一种基于简化容积粒子滤波的目标定位方法与流程
本发明涉及目标定位领域,具体涉及一种基于简化容积粒子滤波的目标定位方法。
背景技术:
众多经典的滤波算法已经被广泛应用于目标跟踪导航和即时定位与地图构建(simultaneouslocalizationandmapping,slam)等系统中,诸如卡尔曼滤波(kf)、扩展卡尔曼滤波(ekf)、无迹卡尔曼滤波(ukf)、容积卡尔曼滤波(ckf)、粒子滤波(pf)等算法。针对上述各算法的不足之处,一系列修正算法陆续被提出。经典的滤波算法可以分为两大类:基于kf框架和基于pf框架的滤波算法。前者是针对高斯噪声条件下高精度算法,而后者是非高斯条件下的最优解决方案。粒子滤波的精度在很大程度上取决于粒子的数目和重要性函数的选取。粒子的数目较多时,计算量的急剧增长为系统带来“维数灾难”。另外,如果重要性函数选择不好,常常会导致滤波发散或者极差的滤波效果。因此,重要性函数对于粒子滤波器的设计是至关重要的。判断重要性函数好坏的一个非常最后那要的标准就是看它能否最大程度地利用最新的量测值,使得采样粒子能体现最新的量测值信息。标准粒子滤波算法的一个潜在缺点就是:基于的一组无法确切地描述真是后验概率密度函数的尾部,这一现象在量测值出现于估计函数之外时更为明显。主要原因就是采用了确定的混合估计函数来估计时变的真实后验分布,即重要性密度函数选取的不理想。
在pf的优化法中,寻找合适的建议密度分布函数是一个比较可行的思路,也一直是学者们的研究热点。如果可以找到最优建议密度分布函数,并引导重采样做正确的采样分布,就可以保证样本集合的有效性,也能够保证pf的估计性能。近些年,有些学者提出将两种方案集成起来的思路,用基于kf的滤波算法改进pf,即用前者产生建议密度分布,指导后续pf过程中的“采样”。比较有代表性的算法有ekf与pf结合的扩展粒子滤波(epf)算法,ukf与pf结合得到的无迹粒子滤波(upf)算法以及比较新的容积粒子滤波(cpf)算法-ckf与pf结合所得。由于ckf的滤波精度优于ekf和ukf,因此cpf的精度也优于epf和upf。与pf、epf、upf算法相比,cpf大幅度提升了滤波精度,是目前滤波精度最高的算法之一。但是由于pf本身计算量比较大,而且容易出现粒子退化现象,引入ckf算法后又增加了产生每一个粒子的计算量,使计算量成倍增加,“维数灾难”更加严峻。因此,基于cpf算法的目标定位算法虽然能够取得较高的估计精度,但是对定位系统的硬件要求很高,每一次对目标进行位置更新的过程,都需要付出昂贵的计算代价。尤其对于水下作业的定位系统而言,充电、更换电池是非常困难甚至是不可能的事情,所以系统的功耗直接决定其工作寿命。使用几十倍甚至上百倍的功耗去换取精度上几个百分点的上升,对于水下定位系统,尤其是实时定位系统,显然不是一个很明智的选择。总之,巨大的计算量是基于cpf算法的目标定位系统的最大缺点。综上,如何改进定位系统的滤波算法,取得精度与效率的折中具有重大的意义。
技术实现要素:
本发明的目的在于克服上述技术缺陷,提出了一种基于简化容积粒子滤波的目标定位方法,能够显著降低运算量。
为了实现上述目的,本发明的技术方案为:
一种基于简化容积粒子滤波的目标定位方法,所述方法包括:
步骤1)建立k时刻的目标运动的状态空间模型;利用状态空间模型对k时刻目标状态进行预测得到第一次滤波结果
步骤2)记
步骤3)从步骤2)的粒子集中选取“优质粒子”,并将“优质粒子”的权值进行归一化;这些“优质粒子”组成新粒子集;
步骤4)对步骤3)得到的新粒子集进行重采样,得到重采样粒子集;
步骤5)计算重采样粒子集中粒子的均值为
