多瓦片处理阵列中的同步的制作方法
本公开涉及在包括多个瓦片(tile)的处理器中同步多个不同瓦片的工作量,每个瓦片包括具有本地存储器的处理单元。具体地,本公开涉及批量同步并行(bsp)计算协议,其中瓦片组中的每一个必须在该组中的任何瓦片可以继续交换阶段之前完成计算阶段。
背景技术:
计算中的并行性(parallelism)采取不同的形式。程序片段可以被组织为并发地执行(其中它们在时间上重叠但可以共享执行资源)或者并行地执行,其中它们可能同时在不同资源上执行。
计算中的并行性可以以多种方式来实现,诸如借助多个互连处理器瓦片的阵列,或者多线程处理单元,或者其中每个瓦片包括多线程处理单元的多瓦片阵列。
当借助于包括在同一芯片(或在相同集成电路封装中的芯片)上的多瓦片阵列的处理器实现并行性时,每个瓦片包括其自己的单独的相应处理单元,其具有本地存储器(包括程序存储器和数据存储器)。因此,程序代码的单独部分可以在不同的瓦片上并发运行。这些瓦片经由片上互连(on-chipinterconnect)而连接在一起,这使得在不同瓦片上运行的代码能够在瓦片之间进行通信。在一些情况下,每个瓦片上的处理单元可以采取桶形线程处理单元(或其他多线程处理单元)的形式。每个瓦片可以具有上下文组和执行流水线,使得每个瓦片可以并发地运行多个交错线程。
通常,在阵列中的不同瓦片上运行的程序的各部分之间可以存在依赖性。因此,需要一种技术来防止一个瓦片上的一段代码在它所依赖于的数据被另一瓦片上的另一段代码使其可用之前运行。存在许多用于实现此目的的可能方案,但是本文中感兴趣的方案被称为“批量同步并行”(bsp)。根据bsp,每个瓦片以交替的方式执行计算阶段和交换阶段。在计算阶段期间,每个瓦片在瓦片上本地执行一个或多个计算任务,但是不将其计算的任何结果与任何其他瓦片通信。在交换阶段,允许每个瓦片将来自先前计算阶段的计算的一个或多个结果交换到组中的一个或多个其他瓦片,和/或徙组中的一个或多个其他瓦片交换,但是在该瓦片完成交换阶段之前尚未开始新的计算阶段。此外,根据这种形式的bsp原理,屏障同步被置于从计算阶段过渡到交换阶段,或者从交换阶段过渡到计算阶段,或两者的接合点处。也就是说:(a)在允许组中的任何瓦片继续到下一个交换阶段之前,需要所有瓦片都完成其各自的计算阶段,或者(b)在允许组中的任何瓦片继续到下一个计算阶段之前,组中的所有瓦片都需要完成其各自的交换阶段,或者(c)两者。当在本文中使用时,短语“在计算阶段和交换阶段之间”包含所有这些选项。
在机器智能中可以找到多线程和/或多瓦片并行处理的示例性使用。如机器智能领域的技术人员所熟悉的,机器智能算法“能够产生知识模型”并使用知识模型来运行学习和推理算法。结合知识模型和算法的机器智能模型可以被表示为多个互连节点的图形(graph)。每个节点表示其输入的功能。一些节点接收对图形的输入,一些接收来自一个或多个其他节点的输入。一些节点的输出激活形成其他节点的输入,一些节点的输出提供图形的输出,并且对图形的输入提供对一些节点的输入。此外,由一个或多个相应参数例如权重对每个节点处的功能进行参数化。在学习阶段期间,目标是基于一组经验输入数据,找到针对各种参数的值,使得图形作为整体将针对可能输入范围而生成期望的输出。用于这样做的各种算法在本领域中是已知的,诸如基于随机梯度下降(stochasticgradientdescent)的反向传播算法(backpropagationalgorithm)。在多次迭代后,逐渐调整参数以减少它们的差错,并且因此图形收敛于解。在随后的阶段,学习的模型然后可以被用来在给定一组指定输入的情况下对输出进行预测,或者在给定一组指定输出的情况下对输入(原因)进行推断,或者可以对其执行其他内省形式的分析。
