一种基于特征加权模糊支持向量机的音乐流派分类方法及系统与流程
本发明涉及一种基于特征加权模糊支持向量机的音乐流派分类方法及系统,属于音乐内容检索及模式识别技术领域。
背景技术:
音乐是人们用来表现生活、抒发情感的一种艺术。音乐流派是人类创造的分类标签,由专家们通过一定的相似性将音乐进行组织整理。随着音乐数据的不断增多,越来越庞大的数字音乐数据库需要智能化、自动化的分类管理,音乐流派的分类受到社会和学界越来越广泛的关注。然而,当下音乐的发展趋势越来越多元化,一首音乐作品可能会融入多种流派。
音乐流派分类系统有三个组成部分:音乐特征的提取及选择;分类器的选择及模型训练;分类效果测试及对比。国内外研究,主要围绕着新特征的引入以及分类器最优适配选择进行开展。目前,主流的音乐流派分类系统主要集中于音色、节奏、基因频率等音频的声学特征进行提取,且多采用支持向量机(svm)分类器对音乐流派分类,取得了良好的效果。然而,目前的研究工作,鲜有考虑到音乐流派具有模糊性这一特点,其最终仅输出一个可能性最大的流派,导致音乐流派信息的不完整,不能跟上如今音乐更加多元化的发展趋势。此外,svm分类器受噪点影响较大的问题,在对音乐流派分类上也没有得到很好的解决。
技术实现要素:
本发明提供了一种基于特征加权模糊支持向量机的音乐流派分类方法及系统,该发明考虑到了不同权重的特征对分类的贡献程度的不同,能够很好的降低噪点影响;对在盲区的不可分点的多类别概率划分,符合当下音乐多元化的实质。
本发明的技术方案是:一种基于特征加权模糊支持向量机的音乐流派分类方法,包括:
特征权重的计算及特征选择步骤,先将原始音乐数据集归一化处理并分为归一化音乐训练集和归一化音乐测试集,然后在归一化音乐训练集上使用relieff特征选择算法得到各个特征的权重,将特征权重按照从大到小累加直到超过所有特征权重之和的设定比值,将剩余未被累加的特征移除得到最终的音乐训练集和音乐测试集;其中,原始音乐数据集包含类别属性和特征属性;
隶属度确定步骤,求出最终的音乐训练集按照类别属性下的各个类中心,并基于音乐训练集里的每个音乐训练样本到所属类的类中心的加权欧式距离来确定每个训练样本的隶属度;
分类模型的训练步骤,将最终的音乐训练集按照一类对其余的方式分组,并由隶属度确定步骤得到的各训练样本的隶属度作为各训练样本在构造最优分类面判别式的惩罚系数,对每组分别求出最优分类面,将各组最优分类面合并作为最终的分类模型;
音乐流派分类步骤,将最终的音乐测试集代入分类模型,如果音乐测试集中的测试样本落入相应的类别,则输出测试样本所对应的音乐流派类别结果;如果测试集中的测试样本散落在分类模型得出的不可分区域,则该测试样本作为不可分点,针对不可分点,按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,类别概率低于设定最小类别概率阈值的类别标签被剔除,并将剩余类别类别概率重新百分比计算并按类别概率从大到小排序,以此作为该不可分点的类别概率输出结果;其中,不可分区域为不可让样本落入唯一类别的区域。
所述特征权重的计算及特征选择步骤,具体为:
原始音乐数据集包含类别属性和特征属性,针对原始音乐数据集的各特征属性分别采用0均值归一化的方法进行归一化、原始音乐数据集的类别属性不变,得到归一化音乐数据集,将归一化音乐数据集按照1:1的比例拆分为归一化音乐训练集和归一化音乐测试集;
采用relieff特征选择算法对归一化音乐训练集进行特征权重计算,得到每一个特征的特征权重;
将特征权重按照从大到小排序,依次累加直到超过所有特征权重之和的80%,将剩余特征权重对应的特征在归一化音乐训练集和归一化音乐测试集上移除,得到最终的音乐训练集和音乐测试集。
所述隶属度确定步骤,具体为:
分别对最终的音乐训练集里的每个类别,求取该类别内所有样本分别在各个特征上的平均值,以此作为该类别的类中心;