作为上述方法的一种改进,所述步骤1)具体包括:
步骤1-1)使用如下状态空间模型描述的目标的运动:
xk=f(xk-1)+wk,(3)
zk=h(xk)+vk,(4)
其中,k为整数,时刻k的目标状态为xk∈rn;zk为传感器采集到的量测信息;wk∈rn为输入的白噪声,vk∈rm为观测噪声;式(5)为状态方程,式(6)为观测方程,f(·)为状态转移函数,h(·)为观测信息函数,结合先验知识给定目标状态的初值x0;
步骤1-2)结合状态空间模型,使用容积卡尔曼滤波对k时刻目标的状态进行预测,得到第一次滤波结果
作为上述方法的一种改进,所述步骤2)具体包括:
步骤2-1)记
其中,
步骤2-2)为粒子集中每个粒子计算权重
其中,
步骤2-3)对
作为上述方法的一种改进,所述步骤3)具体为:
给定一个权重阈值ωth,将权值小于ωth的粒子全都舍弃,余下的记为“优质粒子”,共m个;将“优质粒子”重新按顺序从1开始编号记为
作为上述方法的一种改进,所述权重阈值ωth=1/n。
作为上述方法的一种改进,所述重采样为:随机重采样、多项式重采样、系统重采样或残差重采样。
作为上述方法的一种改进,所述步骤5)具体为:
所述步骤4)中重采样粒子集为:
输出k时刻的目标状态向量:重采样粒子集的均值
本发明的优势在于:
1、本发明的方法保持了cpf跟踪定位方法估计性能高的优点;但是其运算量下降约一个数量级;
2、本发明的方法对强非线性、非高斯的运动模型也能达到很高的定位精度。
附图说明
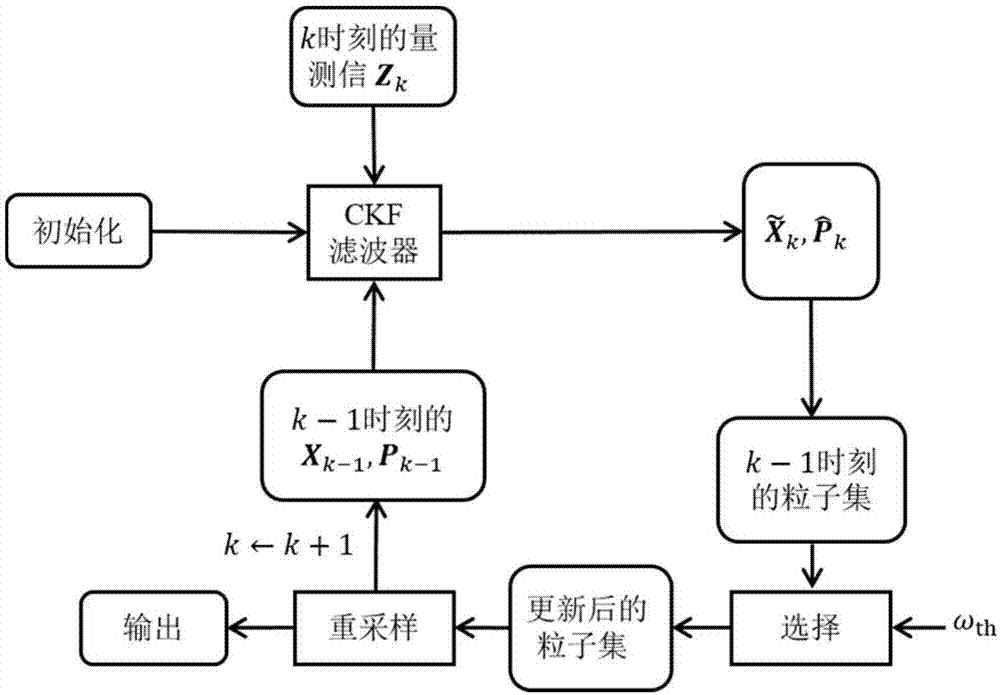
图1为本发明的k时刻的基于简化容积粒子滤波的目标定位方法的流程图;
图2为本发明的连续的基于简化容积粒子滤波的目标定位方法流程图;
图3为标准cpf与简化cpf的估计轨迹对比图(粒子数100);
图4为ckf、pf、标准cpf、本发明提出的icpf在某一次滤波的定位误差曲线图(粒子数100);
图5为cpf与icpf某一次滤波的定位误差曲线比较图(粒子数500);
图6为某时刻重采样更新后的粒子集对比图(粒子数100);
图7为某时刻重采样更新后的粒子集对比图(粒子数200);
图8为某时刻重采样更新后的粒子集对比图(粒子数500);
图9为ckf、pf、标准cpf、本发明的icpf的定位误差rmse比较图(蒙特卡洛实验10次);
图10为ckf、pf、标准cpf、本发明的icpf的运行时间的比较图(蒙特卡洛实验10次);
图11为ckf、pf、标准cpf、本发明的icpf的估计轨迹对比图(粒子数100);
图12为ckf、pf、标准cpf、本发明的icpf的某一次滤波的定位误差曲线图(粒子数100);
图13为某时刻重采样更新后的粒子集对比图(粒子数100);
图14为某时刻重采样更新后的粒子集对比图(粒子数200);
图15为某时刻重采样更新后的粒子集对比图(粒子数500);
图16为ckf、pf、标准cpf、本发明的icpf的定位误差rmse比较图;
图17为ckf、pf、标准cpf、本发明的icpf的运行时间的比较图。
具体实施方式
下面结合附图对本发明进行详细的说明。
本发明提出一种改进的滤波方案,称为简化容积粒子滤波(improvedcubatureparticlefilter,icpf)的目标定位方法。本发明所提的方法不但能避免出现粒子退化现象,还具有操作简单、计算量低(计算量下降一个数量级)的优点。同时该方法的估计精度没有降低。我们认为,这个更加简洁的新算法将推动非线性滤波的进一步应用,并大大降低了实时应用的难度。仿真和湖上试验结果均证明了新方法的优异性。
1、状态系统模型
考虑用如下状态空间模型描述的动态系统
