基于特征选择的多模态数据分类方法与流程
本发明属于计算机图像处理技术领域,更具体地,涉及一种基于特征选择的多模态数据分类方法。
背景技术:
随着信息技术的快速发展,数字图像的数量得到了迅速的增长。图像分类是计算机视觉领域和图像处理领域的热门问题之一,图像分类的主要目的就是对图像进行识别,同时区分出不同种类的图像。然而,由于图像的质量和内容千差万别,产生多种数据类型的图像特征,因此,用户如何有效地在不同模态下的图像数据中找到同一类图像已成为研究热点。
在互联网时代,每天都有大量的数据存在不同的模态出现在人们的日常生活中,例如,图像,视频,文本等等。由于不同信息资源的不同统计特性,发现不同模态之间的关系是非常重要的。多模学习可以相互提供补充信息,充分利用各个模态之间的内在关联性,因此,多模分类较单模态在准确率和可靠性方面通常能产生更好的性能。在现有的多模融合的应用领域,例如,阿尔兹海默症多模联合诊断较单模方法已经产生显著的成就;情感识别领域,利用多模态信息融合来识别情感就比单模态下更加准确可靠。因此,深入研究多模场景下的图像分类问题具有非常重要的理论意义和实用价值。
现有的特征选择方法在中小规模情况下能够有效的识别出一阶关键特征。然而,当多模态数据的特征之间呈现出超高维特性,现有的特征选择方法很难有效的从海量的特征集合中识别相互紧密相关的特征子集。
技术实现要素:
本发明的目的是针对低阶空间特征选择方法无法有效揭示多模态数据特征之间的高阶关联关系存在的问题,提供一种基于特征选择的多模态数据分类方法,不仅充分利用多模态数据之间的内在关联与互补信息,而且能够有效地从海量数据集中识别出最紧密相关的特征,最终可以达到更好分类效果。
为了实现上述目的,本发明采用的技术方案是,基于特征选择的多模态数据分类方法,包括以下步骤:
步骤1)、基于给定的多模态数据集提取各模态数据的特征信息;
步骤2)、对步骤1)中提取的特征信息的维度进行扩展,将特征信息从低阶扩展为高阶得到高阶特征信息;
步骤3)、构建基于多模态数据的特征选择模型,将经步骤2)得到的高阶特征信息输入到特征选择模型,选择出与类别标签(分类方法中默认有类别存在)关系紧密的特征子集;
步骤4)、利用步骤3)得到的特征子集中的训练样本对各模态数据对应的子分类器进行训练;
步骤5)、将经过步骤4)训练的所有子分类器构建为一个集成分类器,将多模态数据输入集成分类器中,输出最终分类结果。
进一步的,步骤1)中所述的多模态数据及包括adni数据集和office数据集,adni数据集包含三种模态mri、pet和csf下的数据;office数据集包括mazon、dslr和webcam数据集;提取所有数据集的surf和decaf特征,并分别训练lenet和alexnet网络模型,获得decaf-lenet和decaf-alexnet特征。
进一步的,步骤2)中所述的特征信息的维度扩展包括如下步骤:采用非线性核显式展开方法对特征信息间高阶关系进行线性表示,将初始的特征信息进行维度扩展,将特征信息从低阶映射到高阶空间中,获得组合式高阶特征信息。
进一步的,所述步骤3)还包括采用cuttingplane方法与整数规划相结合对选择出的特征子集进行更新,从中选择出关系最为紧密的高阶特征信息子集。
进一步的,步骤4)中所述的各模态数据对应的子分类器训练包括如下步骤:利用训练样本对子分类器进行训练,优化特征选择的权重,将训练样本输入训练后的子分类器得到各个子分类器的分类结果。
