一种基于数据挖掘的学生孤僻程度预测方法与流程
本发明属于大数据应用领域,具体涉及一种基于数据挖掘的学生孤僻程度预测方法。
背景技术:
大学生作为一个特殊的社会文化群体,正处于人生发展的重要时期,有孤僻感的大学生不能与人保持正常的人际交往,是不健康的社会行为模式,是需要矫正的自我心理状态。本方法提供一种基于数据挖掘计算学生孤僻程度的方法,对孤僻程度较高的学生,给学校提供孤僻预警,同时给出与孤僻学生联系较为紧密的几个联系人,方便学校对孤僻学生进行及时、针对性的关怀。
通常学校采取思政指导教师来负责学生的思想工作,在学生中指派若干助手负责盯控学生思想动态,对学生的孤僻程度无法量化。
技术实现要素:
本发明的目的就在于为了合理量化学生孤僻程度,而提出一种基于数据挖掘的学生孤僻程度预测方法。
本发明通过以下技术方案来实现上述目的:
一种基于数据挖掘的学生孤僻程度预测方法,包括数据采集、计算每个学生的相关指数、将学生的相关指数生成指数矩阵并根据指数矩阵计算每个学生的孤僻指数;
通过分析学生一卡通刷卡数据、门禁数据,挖掘学生行为的频繁模式,提取学生行为的关联规则,给出学生与群体的人际关系指数。人际关系指数越高的,孤僻程度越低。人际关系指数越低的,孤僻程度则越高。
通过分析学生的家庭信息、消费数据,挖掘因家庭社会经济地位较低等造成的自觉低人一等,对集体没有认同感和归属感,没有自信,挖掘缺乏父母关爱造成的没有安全感,从而造成的孤僻。
通过调研分析学生的校园活动、社会公益活动参与情况,热爱集体活动的学生孤僻指数相对较低。
通过分析学生运动打卡数据,挖掘不爱运动的学生,认为运动指数较低的学生孤僻指数较高。
通过分析学生上网行为数据,观察学生心理状态积极指数,态度越积极,孤僻指数越低,态度越消极,孤僻指数越高。
其中数据采集具体为:
从一卡通数据中筛选近一个完整月的消费数据,提取学号、消费地点、刷卡机编号三个字段,以及近一个月的门禁刷卡记录,提取学号、刷卡机编号、刷卡时间三个字段;
从家庭信息表提取学号、家庭收入、是否单亲、是否孤儿、是否留守儿童四个字段;
从社会活动参与主统计数据中提取学号、活动总次数;
从运动打卡数据中提取学号、每次运动的时长;
从上网行为数据库中提取学号、上网时长、每次网络搜索的关键词。
其中相关指数包括:由一卡通数据得到的人际关系指数,由家庭收入数据计算得到的经济指数,由运动数据得到的运动指数,由社会活动参与统计数据得到社交指标,由上网数据统计得到的上网行为指数。
其中计算人际关系指数的方法为:
将一卡通数据按刷卡机编号、刷卡时间以天为单位进行切片,切片后计算该切片数据内每一个学生刷卡时,与另一个学生在1分钟内且操作顺序相邻的频率即支持度:
规则s1→s2的支持度等于s1,s2共同出现的次数σ与总事务数n比值
设置阈值t1,删除小于阈值的支持度数据。为避免产生虚假结果,设置刷卡率阈值,删除低于阈值的样本数据。认为低于阈值的样本量太少,不具有统计分析意义。刷卡率阈值需要通过观察数据分布来确定。对于刷卡次数少的学生可以考虑与孤僻相关的其他指标,这里我们只考虑正常刷卡学生的人际关系指标。
满足最小支持度阈值的所有项集称作频繁项集,产生频繁项集;
如图1,格结构常常用来表示所有可能的项集。发现频繁项集的一种原始方法是确定格结构中的每个候选项集,但这种方法的开销可能非常大。因为它需要进行n2次比较,其中n是事务数。
