一种用于淡水水生生物水质基准预测的系统的制作方法
本发明涉及水质基准预测技术领域,具体涉及一种用于淡水水生生物水质基准预测的系统。
背景技术:
水质基准是指水环境中的污染物质或有害因素对人体健康、水生态系统与使用功能不产生有害效应的最大剂量或水平。淡水水生生物水质基准(freshwaterqualitycriteriafortheprotectionofaquaticorganisms)是指能够保护淡水水生生物及其生态功能的水质基准,包括短期水质基准和长期水质基准。
水生生物水质基准是保护水生生物物种多样性及充分发挥水生生物群落生态功能的保证,是制定水环境管理目标及措施的重要依据。目前用于推导淡水水生生物水质基准的方法主要有评价因子法、物种敏感度分布曲线法及毒性百分数排序法。
评价因子法的优点是简单易行,所需数据量少且适用范围广,但由于评价因子法推导出的基准值仅取决于最敏感物种的毒性数据且评价因子的确定通常是从经验出发,因此结果的准确性存在较大的不确定因素。此外,评价因子法也未考虑物种间的关系以及污染物的生物富集效应等。
毒性百分数排序法综合考虑了污染物的多种环境行为及环境毒理学因素,包括急性、慢性毒性效应,生物体内的富集效应以及物种间的相互联系,因此毒性百分数排序法能够更全面地反映污染物对水生生物的影响,但由于在运用该方法推导最大浓度基准和连续浓度基准时要求包括3门、8科水生生物的大量毒性数据,从而计算相关的累积概率,在此基础上再严格筛选其中累积概率接近0.05的4个属的急性及慢性毒性数据,据此推导出水质基准。该方法所需数据量大,但最终仅选择其中4个属的数据进行分析,未充分利用所收集的数据,也不能将各种生物按照营养级的相互关系进行综合考虑,因此仍不能全面表征污染物对整个生态系统的不利影响。
物种敏感度分布曲线法可通过有限的毒理学数据有效地表征污染物对整个生态系统的影响,但物种敏感度分布曲线法与评价因子法一样,也未考虑生物体内的富集效应,采用物种敏感度分布曲线法推导基准值时,毒性数据量越多,曲线拟合的结果越好,评价结果的可靠性也越高,因此当毒性数据量较充分时宜选用该方法,而当毒性数据少于5个时则不能采用物种敏感度分布曲线法。
现有技术中用于推导淡水水生生物水质基准的方法不适合个人和单位建立模型,用于拟合水质基准研究需要的污染物毒性数据的概率分布,并计算指定累积概率条件下的污染物质浓度,不具备输出模型拟合优度的检验参数的功能。
cn201710618844.6公开了一种用于淡水水生生物水质基准预测的系统,其公开了根据模型的拟合优度评价参数分别评价逻辑斯谛分布模型、正态分布模型或极值分布模型的拟合度,但其未公开具体的评价方法。
技术实现要素:
为了克服现有技术中存在的问题,本发明提供一种用于淡水水生生物水质基准预测的系统,该系统适合个人和单位建立模型,用于拟合水质基准研究需要的污染物毒性数据的概率分布,并计算指定累积概率条件下的污染物质浓度,具备输出模型拟合优度的检验参数的功能,并且能够高效选出最优模型。
为实现上述目的,本发明所述的用于淡水水生生物水质基准预测的系统包括:
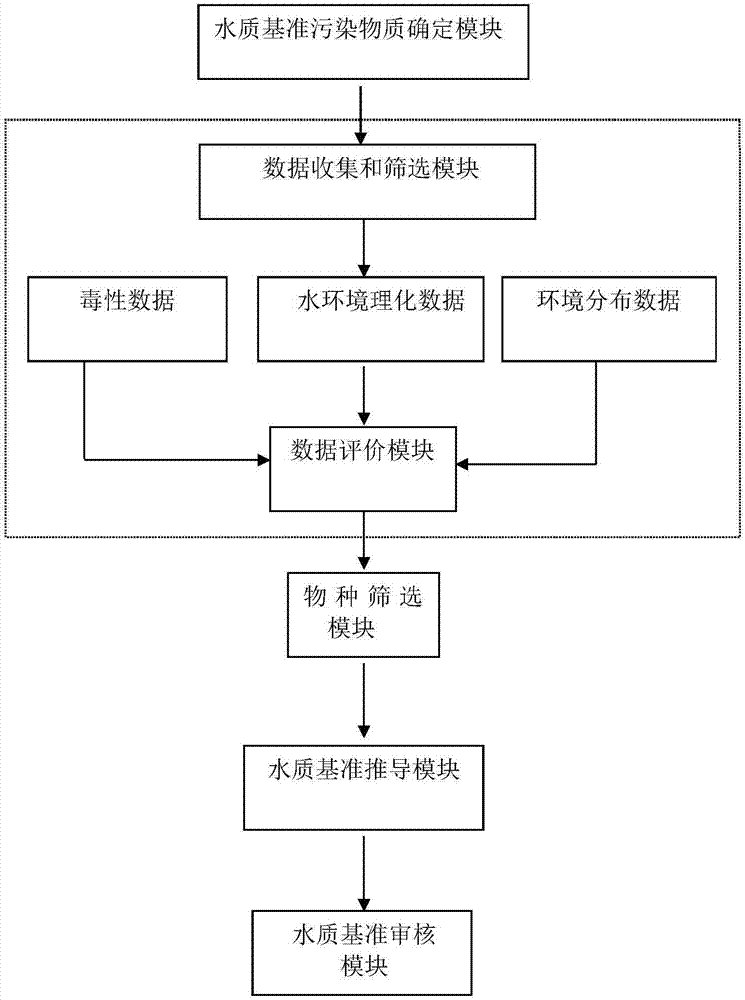
水质基准污染物质确定模块,用于筛选制定淡水水生生物水质基准的污染物质;
数据收集和筛选模块,用于收集和筛选水质基准污染物质确定模块所筛选出的污染物质的数据;污染物质的数据包括淡水水生生物毒性数据、水体理化参数数据、物质固有的理化性质数据和环境分布数据;
数据评价模块,用于对数据收集和筛选模块收集和筛选出的数据的可靠性进行评价;
物种筛选模块,用于筛选基准受试物种;
水质基准推导模块,用于推导淡水水生生物水质基准;以及
水质基准审核模块,用于审核水质基准推导所用数据以及推导步骤,以确保基准合理可靠;
其中,所述的水质基准推导模块包括毒性数据分布检验模块、累积概率计算模块、模型拟合与评价模块、水质基准外推模块和水质基准果表述模块;