每个节点的实现将涉及数据的处理,并且图形的互连对应于要在节点之间交换的数据。通常,每个节点的至少一些处理可以独立于图形中的一些或所有其他节点来被执行,因此大的图形显露出巨大并行性的机会。
技术实现要素:
如上所提及,表示知识模型的机器智能模型和关于知识模型如何被用来学习和推理的算法信息通常可以由多个互连节点的图形来表示,每个节点对数据具有处理要求。图形的互连指示要在节点之间要被交换的数据,并因此导致在节点处执行的程序片段之间的依赖性。通常,节点处的处理可以独立于另一节点而被执行,因此大的图形显露出巨大的并行性。高度分布式的并行机器是适合用于计算这种机器智能模型的机器结构。此特征使得机器能够被设计为实现某些时间确定性保证。
在本公开中利用的知识模型的因素是图形的一般静态性质。也就是说,在执行机器智能算法期间,包含图形的节点和图形的结构通常不会改变。发明人已经制造了一种机器,其使得某些时间确定性保证能够优化机器智能模型上的计算。这允许编译器以时间确定性的方式在节点上进行划分和调度工作。正是这个时间确定性在下面描述的实施例中被利用以用于在设计被优化以基于知识模型处理工作负载的计算机时的显著优化。
根据本发明的一个方面,提供了一种计算机,包括多个处理单元,每个处理单元具有保存本地程序的指令存储,执行所述本地程序的执行单元,用于保存数据的数据存储;具有输入线组的输入接口,和具有输出线组的输出接口;切换结构,所述切换结构通过相应的输出线组而连接到每个处理单元,并通过相应的输入线经由每个处理单元可控制的切换电路而连接到每个处理单元;同步模块,所述同步模块可操作以生成同步信号以控制所述计算机在计算阶段和交换阶段之间进行切换,其中所述处理单元被配置为根据公共时钟执行其本地程序,所述本地程序使得在交换阶段中至少一个处理单元从其本地程序执行发送指令,以在发射时间将数据包发射到其输出连接线组上,所述数据包的目的地是至少一个接收处理单元但没有目的地标识符,并且在预定的切换时间,所述接收处理单元从其本地程序执行切换控制指令,以控制其切换电路将其输入线组连接到所述切换结构以在接收时间接收所述数据包,所述发射时间、切换时间和接收时间由公共时钟相对于同步信号来管控。
本发明的另一方面提供了一种在计算机中计算功能的方法,包括:多个处理单元,每个处理单元具有保存本地程序的指令存储,用于执行本地程序的执行单元,用于保存数据的数据存储,具有输入线组的输入接口和具有输出线组的输出接口;切换结构,所述切换结构通过相应的输出线组而连接到每个处理单元,并通过其相应的输入线经由每个处理单元可控制的切换电路而连接到每个处理单元;和同步模块,所述同步模块可操作以生成同步信号以控制所述计算机在计算阶段和交换阶段之间进行切换,所述方法包括:处理单元根据公共时钟在计算阶段执行其本地程序,其中在交换阶段的预定时间,至少一个处理单元从其本地程序执行发送指令,以在发射时间将数据包发射到其输出连接线组,所述数据包的目的地是至少一个接收处理单元但没有目的地标识符,并且在预定的切换时间,所述接收处理单元从其本地程序执行切换控制指令以控制切换电路将其输入线组连接到所述切换结构以在接收时间接收所述数据包,发送时间、切换时间和接收时间由公共时钟相对于同步信号来管控。