进一步的,步骤5)具体包括如下步骤:先采用最小二乘方法确定各子分类器的权重,然后将所有子分类器通过加权计算得到集成分类器。
与现有技术相比,本发明至少具有以下有益效果,本发明采用非线性核显式展开方式对数据进行展开表示,获得组合式高阶特征,并从中识别出关系最为紧密的高阶特征子集;充分挖掘特征之间的高阶依赖关系;本发明构建了集成分类器,将所有子分类器集成为一个整体的分类器,提高了分类准确率;本发明基于特征选择的多模分类方法,本发明在多模分类中应用广泛,不仅可以实现对阿尔兹海默症患者与健康对照组更加准确地分类,同时也有利于对阿尔兹海默症患者的前期诊断治疗。
本发明通过显性展开的方式,能够表达出特征之间的依赖关系,并形成组合式的多粒度特征,而传统的方法不能对高阶依赖关系进行表达,只能进行单粒度的特征的选择,无法揭示特征与特征之间的依赖关系,从而其精确度和性能受到限制,无法有效的从海量的特征集合中识别相互紧密相关的特征子集。
进一步的,本发明的方法属于低复杂度的算法,即使在进行海量的特征集合识别中,也不需要占用大量的计算资源,对硬件的需求较低,节约运算资源;另外,与传统的集成方法相比,我们加入了特征选择的功能,这样能够有效消除噪音和负面因素的影响,使预测性能更加稳定有参考价值。
附图说明
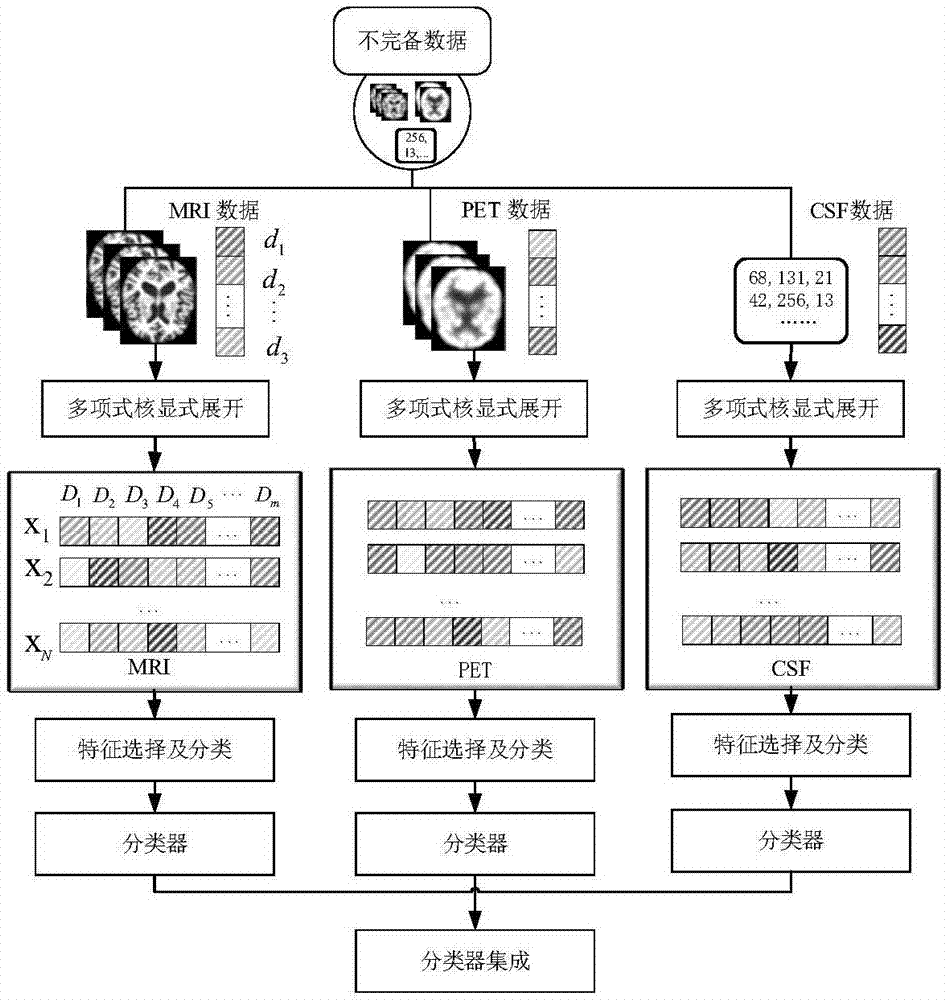
图1是本发明的整体框架图。
图2是基于cuttingplane的多模特征选择流程图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好的理解本发明。
图1是本发明基于特征选择的多模分类方法的框架图。在本实施例中,如图1所示,将三种模态mri,pet,csf作为输入数据。
步骤1:构建初始的图像数据集。针对adni数据集和office数据集,对数据进行预处理,提取它们特征信息。adni数据集是103*189,office数据集包括:amazon是958*4096,dslr是157*4096,webcam是295*4096。
步骤2:采用非线性核显式展开对特征间高阶关系进行线性表示,将初始的数据进行维度扩展,将低阶特征映射到高阶特征空间中,获得组合式高阶特征。
步骤3:基于多模超高维数据的关键特征快速选择,从中选择出关系最为紧密的高阶特征子集。cuttingplane方法主要思路是通过不断添加割平面并利用精确线性搜索实现算法的加速和优化。在cuttingplane切片基础上,配合采用整数规划和最坏情况分析对选择特征子集进行更新。
步骤4:利用训练样本对所述的模型进行训练,优化特征选择的权重,训练分类器,得到各个子分类器的预测结果。
步骤5:构建多模分类集成学习模型,输出最终分类结果。集成模型是由多个子分类器模型组成的,每个子分类器都有自己的参数,不同的输入样本数据、权重、偏差及产生的预测值型。将多个不同的子分类器构建为一个集成分类器,并调整集成模型中各种参数。集成学习能够显著地提高系统的准确率和泛化能力。
其中,所述的步骤2中具体包括:
采用非线性核显式展开对特征间高阶关系进行线性表示,将步骤1所获得的数据进行维度扩展,将低阶特征映射到高阶特征空间中,获得组合式高阶疾病特征,并从中识别出与疾病关系最为紧密的高阶特征子集。针对d次多项式,多项式核定义为:
k(x,y)=(γxty+ρ)d
令d=2,我们得到它的二次核函数的特殊情况。在使用多项式理论和重组后,
由此可得,它的显式特征映射:
对于多项式核展开式,特征的维数将以d呈指数级增加。当阶数d=2时,m是初始的特征维数,则扩展后的维数是(m+2)(m+1)/2。通常,当m=106时,扩展的维数大约1012。
