一种基于空间坐标系的多摄像头数据融合方法与流程
本发明涉及视频图像处理领域,具体说是一种在空间坐标系下对连续多监控场景下的多摄像头采集到的监控数据融合方法。
背景技术:
近年来,随着用于安防的网络摄像头的普及,智能视频监控技术已经迅速成为当下的一个研究热点。视频数据是对监控场景中发生的事的记录,其中蕴含着各类信息。鉴于在大多数视频监控数据中背景是固定不变的,所以对于视频监控数据,使用者真正感兴趣的是其中出现的目标以及目标的运行轨迹。
目前,视频监控数据大多是根据摄像头的编号对各摄像头采集到的数据分别进行存储,然后再通过智能视频监控技术进行分析处理。而目标检测、目标识别和目标跟踪是智能视频监控分析处理的三个重要环节。其中,目标跟踪是用来确定我们感兴趣的目标在视频序列中连续的位置,目标跟踪技术是计算机视觉领域的一个基础技术,具有广泛的应用价值。
传统的目标跟踪技术都是基于二维图像空间对目标的历史运动轨迹进行记录。这种方法容易实现,且可以记录目标在当前场景下的运动轨迹。但是这种方法不足在于:1.传统的目标跟踪技术局限在二维图像空间,不能反映目标在空间中的位置变化信息;2.当目标发生跨场景的移动时,传统的目标跟踪技术需要将当前场景中的目标与之后多个场景中的目标进行比对,并以此判断目标的移动方向,不能很好的对目标进行多场景的持续跟踪。
技术实现要素:
本发明的目的是:通过建立二维图像坐标系与真实三维空间坐标系之间的映射关系,将对多个摄像头获取到的视频帧进行目标检测与目标识别后的得到的目标在二维图像坐标系下的坐标信息映射到空间坐标系中,并在此基础上提供一种对目标进行跨场景跟踪方法,实现对多摄像头采集到的视频监控数据进行融合。
该方法在分析摄像头成像原理和摄像头标定技术的基础上,建立二维图像坐标系与真实三维空间坐标系之间的坐标映射方程;然后将通过目标检测与目标识别方法获取到的目标在二维图像坐标系下的坐标,转换为目标在三维空间坐标系下的坐标;最后基于目标在三维空间坐标系下的坐标进行目标跟踪,实现多摄像头数据融合。这种方法可以还原目标在真实空间中的位置变化信息,同时还可以更好地对目标进行跨场景跟踪,实现对多个摄像头采集到的数据的融合,为高层次的目标行为分析提供更多的信息。
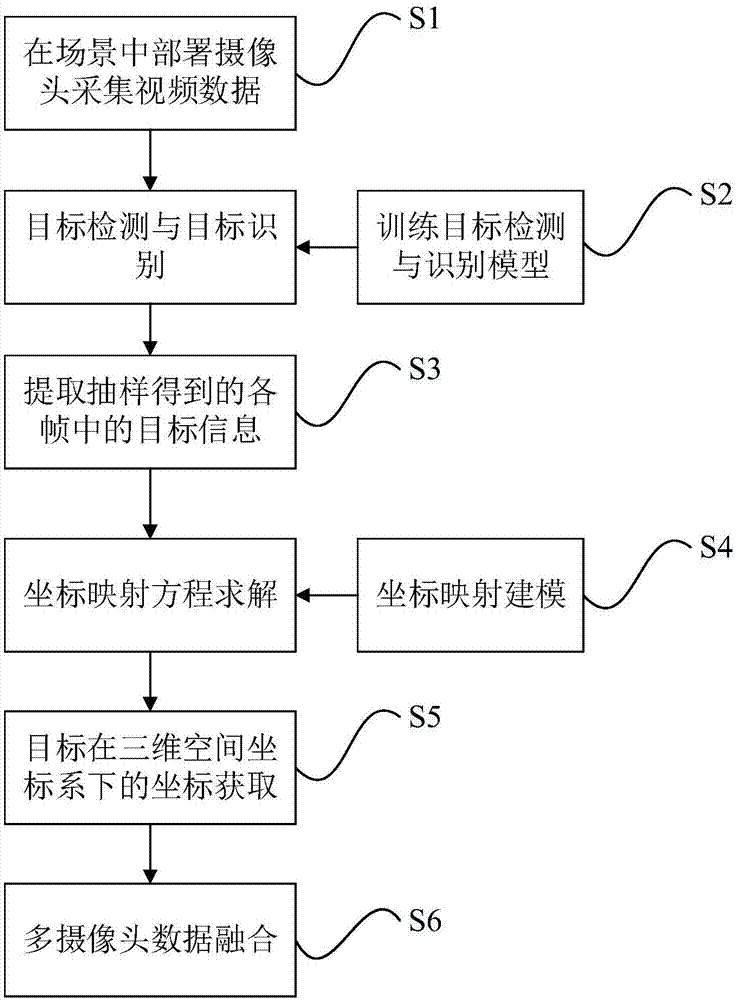
为了实现上述目的,本发明提供了一种基于空间坐标系的多摄像头数据融合方法,该方法包括以下步骤:
在需要被监控的场景中部署各个摄像头;针对需要提取的目标构建训练数据集,完成目标检测与识别模型的训练;基于目标检测与识别模型提取各摄像头采集到的视频数据中的目标的类别和目标在二维图像坐标系统下的位置信息,建立二维图像坐标系与三维空间坐标系之间的坐标映射关系;对于连续多个场景中的摄像头采集到的视频流数据,进行目标检测与目标识别处理,提取各帧中出现的目标的类别信息以及目标在二维图像坐标系下的位置信息;基于坐标映射关系,将目标在二维图像坐标系下的位置信息映射为目标在三维空间坐标系下的坐标;并根据当前时间节点中的各目标与上一时间节点中各目标之间的距离信息,发现相邻时间节点中的相同目标,并将其连接起来,得到目标在三维空间坐标系下的运动轨迹数据。
