基于决策树的数控车床车削过程能耗预测系统的制作方法
本发明涉及机床控制系统技术领域,尤其涉及一种基于决策树的数控车床车削过程能耗预测系统。
背景技术:
目前,对数控车床的车削过程能耗的预测还没有形成比较统一的技术体系。传统的方法主要是有经验的操作工依据经验和操作手册综合选择合适的车削参数,或者通过现场切削实验或者监测加工过程来合理选择车削参数。这种方法受工人的主观因素、具体的车床种类以及加工方法、加工对象不同的影响而差异很大,无法大规模普及。有学者提出各种不同的假设和理论模型,将多种数学方法应用于数控车床的车削过程能耗的预测中,如支持向量机法、神经网络法等。不可否认这些方法虽然取得了一定的成果,但各有其不足之处。
现有的支持向量机法,借助二次规划来求解支持向量时涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。此外,经典的支持向量机法只给出了二类分类的算法,对于数据挖掘的实际应用中涉及的多类分类问题需要结合其他算法加以解决,比较复杂。
现有的神经网络法,存在样本数据训练时间长甚至完全不能训练的情况。此外,存在样本训练过程中学习新样本时有遗忘旧样本的趋势。
技术实现要素:
本发明的目的是针对现有技术存在的问题,提供一种基于决策树的数控车床车削过程能耗预测系统,利用数据挖掘技术中的决策树算法,充分衡量各种因素对数控车床车削过程能耗的影响,建立各车削参数与车削过程能耗的定量关系,从而建立能耗决策树预测模型,来进行数控机床车削过程的能耗预测。
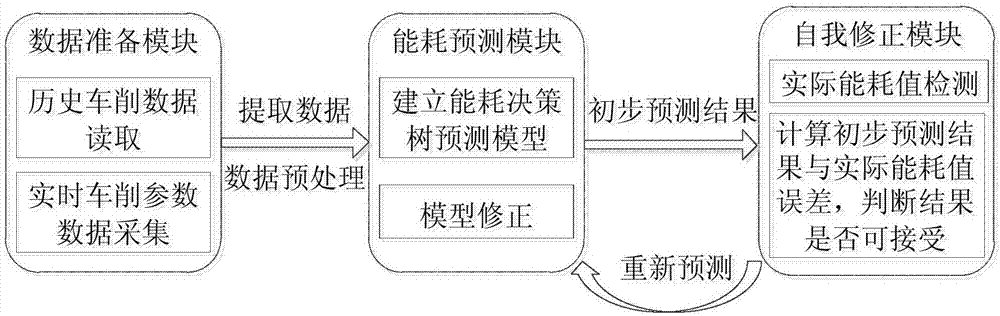
为实现上述目标,本发明采用的技术方案如下:所述的基于决策树的数控车床车削过程能耗预测系统包括数据准备模块、能耗预测模块、自我修正模块,其中,数据准备模块主要包括历史车削能耗数据读取模块以及实时车削参数数据采集模块两大部分,从车削参数数据库中选取包括刀具类型、主轴转速、进给量和切削深度在内的主要参数属性构成属性集作为评价指标,对从车削参数数据库中提取的各参数属性值以及实时检测的各参数属性值进行预处理,并将连续型属性离散化,转换成调用决策树算法所需的数据格式,再传送至能耗预测模块;数据准备模块的工作完成后,实时车削参数数据采集模块与能耗预测模块协同工作,调用决策树算法,计算各参数属性的信息增益率,选取信息增益率最大的属性作为决策树的根结点,再由该属性的不同取值建立分支,调用此方法建立决策树各节点的分支,直到所有子集只包含同一类别的数据为止,建立车削过程能耗决策树预测模型;然后对模型进行修正,以提高模型预测精度,输出初步的能耗预测结果;得到初步的能耗预测结果后,自我修正模块与能耗预测模块协同工作,对初步预测结果进行修正,得到最终的预测结果。
进一步的,在数据准备阶段,从车削参数数据库依据历史车削参数与车削能耗的关系,获取大量已知的样本基础数据构成样本集,然后将样本集划分为两类样本,一类用作训练样本集s,用于建立能耗决策树预测模型,一类作为测试样本集,用来对初步建立的能耗决策树预测模型中不正确的数据进行修正。
进一步的,训练样本集s中初步提取的各类车削参数都是具体的数值,具有连续属性,构成属性集a={a1,a2,...,an},表示属性集a中共有n个属性,每个属性aj具有t个不同的取值即aj={a1,a2,...,at},j=1,2...n,将训练样本集s划分为t个子集s={s1,s2,...,st},需要对属性aj,j=1,2...n中的连续属性值进行离散化处理,具体方法为:将属性aj,j=1,2...n中t个不同的取值按照从小到大的顺序依次排列,排列后的属性取值序列为b1、b2、...、bt,逐一求取两个相邻值的平均值