分别对音乐训练集里的每个类别,求取该类别里各个样本到该类别中心的加权欧氏距离;
分别对音乐训练集里的每个类别,取该类别下的最大加权欧式距离作为该类别特征空间超球体半径,将该类别里各个样本到该类别中心的加权欧氏距离与该类别特征空间超球体半径的作除,将数值1与作除的结果作差来确定该类别下各个样本的隶属度。
所述分类模型的训练步骤,具体为:
先将最终的音乐训练集按照一类对其余的方式分组,假设共有c个类别,第一组把类别1的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,第二组把类别2的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,以此类推共分为c组;
采用模糊支持向量机思想,将隶属度确定步骤得到的每个音乐训练样本的隶属度,作为各训练样本在分别构造c个类别的最优分类面判别式的惩罚系数;
对每组训练集分别求出该组正类对应的类别的最优分类面,将各组最优分类面合并作为最终的分类模型。
所述按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,具体为:按照
一种基于特征加权模糊支持向量机的音乐流派分类系统,包括:
特征权重的计算及特征选择装置,用于先将原始音乐数据集归一化处理并分为归一化音乐训练集和归一化音乐测试集,然后在归一化音乐训练集上使用relieff特征选择算法得到各个特征的权重,将特征权重按照从大到小累加直到超过所有特征权重之和的设定比值,将剩余未被累加的特征移除得到最终的音乐训练集和音乐测试集;其中,原始音乐数据集包含类别属性和特征属性;
隶属度确定装置,用于求出最终的音乐训练集按照类别属性下的各个类中心,并基于音乐训练集里的每个音乐训练样本到所属类的类中心的加权欧式距离来确定每个训练样本的隶属度;
分类模型的训练装置,用于将最终的音乐训练集按照一类对其余的方式分组,并由隶属度确定装置得到的各训练样本的隶属度作为各训练样本在构造最优分类面判别式的惩罚系数,对每组分别求出最优分类面,将各组最优分类面合并作为最终的分类模型;
音乐流派分类装置,用于将最终的音乐测试集代入分类模型,如果音乐测试集中的测试样本落入相应的类别,则输出测试样本所对应的音乐流派类别结果;如果测试集中的测试样本散落在分类模型得出的不可分区域,则该测试样本作为不可分点,针对不可分点,按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,类别概率低于设定最小类别概率阈值的类别标签被剔除,并将剩余类别类别概率重新百分比计算并按类别概率从大到小排序,以此作为该不可分点的类别概率输出结果;其中,不可分区域为不可让样本落入唯一类别的区域。
所述特征权重的计算及特征选择装置,具体用于:
原始音乐数据集包含类别属性和特征属性,针对原始音乐数据集的各特征属性分别采用0均值归一化的方法进行归一化、原始音乐数据集的类别属性不变,得到归一化音乐数据集,将归一化音乐数据集按照1:1的比例拆分为归一化音乐训练集和归一化音乐测试集;
采用relieff特征选择算法对归一化音乐训练集进行特征权重计算,得到每一个特征的特征权重;
将特征权重按照从大到小排序,依次累加直到超过所有特征权重之和的80%,将剩余特征权重对应的特征在归一化音乐训练集和归一化音乐测试集上移除,得到最终的音乐训练集和音乐测试集。
所述隶属度确定装置,具体用于:
分别对最终的音乐训练集里的每个类别,求取该类别内所有样本分别在各个特征上的平均值,以此作为该类别的类中心;
分别对音乐训练集里的每个类别,求取该类别里各个样本到该类别中心的加权欧氏距离;
分别对音乐训练集里的每个类别,取该类别下的最大加权欧式距离作为该类别特征空间超球体半径,将该类别里各个样本到该类别中心的加权欧氏距离与该类别特征空间超球体半径的作除,将数值1与作除的结果作差来确定该类别下各个样本的隶属度。
