基于神经网络的多特征融合中文新闻文本摘要生成方法与流程
本发明涉及基于神经网络的多特征融合中文新闻文本摘要生成方法,属于自然语言处理技术领域。
背景技术:
自动文摘将文本内容通过精炼的话概括,是解决信息过载和人工文摘成本大的有效工具,主要应用于新闻领域。
自动文摘的现有研究主要包括两种解决思路,一种是extractive,抽取式的,从原文中找到一些关键的句子,组合成一篇摘要;一种是abstractive,摘要式的,这需要计算机可以读懂原文的内容,并且用自己的意思将其表达出来。本发明利用摘要式(abstractive)这一解决思路来自动生成摘要。
注意力机制可以用来帮助神经网络更好地理解输入数据,尤其是一些专有名词和数字。attention在decoder阶段起作用,通过将输出与所有输入的词建立一个权重关系来让decoder决定当前输出的词与哪个输入词的关系更大(即应该将注意力放到哪个词上)。
通过多特征融合的方式可以更加全面细致地提取文本的深层语义特征。这种融合方式的优点是,不必对各通路输出数据进行同一维度上尺度的统一,可以避免数据信息损失。
技术实现要素:
本发明提供了基于神经网络的多特征融合中文新闻文本摘要生成方法,以用于提高中文新闻文本摘要自动生成的精确度。
本发明的技术方案是:基于神经网络的多特征融合中文新闻文本摘要生成方法,该方法首先进行文本预处理,再进行多特征融合,将融合后的信息输入到解码器生成摘要,再将整个模型的构建与数据进行处理,对于新的文本,利用训练后的网络模型生成摘要;
所述方法的具体步骤如下:
step1、进行文本预处理,中文新闻语料包括新闻文本及其摘要,使用分词工具jieba进行文本预处理包括分词、去停用词,再利用word2vec将分词后的语料表示成词向量;
step2、使新闻文本词向量矩阵分别通过cnn和带有注意力机制的lstm通路进行多特征融合;
step3、将融合后的向量输入解码器,解码器是单向lstm模型,并利用其对应的摘要向量,解码自动生成中文文本摘要;
step4、通过训练整个的网络模型后,对于新的文本,利用训练后的网络模型生成摘要。
所述步骤step2的具体步骤如下所示:
step2.1、lstm通路分析文本整体信息,lstm能处理序列形式的文本数据,注意力机制辅助解码器识别当前时间步的重点信息;用带注意力机制的双向lstm,对于基本的lstm结构,其当前时间步隐层状态更新公式为:
ht=ot·tanh(ct)
其中:
ot=σ(wo·[ht-1,xt]+bo)
ft=σ(wf·[ht-1,xt]+bf)
上述公式中,xt是当前时间步的输入,ht是当前时间步的lstm隐层状态,ot是lstm单元输出,lstm单元状态更新ct,当前输入的单元状态c~t,上一次的单元状态ct-1,ft是遗忘层更新,σ是sigmoid函数,遗忘门层权重矩阵wf,lstm单元状态权重矩阵wc,lstm输出层权重矩阵wo;遗忘门层的偏置项为bf,单元状态的偏置项为bc,输出层的偏置项为bo;
对于双向lstm,由于有正向和反向两个计算方向,其结构用公式表示为:
st=f(uxt+wst-1)
s‘t=f(u’xt+w‘s’t+1)
o‘=g(v’s’t+vst)
其中st为正向t时刻的隐藏状态,s‘t是反向t时刻的隐藏状态,u,w,u’,w‘分别是正向和反向对应的矩阵权重,最终的输出o'取决于正向和反向计算的加和,v',v为权重矩阵,f为上面基本的lstm结构,g为softmax函数;