进一步的,计算出训练样本集s中每个参数属性的信息增益率的方法为:训练样本集s={s1,s2,...,sm},包含m个类ci,i=1,2,...,m,si为类ci中的样本数,将进行分类的需要的信息量记为i(s),则:
其中,pi为训练样本集s中任意样本属于类ci的概率。训练样本集s按照上述属性aj={a1,a2,...,at},j=1,2...n,的t个不同的取值划分成t个子集,记为s={s1,s2,...,st},其中,sj,j=1,2...t是s的子集,它们在属性aj,j=1,2...n上具有值aj,其中,aj为属性aj的第j个分量。则由属性aj,j=1,2...n划分子集的信息熵e(aj)可表示为:
则可得到由属性aj划分子集的信息增益g(aj)表示为:
g(aj)=i(s)-e(aj),j=1,2...t;
信息增益率等于信息增益对分割信息量的比值,由分割信息量计算公式:
得出最终则由属性aj划分子集的信息增益率gr(aj)表示为:
进一步的,建立能耗决策树预测模型的方法为:分别计算出训练样本集s中每个参数属性的信息增益率,选取具有最大信息增益率的属性作为测试属性,建立决策树的根结点,这样,将样本集划分为若干子集;采用同样的方法依次对子集进行新一轮的划分,直到不可划分或达到终止条件为止,建立初步的决策树预测模型;同时,将实时检测的车削参数数据代入决策树模型,结合历史数据,生成初步的预测结果,并将结果存入车削参数基础数据库中形成历史数据。
进一步的,对生成的能耗决策树预测模型进行修正的方法为:一方面,使用测试样本集对生成的能耗决策树中不正确的数据进行修正,另一方面,定时对样本进行更新以提高能耗决策树预测模型的准确性;可以选择具有典型特征的样本加入训练样本集中,而数据库中已有的重复的样本数据则无需加入,具体的操作方法如下:
设有p个样本的数据集e=(e1,e2...ep),其中心样本为et,t∈(1,2,...,p);设ei为待检测的数据样本即
其中,ei,
进一步的,所述自我修正模块内置实际的能耗探测装置,将能耗预测模块预测的初步预测结果与能耗探测装置实际检测到的能耗相比较,得到误差e;事先根据实际问题的要求,设置误差允许范围,当误差e在所设置的误差允许范围内时,则该预测结果被判断为可接受;当误差e不在误差允许范围时,自我修正模块将结果反馈到能耗预测模块,能耗预测模块结合所得的误差e,重新预测并重新计算新一轮的误差,重复上述过程直到得到的误差满足根据实际情况设置的判断标准;如此,通过自我修正模块对初步预测结果进行修正,将得到的修正量再与初步预测结果相结合,从而得到最终的预测结果。
与现有技术相比,本发明的有益效果为:
本发明充分考虑了各种因素对数控机床车削能耗的影响,利用数据挖掘技术中的决策树算法得到车削能耗与车削参数之间的定量关系,再与自我修正模块相结合,对初步预测结果进行修正,来进行数控机床车削过程的能耗预先测算,用于指导实际加工过程。此外,可根据实际情况不断更新模型,从而不断提高预测模型的预测精度,使操作者能够选择更加合理的车削参数,最终帮助企业提高加工效率。
附图说明
图1为本发明的数控机床车削过程能耗预测系统的结构示意图。