优先地,建立二维图像坐标系与三维空间坐标系之间的坐标映射关系步骤,具体包括:
对于各摄像头监控的场景中,选择50个均匀分布的二维图像坐标系中的像素坐标,记为{(u1,v1),(u2,v2),……,(u50,v50)},同时获取这50个像素坐标在真实三维空间坐标系中对应的空间坐标,记为{(x1,y1,z1),(x2,y2,z2),……,(x3,y3,z3)},各点在真实三维空间坐标系下的坐标可以通过手工测量或者是利用gps定位的方法获取;
在摄像头成像的过程中,二维图像坐标点(u,v)与对应的三维空间坐标点(x,y,z)之间满足:
考虑到我们关注的目标都在地平面上,即z=0,因此上式可转化为:
其中,参数(w1,w2,b1,w3,w4,b2)为常数,通过最小二乘法,找到使得所有拟合结果与实际数据的偏差的平方和
优选地,根据当前时间节点中的各目标与上一时间节点中各目标之间的距离信息,发现相邻时间节点中的相同目标,并将其连接起来,得到目标在三维空间坐标系下的运动轨迹数据步骤,具体包括:
读取各摄像头监控场景下目标在三维空间坐标系下的坐标数据,并按坐标数据出现时间的先后排序;
计算第(i+1)个时间节点中各目标在三维空间坐标系下的坐标((i+1)1~(i+1)a)与第i个时间节点中各目标在三维空间坐标系下的坐标(i1~ib)之间的距离,记为dxy(其中x∈[1,a],y∈[1,b]);
当x为定值时,暂且认为使得dxy最小的y与x是同一目标在相邻两个时间节点中的编号;
若dxy小于给定阈值t,则确定x,y为同一目标在相邻两个时间节点中的编号,否则x为在第(i+1)个时间节点第一次出现在监控场景中的新目标的编号;
将相邻两个时间节点中的相同目标在三维空间坐标系下的坐标依次连接起来,同时记录每一条坐标连线所属的目标的类别以及起止时间节点,得到各摄像头监控的场景下目标在三维空间坐标系下的运动轨迹数据。
优选地,完成目标检测与识别模型的训练步骤,具体包括:
步骤201:针对每种需要提取的目标,采集500-1000张包含该目标的图片,对于这些图片中应尽可能包括从不同角度拍摄的目标;
步骤202:通过手动标记的方法,为步骤201中采集到的图片添加类别标签;
步骤203:通过手动标记的方法,为步骤201中采集到的图片添加目标在二维图像坐标系下的位置信息;
步骤204:将用于训练的图片数据集随机打乱构建训练数据集,并导入基于caffe的深度学习框架faster-rcnn;
步骤205:根据训练集的类别、类别数量修改训练参数,并设置迭代次数;
步骤206:训练目标检测与识别模型。
优选地,基于目标检测与识别模型提取各摄像头采集到的视频数据中的目标的类别和目标在二维图像坐标系统下的位置信息步骤,具体包括:
对于连续多个场景中的摄像头采集到的视频流数据,利用目标检测与识别模型进行目标检测与目标识别处理,每隔1秒提取各摄像头采集到的当前帧中的目标的类别信息和目标在二维图像坐标系下的位置信息;同时,获取目标所属摄像头的id以及采集时间,与该目标的位置信息构成目标的信息。
