一种基于卷积神经网络的汉语句子词义消岐方法与流程
本发明涉及一种基于卷积神经网络的汉语句子词义消岐方法,该方法在自然语言处理领域中有着很好的应用。
背景技术:
在自然语言处理领域中,词汇普遍具有一词多义现象。词义消歧的目的是确定歧义词汇在特定上下文环境中的语义。词义消歧在机器翻译、自动文摘、信息检索和文本分类中有着重要的应用,其性能的好坏与词义消歧紧密相关。
经常使用一些常见的算法对词汇进行消岐和分类,例如:k-means、朴素贝叶斯、基于关联规则的分类方法和人工神经网络等。但是,传统的算法存在着一些缺点和不足。所提取的消岐特征只局限于局部区域,分类器的训练效果不是很好。近年来,深度学习算法已被广泛地应用到自然语言处理领域。卷积神经网络是当前深度学习算法中的主要模型。将处理好的消岐特征输入到初始化的卷积神经网络(convolutionneuralnetwork,cnn)模型之中。在cnn模型中,神经元的权值是共享的。这使得神经元可以共享资源,降低了网络模型的复杂度,防止出现过拟合现象。对于歧义词汇而言,可以很好地应用卷积神经网络来进行消岐,实现语义的正确分类。
技术实现要素:
为了解决自然语言处理领域中的词汇歧义问题,本发明公开了一种基于卷积神经网络的汉语句子词义消岐方法。
为此,本发明提供了如下技术方案:
1.基于卷积神经网络的汉语句子词义消岐方法,其特征在于,该方法包括以下步骤:
步骤1:对语料所包含的所有汉语句子进行分词、词性标注和语义类标注,选取歧义词汇左右四个邻接词汇单元的词形、词性和语义类作为消岐特征;
步骤2:提取歧义词汇左右四个邻接词汇单元的词形、词性和语义类,统计其频度,转换成对应的二进制数。选取一小部分处理好的语料作为测试数据,其余的作为训练数据;
步骤3:训练包括前向传播和反向传播两个过程。训练数据作为cnn模型训练的输入,经过cnn模型的训练,得到优化后的cnn模型;
步骤4:测试过程为前向传播过程,即语义分类过程。在优化后的cnn模型上,输入测试数据,计算歧义词汇在每个语义类别下的概率分布,其中,具有最大概率的语义类即为歧义词汇的语义类。
2.根据权利要求1所述的基于卷积神经网络的汉语句子词义消岐方法,其特征在于,所述步骤1中,对汉语句子进行分词、词性标注和语义类标注,提取消岐特征,具体步骤为:
步骤1-1利用汉语分词工具对汉语句子进行词汇切分;
步骤1-2利用汉语词性标注工具对已切分好的词汇进行词性标注;
步骤1-3利用汉语语义标注工具对已切分好的词汇进行语义类标注;
利用汉语分词工具、汉语词性标注工具和汉语语义标注工具对语料所包含的所有汉语句子进行词汇切分、词性标注和语义类标注,选取歧义词汇左右四个邻接词汇单元的词形、词性和语义类作为消岐特征。
3.根据权利要求1所述的基于卷积神经网络的汉语句子词义消岐方法,其特征在于,所述步骤2中,以哈尔滨工业大学人工语义标注语料为基础,统计消岐特征的出现频度,具体步骤为:
步骤2-1提取歧义词汇的左右四个邻接词汇单元的词形、词性和语义类;
步骤2-2统计消岐特征的出现频度;
步骤2-3其频度经过二进制转化后,每个消岐特征对应于一组二进制数。选取一小部分处理好的语料作为测试数据,其余的作为训练数据。
4.根据权利要求1所述的基于卷积神经网络的汉语句子词义消岐方法,其特征在于,所述步骤3中,对cnn模型进行训练,具体步骤为:
前向传播过程:
步骤3-1把训练数据输入到初始化的cnn模型中;
步骤3-2经过卷积层,提取更完整的消岐特征;
步骤3-3经过池化层,提取最大的消岐特征。可以大大地缩小消岐特征的规模,从而减少参数个数,加快模型计算的速度,有效地防止过拟合;
步骤3-4通过卷积和池化交替操作之后,进入全连接层,对所提取的消岐特征进行降维,连接成一维消岐特征向量;
步骤3-5利用softmax层来计算歧义词汇m在每个语义类别si(i=1,2,...,n)下的预测概率,所述的softmax函数如下:
其中,ai表示softmax层的输入数据,p(si|m)表示歧义词汇m在语义类别si下的出现概率(i=1,2,...,n);
步骤3-6从p(s1|m)、p(s2|m)、...、p(sn|m)中选取最大概率作为预测概率。具体计算如下:
其中,y_predictedj表示歧义词汇m的预测概率;