图2为本发明的数控机床车削过程能耗预测的流程图。
具体实施方式
下面结合附图对本发明进行详细说明。
如图1所示,本发明主要包括三大模块,具体分别为:数据准备模块、能耗预测模块、自我修正模块。其中,数据准备模块主要包含历史车削能耗数据读取以及实时车削参数数据采集两大模块,主要完成的任务是对各类数据进行预处理,将其转换成数据挖掘决策树算法所需的数据格式,再传送至能耗预测模块;数据准备模块的工作完成后,将实时车削参数数据采集模块与能耗预测模块结合,调用决策树算法,然后对模型进行修正,输出初步的能耗预测结果;自我修正模块具有自我学习和自我完善的功能,得到初步的能耗预测结果后,将数据传送至自我修正模块对初步预测结果进行修正,即可得到最终的预测结果。总体步骤为:
步骤一:数据准备模块完成历史车削能耗数据的读取以及实时车削参数数据的采集两大任务,并对所得的各类数据进行预处理,将其转换成数据挖掘决策树算法所需的数据格式后传送至能耗预测模块;
步骤二:步骤一中数据准备模块任务完成后,实时车削参数数据采集模块与能耗预测模块协同工作,调用决策树算法,建立车削过程能耗决策树预测模型;
步骤三:对步骤二中得到的能耗决策树预测模型进行修正,得到初步的预测结果;
步骤四:将步骤三中所得到的初步预测结果传送到自我修正模块,自我修正模块与能耗预测模块协同工作,对初步预测结果进行修正,得到最终的预测结果。
如图2所示,本发明进行数控车床车削过程能耗预测的步骤包括:
步骤1.1:数据准备模块从车削参数数据库中选取刀具类型、主轴转速、进给量和切削深度等主要参数属性构成属性集作为评价指标;
步骤1.2:对从车削参数数据库中提取的各参数属性值以及实时检测的各参数属性值进行预处理,并将连续型属性离散化,转换成调用决策树算法所需的数据格式,再传送至能耗预测模块;
步骤2:计算各参数属性的信息增益率,选取信息增益率最大的属性作为决策树的根结点,再由该属性的不同取值建立分支,调用此方法建立决策树各节点的分支,直到所有子集只包含同一类别的数据为止,建立车削过程能耗决策树预测模型;
步骤3:对步骤2中建立的能耗决策树预测模型进行修正,以提高模型预测精度,输出初步的能耗预测结果;
步骤4:将初步预测结果传送到自我修正模块,自我修正模块与能耗预测模块协同工作,对初步预测结果进行修正,得到最终的预测结果。
以下结合实施例对本发明的实施过程和原理进行进一步说明。
1、车削参数基础数据提取。
如图2所示,在数控机床车削过程能耗预测过程中,首先是数据准备阶段,即从车削参数数据库依据历史车削参数与车削能耗的关系,获取大量已知的样本基础数据构成样本集,然后将样本集划分为两类样本,一类用作训练样本集s,用于建立能耗决策树预测模型,一类作为测试样本集,用来对初步建立的能耗决策树预测模型中不正确的数据进行修正。由于原始数据中包含大量不完整的、含噪声的数据,必须对原始数据进行预处理以提高数据的质量,从而提高预测结果的准确性。
2、对训练样本集s中的连续属性值进行离散化处理,计算信息增益率。
训练样本集s中初步提取的各类车削参数都是具体的数值,具有连续属性,构成属性集a={a1,a2,...,an},表示属性集a中共有n个属性,每个属性aj具有t个不同的取值即aj={a1,a2,...,at},j=1,2...n,将训练样本集s划分为t个子集s={s1,s2,...,st},需要对属性aj,j=1,2...n中的连续属性值进行离散化处理,具体方法为:将属性aj,j=1,2...n中t个不同的取值按照从小到大的顺序依次排列,排列后的属性取值序列为b1、b2、...、bt,逐一求取两个相邻值的平均值
