一种基于动态手势识别的智能人机交互方法与流程
本发明提出了一种基于动态手势识别的非接触式交互方法,是一种面向智慧家庭场景的智能人机交互解决方案。
背景技术:
近年来,随着机器学习技术,特别是深度学习理论的飞速发展,以及高清摄像头、高性能显卡等硬件设备制造工艺的日益成熟,人工智能技术从主要被应用于工业界,开始被越来越广泛地应用于人们的日常生活中,例如,基于车牌识别的智能门禁系统、基于人脸识别的无人值守超市、基于风格迁移的人脸卡通化软件等。在此背景下,旨在综合人工智能、物联网、云计算以创造出舒适、健康、安全、便捷的定制化家居生活的“智慧家庭”概念应运而生,其中,如何结合家庭环境感知对家居设备进行控制,即设计出一种面向智慧家庭场景的智能人机交互解决方案,是一项极具挑战性的工作。
目前,市面上已经有一批基于手势识别的人机交互方案及设备,但是,该类方案一般只能识别静态手势,且多需要特殊的设备,应用场景较为有限。以微软xboxone主机的手势操作为例,其手势交互方案不仅需要配备专用的kinect深度摄像头,且基本只能识别肢体动作,对手势的识别率较低,无法满足用户日常所需。另一方面,囿于家居场景中嵌入式设备的算力限制,现有方案无法使用残差网络等目前业界性能最好的卷积神经网络,而只能采用传统机器学习算法中的支持向量机甚至简单的模板匹配方法来进行静态手势识别,此类方法一方面识别效果较差,特别是对光照、肤色、手势方向、图像背景等因素的鲁棒性较差;另一方面,该类方法不易集成手部区域跟踪及轨迹分类算法,无法实现对动态手势即手势运动轨迹作出交互响应行为,基本不能满足智能化家庭背景下的人机交互需求。总的来讲,面向家居智能化的时代背景,传统的机器学习方法已经无法满足智能人机交互方案需要在嵌入式设备上满足鲁棒性、实时性、准确性的要求,因此,引入深度学习方案,在嵌入式设备上实现深度卷积神经网络,是智慧家庭发展的必然要求。
本发明旨在面向室内场景下的动态手势识别任务的实际需求,有针对性地改进轻量化目标检测卷积神经网络,并集成手势跟踪及轨迹分类算法,在nvidiatx2开发板上实现对动态手势的实时、高性能检测,并在此基础上提供非接触式的智能人机交互方法,为智慧家庭整体解决方案提供友好的人机接口。
技术实现要素:
本发明的发明目的在于:针对目前基于手势的人机交互方案一般采用传统的机器学习算法,无法满足智慧家庭背景下嵌入式设备对实时性、鲁棒性的要求。本发明尝试改进轻量化的目标检测网络,实现对手部区域的快速准确检测,在此基础上集成目标跟踪算法获取手部的运动轨迹并根据轨迹分类结果提供个性化的人机交互行为。
本发明的一种基于动态手势识别的智能人机交互方法,包括下列步骤:
步骤一、对彩色摄像头捕获的视频帧进行手部区域检测:
通过卷积神经网络提取视频图像的低阶特征谱和高阶特征谱,进行尺寸归一化后进行特征谱融合,得到融合特征谱;
基于融合特征谱进行手部区域检测,得到初步目标检测框,并对其进行非极大值抑制操作以去除冗余检测框;