原则上,可以生成同步信号以控制从计算阶段到交换阶段的切换,或者从交换阶段到计算阶段的切换。然而,对于本文所定义的时间确定性架构,优选的是,生成同步信号以开始所述交换阶段。在一个实施例中,每个处理单元向所述同步模块指示其自己的计算阶段完成,并且当所有处理单元已经指示其自己的计算阶段完成时,由所述同步模块生成同步信号,以开始所述交换阶段。
应该预先确定发射时间,以便能够正确地完成所述时间确定性交换。假设执行所述发送指令的时间是预先确定的,可以通过在执行所述发送指令的时间之后的已知数量的时钟周期来确定之。可替代地,所述发射时间可以是从执行所述发送指令已知的时间以某种其他方式确定的已知延迟。重要的是,所述发射时间相对于预期接收处理单元上的接收时间而言是已知的。
所述发送指令的特征可以包括所述发送指令显式地定义发送地址,所述发送地址标识所述数据存储中将从其中发送所述数据包的位置。可替代地,在发送指令中没有显式地定义发送地址,并且所述数据包是从由所述发送指令隐式地定义的寄存器中所定义的发送地址被发射的。所述本地程序可以包括用于更新所述隐式寄存器中的所述发送地址的发送地址更新指令。
在本文所描述的实施例中,切换电路包括多路复用器,其具有连接到其处理单元的退出输出线组,以及连接到所述切换结构的多组输入线,由此,由所述处理单元控制来选择所述多组输入线中的一组输入线。每组可包括32位。当使用64位数据时,一对多路复用器可以连接到处理单元并一起进行控制。
在所描述的实施例中,所述接收处理单元被配置为接收数据包并将其加载到数据存储中由存储器指针所标识的存储器位置。在将每个数据包加载到所述数据存储中之后,所述存储器指针可以自动递增。可替代地,所述接收处理单元处的所述本地程序可以包括更新所述存储器指针的存储器指针更新指令。
所述发送指令可以被配置为标识要发送的多个数据包,其中,每个数据包与不同的发射时间相关联,因为它们是从所述处理单元串行发送的。
可以控制所述多路复用器的输入线组之一以连接到空输入(nullinput)。这可以被用来忽略到达所述处理单元的数据。
预期用于接收特定数据包的所述接收处理单元可以是在较早时间执行发送指令的相同处理单元,由此所述相同的处理单元被配置为发送数据包并在稍后时间接收该数据包。处理单元“发送给自身”的目的可能是遵循:将传入数据与从其他处理单元接收的数据交错地布置在其存储器中。
在一些实施例中,至少两个所述处理单元可以发射对协作,其中第一数据包从该对的第一处理单元经由其输出连接线组被发射,并且第二数据包从该对的第一处理单元经由该对的第二处理单元的输出连接线组被发射,以实现双宽传输(doublewidthtransmission)。在一些实施例中,该对中的至少两个控制其切换电路,以将其相应的输入线组连接到所述切换结构,以接受来自发送对的相应瓦片的相应数据包。
多个处理单元可以被配置为执行相应的发送指令以发射相应的数据包,其中至少一些数据包的目的地不是接收处理单元。
可以以包括多个互连节点的静态图形的形式提供正在计算的功能,每个节点由本地程序的小代码(codelet)实现。小代码定义图形中的顶点(节点),并且可以被视为执行的原子线程(atomicthread),稍后在说明书中讨论。在计算阶段,每个小代码可以处理数据以产生结果,其中一些结果对于后续计算阶段不是必需的,并且不被任何接收处理单元接收。它们被有效地丢弃,但不需要做出任何积极的丢弃行动。在交换阶段,经由切换结构和切换电路在处理单元之间发射数据包。注意,在交换阶段,从本地程序执行一些指令以实现交换阶段。这些指令包括发送指令。虽然计算阶段负责计算,但请注意,在交换阶段期间包括一些算术或逻辑功能是可能的,前提是这些功能不包括对本地程序定时的数据依赖性,以使其保持同步。