所述分类模型的训练装置,具体用于:
先将最终的音乐训练集按照一类对其余的方式分组,假设共有c个类别,第一组把类别1的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,第二组把类别2的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,以此类推共分为c组;
采用模糊支持向量机思想,将隶属度确定装置得到的每个音乐训练样本的隶属度,作为各训练样本在分别构造c个类别的最优分类面判别式的惩罚系数;
对每组训练集分别求出该组正类对应的类别的最优分类面,将各组最优分类面合并作为最终的分类模型。
所述按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,具体为:按照
本发明的有益效果是:本发明的分类器选择模糊支持向量机,能够根据不同输入样本对分类贡献的不同,赋以相应隶属度,目的在于能够很好的减少噪声的影响;用relieff特征选择算法计算出的各特征权重,用于对模糊支持向量机的隶属度的确定方法,考虑到了不同权重的特征对分类影响大小的不同;针对盲区不可分点,用该点到各个类中心的加权欧氏距离进行多类别概率划分,符合当下音乐多元化的实质。
附图说明
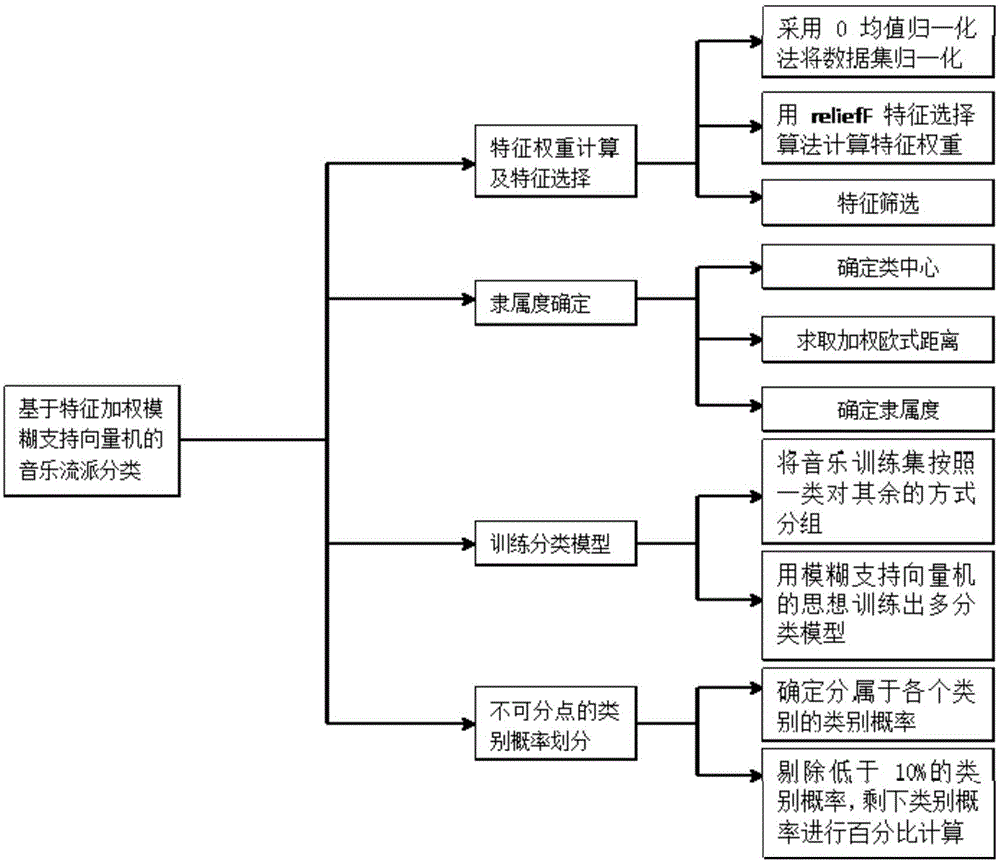
图1是基于模糊支持向量机的音乐流派分类方法模块图;
图2是特征权重计算及特征选择流程图;
图3是隶属度确定模块图;
图4是模型训练模块图;
图5不可分点的划分流程图;
图6是支持向量机不可分区域的展示图。
具体实施方式
实施例1:如图1所示,一种基于特征加权模糊支持向量机的音乐流派分类方法,包括:
s1、特征权重的计算及特征选择步骤,先将原始音乐数据集归一化处理并分为归一化音乐训练集和归一化音乐测试集,然后在归一化音乐训练集上使用relieff特征选择算法得到各个特征的权重,将特征权重按照从大到小累加直到超过所有特征权重之和的设定比值,将剩余未被累加的特征移除得到最终的音乐训练集和音乐测试集;其中,原始音乐数据集包含类别属性和特征属性;
s2、隶属度确定步骤,求出最终的音乐训练集按照类别属性下的各个类中心,并基于音乐训练集里的每个音乐训练样本到所属类的类中心的加权欧式距离来确定每个训练样本的隶属度;
s3、分类模型的训练步骤,将最终的音乐训练集按照一类对其余的方式分组,并由隶属度确定步骤得到的各训练样本的隶属度作为各训练样本在构造最优分类面判别式的惩罚系数,对每组分别求出最优分类面,将各组最优分类面合并作为最终的分类模型;
s4音乐流派分类步骤,将最终的音乐测试集代入分类模型,如果音乐测试集中的测试样本落入相应的类别,则输出测试样本所对应的音乐流派类别结果;如果测试集中的测试样本散落在分类模型得出的不可分区域,则该测试样本作为不可分点,针对不可分点,按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,类别概率低于设定最小类别概率阈值的类别标签被剔除,并将剩余类别类别概率重新百分比计算并按类别概率从大到小排序,以此作为该不可分点的类别概率输出结果(指这些不可分点的测试样本会输出保留类别下的类别概率输出结果);其中,不可分区域为不可让样本落入唯一类别的区域。
进一步地,可以设置步骤s1中,所述特征权重的计算及特征选择步骤(参见图2),具体为:
步骤s101:原始音乐数据集包含类别属性和特征属性,针对原始音乐数据集的各特征属性分别采用0均值归一化的方法进行归一化、原始音乐数据集的类别属性不变,得到归一化音乐数据集,将归一化音乐数据集按照1∶1的比例拆分为归一化音乐训练集和归一化音乐测试集:
