一种利用计算机视觉与图像识别的物品统计算法的制作方法
本发明涉及触摸屏技术领域,具体是一种利用计算机视觉与图像识别的物品统计算法。
背景技术:
本发明是为了解决商品在三维空间中种类和数量的统计问题及精确位置坐标的定位问题,提出的一套利用深度学习、三维重建以及多视角交叉验证,以统计货架中商品种类和数量的算法。
技术实现要素:
本发明的目的在于提供一种利用计算机视觉与图像识别的物品统计算法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
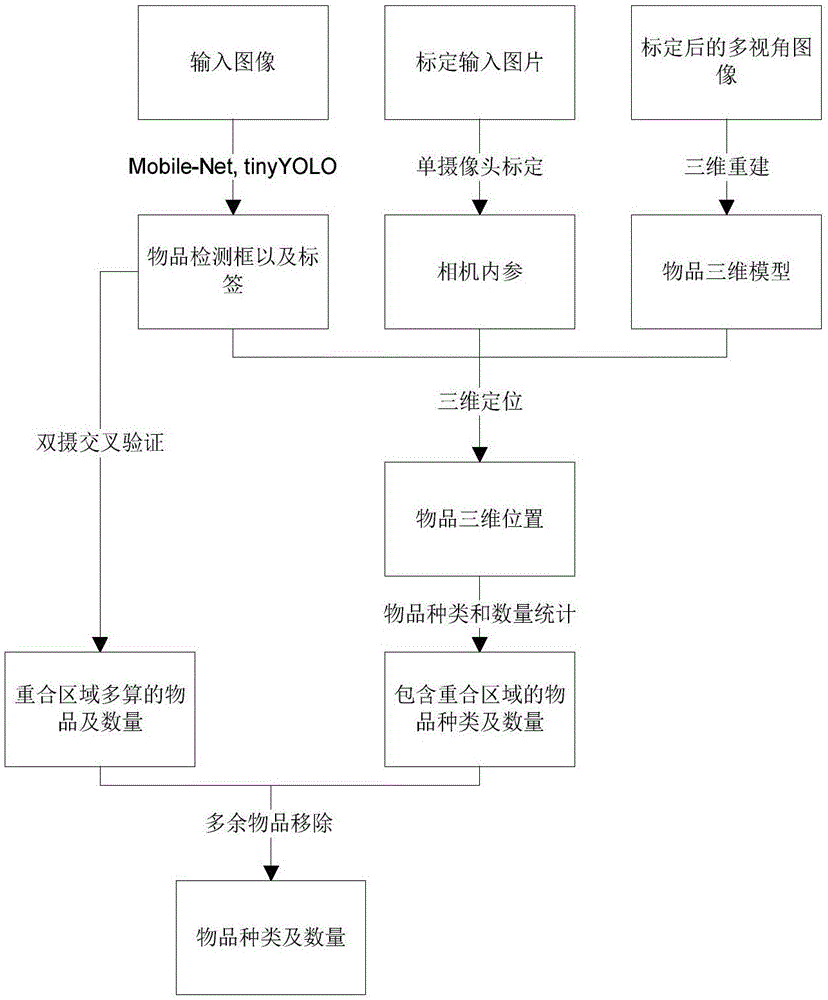
一种利用计算机视觉与图像识别的物品统计算法,包含以下步骤:
a、首先要对六个摄像头进行相机标定,相机标定的目标是计算相机的内部参数,比如焦距和图像中心坐标,以及每对相机之间的相对位置以及角度;
b、获得商品的三维模型;估算商品在三维空间中的姿态,
c、商品位置估计;估算商品在三维空间中的位置;
d、单摄像头以及双摄像头交叉验证。
作为本发明的进一步技术方案:所述相机标定包括以下两种方式;a)单摄像头标定。如图1,用每一个摄像头拍摄一些不同姿态的平面棋盘格图案,然后计算摄像头的内部矩阵和鱼眼畸变系数,b)双摄像头标定。我们需要对每一层的两个相机同时拍摄标定图像,并加以反畸变操作。然后,使用上一步估算的内部矩阵以及标定图案中特征点的三维以及二维位置,解pnp来得到每个相机到标定板平面的姿态,进而获得它们之间的相对位置和角度。
作为本发明的进一步技术方案:所述步骤b是通过特征图与三维模型的匹配计算得到,具体步骤如下:第一步是获得物体不同视角的已标定图片,即对于每一个视角拍摄的图片,我们都需要计算出相机是从哪个角度拍摄到的这张图片,第二步是对目标进行背景移除,生成前景图像,为了获得精确的前景掩膜像,采用基于深度学习的maskr-cnn神经网络,以及谷歌开源的deeplabv3+工程;第三步是模型雕刻和内部挖空处理,即在一个封闭的三维空间中创造一些三维坐标点云,并且根据相机的标定参数和剪影图像,从每个角度去掉非物体的点云,由于只需要知道图像的表面信息,为了简化模型,我们去掉了物体的内部点云,首先把点云转换为三维像素,然后分别在两个坐标轴上进行形态学操作,第四步是对这个模型进行水平集转换,进而实施形状优化,水平集转换是把整个模型分为若干个层,即切面,由于挖空处理,每一个切面是一个轮廓,可以用极值坐标来表示轮廓上的点云坐标,我们把每一层都按照固定数量的角度进行量化,得到了一个二维的流形,其中横轴为角度,纵轴为物体的z轴,每个像素值表示半径,然后对这个流形进行双边滤波,以及强化平滑的非线性优化,得到一个保留细节的平滑模型,第五步是点云染色,即顶点染色,使用第一步获得的彩色图像和第二步获得的前景图像,以及相机参数,即可找到点云到彩色图像上像素点的对应关系,并对其赋予颜色值,第六步是生成模型文件,选择了通用性较高的ply格式,该格式的文件包括顶点信息以及平面信息,每个顶点信息包括该顶点的xyz坐标以及颜色rgb,为了使用gpu进行模型渲染,需要给定面信息,即顶点的连接方式,由于在第四步以及进行了水平集转换,只需要连接相邻顶点即可。