本文所描述的时间确定性架构在图形表示机器智能功能的上下文中特别有用。
切换结构可以被配置成使得在交换阶段中经由一系列临时存储以流水线的方式通过它发射数据包,每个存储保存数据包一个公共时钟周期。
附图说明
为了更好地理解本发明并示出如何实现本发明,现在将通过示例的方式对以下附图进行参考。
图1示意性地图示出了单芯片处理器的架构;
图2是连接到切换结构的瓦片的示意图;
图3是图示出bsp协议的图;
图4是示出时间确定性交换中的两个瓦片的示意图;
图5是图示出时间确定性交换的示意性定时图;
图6是机器智能图的一个示例;
图7是图示出用于生成时间确定性程序的编译器的操作的示意性架构;和
图8到图11图示出了在时间确定性架构中可用的不同指令的指令格式。
图12是操作为发射对的两个瓦片的示意图;和
图13是操作为接收对的两个瓦片的示意图。
具体实施方式
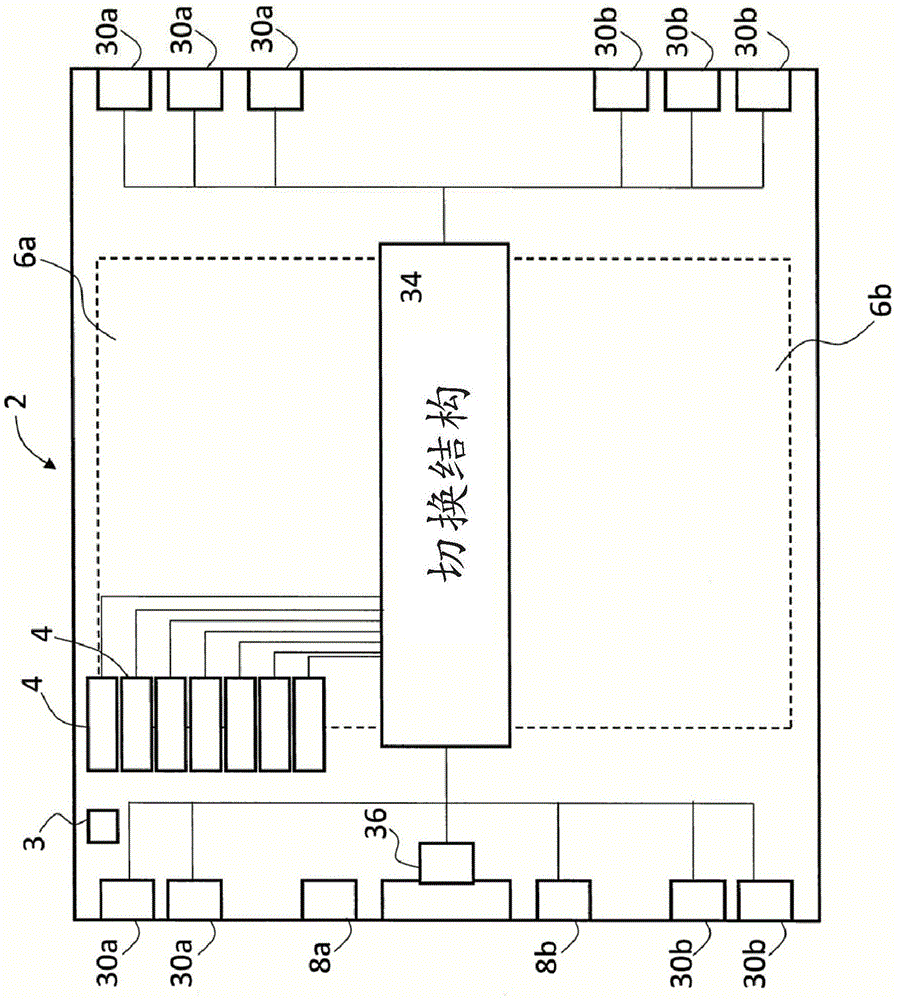
图1示意性地图示出了单芯片处理器2的架构。处理器在本文中被称为ipu(智能处理单元),以表示其对机器智能应用的适应性。在计算机中,单芯片处理器可以如稍后所讨论的那样使用芯片上的链路而连接在一起以形成计算机。本说明书集中于单芯片处理器2的架构。处理器2包括被称为瓦片的多个处理单元。在一个实施例中,有1216个瓦片被组织在在本文中被称为“北”和“南”的阵列6a、6b中。在所描述的示例中,每个阵列具有8列76个瓦片(实际上通常将有80个瓦片,为了冗余目的)。应当理解,本文所描述的概念扩展到许多不同的物理架构——这里给出一个示例以帮助理解。芯片2具有两条芯片到主机链路8a、8b和4条芯片到芯片链路30a、30b,其被布置在芯片2的“西”边缘上。芯片2从经由卡片到主机链路之一连接到芯片的主机(未示出)接收采取由芯片2处理的输入数据的形式的工作。芯片可以通过沿着芯片的“东”侧布置的另外6条芯片到芯片链路30a、30b而一起连接成卡片。主机可以访问计算机,该计算机被构造为如本文所述的单芯片处理器2或一组多个互连的单芯片处理器2,这取决于来自主机应用的工作量。
芯片2具有控制芯片活动的定时的时钟3。时钟连接到芯片的所有电路和组件。芯片2包括时间确定性切换结构34,所有瓦片和链路通过多组连接线连接到该切换结构34,该切换结构是无状态的,即没有程序可见状态。每组连接线被端对端固定。线是流水线的。在该实施例中,一组包括32条数据线加上控制线,例如一个有效位。每组可以携带32位数据包,但是在此注意,单词“包”(packet)表明表示数据(在本文中有时被称为数据项)的一组位,可能具有一个或多个有效位。“数据包”不具有报头(header)或任何形式的允许预期接收者被唯一标识的目的地标识符,它们也不具有包结束信息(end-of-packetinformation)。相反,它们每个都表示输入到瓦片或从瓦片输出的数值或逻辑值。每个瓦片都有自己的本地存储器(稍后描述)。瓦片不共享存储器。切换结构如稍后所述构成仅连接到多路复用器和瓦片的连接线交叉组并且不保存任何程序可见状态。切换结构被认为是无状态的并且不使用任何存储器。瓦片之间的数据交换是在如本文所述的时间确定性基础上实施的。流水线连接线包括一系列临时存储,例如在将数据释放到下一个存储之前保存一个时钟周期的数据的锁存器(1atch)或触发器(flipflop)。沿着线行进的时间由这些临时存储来确定,每个临时存储在任意两点之间的路径中用完一个时钟周期。