具体抑制处理为:
(1)将所有检测目标框根据分类置信度按从大到小的顺序排序;
(2)选取置信度最高分所对应的检测框,记为框a并保留;
(3)遍历所有非a框,去除其中与框a的交并比大于预设阈值的检测目标框;
(4)对未处理的检测目标框重复步骤(2)~(3),直到所有检测目标框均被处理,所述处理包括保留和删除;
步骤二、对手部区域进行基于相关滤波的手势跟踪:
步骤三、对手势轨迹进行分类:
通过预设的分类网络(如神经网络),每隔固定帧数进行一次手势轨迹分类处理,且在将轨迹样本送入分类网络前,应当进行白边补全及大小归一化操作;
步骤四:根据手势轨迹作出交互行为。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
本发明提出了一种基于动态手势识别的非接触式交互方法,该方法改进了基于深度卷积神经网络的目标检测网络并集成了跟踪、分类算法,能够在嵌入式设备上实现对动态手势的实时识别,并对光照、肤色、背景等因素有极强的鲁棒性,是一种面向智慧家庭场景的智能人机交互解决方案。
附图说明
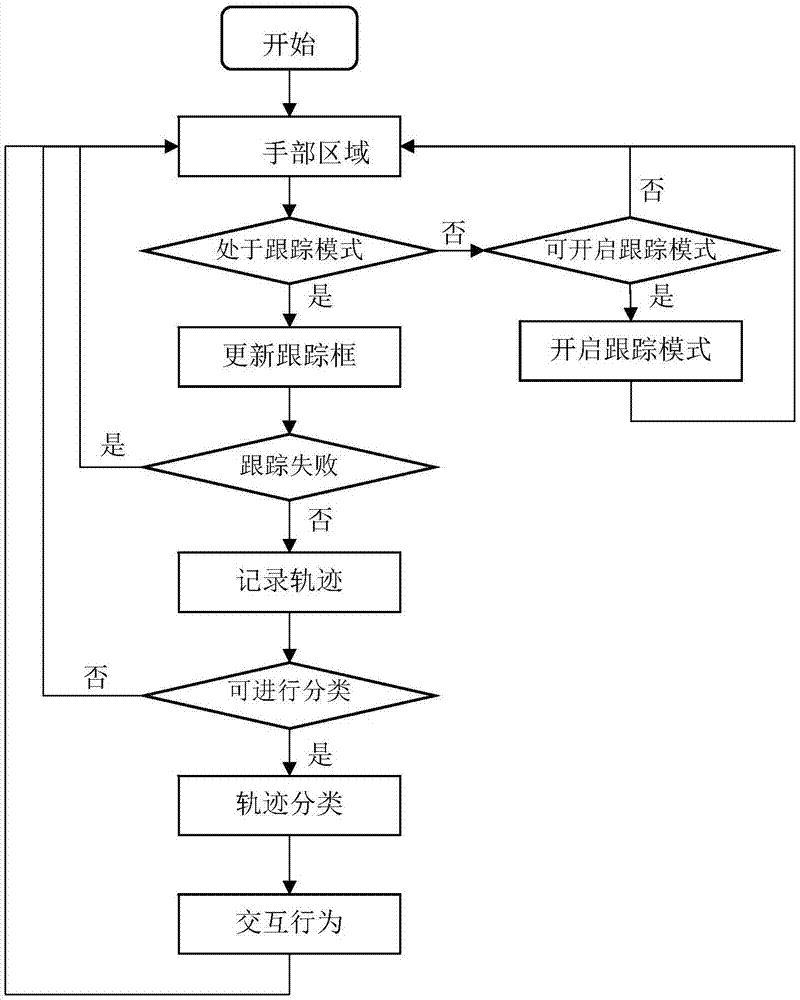
图1是实施例的处理过程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
本发明针对目前基于手势的人机交互方案一般采用传统的机器学习算法,无法满足智慧家庭背景下嵌入式设备对实时性、鲁棒性的要求。本发明尝试改进轻量化的目标检测网络,实现对手部区域的快速准确检测,在此基础上集成目标跟踪算法获取手部的运动轨迹并根据轨迹分类结果提供个性化的人机交互行为。
首先,对彩色摄像头捕获的视频帧进行手部区域检测。
常规的目标检测网络直接抽取高阶特征谱作预测,没有充分融合不同尺度的特征,且由于高阶特征谱中的点对应原图中的感受野较大,而手部区域占整幅图像的比例一般较小,所以常规检测网络对手部区域的检出率一般不高。为此,本发明在卷积神经网络中引入上下文信息,即将包含丰富边缘、纹理等信息的低阶特征谱和包含丰富语义信息的高阶特征谱融合后再进行目标框回归及分类操作。特别地,为了充分融合卷积特征谱的信息,本发明将低阶特征谱经池化(pooling)操作后归一化为38×38像素大小,将高阶特征谱经反卷积(deconvolution)操作后也归一化为38×38像素大小,再将两者进行相加融合后进行后续操作。
其次,为了防止同一个目标被检测多次,应在得到初步检测结果后进行非极大值抑制操作以去除冗余检测框,具体算法步骤如下:
(1)将所有检测目标框(检测框)根据分类置信度按从大到小的顺序排序;
(2)选取置信度最高分所对应的检测框,记为框a并保留;
(3)遍历其它所有检测框(即遍历所有非a框),去除其中与框a的iou(交并比)大于预设阈值(本具体实施方式中的优选取值设置为0.5)的框;