给定原始音乐数据集j共有c个类别,数据集包含类别属性以及音色、节奏、基因频率等相关的音频声学特征t,特征数为n,tj表示第j个特征,j=1,2,...,n。
由于特征属性上存在量纲的不同,针对原始音乐数据集的各特征属性分别采用0均值归一化的方法进行归一化,计算公式如下:
步骤s102,采用relieff特征选择算法对归一化音乐训练集进行特征权重计算,得到每一个特征的特征权重:
1)、训练集为d,特征总个数n,设样本抽样次数m,最近邻样本个数r,各个特征的特征权重集w初始化置为0。
2)、一次抽样更新权值的算法如下:
a、从d中随机选择一个样本x;
b、从x的同类样本集中找到x的r个最近样本集h,ha表示同类样本集的第a个样本,a=1,2,...,r;从x的每一个不同类样本集中找到r个最近邻样本集f,fk表示从第k类样本集找到的r个最近邻样本集,fk,b表示第k类样本集的第b个样本,b=1,2,...,r。
c、对特征权重集w,计算一次抽样下每个特征的特征权值的更新,公式如下:
其中wj表示第j个特征的特征权重,class(x)表示样本x拥有的类标签,diff(tj,x.ha)是样本x和ha在特征tj上的距离(a=1,2,...,r),diff(tj,r,fk,b)是样本x和fk,b在特征tj上的距离(b=1,2,...,r)。pk表示第k类样本在归一化音乐训练集d中出现的概率,p(class(x))表示样本x所属类在归一化音乐训练集d中出现的概率。
3)、m次抽样下,将n个特征的特征权重更新m次。
步骤s103,将特征权重按照从大到小排序,依次累加直到超过所有特征权重之和的80%,剩余特征权重对应的特征被移除,剩余n′个特征的特征权重集w′,wj′表示降维后特征权重集的第j个特征的特征权值(j=1,2,...,n′),归一化音乐训练集d和归一化音乐测试集g经过特征降维得到最终的音乐训练集d′和音乐测试集g′。
进一步地,可以设置步骤s2中,所述隶属度确定步骤(参见图3),具体为:
步骤s2中,分别对最终的音乐训练集里的每个类别,求取该类别内所有样本分别在各个特征上的平均值,以此作为该类别的类中心:对音乐数据集的第k个类别对应的训练集d′k,求该类别里所有数据分别在n′个特征上的平均值,n′个特征平均值构成的点称为第k个类别的类中心,用ok表示。按照上述方式对训练集求取所有类的类中心。
步骤s202,分别对音乐训练集里的每个类别,求取该类别里各个样本到该类别中心的加权欧氏距离:对音乐训练集的第k个类别的训练集d′k,计算该类别里所有数据到第k类类中心ok的加权欧氏距离,d′k内一个样本用x′k表示,其到第k类类中心ok的加权欧式距离计算公式如下:
步骤s203,分别对音乐训练集里的每个类别,取该类别下的最大加权欧式距离作为该类别特征空间超球体半径,将该类别里各个样本到该类别中心的加权欧氏距离与该类别特征空间超球体半径的作除,将数值1与作除的结果作差来确定该类别下各个样本的隶属度:对音乐数据集的第k个类别的训练集d′k,取d′k的所有样本各自到类中心ok加权欧式距离的最大距离dkmax,以此作为第k类别的特征空间超球体半径。按照上一步的方法,分别对所有类求取特征空间超球体半径。不失为一般性,仍对于训练集d′k内一个样本x′k,根据如下公式计算x′k属于第k类别的隶属度:
进一步地,可以设置步骤s3中,所述分类模型的训练步骤(参见图4),具体为:
步骤s301,先将最终的音乐训练集按照一类对其余的方式分组,假设共有c个类别,第一组把类别1的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,第二组把类别2的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,以此类推共分为c组;