本发明针对监控场景的实际需要,利用深度学习框架训练目标检测与目标识别模型,可以从连续多个监控场景中的摄像头采集到的图像中同时提取出多个不同目标的类别信息和目标在二维图像坐标系下的位置信息;通过最小二乘法,建立二维图像坐标系与三维空间坐标系之间的坐标映射关系,可以将检测到的各个目标在二维图像坐标系下的位置信息信息转化为该目标三维空间坐标系下的坐标;通过计算相邻时间节点下各目标之间的距离信息,获取目标在在三维空间坐标系下的运动轨迹。与传统目标跟踪技术相比,本方法可以将各摄像头采集到的分散的监控数据进行融合,可以同时获取多个目标在连续多个场景下的空间位置变化信息;通过坐标映射方程可以完成二维像素坐标向三维空间坐标的转换,实现了对目标在三维空间下的跟踪;同时,本方法所存储目标的类别数据和轨迹数据,相比于传统目标跟踪技术所采用的存储连续图像数据,大大减少了存储的数据量,提高了计算效率。
附图说明
图1是本发明实施例提供的一种基于空间坐标系的多摄像头数据融合方法的流程示意图;
图2是目标检测与识别模型训练过程的流程图。
具体实施方式
本发明的一种基于空间坐标系的多摄像头数据融合方法,结合附图作进一步详细说明:
图1是本发明实施例提供的一种基于空间坐标系的多摄像头数据融合方法的流程示意图。如图1所示,基于空间坐标系的多摄像头数据融合方法,包括步骤s1-s6:
s1、在需要被监控的场景中部署多个摄像头,其中相邻摄像头覆盖的场景的边缘应尽可能靠近,同时相邻摄像头覆盖的场景边缘应尽可能少重叠。
s2、训练目标检测与识别模型,模型训练流程图如附图2所示,具体实施时步骤如下:
步骤201:每个类别选择500-1000张至少包含一个该类别目标的图片。对于图片的选取,应尽可能地选择不同角度下拍摄的图片以及包含不同姿态的目标的图片,构成图片数据集。
步骤202:通过手动标记的方法,为步骤201中采集到的图片添加类别标签,类别标签就是图片中的目标所属的类别。
步骤203:通过手动标记的方法,为步骤201中采集到的图片添加目标在二维图像坐标系下的位置信息,目标在二维图像坐标系下的位置信息就是目标所在的矩形包围框的坐标信息(x1,y1,x2,y2),其中(x1,y1)是目标所在的矩形包围框的左上角坐标,(x2,y2)是目标所在的矩形包围框的右下角坐标。
步骤204:将用于训练的图片数据集随机打乱构建训练数据集,按照7:2:1的比例分为训练集、测试集和验证集,并导入深度学习框架faster-rcnn。
步骤205:根据训练集中目标的类别以及目标类别的数量修改训练参数,并设置迭代次数,包括rpn第1阶段,fastrcnn第1阶段,rpn第2阶段,fastrcnn第2阶段这四个阶段的迭代次数。
步骤206:训练目标检测与识别模型,在完成了设置的迭代次数后,将会得到后缀名为.caffemodel的目标检测与识别模型文件。
s3、对于连续多个场景中的摄像头采集到的视频流数据,每隔1秒对个摄像头采集到的当前帧进行目标检测与目标识别处理。提取当前帧中目标的类别信息和目标在二维图像坐标系下的二维像素坐标位置信息(ui,vi),同时还需要存储目标所属摄像头的id以及目标出现的时间信息,这些信息共同构成目标的信息。