图2图示出了根据本公开的实施例的示例性瓦片4。在瓦片中,多个线程通过单个执行流水线被交错。瓦片4包括:多个上下文26,每个上下文被布置为表示多个线程中的不同的相应一个线程的状态;对于多个线程是公共的共享指令存储器12;对于多个线程同样是公共的共享数据存储器22;对于多个线程同样是公共的共享执行流水线14、16、18;和线程调度器(s)24,用于调度多个线程以用于以交错的方式通过共享流水线执行。线程调度器24在图中由时隙s0...s5的序列来示意性地表示,但实际上是管理线程的与其时隙相关的程序计数器的硬件机制。执行流水线包括提取级14、解码级16、以及包括执行单元(exu)和加载/存储单元(lsu)的执行级18。每个上下文26包括用于表示相应线程的程序状态的相应寄存器组r0、r1...。
在线程调度器24的控制下,提取级14被连接以从指令存储器12中提取要执行的指令。线程调度器24被配置为控制提取级14以从本地程序提取指令以用于在每个时隙中执行,如将在下面更详细地讨论的。
提取级14可以访问当前分配给时隙的每个线程的程序计数器(pc)。对于给定的线程,提取级14从指令存储器12中的下一个地址提取该线程的下一个指令,如线程的程序计数器所指示的。注意,本文所指的指令意味着机器代码指令,即计算机指令组的基本指令之一的实例,由操作码和零个或多个操作数组成。还要注意,加载到每个瓦片中的程序由处理器或编译器确定,以基于所支持的机器智能模型的图形来分配工作。
然后,提取级14将所提取的指令传递到解码级16以进行解码,然后解码级16将解码指令的指示连同指令中所指定的当前上下文的任何操作数寄存器的解码地址一起传递给执行级18,以便执行指令。
在本示例中,线程调度器24根据轮循(round-robin)方案对线程进行交错,由此,在该方案的每一轮次内,该轮次被划分成时隙序列s0、s1、s2、s3,每个时隙用于执行相应的线程。通常,每个时隙是一个处理器周期长,并且不同的时隙是均匀大小的(但是在所有可能的实施例中不一定如此)。然后重复该模式,每一轮次包括每个时隙的相应实例(在每个实施例中每次以相同的顺序,但在所有可能的实施例中同样也不一定如此)。因此,请注意,本文所指的时隙意味着序列中的重复分配位置,而不是时隙在序列的给定重复中的特定实例。在所图示的实施例中,存在八个时隙,但是其他数量也是可能的。每个时隙与用于管理执行线程的上下文的硬件资源例如寄存器相关联。
标记为sv的上下文26之一被保留用于特殊功能,以表示“监督者”(sv)的状态,其工作是协调“工作者”线程的执行。可以将监督者实现为程序,其被组织为可以并发运行的一个或多个监督者线程。监督者线程还可以负责执行稍后描述的屏障同步,或者可以负责用于在瓦片之上或之外以及在本地存储器之中和之外交换数据,因此可以在计算之间的工作者线程之间共享之。线程调度器24被配置成,当程序作为一个整体开始时,通过将监督者线程分配给所有时隙而开始,即,监督者sv开始在所有时隙s0...s5中运行。但是,向监督者线程提供了一种机制,用于在某个后续点(直接或者在执行一个或多个监督者任务之后)将其正在运行的每个时隙暂时放弃给相应的一个工作者线程,c0、c1表示工作者线程已分配到的时隙。这是通过监督者线程执行放弃指令来实现,在本文中通过示例的方式称为“run”。在实施例中,该指令采用两个操作数:指令存储器12中的工作者线程的地址和数据存储器22中针对该线程的一些数据的地址:
runtask_addr,data_addr
每个工作者线程都是一个小代码,旨在表示图形中的顶点并以原子方式执行。也即是说,其消耗的所有数据在启动时可用,并且它产生的所有数据在其退出之前对其他线程都不可见。它运行完成(除了差错条件)。数据地址可以指定要由小代码作用于其上的一些数据。可替代地,放弃指令可以只采用指定小代码地址的单个操作数,并且数据地址可以被包括在小代码的代码中;或者单个操作数可以指向指定小代码的地址和数据的数据结构。小代码可以彼此独立地并且并发地运行。
无论哪种方式,这个放弃指令(“run”)作用于线程调度器24,以便将当前时隙——即在其中执行该指令的时隙放弃给由操作数指定的工作者线程。注意,在放弃指令中隐含它是正在被放弃的执行该指令的时隙(在机器代码指令的上下文中隐含意味着它不需要操作数来指定它——从操作码本身隐含地理解它)。因此,交出的时隙是监督者执行放弃指令的时隙。或者换句话说,监督者正在它所交出的相同空间中执行。监督者说“在这个时隙运行这个小代码”,然后从那点起,该时隙由相关的工作者线程(暂时)拥有。注意,当监督者使用时隙时,它不使用与该时隙相关联的上下文,而是使用其自己的上下文sv。
监督者线程sv在每个时隙中执行类似的操作,以将其所有的时隙c0、c1交给不同的相应工作者线程。一旦它对了最后一个时隙这样做,监督者就会暂停执行,因为它没有可以在其中执行的时隙。注意,监督者可以不交出它所有的时隙,它可以保留一些用于自身的运行。
当监督者线程确定是时候运行小代码时,它使用放弃指令(“run”)将该小代码分配给它在其中执行”run”指令的时隙。
时隙c0、c1中的每个工作者线程继续执行其一个或多个计算任务。在其(一个或多个)任务结束时,工作者线程然后将其正在运行的时隙交回给监督者线程。
这是通过工作者线程执行退出指令(“exit”)来实现的。在一个实施例中,exit指令采取至少一个操作数并且优选地仅采取单个操作数,退出状态(例如二进制值),以用于程序员期望的任何目的,以在结束时指示相应小代码的状态。
exitexit_state
在一个实施例中,exit指令作用于调度器24,使得将在其中执行它的时隙归还给监督者线程。然后,监督者线程可以执行一个或多个后续监督者任务(例如,屏障同步和/或存储器中的数据移动以促进工作者线程之间的数据交换),和/或继续执行另一个放弃指令以将新的工作者线程(w4等)分配给所说的时隙。因此,再次注意,指令存储器12中的线程总数可以大于桶形线程处理单元10在任何一个时刻可以交错的数量。监督者线程sv的作用是调度来自指令存储器12的哪个工作者线程w0...wj在整个程序的哪一级将被执行。
在另一个实施例中,exit指令不需要定义退出状态。
该指令作用于线程调度器24,使得将在其中执行它的时隙返回给监督者线程。然后,监督者线程可以执行一个或多个监督者后续任务(例如,屏障同步和/或数据交换),和/或继续执行另一个放弃指令等等。
如上面简要提到的,在芯片中的瓦片之间交换数据。每个芯片都运行批量同步并行协议,包括计算阶段和交换阶段。协议例如在图3中被图示出。图3中的左侧图表示计算阶段,其中每个瓦片4处于状态小代码在本地存储器(12、22)上执行的阶段。尽管在图3中,瓦片4被示出被布置成圆形,但这仅用于说明目的而不反映实际的架构。