xk=f(xk-1)+wk,(5)
yk=h(xk)+vk,(6)
式中,k为离散时间,系统在时刻k的状态为xk∈rn;yk∈rm为对应状态的观测信号,wk∈rn为输入的白噪声,vk∈rm为观测噪声。
其中,式(5)为状态方程,式(6)为观测方程,f为状态转移函数,h为观测信息函数。
2、标准容积粒子滤波(cpf)
用容积卡尔曼滤波ckf改进粒子滤波pf算法的核心在于:在采样阶段,利用ckf算法为每个粒子计算均值和协方差,然后利用该均值和协方差,然后利用该均值和方差“指导”采样。因为用ckf算法计算均值和方差的过程中,利用了近似后验滤波密度的函数,即已经“吸纳”了最新的观测信息zk,在粒子滤波的框架下,ckf算法为每个粒子产生符合高斯建议密度分布。换句话说,在k时刻利用ckf算法以及最新的观测信息zk来计算第i个粒子的均值和方差,并利用该均值来采样并更新该粒子。
标准cpf算法流程如下。
(1)初始化,k=0。结合先验知识给定初始粒子值x0。
(2)fork=1:k,
a)重要性采样阶段。
(3)fori=1:n,
用ckf算法对每一个粒子进行估计,得到每个粒子的均值
更新粒子集合,
(4)计算权重。
fori=1:n,
为粒子集合中每个粒子重新计算权重并归一化权重。
p(·)是后验概率密度分布。
b)选择阶段(重采样)。
根据近似分布产生n个随机样本集合,并计算权重,进行归一化,对粒子集合进行复制和淘汰,得到更新后的粒子集。
c)输出:计算粒子集的均值xk作为算法的输出。
cpf算法与pf算法最大的区别就是产生粒子的过程借助了ckf算法,其他步骤几乎是相同的。
这种方法的本质是改善了建议密度分布的问题,将先验分布的粒子集合转移到似然区域,其代价在于对系统做了高斯假设。我们知道,基本粒子滤波是不受线性高斯模型约束的,那么cpf受到了高斯模型的约束。这也是算法的不足之处。
标准cpf算法引入了ckf算法来“指导”采样过程,它最突出的优点是估计精度高,同时,它也存在如下的缺点,导致了实际应用中的局限性。
1、产生新粒子的过程复杂程度与粒子数目成正比。(按照标准cpf算法步骤,上一过程结束后的每一个粒子都要用ckf处理)
2、重采样阶段,可能导致新的粒子权值两极分化和粒子多样性匮乏,造成粒子退化现象。粒子有很多权值很小(误差非常大)的粒子也可能会被重新采到,引入的新的误差。
3、如果粒子数目比较大,重采样阶段计算复杂度会很高。
3.简化容积粒子滤波(icpf)
本发明的简化容积粒子滤波icpf不仅保留了标准cpf估计精度高的优点,也解决了粒子滤波最大的两个诟病:运算量大和粒子退化现象。
下面给出icpf的具体步骤。
(1)初始化,k=0。结合先验知识给定初始值x0。
(2)fork=1:k,
第一步预测更新:用ckf算法更新预测结果,得到第一次滤波结果
(3)第二步预测更新:
a)重要性采样阶段。
利用“种子”和最新的协方差矩阵,产生新的粒子集合,
为每个粒子计算权重并归一化权重。
式中
b)选择阶段(重采样)。
给定一个权重阈值ωth,将权值小于ωth的粒子全都舍弃,余下的记为“优质粒子”,将“优质粒子”的权值ωi进行归一化。即,每个粒子的权值ωi更新为
c)输出
重采样粒子集的均值
可以看出,本发明中的算法具有如下特点:
1.产生新粒子的过程简单快速。
2.避免出现粒子退化现象,因为每一次递推过程都重新产生粒子。
3.重采样阶段,有很多权值很小的粒子直接被舍弃,只保留有价值的“优质”粒子。
4.即使粒子数目比较大,重采样阶段计算复杂度也不会很高。
5.保持了cpf算法估计性能高的优点。
如图1所示,基于简化容积粒子滤波(icpf)的目标定位方法的步骤如下:
1、设定参数p、r、q、t、n、f(·)、ωth,以及结合先验知识给定目标坐标的初值x0。一般情况下,建议取ωth=1/n。
2、传感器采集目标信息,如目标相对于传感器的方位角、距离等,采集到的信息称为量测信息z,k时刻的量测信息记为zk。
3、根据量测信息的性质确定量测方程h(·)和权重函数ωi的计算形式。
4、预测更新:用ckf算法更新预测结果,得到第一次滤波结果
5、产生粒子集:以
6、重要性采样阶段:为每个粒子计算权重并归一化权重,选取“优质粒子”,并将“优质粒子”的权值ωi进行归一化。这些“优质粒子”组成新的粒子集
7、重采样阶段:对上一步得到的新粒子集进行重采样:对粒子进行复制和淘汰。
8、对重采样得到的结果计算均值,记为
如果对目标的跟踪没有结束,则重复步骤2-8,继续向下处理;否则输出结果,整个跟踪阶段结束;如图2所示。
4.性能分析
下面进行蒙特-卡洛实验来分析本发明所提icpf算法的性能,并与原算法进行比较。首先考虑k时刻的状态向量为xk=[x,y,vx,vy,ax,ay]t,根据式(5)和式(6)建立状态方程和观测方程如下:
xk=φxk-1+wk(7)
yk=h(xk,vk)=dist(xk,{a,b,c})+vk(8)
记t为采样间隔,式(3)中的状态转移矩阵为:
wk和vk分别是均值为零方差为q和r的高斯白噪声;dist(xk,{a,b,c})表示xk确定的坐标离节点{a,b,c}的距离。
目标从原点处开始先做匀速直线(cv)运动,速度为vx=5m/s,vy=3m/s,5s后加速度为ax=-0.1m/s2,ay=0.1m/s2并持续到55s,55s到105s加速度为
图3给出了粒子数目为100时,ckf、pf、标准cpf、本发明提出的icpf这几种方法的轨迹估计结果与真实轨迹的对比。从图中可以看到,标准cpf和icpf的轨迹曲线几乎是重合的,说明两种方法的估计结果几乎是一致的。图4中这几种方法在各采样点的定位误差曲线也印证了上述结论。图5给出了当粒子数为500时标准cpf和icpf的误差曲线,可以看到,粒子数增大后,二者的误差曲线更加接近了。图6到8给出粒子数目分别为100、200、500时,随机截取的某采样时刻重采样更新后的粒子集对比图。从这几张对比图中,我们可以清晰地看到,本发明的icpf产生的粒子集与标准cpf产生的粒子集是非常近似的,随着粒子数目的增加,两个集合有重合趋势。以上结果说明,随着粒子数目的增加,标准cpf和icpf两种方法的效果越来越近似。
这种趋势的出现并不难理解。随着粒子数目的增加,产生的粒子越来越好地覆盖了真实值的似然区域。另外,由于筛选粒子的方法是相同的(计算权重的公式和重采样算法不变),因此筛选后留下来的粒子都是聚集在真实值周围的粒子。随着粒子数目的增大,标准cpf产生的粒子集所覆盖的区域也能够被icpf的粒子集所覆盖,因此两种算法估计的结果也是很相近的。
在使用同样的量测信息和估计参数(初始估计值、初始协方差矩阵、噪声方差矩阵等)的情况下,ckf、pf、cpf方法的结果都是趋近真实值的。而且由实际情况可知,只使用ckf或者pf方法也能得到估计的结果,只是性能比cpf差一些。在要求实时处理或其他要求处理速度的系统中,ckf和pf方法不失为cpf的良好替代方法。而且当粒子数目无穷大的时候,pf和cpf是等效的。因此,对于本发明的方法,我们可以这么理解:当对系统做了一次ckf滤波处理后,得到初步结果