在注意力机制中,eij的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大,eij是由第i-1个输出隐藏状态si-1和输入中各个隐藏状态共同决定的,经过归一化成为权重aij,由带注意力机制的lstm通道的隐藏向量序列(h1,h2…ht)按权重相加得到的新闻文本在i时刻的信息向量ci,能表示为公式:
eij=a(si-1,hj)
其中a是sigmoid函数;
eij经过归一化成为权重aij,aij表示为公式:
其中,tx为输入词的个数;
隐藏向量序列(h1,h2…ht)按权重相加得到ci,ci表示为公式:
step2.2、cnn通路提取文本局部特征,为了提取不同方面特征,使用两个cnn通路;同一条cnn通路中卷积核的尺寸相同,池化层均采用最大池化;通过将不同卷积核的cnn的处理结果拼接在一起,以更全面、更细致地挖掘深层特征;嵌入层为输入新闻文本词向量矩阵,依次经过cnn1,cnn22种3层卷积层和池化层提取特征和降维,2条通路的输出经压平层压为1维向量;
step2.3、在经过cnn通路和带有注意力机制的lstm通路提取不同层次的文本特征后,通过融合层来实现各个通路输出的融合;融合层采用合并拼接各个神经网络通路输出向量的方式,将各个通路提取的文本特征向量拼接融合在一起;各条通路的输出均为一维的数据。
所述步骤step3的具体步骤如下所示:
step3.1、新闻文本对应的摘要y=y1,y2…yn),yi∈rd,i∈[0,n]
其中d为向量维度,n为摘要的词个数;
每个lstm单元都会根据它的输入并通过其内部结构计算出ht,具体过程如下:
it=σ(w1yt-1+w2ht-1+w3m)
i′t=tanh(w4yt-1+w5ht-1+w6m)
ft=σ(w7yt-1+w8ht-1+w9m)
ot=σ(w10yt-1+w11ht-1+w12m)
mt=mt-1·ft+it·i′t
ht=mt·ot
其中yt-1,ht-1,m是每个lstm单元的输入,wi∈[1,14],是可学习的参数矩阵,σ是sigmoid激活函数,tanh是tanh激活函数,it和i′t是输入层更新,ft是遗忘层更新,ot是输出层更新,mt是更新的细胞状态,ht是lstm单元的隐含层状态,也是每个lstm结构的最终输出;
根据ht得到y′t的条件概率:
p(y′t|y′t-1,y′t-2,,,y′1,m)=ρ(w13ht+w14m)
其中y‘t为解码器t时刻的输出,ρ为输出层的softmax函数,对于t时刻,根据lstm单元的输出ht和m,利用输出层函数softmax,得到在已知前t-1时刻的摘要词的条件下,第t时刻的摘要词是y‘t的概率;对于模型每一次的迭代输出,这个概率是一个定值;
step3.2、在训练过程中,给定一个训练语料
其中n为每个训练样本标准摘要的词个数,参数θ是构成网络模型的参数;
通过随机梯度下降算法端对端的训练网络模型,优化模型参数θ,使得模型损失l达到最小值。
所述步骤step4的具体步骤包括:
对于新文本x,直接利用训练好的模型参数进行摘要生成,首先对新文本进行文本预处理,即分词,去停用词,使用word2vec将文本转化为词向量,并按顺序输入到模型网络中;采用集束搜索beamsearch的方法,通过搜索词汇库,生成一个长度为n个词的序列y,使得p(y|x最大,这个公式表示为输入序列为x的条件下,输出是y序列,其中,x表示输入序列即我们输入的新闻文本,y表示输出序列即模型生成的摘要序列;即通过每个时间步追踪的路径数目k对搜索进行参数化,在每个时间步执行argmaxp(yt|{y1,…,yt-1},x),保留k个概率最大的t元序列,直至生成使p(y|x最大的n元序列。