步骤3-7将预测概率y_predictedj和真实概率yj进行比较,利用交叉熵损失函数来计算误差loss。所述误差loss的计算过程如下所示:
其中,yj表示歧义词汇m属于语义类别si的真实概率。
反向传播过程:
根据误差loss反向传播,逐层更新参数,参数更新过程如下:
其中,θ表示参数集,θ'表示更新后的参数集,a为学习率。
不断迭代cnn模型,得到优化后的cnn模型。
5.根据权利要求1所述的基于卷积神经网络的汉语句子词义消岐方法,其特征在于,在所述步骤4中,对歧义词汇m进行语义分类,具体过程为:
语义分类过程:
步骤4-1把测试数据输入到优化后的cnn模型之中;
步骤4-2经过卷积层设置卷积核,提取更完整的消岐特征;
步骤4-3经过池化层,提取最大的消岐特征;
步骤4-4通过卷积和池化交替操作之后,进入全连接层,对所提取的消岐特征进行降维,连接成一维消岐特征向量;
步骤4-5利用softmax层来计算歧义词汇m在每个语义类别下的概率分布。其中,具有最大概率的语义类别s'即为歧义词汇的语义类别。所述语义类别s'的确定过程如下:
其中,s'表示概率最大的语义类别,n表示语义类别数,p(s1|m),...,p(si|m),...,p(sn|m)表示歧义词汇m在语义类别下的概率分布序列。
有益效果:
1.本发明是一种基于卷积神经网络的汉语句子词义消岐方法。对汉语句子进行了词汇切分、词性标注和语义类标注。以哈尔滨工业大学人工语义标注语料为基础,统计消岐特征的出现频度。所提取的消岐特征具有较高的质量。
2.本发明所使用的模型为卷积神经网络模型,最大的特点是局部感知和参数共享,能够很好地处理高维数据,无需手动选取数据特征。只要训练好cnn模型,就可以获得较好的分类效果。经过卷积和池化两大操作,能够提取更完整的消岐特征,减少数据量和参数量,防止出现过拟合。
3.本发明使用的分类器为softmax分类器,不仅能解决二类分类的数据处理,而且能够解决多分类的数据处理。
4.在训练模型时,采用随机梯度下降法进行参数更新。通过计算误差,误差通过反向传播沿原路线返回,即从输出层反向经过各中间隐藏层,逐层更新每一层参数,最终回到输出层。不断地进行前向传播和反向传播,以减小误差,更新模型参数,直到cnn训练好为止。随着误差反向传播不断地对参数进行更新,整个cnn模型对输入数据的消岐准确率也有所提高。
附图说明:
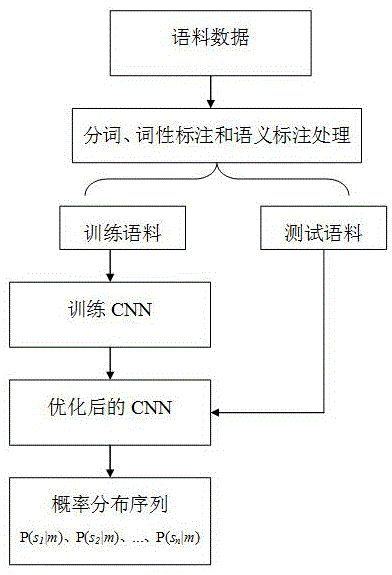
图1为本发明实施方式中的汉语句子词义消岐的流程图;
图2为本发明实施方式中的基于cnn的词义消歧模型的训练过程;
图3为本发明实施方式中的基于cnn的词义消歧模型的测试过程。
具体实施方式:
为了使本发明的实施例中的技术方案能够清楚和完整地描述,以下结合实施例中的附图,对本发明进行进一步的详细说明。
以对汉语句子“中华各族儿女共同创造的优秀传统文化,始终是维系全体中国人的精神纽带和实现和平统一的重要基础。”中的歧义词汇“儿女”进行消岐处理为例。
本发明实施例基于卷积神经网络的汉语句子词义消岐方法的流程图,如图1所示,包括以下步骤。
步骤1消岐特征的提取过程如下:
汉语句子:中华各族儿女共同创造的优秀传统文化,始终是维系全体中国人的精神纽带和实现和平统一的重要基础。
步骤1-1利用汉语分词工具对汉语句子进行词汇切分,分词结果为:中华各族儿女共同创造的优秀传统文化始终是维系全体中国人的精神纽带和实现和平统一的重要基础。
步骤1-2利用汉语词性标注工具对分词结果中的词汇进行词性标注,词性标注结果为:中华/nz各族/r儿女/n共同/d创造/v的/u优秀/a传统/n文化/n始终/d是/v维系/v全体/n中国/ns人/n的/u精神/n纽带/n和/c实现/v和平/a统一/n的/u重要/a基础/n。
步骤1-3利用汉语语义标注工具对分词结果中的词汇进行语义类标注,语义类标注结果为:中华/di02各族/dn03儿女/ah14共同/ka23创造/hc05的/kd01优秀/ed03传统/di14文化/dk02始终/ka11是/ja01维系/ie02全体/eb02中国/di02人/aa01的/kd01精神/df01纽带/dd09和/kc01实现/ie14和平/ef01统一/ie08的/kd01重要/ed28基础/dd12。