步骤s302,采用模糊支持向量机思想,将隶属度确定步骤得到的每个音乐训练样本的隶属度,作为各训练样本在分别构造c个类别的最优分类面判别式的惩罚系数:为方便理解,以下针对第一组构造模糊支持向量机的过程进行阐述,第一组训练集的正类样本为类别为1的训练样本,其余类别下的训练样本合起来定为负样本。第一组总样本个数为n。模糊支持向量机是在支持向量机基础上提出来的,在支持向量机方法中,最优分类面的训练结果允许数据点存在偏移,因此在最终优化问题的目标函数引入了松弛变量对应数据点允许的偏移量,并为了限制其取值加入了惩罚因子c,惩罚因子越大则对偏移样本的约束程度就越大,说明对应的这个样本产生偏移对计算出最优分类面的影响越大,支持向量机在这一过程对所有的松弛变量都使用共同的惩罚因子。模糊支持向量机根据每一个训练样本对分类的贡献程度不同给其赋予相应的隶属度,通过隶属度控制惩罚因子,隶属度越小对应惩罚因子越小,对模型的训练影响就越小,则噪点数据被赋予很小的隶属度就可以减少噪点数据对最优分类面构造的影响。
模糊支持向量机的目标函数如下:
s.t.yi[(w*x)+b]≥1-ξi,ξi≥0(i=1,2,...,n)
其中,w为最优分类面的线性系数,b为偏置,ψi为步骤s2的隶属度确认方法分别求出来的每个音乐训练样本的隶属度,cψi为隶属度控制下的惩罚因子。
求解上述目标函数,需要将其转化为一个对偶问题,在以下步骤中用到的核函数为svm常用的高斯径向基核函数k<xi,xj>,k〈xi,xj>表示任意两个训练样本xi与训练样本xj在高斯径向基核函数下的内积,具体的对偶问题如下:
求出拉格朗日乘子αi和偏置b,得到最优分类面的决策函数:
其中,yi表示第i个模糊样本是否属于第1类,属于则为1,不属于则为-1,k〈xi,xj>表示任意两个训练样本xi与训练样本xj在高斯径向基核函数下的内积,b为求出的偏置。
步骤s303,对每组训练集分别求出该组正类对应的类别的最优分类面,将各组最优分类面合并作为最终的分类模型:
由以上s302步骤,求出了第一组训练集下的决策函数,也即第一个类别的最优分类面,以此类推分别求出其余类别的最优分类面,所有的分类面一起构成了最终的多分类模型。
音乐测试集的一个测试样本则通过分别代入各个类别的决策函数,通过各类别对应的f(x)值是否为正来判断是否属于该类别(f(x)大于0,则属于;否则不属于)。
由于可能存在着不可让样本落入唯一类别的区域不可分区域,如图6所示的阴影部分,需要进一步的划分。
进一步地,可以设置步骤s4,不可分点的类别概率划分(参见图5),具体为:
音乐测试集在不可分区域上的数据,表征为其流派信息不显著划定为一具体的流派,因此考虑对其做多类别概率划分,从而更为完整的确定其流派信息。
步骤s401,在采用一对多策略求出来的分类模型,存在着不可让样本落入唯一类别的区域不可分区域,而分布在这些区域的测试样本都是不可分点,针对这些不可分点,按照其到各个类中心的加权欧氏距离之间的比值关系来确定分属于各个类别的类别概率:
首先,对于不可分区域内的一个不可分点x#,求其到每个类中心的加权欧氏距离,沿用步骤s202里的加权欧氏距离计算公式,到第k个类别类中心ok的加权欧氏距离用
为区别于前述训练集各个样本隶属度计算公式,在此不可分区域内的一个不可分点x#分属于各个类别的程度用类别概率这一概念描述;则,加权欧式距离越大对应的类别概率越小,对应的属于各个类别的程度大小关系正比于距离长度倒数的平方关系,到所有的类中心的加权欧式距离最大的对应的类别概率最小,加权欧式距离的最大值用
由上将不可分点x#分别属于c个类的类别概率相加且和为1,用百分比表示即为100%,公式表述如下:
步骤s402,设定一个最小类别概率阈值,类别概率低于该阈值的类别标签被剔除,并将剩余类别类别概率重新百分比计算并按类别概率从大到小排序,以此作为该不可分点的类别概率输出结果:
设定一个最小类别概率阈值10%,类别概率低于该阈值的类别都被剔除。
计算剩下类别概率占剩下类别概率总和的百分比,并按照从大到小的顺序输出。