其中,所述的步骤3中具体包括:
(3-1)基于cuttingplane的多模特征选择模型:首先,引入一个特征选择向量d,所选的特征是0或1。令d={d|d∈{0,1}}是d的域。我们使用||d||1≤b控制特征选择的稀疏性,其中,b控制所选特征的数目,目标函数表示为:
s.t.w(xi⊙d)-yi=ξi,i=1,…,n
其中,w是权重。该目标函数具有无限个二次不等式条件,属于np-hard难题,难以直接求解。但考虑到仅有少部分特征被选中,且符合半正定规划(sip)的形式,表明只有少数限制条件在优化过程中被激活。因此,采用cuttingplane算法间接解决。主要过程是,从一个初始化α=1开始,通过最坏情况分析计算出被激活限制条件dt,并将其加入活跃限制条件集合c=c∪{dt};接着基于新的限制条件c,求解一个含有|c|个限制条件的qcqp子问题更新α,然后再次通过α更新限制条件集合c,依次迭代直至满足条件。
(3-2)基于最坏情况分析的特征选择向量d优化:主要解决如何从为第次迭代快速找到新的限制条件。将问题转化为具有一个线性限制条件的最大化问题。
(3-3)采用近端梯度快速下降法计算获得的最优解w。
实施例1:
本发明为了解决上述问题,提供一种基于高维特征选择的多模分类方法,包括以下步骤:
步骤1:对分别来自adni数据集和office数据集的图像进行预处理,得到,所得数据包括训练样本和测试样本。
具体地,adni数据集总共有三种模态数据(即,mri,pet和csf)下的103位受试者,包括51位ad患者,52位健康对照组。所述多模态信息包括影像特征和非影像特征,所述的影像的类别特征包括:mri图像和pet图像,非影像特征包括:csf。对多模态数据的图像处理,得到103*189。关于每个受试者,其中mri图像包含93维特征,pet图像包含93维特征,生物标志物csf包含3维特征。
office数据集的图像分别来源于:亚马逊amazon(即从网上下载的图像),webcam(即,网络摄像头拍摄的低分辨率的图像),数码单反相机dslr(即,通过数码单反相机拍摄的高分辨率图像)。每个数据集都有10个种类。具体地,提取所有图像的surf和decaf特征,分别训练lenet和alexnet网络模型可以获得decaf-lenet和decaf-alexnet特征。surf的特征维度是800,两种网络训练的decaf的特征维度是4096。
步骤2:特征重表。采用非线性核显式展开,对维度进行扩展。采用如下公式:
由此可得,它的显式特征映射:
将adni数据集扩展为103*8940,其中mri模态的维度是4465,pet模态的维度是4465,csf模态的维度是10。将office数据集统一扩展为180902维。
步骤3:特征快速选择过程。具体内容如下:
给定一组数据样本x=[x1,...,xi,...,xn],i=1,...,n,其中n是样本总数。每个样本有m种模态,即
特征选择向量d,所选的特征是要么0或1。令d={d|d∈{0,1}}是d的域。使用||d||1≤b控制特征选择的稀疏性,其中,b控制所选特征的数目,b=30,目标函数可以表示为:
s.t.w(xi⊙d)-yi=ξi,i=1,…,n
其中,常数c是正则化参数。约束条件是预测值与真实值的偏差。
引入对偶变量α,α∈a={α|αi≥0,i=1,…,n},目标函数的拉格朗日形式可以写为如形式:
将l(w,ξ,α)关于w和ξ的导数为0,我们可以得到kkt条件,即w=α(xi⊙d),
