver运行的accuracy结果比较图;
图4为本发明实施例提供的数据集pima运行的accuracy结果比较图;
图5为本发明实施例提供的数据集sonar运行的accuracy结果比较图;
图6本发明实施例提供的数据集balance运行的accuracy结果比较图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供的基于差分隐私保护的谱聚类算法,是基于差分隐私模型,利用累计分布函数生成满足拉普拉斯分布的随机噪声,将该噪声添加到经过谱聚类算法计算的样本相似度的函数中,干扰样本个体之间的权重值,实现样本个体间的信息隐藏达到隐私保护的目的。
图1为本发明实施例提供的基于差分隐私保护的谱聚类方法流程图,该方法包括如下步骤:
s1、对数据集中的样本数据进行预处理,预处理是指将各属性下的属性值除以该属性下的最大属性值;
数据集中的样本数据均具多重属性,样本数据中至少包括如下信息:各属性下的属性值。
s2、通过高斯核函数的距离计算公式计算相似矩阵;
d(si,sj)表示样本si到样本sj的欧式距离,wij为样本si与样本sj间的权重值,即相似矩阵中i行第j列的元素,其中,i=1,2,…,r,j=1,2,…,r,且i≠j,r为数据集中的样本数据个数,δ为相似函数的参数,其取值为δ=0.9,其取值是基于聚类效果设定的。
s3、基于给定的k-near值简化相似矩阵,即将相似矩阵中小于k-near值的元素值设为零,保留大于等于k-near值的元素值;
在本发明实施例中,两样本间的权重值可以理解为两样本间的亲密度或者是相似性,权重值越大,两样本间越亲密,相似性越高;权重值越小,两样本间相似性越低,需要保密这种亲密关系不被泄漏,只需对相似矩阵中的相对大的权重值进行保密,为了简化计算过程,减少计算量,将相似矩阵中的相对小的权重值置零,基于k-near值来进行上述简化过程,将相似矩阵中小于k-near值的元素值设为零。
s4、根据累计分布函数生成满足拉普拉斯分布的随机噪声,添加到相似矩阵中非零元素;
为了确保这种亲密关系不被泄漏,因此,通过拉普拉斯噪声来隐藏潜在的数据信息,即对相似矩阵中的非零元素添加拉普拉斯噪声,拉普拉斯噪声机制主要针对数值型数据的数据值进行扰动来达到隐私安全保护,累计分布函数的表述为:d(x)=(1/2)(1+sgn(x)×(1-exp(x/b)))。
s5、基于随机噪声扰动后的相似矩阵来构建邻接矩阵s及度矩阵d;
基于相似矩阵来构建连接矩阵及度矩阵的方法均是现有的,在此不做详细说明。
s6、基于邻接矩阵s及度矩阵d求出拉普拉斯矩阵l,拉普拉斯矩阵的计算公式为:l=d1/2sd1/2。
s7、获取拉普拉斯矩阵的前m大特征值及对应的特征向量;
计算出拉普拉斯矩阵的特征值,通过matlab的排序算法将特征值从大到小排序,取前m个特征值λ1、λ2、…、λm,并计算出及这m个特征值对应的特征向量为(λ11、λ12、…、λ1m)、(λ21、λ22、…、λ2m)、…、(λm1、λm2、…、λmm),m的取值一般为2~3,也就是将数据进行降维处理,通常降至二维或三维。
s8、归一化特征向量,将归一化后的特征向量组成特征矩阵,将数据点映射到基于一个或多个确定的降维空间去;
以特征向量(λ11、λ12、…、λ1m)为例说明归一化处理,其归一化后的特征向量为:
s9、利用k-means聚类方法对特征矩阵进行聚类,得到对应的聚类标签label;
将特征矩阵的每一行看做一个数据点,采用k-means聚类方法将聚为k类,该k值可以自己设定,或者是通过标准聚类标签的聚类来计算聚类种类k值,通过标准聚类标签的聚类获取的k值,聚类结果会更精准,标准聚类标签为样本数据本身携带的聚类标签,例如,来自于uciknowledgediscoveryarchivedatabase的样本数据,每个样本数据中都携带有与之对应的标准聚类标签label。
谱聚类的算法对于数据的实用性更强,对于凸型的空间数据和高纬度的数据不容易陷入局部最优解,因此利用谱聚类算法先计算样本数据间的样本相似性作为数据点之间的权重值,再利用差分隐私算法,对权重值添加拉普拉斯分布的随机噪声,来干扰权重值达到隐私保护的目的,干扰后的数据不仅可以实现隐私保护还保证了聚类的有效性。
在步骤s9之后还包括:
s10、评估步骤s9中所获得的聚类标签label的精准度accuracy,
在本发明实施例中,精准度
以下针对基于差分隐私保护的谱聚方法的效果进行以下实验:
本文所采用的数据集均来自于uciknowledgediscoveryarchivedatabase(http://archive.ics.uci.edu/)数据集中的liver、pima、sonar、balance四个数据集进行实验,如表1所示:
表1为uci数据集
本实验首先对数据集进行归一化处理,将各个属性的值控制在[0,1]之间。然后调整相似性函数σ的值如0.1,0.5,0.9,1,2,4,6,8,10,12来确定最佳的聚类状态。并用聚类的评价指标accuracy作为聚类结果的输出,从图2可以看出,聚类效果比较好的σ维持在0.9~2之间。
实验配置环境
本发明主要采用了matlab软件编程来实现文中所提到的算法,实验的软硬件环境如下:
硬件环境配置:inteli5处理器,4g内存;
软件环境配置:matlabr2013b编程软件,操作系统windows764位旗舰版
实验结果
本文首先对四个数据集liver、pima、sonar、balance进行预处理,使其每个属性值都在[0,1]之间,对四个数据集分别进行谱聚类算法和差分隐私谱聚类算法实验,因为实验的偶然性,所以选择进行20次实验,对比20的实验结果来计算平均值,图3至图6分别是四个数据集的扰动前后的情况:
由图3可知,对于数据集liver,运用差分隐私的谱聚类算法和只用谱聚类算法在聚类效果上是差不多的,所有在保证隐私安全的前提下,保证了数据集liver的聚类有效性。
由图4可知,对于数据集pima,accuracy的值平均分布在0.6~0.7,分布较为稳定,而扰动前后的对比,虽然总体上是加扰动前聚类效果要好,但是此条件下并不能满足隐私保护,所以扰动后的算法任然具有可用性。
由图5可知,对于数据集sonar,其运行的总体情况是加入拉普拉斯噪声的要比不加噪声的好,accuracy的值平均分布在0.5~0.6,而干扰后的算法在隐私保护的前提下可以达到聚类效果的最好状态。
由图6可知,对于数据集balance的运行结果总体都比未扰动的效果更好,其accuracy的平均值稳定在0.4左右,而加入扰动后的值平均在0.5左右,提高了聚类的有效性。同时,因经过扰动后的权重随着随机点的选取,可能会出现样本点更好的聚类在样本中心点所以出现扰动后结果优于扰动前。
对比图3、图4、图5、图6,对于不同的四个数据集,在相同的谱聚类算法和差分隐私谱聚类算法中,accuracy的运行结果总体比没有扰动的数值要提高一些,这也说明了本文提出的算法在实现隐私保护方面有了显著的成效,并且得到了很好的聚类有效性。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!