图9给出了上述参数条件下,蒙特卡洛仿真50次后求得几种方法的误差对比曲线。记标准cpf方法与本发明的icpf方法的运算时间分别为tcpf、ticpf。图10给出了两种方法的运行时间、标准cpf方法与新提出icpf方法运算时间之倍数tcpf/ticpf随粒子数增加的变化曲线。我们可以清晰地看到,icpf方法与标准cpf方法的估计精度几乎是相等的,但是运算量下降了至少一个数量级。运行程序的电脑型号为联想90d4ct01ww,处理器为amda10pr0-7800br7,4cpus,3.5ghz,内存4gb,操作系统为windows7,matlab版本为2015a。
为了进一步验证本文所提出的方法,我们在2018年3月22日在千岛湖进行了水下定位实验。通过对比上述两种方法的运行时间多少以及对目标位置坐标的跟踪结果,证明本发明的方法可以在高精度和高效率之间取得很好的折中。试验中,目标是紧贴于小船底部的一个发射换能器,认为目标和小船的轨迹是重合的。小船的真实轨迹由差分gps给出。本次实验使用的三个节点(节点名称记为a、b、c)布放在约一公里见方的湖水区域。每个节点分为两部分:用于水下接收信号的收发合置换能器模块和连接了gps信号接收器的浮标模块。节点中的水声换能器位于水下5米深,节点顶部的浮标浮于水面。试验中只考虑目标的二维坐标信息(即东向和北向),坐标系的参考点选取为c节点在初始时刻的位置。gps每隔1s发送定位信息,水声测距信号间隔2s发送和采集。
与仿真中的模型类似,我们仍选择ca模型对上述目标进行跟踪。考虑k时刻的状态向量为xk=[x,y,vx,vy,ax,ay]t,维数n=6;假设过程噪声方差为q=diag[0.15,0.15,0.01,0.01,0.01,0.01],测量噪声方差为
值得注意的是,由于实验条件比较恶劣,我们的三个节点并不是一直都能全部采集到信息,为了尽可能提高量测信息的利用率和定位的精度,我们对量测信息大于等于2的情况进行滤波,即量测信息的维度可取2或3。实验中使用的目标跟踪算法与仿真实验中相同。实验数据的处理结果与前一小节中仿真的结果是类似的。图11给出了粒子数目为100时,两种算法的轨迹估计结果与真实轨迹的对比。从图11中可以看到,标准cpf和icpf曲线几乎是重合的,说明两种方法的估计结果几乎是一致的。图12中这几种方法在各采样点的定位误差曲线也印证了上述结论。图13到图5给出粒子数目分别为100、200、500时,随机截取的某采样时刻重采样更新后的粒子集对比图。与仿真结果相同,这几张对比图中icpf产生的粒子集与标准cpf产生的粒子集是非常近似的,随着粒子数目的增加,两个集合有重合趋势。
另外,本发明所提新方法在保证估计精度的同时,运算时间相比于标准方法大大降低,极大提高了运算效率。图16给出了上述参数条件下,蒙特卡洛仿真50次后求得集中算法的误差对比曲线。标准cpf算法和icpf算法的rmse相差很小,约0.2m,我们认为两种算法在目标位置估计方面的性能是一致的。图17给出了两种方法的运行时间、标准cpf算法与新提出icpf算法运算时间之倍数tcpf/ticpf随粒子数增加的变化曲线。相比于cpf,icpf的运算量下降了大约一个数量级。另外,当粒子数目不是很大的时候pf算法很容易发散,这是由于产生粒子集的方差参数设置不够合理。在本试验中,由于存在很严重的“跳点”情况,量测信息经常出现失效的情况,导致在某些区域中可定位的点并不是连续分布的,而是有可能间隔了很大的距离,这个距离超出了粒子集覆盖的范围,因此pf算法容易失效。在这种情况下,造成pf性能不佳的主要原因是数据的不完整,如果盲目调大生成粒子集的区域,又会使得算法在量测数据完整的阶段产生的粒子集过于稀疏,落在有效区间内的粒子过少,降低了估计精度。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!