所述的毒性数据分布检验模块用于将筛选获得的污染物质的所有毒性数据进行正态分布检验;若不符合正态分布,进行对数变换后重新检验;
所述的累积概率计算模块用于将所有已筛选物种的最终毒性值按从小到大的顺序进行排列,并且给其分配等级r,最小的最终毒性值的等级为1,最大的最终毒性值等级为n,依次排列,计算每个物种的最终毒性值的累积概率,计算公式如下:
其中:
p为累积概率,%;
r为物种排序的等级;
n为物种的个数;
所述的模型拟合与评价模块使用逻辑斯谛分布模型、正态分布模型或极值分布模型进行数据拟合获得ssd曲线,根据模型的拟合优度评价参数分别评价模型的拟合度;
评价模型的拟合度的评价方法为采用决定系数、均方根、残差平方和、k-s检验这四个参数同时作为模型拟合优度参数,具体步骤如下:
1)比较上述三个模型的决定系数r2,若三个模型的决定系数r2有一个为最大,则选取该拟合模型,并终止评价;若三个模型的决定系数r2有两个或两个以上为相同,则选取决定系数r2相同的模型进行下一步比较;
2)比较决定系数r2相同的模型的均方根rmse,若均方根rmse有一个为最小,则选取该拟合模型,并终止评价;决定系数r2相同的模型的均方根rmse有两个或两个以上为相同,则选取均方根rmse相同的模型进行下一步比较;
3)比较均方根rmse相同的模型的残差平方和sse,若残差平方和sse有一个为最小,则选取该拟合模型,并终止评价;均方根rmse相同的模型的残差平方和sse有两个或两个以上为相同,则选取残差平方和sse相同的模型进行下一步比较;
4)将残差平方和sse相同的模型进行k-s检验,若p值(即概率)大于0.05,通过k-s检验,则选取该拟合模型,并终止评价。
所述的水质基准外推模块利用ssd曲线上累积概率5%对应的浓度值hc5,除以评估因子,确定最终的淡水水生生物水质基准;评估因子取值为2-5;
所述的水质基准结果表述模块用于表述淡水水生生物水质基准,淡水水生生物水质基准保留4位有效数字,单位用μg/l表示。
所述的数据评价模块将数据的可靠性分为四个等级,包括无限制可靠数据、限制性可靠数据、不可靠数据和不确定数据,其中无限制可靠数据是指数据来自glp(goodlaboratorypractice,glp,良好实验室规范)体系,或数据产生过程完全符合实验准则;限制性可靠数据是指数据产生过程不完全符合实验准则,但有充足的证据证明数据可用;不可靠数据是指数据产生过程与实验准则有冲突或矛盾,没有充足的证据证明数据可用,实验过程不能令人信服或被判断专家所接受;不确定数据是指没有提供足够的实验细节,无法判断数据可靠性。
用于水质基准制定的数据采用无限制可靠数据和限制性可靠数据,可靠数据和限制性可靠数据来自于严格控制实验条件的实验,实验过程中维持在受试物种的最适生长范围之内,其中,溶解氧饱和度大于60%,总有机碳或颗粒物的浓度不超过5mg/l;实验用水采用标准稀释水,避免使用蒸馏水或去离子水,优先采用流水式实验获得的物质毒性数据,其次采用半静态或静态实验数据,而且实验必须设置对照组(空白对照组、助溶剂对照组等),如果对照组中的物种出现胁迫、疾病和死亡比例超过10%,不采用该数据。
所述的基准受试物种包括本土物种、引进物种以及在我国自然水体中有广泛分布的国际通用物种。
所述的基准受试物种至少涵盖水生植物、无脊椎动物和脊椎动物3个营养级;物种应该至少包括5个:1种硬骨鲤科鱼、1种硬骨非鲤科鱼、1种浮游动物、1种底栖动物、1种水生植物。
所述的正态分布检验包括k-s检验(kolmogorov-smirnovtest)。
所述的逻辑斯谛分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
所述的正态分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