3、建立能耗决策树预测模型。
训练样本集s={s1,s2,...,sm},包含m个类ci,i=1,2,...,m,si为类ci中的样本数,将进行分类的需要的信息量记为i(s),则:
其中,pi为训练样本集s中任意样本属于类ci的概率。训练样本集s按照上述属性aj={a1,a2,...,at},j=1,2...n,的t个不同的取值划分成t个子集,记为s={s1,s2,...,st},其中,sj,j=1,2...t是s的子集,它们在属性aj,j=1,2...n上具有值aj,其中,aj为属性aj的第j个分量。则由属性aj,j=1,2...n划分子集的信息熵e(aj)可表示为:
则可得到由属性aj划分子集的信息增益g(aj)表示为:
g(aj)=i(s)-e(aj),j=1,2...t;
信息增益率等于信息增益对分割信息量的比值,由分割信息量计算公式:
得出最终则由属性aj划分子集的信息增益率gr(aj)表示为:
由此,分别计算出训练样本集s中每个参数属性的信息增益率,选取具有最大信息增益率的属性作为测试属性,建立决策树的根结点,这样,将样本集划分为若干子集。采用同样的方法依次对子集进行新一轮的划分,直到不可划分或达到终止条件为止,建立初步的能耗决策树预测模型。同时,将实时检测的车削参数数据代入决策树模型,结合历史数据,生成初步的预测结果,并将结果存入车削参数数据库中形成历史数据。
4、对生成的能耗决策树预测模型进行修正。
一方面,使用测试样本集对生成的能耗决策树中不正确的数据进行修正,另一方面,由于数控车床实际运行的车削参数可能发生变化,需要定时对样本进行更新以提高能耗决策树预测模型的准确性。鉴于样本数据非常庞大,可以选择具有典型特征的样本加入样本训练集中,而数据库中已有的重复的样本数据则无需加入,具体的操作方法如下:
设有p个样本的数据集e=(e1,e2...ep),其中心样本为et,t∈(1,2,...,p)。设ei为待检测的数据样本即
其中,ei,
5、自我修正模块对初步的能耗预测结果进行修正。
自我修正模块内置实际的能耗探测装置,建立的能耗修正模型具有学习和记忆的功能。将能耗预测模块预测的初步预测结果与能耗探测装置实际检测到的能耗相比较,得到误差e,事先根据实际问题的要求,设置合理的误差允许范围作为结果的判断标准,当误差e满足所设置的判断标准时,则该预测结果被判断为可接受;当误差e不满足判断标准时,自我修正模块将结果反馈到能耗预测模块,能耗预测模块结合所得的误差e,重新预测并重新计算新一轮的误差,重复上述过程直到得到的误差满足根据实际情况设置的判断标准。这样,通过反馈使得每次得到的初步预测结果不断得到修正,越来越接近能耗的真实值,从而提高预测的精度。如此,通过自我修正模块对初步预测结果进行修正,将得到的修正量再与初步预测结果相结合,从而得到最终的预测结果。
本发明提出了一种基于决策树的数控车床车削过程能耗预测系统及方法,主要包括如何获取车削参数训练样本集以及属性集,以及如何生成能耗决策树预测模型,并给出预测结果的修正方案,通过本发明的方法,能够有效指导数控车床车削过程合理选择车削参数,并且预测结果更准确,具有实用价值。
- 还没有人留言评论。精彩留言会获得点赞!