(4)再继续从未处理(保留、删除)的检测框中选出置信度最高的,重复步骤(2)~(3,直到所有检测框均被处理
然后,对手部区域进行跟踪。
由于手部检测网络无法保证每一帧均能准确检出手部并保证手势轨迹的平滑,即存在漏检和虚检现象,因此,为了保证轨迹分类网络的输入质量,并兼顾实时性需求,本发明引入了基于相关滤波的手势跟踪方法。
记h、g、f、λ分别为相关滤波器模板、样本标签、训练样本和正则化参数,则有
其中k表示特征迭代指示变量,d表示特征总维数,l表示特征维度,
为了加快求解速度,可以迭代求解滤波器的分子a和分母b,即
其中,η为学习率,t为迭代次数,
由上式可得,下一帧的目标位置可由最小化分数y得到,即
其中,f-1为傅里叶逆变换,zl表示目标区域的二维傅里叶变换结果。
再者,对手势轨迹进行分类。
为了提高程序整体运行效率,并考虑到实际使用场景下手势轨迹的绘制过程,手势分类网络不在每一帧前向传播轨迹样本,而是每隔固定帧数k(例如40帧)分类一次。此外,由于检测网络的输出结果的大小和尺寸均不固定,因此,在将轨迹样本送入分类网络前,应当进行白边补全及大小归一化操作(优选的统一大小为224×224像素点)。
最后,根据手势轨迹作出交互行为。
为了提供个性化的交互服务,具体的交互行为应当取决于具体的应用场景并可由用户自行定制。举例来说,当本发明方法被应用到智能音箱上时,交互动作可以是对话行为;当本发明方法被应用到陪护机器人上时,交互动作可以是移动行为。
参见图1,在具体实现时,本发明主要可以分为手部区域检测、手部区域跟踪、手势轨迹分类和交互响应4个步骤,各步骤具体为:。
步骤s1:手部区域检测:
步骤s101:从彩色摄像头获取视频帧图像;
步骤s102:对捕获图像进行减均值、通道交换、大小归一化等预处理操作;
步骤s103:检测手部区域;
步骤s104:对手部区域检测框进行非极大值抑制。
步骤s2:手部区域跟踪:
步骤s201:当手部区域检测框的置信度高于预设阈值时,将其作为跟踪框的首帧目标位置;
步骤s202:利用相关滤波器更新当前帧目标位置(更新跟踪框);
其中相关滤波器具体实现可参考文献《henriquesjf,caseiror,martinsp,etal.high-speedtrackingwithkernelizedcorrelationfilters[j].ieeetransactionsonpatternanalysis&machineintelligence,2015,37(3):583-596.》。
步骤s203:如果跟踪置信度小于预设阈值,则返回跟踪失败,否则继续更新目标位置。
步骤s3:手势轨迹分类:
步骤s301:在预设时刻生成手势轨迹样本图像;
步骤s302:在分类网络中前向传播轨迹样本,获取轨迹分类结果。
s4:交互响应:根据轨迹分类结果作出预设交互行为。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!