其中,
引入一个额外向量
采用cuttingplane方法与整数规划相结合进行解决半无限qcqp问题。主要过程是,从一个初始化α=1开始,通过最坏情况分析计算出被激活限制条件dt,并将其加入活跃限制条件集合c=c∪{dt};接着基于新的限制条件c,求解一个含有|c|个限制条件的qcqp子问题更新α,然后再次通过α更新限制条件集合c,依次迭代直至满足条件。具体地,我们需要解决以下优化问题:
由于|c|很小,通过最坏情况分析可以有效解决上述标准问题并获得一个新的α更新集合c。整个过程将迭代直到达到停止条件。
采用整数规划和最坏情况分析对选择特征子集进行更新。基于最坏情况分析的特征选择向量d的优化主要解决如何从备选域d中为第t次迭代快速找到新的限制条件。将问题转化为一个线性限制条件
其中,
其中,
显然,由于dj∈{0,1},上述问题可以通过对cj的排序,寻找最大的cj。
本发明采用快速梯度下降法对w进行更新,采用的公式如下:
其中,wk表示当前第k步的权重,wk-1表示第k-1步的权重,wk+1表示第k+1步的权重。另外,参数ρ-1=ρ0=1,并且
这样通过快速下降梯度法就可以求得最优参数w。
步骤4:设置训练样本为93个,测试样本为10个。利用训练集和相对应的标签训练分类器,然后在测试集上进行预测分析,得到预测值。将预测值与该已知的类别测试样本进行匹配,计算分类准确率。
步骤5:构建集成分类器模型,输出最终的分类结果。将每个子分类器整合成一个整体的子分类器,要求调整每个子分类器对应的权重。
在公开的阿尔兹海默症(adni)数据集上对本发明所涉及的算法测试,目的是对阿尔兹海默症患者与健康对照组准确地分类。结合图2具体说明本发明的超高维特征选择及分类方法的实施方案。
表1:adni数据集的统计信息
表2:office数据集的统计信息
(1)实验设置
将参数b设置为:b=30
(2)对比实验
多核学习方法(mutiplekernellearning,mkl):zhang等人在2011年提出的多核学习方法,结合了生物标志物的三种模态分别是mri,pet和csf对阿尔兹海默症患者和健康对照组进行分类。
(3)实验性能
在实验1和实验2中,分别对adni数据集和office数据集上进行测试,实验1和实验2为了说明所提出的方法在不同领域不同数据背景情况下是有一定的适应性;实验1和实验2的结果(准确率accuracy)如下表3和4所示:
表3:在adni数据集上的表现(%)
表4:在adni数据集上不同方法的表现(%)
由上述具体的实施的实验结果表明,本实施例提出的方法相比于mkl分类准确率,本发明提出的多模分类性能优于mkl,从分类精度方面能够看出,本发明的方法具有明显的提升,本方法在疾病筛查的误诊率和漏检率发面来说,具有更好的性能。因为特征选择带来的正面影响,分类精度、敏感性和特异性提升幅度大,本发明的分类精度、敏感性和特异性的测试结果都达到了90%以上,在实际应用中,能够提供更加可靠的参考价值和准确率。
表5:在office数据集上的表现(%)
从表5中的数据可以看到,通过多模态数据的引入,有效的补充了单模态数据存在的描述信息不全面的问题,也可以看出在模态数据较多的情况下,本发明的方法能够实现高于90%的分类精度。
以上所述仅为本申请的优选实施案例而已,并不用于限制本申请,对于本申请的技术人员来说,本申请可以由各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!