如不可分点x#,类别概率大于10%的类别有β个,对应的β个类别用y1…yβ表示,这β个类别概率再分别计算所占剩下类别概率总和的百分比,计算之后的类别概率用
一种基于特征加权模糊支持向量机的音乐流派分类系统,包括:特征权重的计算及特征选择装置,用于先将原始音乐数据集归一化处理并分为归一化音乐训练集和归一化音乐测试集,然后在归一化音乐训练集上使用relieff特征选择算法得到各个特征的权重,将特征权重按照从大到小累加直到超过所有特征权重之和的设定比值,将剩余未被累加的特征移除得到最终的音乐训练集和音乐测试集;其中,原始音乐数据集包含类别属性和特征属性;隶属度确定装置,用于求出最终的音乐训练集按照类别属性下的各个类中心,并基于音乐训练集里的每个音乐训练样本到所属类的类中心的加权欧式距离来确定每个训练样本的隶属度;分类模型的训练装置,用于将最终的音乐训练集按照一类对其余的方式分组,并由隶属度确定装置得到的各训练样本的隶属度作为各训练样本在构造最优分类面判别式的惩罚系数,对每组分别求出最优分类面,将各组最优分类面合并作为最终的分类模型;音乐流派分类装置,用于将最终的音乐测试集代入分类模型,如果音乐测试集中的测试样本落入相应的类别,则输出测试样本所对应的音乐流派类别结果;如果测试集中的测试样本散落在分类模型得出的不可分区域,则该测试样本作为不可分点,针对不可分点,按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,类别概率低于设定最小类别概率阈值的类别标签被剔除,并将剩余类别类别概率重新百分比计算并按类别概率从大到小排序,以此作为该不可分点的类别概率输出结果;其中,不可分区域为不可让样本落入唯一类别的区域。
进一步地,可以设置所述特征权重的计算及特征选择装置,具体用于:原始音乐数据集包含类别属性和特征属性,针对原始音乐数据集的各特征属性分别采用0均值归一化的方法进行归一化、原始音乐数据集的类别属性不变,得到归一化音乐数据集,将归一化音乐数据集按照1∶1的比例拆分为归一化音乐训练集和归一化音乐测试集;采用relieff特征选择算法对归一化音乐训练集进行特征权重计算,得到每一个特征的特征权重;将特征权重按照从大到小排序,依次累加直到超过所有特征权重之和的80%,将剩余特征权重对应的特征在归一化音乐训练集和归一化音乐测试集上移除,得到最终的音乐训练集和音乐测试集。
进一步地,可以设置所述隶属度确定装置,具体用于:分别对最终的音乐训练集里的每个类别,求取该类别内所有样本分别在各个特征上的平均值,以此作为该类别的类中心;分别对音乐训练集里的每个类别,求取该类别里各个样本到该类别中心的加权欧氏距离;分别对音乐训练集里的每个类别,取该类别下的最大加权欧式距离作为该类别特征空间超球体半径,将该类别里各个样本到该类别中心的加权欧氏距离与该类别特征空间超球体半径的作除,将数值1与作除的结果作差来确定该类别下各个样本的隶属度。
进一步地,可以设置所述分类模型的训练装置,具体用于:先将最终的音乐训练集按照一类对其余的方式分组,假设共有c个类别,第一组把类别1的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,第二组把类别2的训练样本定为正样本,其余类别下的训练样本合起来定为负样本,以此类推共分为c组;采用模糊支持向量机思想,将隶属度确定装置得到的每个音乐训练样本的隶属度,作为各训练样本在分别构造c个类别的最优分类面判别式的惩罚系数;对每组训练集分别求出该组正类对应的类别的最优分类面,将各组最优分类面合并作为最终的分类模型。
进一步地,可以设置所述按照其到各个类中心的加权欧氏距离来确定分属于各个类别的类别概率,具体为:按照
上面结合图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!