s4、二维坐标和三维坐标之间的坐标映射方程计算方法具体实施步骤如下:在摄像头成像的过程中,二维图像坐标点(u,v)与对应的三维空间坐标点(x,y,z)之间满足以下关系:
考虑到我们关注的目标都在地平面上,即z=0,因此公式(1)可转化为:
其中,
步骤401:对于各摄像头监控的场景,选择50个均匀分布的二维图像坐标系中的像素坐标,记为{(u1,v1),(u2,v2),……,(u50,v50)},同时通过手工测量或者是利用gps定位的方法采集这50个像素坐标在真实三维空间坐标系中对应的空间坐标,记为{(x1,y1,z1),(x2,y2,z2),……,(x3,y3,z3)}。
步骤402:通过最小二乘法,选择合适的参数(w1,w2,b1,w3,w4,b2),保证所有拟合结果与实际数据的偏差的平方和mx,my最小,mx,my可以表示为:
求使mx,my可以取到极小值时刻参数(w1,w2,b1,w3,w4,b2)的值,即求解方程组:
将参数(w1,w2,b1,w3,w4,b2)带入公式(2)中,得到摄像头监控的场景下二维图像坐标系与三维空间坐标系之间的映射方程。
s5、将步骤s3中提取出的各个目标在二维图像坐标系下的二维像素坐标位置信息(ui,vi)输入步骤4中计算得到的二维图像坐标系与三维空间坐标系之间的映射方程:
从而获取各监控场景下检测到的目标在三维空间坐标系下的坐标(xi,yi,zi)。
步骤s6、多摄像头数据融合,基于各监控场景下的目标在三维空间坐标系下的坐标,提取目标在在三维空间坐标系下的轨迹数据,具体步骤如下:
步骤601:按出现时间的先后顺序,依次读取相邻两个时间节点中各监控场景下目标在三维空间坐标系下的坐标。
步骤602:计算第(i+1)个时间节点中各目标在三维空间坐标系下的坐标(记为(i+1)1~(i+1)a)与第i个时间节点中各目标在三维空间坐标系下的坐标(记为i1~ib)之间的距离,记为dxy(其中x∈[1,a],y∈[1,b])。
步骤603:当x为定值时,选择使得dxy最小的y,并暂且认为x,y为同一目标在相邻两个时间节点中的编号。
步骤604:若dxy小于给定阈值t,则确定x,y为同一目标在相邻两个时间节点中的编号,否则x为在第(i+1)个时间节点第一次出现在监控场景中的新目标的编号。
步骤605:将步骤604中判断得到的相邻两个时间节点中的相同目标在三维空间坐标系下的坐标依次连接起来,并为每一条坐标连线添加该连线所属的目标的类别以及起止时间节点,这些数据共同构成各摄像头监控的场景下目标在三维空间坐标系下的运动轨迹数据。
本发明实施例能还原目标在真实空间中的位置变化信息,同时还可以更好地对目标进行跨场景跟踪,实现对多个摄像头采集到的目标信息进行融合,为高层次的目标行为分析提供更多的信息。
尽管已经示出并描述了本发明的特殊实施例,然而在不背离本发明的示例性实施例及其更宽广方面的前提下,本领域技术人员显然可以基于此处的教学做出变化和修改。因此,所附的权利要求意在将所有这类不背离本发明的示例性实施例的真实精神和范围的变化和更改包含在其范围之内。
- 还没有人留言评论。精彩留言会获得点赞!