作为本发明的进一步技术方案:所述步骤c具体包括:第一步,对于一张输入图像,首先使用商品检测部分获得的物品中心点的图像坐标,以及拍摄该图像的相机的姿态和参数,计算出一个物体射线,这个射线的原点是相机中心点,射线本身与图像坐标点重合,第二步,计算物体在射线上的位置,进而获得它的三维坐标;由于并不是所有商品都有一台以上相机同时观测到,我们选择通过物体在图像上的投影大小和它的实际投影面积来得到它的深度,然而物体的投影面积和它的姿态有关,比如瓶盖对着摄像头时的投影面积,就比瓶身对着摄像头时的面积要小,为了解决这个问题,我们使用了先前生成的三维模型,进一步说,就是寻找一个三维模型的姿态和位置,能和相机所看到的实际物体尽可能相似,即
作为本发明的进一步技术方案:所述步骤d具体包括:首先对每个摄像头获得的检测结果做一个置信度估算。这个数值由两方面的数据获得。第一,最小化后的损失函数
与现有技术相比,本发明的有益效果是:本发明利用深度学习、三维重建以及多视角交叉验证技术,能够快速统计货架中商品种类和数量。
附图说明
图1为本发明的原理示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,实施例1,一种利用计算机视觉与图像识别的物品统计算法,包含以下步骤:
a、为了计算商品在三维空间中的精确位置坐标,我们首先要对六个摄像头进行相机标定。相机标定的目标是计算相机的内部参数,比如焦距和图像中心坐标,以及每对相机之间的相对位置以及角度;
a)单摄像头标定。用每一个摄像头拍摄一些不同姿态的平面棋盘格图案,然后计算摄像头的内部矩阵(intrinsicmatrix)和鱼眼畸变系数(distortioncoefficient)。
b)双摄像头标定。我们需要对每一层的两个相机同时拍摄标定图像,并加以反畸变操作。然后,使用上一步估算的内部矩阵以及标定图案中特征点的三维以及二维位置,解pnp来得到每个相机到标定板平面的姿态,进而获得它们之间的相对位置和角度。
b、获得商品的三维模型。为了获得商品的精确位置信息,我们还需要估算它在三维空间中的姿态,例如,一个饮料瓶是躺倒的还是直立的。我们是通过特征图与三维模型的匹配来计算的。首先我们要获得商品的三维模型。
三维重建的第一步是获得物体不同视角的已标定图片。即对于每一个视角拍摄的图片,我们都需要计算出相机是从哪个角度拍摄到的这张图片。
第二步是对目标进行背景移除,生成前景图像。为了获得精确的前景掩膜像(maskimage),我们采用了基于深度学习的maskr-cnn神经网络,以及谷歌开源的deeplabv3+工程。
第三步是模型雕刻和内部挖空处理,即在一个封闭的三维空间中创造一些三维坐标点云,并且根据相机的标定参数和剪影图像,从每个角度去掉非物体的点云。由于只需要知道图像的表面信息,为了简化模型,我们去掉了物体的内部点云。首先把点云转换为三维像素(voxel),然后分别在两个坐标轴上进行形态学操作。
第四步是对这个模型进行水平集转换,进而实施形状优化。水平集转换是把整个模型分为若干个层,即切面,由于挖空处理,每一个切面是一个轮廓,可以用极值坐标来表示轮廓上的点云坐标。我们把每一层都按照固定数量的角度进行量化,得到了一个二维的流形(manifold),其中横轴为角度,纵轴为物体的z轴,每个像素值表示半径,然后我们对这个流形进行双边滤波,以及强化平滑的非线性优化,得到一个保留细节的平滑模型。