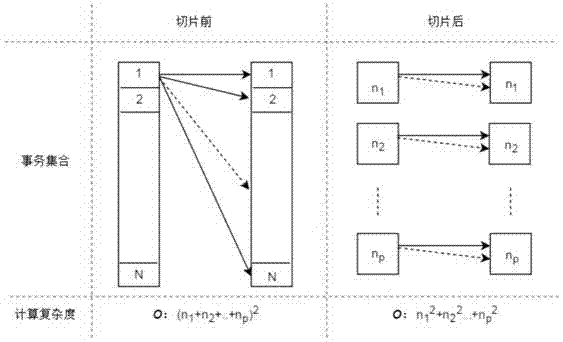
降低计算复杂度。模型假设认为两个学生在同一地点一分钟内一起刷卡的是同伴关系。通过对数据进行切片处理,减少比较次数,从而降低计算复杂度。在数据匹配时,先将数据按照刷卡地点、刷卡时间(以天为单位)进行切片,如图2,在数据进行循环匹配时,仅匹配同一片区内的数据,此时每个片区的计算复杂度为n2,其中n是片区p的事务数,n远小于事务数总数n。
此外,通过先筛选后计算降低复杂度。将数据划分好片区后,对相同片区进行数据全量匹配计算,这种计算方法对于食堂这种消费流水很大的片区,仍然会耗费很多计算时间。因此,采用先筛选后计算的方法,针对每一条刷卡记录,取该记录的时间前后各一分钟的时间点作为可选区间,从全量数据中筛选出该时间区间内的学号即可。
评判结果的可靠性,使用置信度进行度量,置信度计算公式:
输出结果为学号、同时刷卡的学号、两个学生之间的置信度3个字段,设置阈值t2,置信度高于t2则认为是学生的亲密联系人,将每位学生的亲密联系人置信度累加,得到该学生的人际关系指标绝对值;
将人际关系指标绝对值进行归一化,计算方法为:
其中max为所有学生中最高的人际关系指标绝对值,min为所有学生最低的人际关系指标绝对值,x为该学生人际关系指标绝对值,x’即为计算结果,人际关系指数,接近1则表示人际关系差。
其中计算经济指数的方法为:
设定权值w1、w2,家庭贫困程度f=家庭收入*w1+近一个月的一卡通消费总金额*w2,对贫困指标进行归一化
其中计算关爱指数的方法为:
将分类变量单亲、孤儿、留守儿童做哑变量转换,得到三列0、1数值变量。构造关爱变量g,关爱值=单亲+孤儿+留守儿童,归一化处理:
其中计算运动指数的方法为:
根据学生运动详细时间,计算学生运动时长t,并进行归一化处理
其中计算上网行为指数的方法为:
自定义孤僻词库,统计上网行为中出现孤僻相关词的频率nc,归一化
其中计算社会参与指数的方法为:
得到所有学生中最大活动次数,最小活动次数,将每个学生的活动次数进行归一化,得到社会参与指数,该指数越大,越孤僻:
最后一步计算孤僻指数的方法为:
将人际关系指数、经济指数、关爱指数、社会参与指数、运动指数、上网为指数组成矩阵a,a的元素为aij。
标准化a:各指标aij转换成aij’,有aij’=(aij-uj)/sj,i=1,2,...,n,j=1,2,...,m
转化后的矩阵记为
求解已标准化矩阵
计算贡献率
其中y1是第一主成分,ys是第s主成分
计算主成分孤僻指数
对于得分最高的一部分人,可以根据其在人际关系指数计算时的得到的亲密联系人,由其进行关照或者慰问,询问状况针对性进行教育。
本发明有益效果在于,本方法提供一种基于数据挖掘计算学生孤僻程度的方法,对孤僻程度较高的学生,给学校提供孤僻预警;
基于主成分分析的孤僻影响因子权重计算,各主成分的权数为其贡献率,它反映了该主成分包含原始数据的信息量占全部信息量的比重,这样确定权数是客观的、合理的,能够克服某些评价方法中人为确定权重的缺陷;
在计算关联规则时,本方法提出了一种新的降低复杂度的切片处理方法,减少了匹配计算的时间。
附图说明
图1是本发明关联规则项集示意图;
图2是本发明切片处理前后计算复杂度对比图;
图3是本发明主算法的计算流程图。
具体实施方式