所述的极值分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
本发明具有如下优点:本发明所述的用于淡水水生生物水质基准预测的系统与现有技术相比,操作速度快,性能稳定,能够多数据对比分析,一次执行可同时查看多种预计结果。适合个人和单位建立模型,用于拟合水质基准研究需要的污染物毒性数据的概率分布,并计算指定累积概率条件下的污染物质浓度,具备输出模型拟合优度的检验参数的功能。
附图说明
图1是本发明所述的用于淡水水生生物水质基准预测的系统的结构示意图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示,本发明所述的用于淡水水生生物水质基准预测的系统包括:
水质基准污染物质确定模块,用于筛选制定淡水水生生物水质基准的污染物质;
数据收集和筛选模块,用于收集和筛选水质基准污染物质确定模块所筛选出的污染物质的相关数据;数据主要包括淡水水生生物毒性数据、水体理化参数数据、污染物质固有的理化性质数据和污染物质的环境分布数据;
数据评价模块,用于对数据收集和筛选模块收集和筛选出的数据的可靠性进行评价;
物种筛选模块,用于筛选推导污染物质的淡水水生生物水质基准所需要的基准受试物种;
水质基准推导模块,用于推导淡水水生生物水质基准;以及
水质基准审核模块,用于审核水质基准推导所用数据以及推导步骤是否科学,以确保基准合理可靠;
其中,所述的水质基准推导模块包括毒性数据分布检验模块、累积概率计算模块、模型拟合与评价模块、水质基准外推模块和水质基准结果表述模块;
所述的毒性数据分布检验模块用于将筛选获得的污染物质的所有毒性数据进行正态分布检验;若不符合正态分布,进行对数变换后重新检验;
所述的累积概率计算模块用于计算所有最终毒性值的累积概率,具体方法如下:将所有已筛选物种的最终毒性值按从小到大的顺序进行排列,并且给其分配等级r,最小的最终毒性值的等级为1,最大的最终毒性值等级为n,依次排列,计算每个物种的最终毒性值的累积概率,计算公式如下:
其中:
p为累积概率,%;
r为物种排序的等级;
n为物种的个数;
所述的模型拟合与评价模块使用逻辑斯谛分布模型、正态分布模型或极值分布模型进行数据拟合,获得ssd(speciessensitivitydistribution)曲线,根据模型的拟合优度评价参数分别评价模型的拟合度;
评价模型的拟合度的评价方法为采用决定系数、均方根、残差平方和、k-s检验这四个参数同时作为模型拟合优度参数,具体步骤如下:
1)比较上述三个模型的决定系数r2,若三个模型的决定系数r2有一个为最大,则选取该拟合模型,并终止评价;若三个模型的决定系数r2有两个或两个以上为相同,则选取决定系数r2相同的模型进行下一步比较;
2)比较决定系数r2相同的模型的均方根rmse,若均方根rmse有一个为最小,则选取该拟合模型,并终止评价;决定系数r2相同的模型的均方根rmse有两个或两个以上为相同,则选取均方根rmse相同的模型进行下一步比较;
3)比较均方根rmse相同的模型的残差平方和sse,若残差平方和sse有一个为最小,则选取该拟合模型,并终止评价;均方根rmse相同的模型的残差平方和sse有两个或两个以上为相同,则选取残差平方和sse相同的模型进行下一步比较;
4)将残差平方和sse相同的模型进行k-s检验,若p值(即概率)大于0.05,通过k-s检验,则选取该拟合模型,并终止评价。
所述的水质基准外推模块利用ssd曲线上累积概率5%对应的浓度值hc5,除以评估因子,确定最终的淡水水生生物水质基准;评估因子取值为2-5;
所述的水质基准结果表述模块用于表述淡水水生生物水质基准,淡水水生生物水质基准保留4位有效数字,单位用μg/l表示。