本发明使用数据驱动的方法来训练一个中文新闻文本摘要自动生成模型。生成的摘要序列不限于输入文本中的词,在很多情况下能够生成更好的文本摘要。本方法使用的融合多特征的encode-decode框架能够很好的学习训练数据中摘要生成的风格。
本发明的有益效果是:
本方法通过数据驱动学习了一个端到端的中文新闻文本摘要自动生成模型来实现中文新闻文本的摘要自动生成,相对于传统的基于统计学的摘要生成方法,基于神经网络融合多特征自动生成摘要的方法可以深层次的分析文本含义,更加全面地挖掘文本特征,从而提高文本摘要生成的精确度。
附图说明
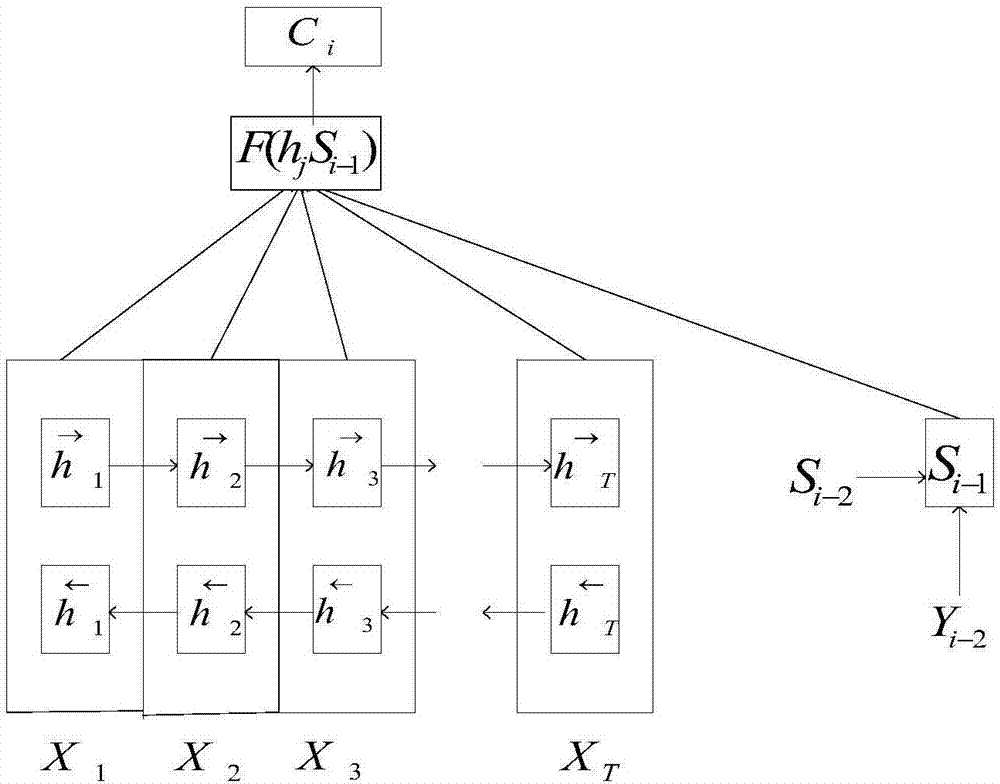
图1是本发明分析文本整体信的lstm通道结构示意图;
图2是本发明提取文本局部特征的cnn通道结构示意图;
图3是本发明多元特征融合的编码器结构示意图;
图4是本发明解码器训练过程结构示意图;
图5是本发明解码器测试过程结构示意图;
图6基于神经网络的多特征融合的中文新闻文本摘要生成模型结构示意图。
具体实施方式
实施例1:如图1-6所示,基于神经网络的多特征融合中文新闻文本摘要生成方法;
所述方法的具体步骤如下:
step1、进行文本预处理,中文新闻语料包括新闻文本及其摘要,使用分词工具jieba进行文本预处理包括分词、去停用词,再利用word2vec将分词后的语料表示成词向量;
step2、使新闻文本词向量矩阵分别通过cnn和带有注意力机制的lstm通路进行多特征融合;
step3、将融合后的向量输入解码器,解码器是单向lstm模型,并利用其对应的摘要向量,解码自动生成中文文本摘要;
step4、通过训练整个的网络模型后,对于新的文本,利用训练后的网络模型生成摘要。
进一步的,所述步骤step2的具体步骤如下所示:
step2.1、lstm通路分析文本整体信息,lstm能处理序列形式的文本数据,注意力机制辅助解码器识别当前时间步的重点信息;用带注意力机制的双向lstm,如图1所示。对于基本的lstm结构,其当前时间步隐层状态更新公式为:
ht=ot·tanh(ct)
其中:
ot=σ(wo·[ht-1,xt]+bo)
ft=σ(wf·[ht-1,xt]+bf)
上述公式中,xt是当前时间步的输入,ht是当前时间步的lstm隐层状态,ot是lstm单元输出,lstm单元状态更新ct,当前输入的单元状态
对于双向lstm,由于有正向和反向两个计算方向,其结构用公式表示为:
st=f(uxt+wst-1)
s′t=f(u’xt+w‘s’t+1)
o‘=g(v’s’t+vst)
其中st为正向t时刻的隐藏状态,s‘t是反向t时刻的隐藏状态,u,w,u′,w‘分别是正向和反向对应的矩阵权重,最终的输出o′取决于正向和反向计算的加和,v′,v为权重矩阵,f为上面基本的lstm结构,g为softmax函数;
在注意力机制中,eij的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大,eij是由第i-1个输出隐藏状态si-1和输入中各个隐藏状态共同决定的,经过归一化成为权重aij,由带注意力机制的lstm通道的隐藏向量序列(h1,h2…ht)按权重相加得到的新闻文本在i时刻的信息向量ci,能表示为公式:
eij=a(si-1,hj)
其中a是sigmoid函数;
eij经过归一化成为权重aij,aij表示为公式:
其中,tx为输入词的个数;
隐藏向量序列(h1,h2…ht)按权重相加得到ci,ci表示为公式:
step2.2、cnn通路提取文本局部特征,为了提取不同方面特征,使用两个cnn通路;同一条cnn通路中卷积核的尺寸相同,池化层均采用最大池化;通过将不同卷积核的cnn的处理结果拼接在一起,以更全面、更细致地挖掘深层特征;如图2中,嵌入层为输入新闻文本词向量矩阵,依次经过cnn1,cnn22种3层卷积层和池化层提取特征和降维,2条通路的输出经压平层压为1维向量;
step2.3、在经过cnn通路和带有注意力机制的lstm通路提取不同层次的文本特征后,通过融合层来实现各个通路输出的融合;融合层采用合并拼接各个神经网络通路输出向量的方式,将各个通路提取的文本特征向量拼接融合在一起;各条通路的输出均为一维的数据。多特征融合示意图如图3所示。图中cnn通路、带有注意力机制的lstm通路输出的一维向量在融合层进行拼接融合生成向量m,表示为公式:
m=[y1,y2]
进一步的,所述步骤step3的具体步骤如下所示:
step3.1、新闻文本对应的摘要y=(y1,y2…yn),yi∈rd,i∈[0,n]
其中d为向量维度,n为摘要的词个数;
每个lstm单元都会根据它的输入并通过其内部结构计算出ht,具体过程如下:
it=σ(w1yt-1+w2ht-1+w3m)
i′t=tanh(w4yt-1+w5ht-1+w6m)
ft=σ(w7yt-1+w8ht-1+w9m)
ot=σ(w10yt-1+w11ht-1+w12m)
mt=mt-1·ft+it·i′t
ht=mt·ot
其中yt-1,ht-1,m是每个lstm单元的输入,wii∈[1,14],是可学习的参数矩阵,σ是sigmoid激活函数,tanh是tanh激活函数,it和i′t是输入层更新,ft是遗忘层更新,ot是输出层更新,mt是更新的细胞状态,ht是lstm单元的隐含层状态,也是每个lstm结构的最终输出;
根据ht得到y′t的条件概率:
p(y′t|y′t-1,y′t-2,,,y′1,m)=ρ(w13ht+w14m)
其中y‘t为解码器t时刻的输出,ρ为输出层的softmax函数,对于t时刻,根据lstm单元的输出ht和m,利用输出层函数softmax,得到在已知前t-1时刻的摘要词的条件下,第t时刻的摘要词是y‘t的概率;对于模型每一次的迭代输出,这个概率是一个定值;
step3.2、在训练过程中,给定一个训练语料
其中n为每个训练样本标准摘要的词个数,参数θ是构成网络模型的参数;
通过随机梯度下降算法端对端的训练网络模型,优化模型参数θ,使得模型损失l达到最小值。
进一步的,所述步骤step4的具体步骤包括:
对于新文本x,直接利用训练好的模型参数进行摘要生成,首先对新文本进行文本预处理,即分词,去停用词,使用word2vec将文本转化为词向量,并按顺序输入到模型网络中;采用集束搜索beamsearch的方法,通过搜索词汇库,生成一个长度为n个词的序列y,使得p(y|x最大,这个公式表示为输入序列为x的条件下,输出是y序列,其中,x表示输入序列即我们输入的新闻文本,y表示输出序列即模型生成的摘要序列;即通过每个时间步追踪的路径数目k对搜索进行参数化,在每个时间步执行argmaxp(yt|{y1,…,yt-1},x),保留k个概率最大的t元序列,直至生成使p(y|x最大的n元序列。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!