下面结合附图对本申请作进一步详细描述,有必要在此指出的是,以下具体实施方式只用于对本申请进行进一步的说明,不能理解为对本申请保护范围的限制,该领域的技术人员可以根据上述申请内容对本申请作出一些非本质的改进和调整。
实施例:
对某校学生进行孤僻程度预测,包括以下步骤:数据采集、计算每个学生的相关指数、将学生的相关指数生成指数矩阵并根据指数矩阵计算每个学生的孤僻指数;
其中相关指数包括:由一卡通数据得到的人际关系指数,由家庭收入数据计算得到的经济指数,由运动数据得到的运动指数,由社会活动参与统计数据得到社交指标,由上网数据统计得到的上网行为指数。
其中数据采集具体为:
从一卡通数据中筛选近一个完整月的消费数据,提取学号、消费地点、刷卡机编号三个字段,以及近一个月的门禁刷卡记录,提取学号、刷卡机编号、刷卡时间三个字段;
从家庭信息表提取学号、家庭收入、是否单亲、是否孤儿、是否留守儿童四个字段;
从社会活动参与主统计数据中提取学号、活动总次数;
从运动打卡数据中提取学号、每次运动的时长;
从上网行为数据库中提取学号、上网时长、每次网络搜索的关键词。
其中计算人际关系指数的方法为:
将一卡通数据按刷卡机编号、刷卡时间以天为单位进行切片,切片后计算该切片数据内每一个学生刷卡时,与另一个学生在1分钟内且操作顺序相邻的频率即支持度:
规则s1→s2的支持度等于s1,s2共同出现的次数σ与总事务数n比值
设置阈值t1,删除小于阈值的支持度数据;
满足最小支持度阈值的所有项集称作频繁项集,产生频繁项集;
评判结果的可靠性,使用置信度进行度量,置信度计算公式:
输出结果为学号、同时刷卡的学号、两个学生之间的置信度3个字段,设置阈值t2,置信度高于t2则认为是学生的亲密联系人,将每位学生的亲密联系人置信度累加,得到该学生的人际关系指标绝对值;
将人际关系指标绝对值进行归一化,计算方法为:
其中max为所有学生中最高的人际关系指标绝对值,min为所有学生最低的人际关系指标绝对值,x为该学生人际关系指标绝对值,x’即为计算结果,人际关系指数,接近1则表示人际关系差。
其中计算经济指数的方法为:
设定权值w1、w2,家庭贫困程度f=家庭收入*w1+近一个月的一卡通消费总金额*w2,对贫困指标进行归一化
其中计算关爱指数的方法为:
将分类变量单亲、孤儿、留守儿童做哑变量转换,得到三列0、1数值变量。构造关爱变量g,关爱值=单亲+孤儿+留守儿童,归一化处理:
其中计算运动指数的方法为:
根据学生运动详细时间,计算学生运动时长t,并进行归一化处理
其中计算上网行为指数的方法为:
自定义孤僻词库,统计上网行为中出现孤僻相关词的频率nc,归一化
其中计算社会参与指数的方法为:
得到所有学生中最大活动次数,最小活动次数,将每个学生的活动次数进行归一化,得到社会参与指数,该指数越大,越孤僻:
最终计算孤僻指数:
将人际关系指数、经济指数、关爱指数、社会参与指数、运动指数、上网为指数组成矩阵a,a的元素为aij。
标准化a:各指标aij转换成aij’,有aij’=(aij-uj)/sj,i=1,2,...,n,j=1,2,...,m
转化后的矩阵记为
求解已标准化矩阵
计算贡献率
其中y1是第一主成分,ys是第s主成分
计算主成分孤僻指数
以上所述实施例仅表达了本发明的一种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!