所述的数据评价模块将数据的可靠性分为四个等级,包括无限制可靠数据、限制性可靠数据、不可靠数据和不确定数据,其中无限制可靠数据是指数据来自glp(goodlaboratorypractice,glp,良好实验室规范)体系,或数据产生过程完全符合实验准则;限制性可靠数据是指数据产生过程不完全符合实验准则,但有充足的证据证明数据可用;不可靠数据是指数据产生过程与实验准则有冲突或矛盾,没有充足的证据证明数据可用,实验过程不能令人信服或被判断专家所接受;不确定数据是指没有提供足够的实验细节,无法判断数据可靠性。
用于水质基准制定的数据采用无限制可靠数据和限制性可靠数据,可靠数据和限制性可靠数据来自于严格控制实验条件的实验,实验过程中维持在受试物种的最适生长范围之内,其中,溶解氧饱和度大于60%,总有机碳或颗粒物的浓度不超过5mg/l;实验用水采用标准稀释水,避免使用蒸馏水或去离子水,优先采用流水式实验获得的物质毒性数据,其次采用半静态或静态实验数据,而且实验必须设置对照组(空白对照组、助溶剂对照组等),如果对照组中的物种出现胁迫、疾病和死亡比例超过10%,不采用该数据。
所述的基准受试物种包括本土物种、引进物种以及在我国自然水体中有广泛分布的国际通用物种。
所述的基准受试物种至少涵盖水生植物、无脊椎动物和脊椎动物3个营养级;物种应该至少包括5个:1种硬骨鲤科鱼、1种硬骨非鲤科鱼、1种浮游动物、1种底栖动物、1种水生植物。。
所述的正态分布检验包括k-s检验(kolmogorov-smirnovtest)。
所述的逻辑斯谛分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
所述的正态分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
所述的极值分布模型为:
其中,y为累积概率,%;
x为毒性值,μg/l;
μ为毒性值的平均值,μg/l;
σ为毒性值的标准差,μg/l。
模型拟合优度评价是用于检验总体中的一类数据其分布是否与某种理论分布相一致的统计方法。对于参数模型来说,检验模型拟合优度的参数包括:
(1)决定系数(coefficientofdetermination,r2)
通常认为,r2大于0.6具有统计学意义,r2越接近1,说明毒性数据的拟合优度越大,模型拟合越精准。
式中:
r2-决定系数,取值范围是[0,1];
yi-第i种物种的实测毒性值,μg/l;
n-毒性数据数量。
(2)均方根(roommeansquareerrors,rmse)
rmse是观测值与真值偏差的平方与观测次数比值的平方根,该统计参数也叫回归系统的拟合标准差,rmse在统计学意义上可反映出模型的精密度,rmse越接近于0,说明模型拟合的精确度越高。计算公式如下:
式中:
rmse-均方根;
yi-第i种物种的实测毒性值,μg/l;
n-毒性数据数量。
(3)残差平方和(sumofsquaresforerror,sse)
sse是观测值和实际值的平方差之和,用于解释变量和随机误差各产生的效应,反映每个样本各观测值的离散状况,又称为组内平方和或误差项平方和。sse越接近于0,说明模型拟合的随机误差效应越低。
计算公式如下:
式中:
sse-残差平方和;
yi-第i种物种的实测毒性值,μg/l;
n-毒性数据数量。
(4)k-s检验(kolmogorov-smirnovtest)
是基于累积分布函数,用于检验一个经验分布是否符合某种理论分布,它是一种拟合优度检验。通过k-s检验来验证分布与理论分布的差异时,若p值(即概率,反映两组差异有无统计学意义,p>0.05即差异无显著性意义,p<0.05即差异有显著性意义)大于0.05,证明实际分布曲线与理论分布曲线不具有显著性差异,通过k-s检验,可反映模型符合理论分布。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!