含有歧义词汇“儿女”的汉语句子的分词、词性标注和语义类标注结果为:中华/nz/d各族/r/d儿女/n/a共同/d/k创造/v/h的/u/k优秀/a/e传统/n/d文化/n/d始终/d/k是/v/j维系/v/i全体/n/e中国/ns/d人/n/a的/u/k精神/n/d纽带/n/d和/c/k实现/v/i和平/a/e统一/n/i的/u/k重要/a/e基础/n/d。
步骤2统计消岐特征的出现频度。
步骤2-1从包含歧义词汇“儿女”的汉语句子中,提取歧义词汇左右四个邻接词汇单元,分别为“中华/nz/d”、“各族/r/d”、“共同/d/k”和“创造/v/h”,一共提取了12个消岐特征。
步骤2-2根据哈尔滨工业大学人工语义标注语料,统计12个消岐特征的出现频度并转化成二进制数,如下表所示。
步骤3歧义词汇“儿女”的语义类有两种,分别为“children”和“young_man_and_woman”。
本发明实施例基于cnn的词义消歧模型的训练过程和基于cnn的词义消歧模型的测试过程,如图2和图3所示。具体为:
前向传播过程:
步骤3-1将12个消岐特征频度所对应的二进制数作为训练数据输入到初始化的cnn模型之中;
步骤3-2经过卷积层设置卷积核,提取更完整的消岐特征;
步骤3-3经过池化层,提取最大的消岐特征;
步骤3-4通过卷积和池化交替操作之后,进入全连接层,对提取的消岐特征进行降维,连接成一维消岐特征向量;
步骤3-5利用softmax层来计算歧义词汇“儿女”在语义类别“children”和“young_man_and_woman”下的预测概率;
所述的softmax函数计算过程如下:
其中,as表示softmax层的输入数据,p(children|儿女)表示歧义词汇“儿女”在语义类别“children”下的出现概率,p(young_man_and_woman|儿女)表示歧义词汇“儿女”在语义类别“young_man_and_woman”下的出现概率。
步骤3-6从p(children|儿女)、p(young_man_and_woman|儿女)中选取最大概率作为预测概率。
其中,y_predicted表示歧义词汇“儿女”的预测概率,为89.99%。
步骤3-6将cnn的预测概率y_predicted和真实概率y进行比较,利用交叉熵损失函数来计算误差。
所述的误差计算过程如下:
其中,loss儿女表示歧义词汇“儿女”的误差。
反向传播过程:
根据误差loss儿女,将误差反向传播,逐层更新每一层的参数,参数更新过程如下:
其中,θ儿女表示歧义词汇“儿女”的参数集,θ'儿女表示更新之后的参数集,a为学习率。
不断迭代cnn模型,得到优化后的cnn模型。
步骤4模型测试,即语义分类过程,具体步骤为:
步骤4-1把测试数据输入到优化后的cnn模型之中;
步骤4-2经过卷积层设置卷积核,提取更完整的消岐特征;
步骤4-3经过池化层,提取最大的消岐特征;
步骤4-4通过卷积和池化交替操作之后,进入全连接层,对提取的消岐特征降维,连接成一维消岐特征向量;
步骤4-5通过softmax层计算歧义词汇“儿女”在每个语义类别下的概率,最大概率所对应的语义类别即为歧义词汇的语义类别。
歧义词汇“儿女”的语义类别s'的确定过程如下:
其中,s'表示歧义词汇“儿女”所对应的语义类别为young_man_and_woman,p(s|儿女)表示歧义词汇“儿女”在每个语义类别下的概率分布。
通过卷积神经网络模型,对包含歧义词汇“儿女”的汉语句子“中华各族儿女共同创造的优秀传统文化,始终是维系全体中国人的精神纽带和实现和平统一的重要基础。”进行词义消岐,歧义词汇“儿女”所对应的语义类别为young_man_and_woman。
本发明实施方式中的基于卷积神经网络的汉语句子词义消岐方法,能够选择精确的消岐特征,并采用卷积神经网络模型来确定歧义词汇的语义类别,具有较高的正确率。
以上所述是结合附图对本发明的实施例进行的详细介绍,本文的具体实施方式只是用于帮助理解本发明的方法。对于本技术领域的普通技术人员,依据本发明的思想,在具体实施方式及应用范围内均可有所变更和修改,故本发明书不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!