第五步是点云染色,即顶点染色,使用第一步获得的彩色图像和第二步获得的前景图像,以及相机参数,即可找到点云到彩色图像上像素点的对应关系,并对其赋予颜色值。
第六步是生成模型文件。我们选择了通用性较高的ply格式。该格式的文件包括顶点信息以及平面信息。每个顶点信息包括该顶点的xyz坐标以及颜色rgb。为了使用gpu进行模型渲染,我们需要给定面信息,即顶点的连接方式。由于在第四步以及进行了水平集转换,我们只需要连接相邻顶点即可。
c、商品位置估计。为了判断商品是否还在货架上,我们需要估算商品在三维空间中的位置。第一步,对于一张输入图像,首先使用商品检测部分获得的物品中心点的图像坐标,以及拍摄该图像的相机的姿态和参数,计算出一个物体射线(objectray),这个射线的原点是相机中心点,射线本身与图像坐标点重合。假设没有测量误差,我们可以确定物体中心点就在这条射线上。实际上,由于测量误差,导致的中心点到射线有一个微小的距离。
第二步,计算物体在射线上的位置,进而获得它的三维坐标。由于并不是所有商品都有一台以上相机同时观测到,我们选择通过物体在图像上的投影大小和它的实际投影面积来得到它的深度。然而物体的投影面积和它的姿态有关,比如瓶盖对着摄像头时的投影面积,就比瓶身对着摄像头时的面积要小。为了解决这个问题,我们使用了先前生成的三维模型。进一步说,就是寻找一个三维模型的姿态和位置,能和相机所看到的实际物体尽可能相似,即
d、单摄像头以及双摄像头交叉验证:为了评估检测结果是否精确,我们首先对每个摄像头获得的检测结果做一个置信度估算。这个数值由两方面的数据获得。第一,最小化后的损失函数
为了扩大视场角而又不受图像边缘畸变所影响,我们的冰柜使用了每层两个摄像头的设计。每个摄像头分别对准货架的左右两边。假如覆盖范围正好互补,那么放在范围交界处的物体则无法有效识别。因此我们设计了有一定重合范围的相机朝向,计算物体数量之后再减去多算的数量。对于重合区域的物体,两个摄像头都可以观察到,此时我们做的两条物体射线必然重合(在没有测量误差的前提下),我们就可以找出多算的商品。然而由于测量误差,这两条射线未必重合,我们通过计算射线之间的距离来判断到底这两条射线是否对应同一个商品。使用先前完成的双摄标定参数,我们首先把这两条射线映射到同一个坐标系,然后便可使用两直线距离公式计算出这两条线之间的距离,以及垂直于这两条线的线段中点(这个中点即双摄估计的三维坐标,也可以辅助我们提高重合区域的定位信息)。我们使用一个阈值来判断射线是否对应同一个物体。
实施例2:在实施例1的基础上,机器视觉无人智能零售柜,在柜子内有多层货架来摆放饮料零食等货品,每层货架上方,安装若干个摄像头来监控货架上货品的种类和数量。用户开门前,摄像头拍摄监控货架上商品种类和数量,用户拿取货品后关门后,再次计算统计剩余货品种类和数量,从而得出用户购物的商品交易详单。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!