在计算阶段之后,存在由箭头30表示的同步。为达到这一点,在处理器的指令组中提供sync(同步)指令。sync指令具有使监督者线程sv等待直到所有当前正在执行的工作者w借助exit指令已退出的效果。在实施例中,sync指令将模式取为操作数(在实施例中是其唯一的操作数),该模式指定sync是否仅本地地仅与在同一处理器模块4例如同一瓦片上本地运行的那些工作者线程相关地作用,或者是否它跨多个瓦片或甚至跨多个芯片进行应用。
sync模式//模式∈{瓦片,芯片,zone_1,zone_2}
bsp本身在本领域中是已知的。根据bsp,每个瓦片4在交替的周期中执行计算阶段52和交换(有时称为通信或消息传递)阶段50。计算阶段和交换阶段由执行指令的瓦片执行。在计算阶段52期间,每个瓦片4在瓦片上本地执行一个或多个计算任务,但是不将这些计算的任何结果与瓦片4中的任何其他瓦片通信。在交换阶段50中,允许每个瓦片4将来自前面计算阶段的计算的一个或多个结果交换(通信)到该组中的一个或多个其他瓦片和/或从其交换,但是还是不执行任何对在另一个瓦片4上执行的任务具有潜在依赖性或者在另一个瓦片4上的任务可能潜在地对其具有依赖性的新计算(不排除可以在交换阶段中执行诸如内部控制相关的操作之类的其他操作)。此外,根据bsp原理,屏障同步被置于从计算阶段52过渡到交换阶段50的接合点,或者从交换阶段50过渡到计算阶段52的接合点或两者。也就是说:(a)在允许组中的任何瓦片继续到下一个交换阶段50之前,需要所有瓦片4都完成它们各自的计算阶段52,或者(b)在允许组中的任何瓦片继续到下一个计算阶段52之前,需要群组中的所有瓦片4都完成它们各自的交换阶段50,或者(c)这两个条件都被强制执行。然后,这个交换和计算阶段的序列可以重复多次重复。在bsp术语中,交换阶段和计算阶段的每次重复在本文中被称为“超步”(superstep),与bsp的一些先前描述中的使用一致。在本文中应注意,术语“超步”有时在本领域中被用来表示交换阶段和计算阶段中的每一个。
执行级18的执行单元(exu)被配置成:响应于sync指令的操作码,当由片上(瓦片间)操作数限定时,使得其中“sync芯片”被执行的监督者线程被暂停,直到阵列6中的所有瓦片4完成了工作者的运行。这可以被用来实现对下一个bsp超步的屏障,即,在芯片2上的所有瓦片4已经通过屏障之后,交叉瓦片程序作为整体可以前进到下一个交换阶段50。
每个瓦片向同步模块36指示其同步状态。一旦已经确定每个瓦片准备好发送数据,则同步过程30使系统进入交换阶段,该交换阶段在图3的右手侧示出。在这个交换阶段,数据值在瓦片之间(实际上在存储器到存储器数据移动中在瓦片的存储器之间)移动。在交换阶段,不存在可能在瓦片程序之间引起并发危险的计算。在交换阶段,每个数据沿着连接线移动,在连接线上,其将瓦片从发射瓦片退出到一个或多个接收瓦片。在每个时钟周期,数据以流水线方式沿其路径(存储到存储)移动一定距离。当从瓦片发出数据时,不会发出标识接收瓦片的报头。相反,接收瓦片知道它将在某个时间期望来自某个发射瓦片的数据。因此,本文所描述的计算机是时间确定性的。每个瓦片操作由程序员分配给它或由编译器练习的程序,其中程序员或编译器功能知晓特定瓦片在某个时间将被发射什么以及接收瓦片在某个时间需要接收什么。为了实现这一点,将send(发送)指令包括在由处理器在每个瓦片上执行的本地程序中,其中send指令的执行时间相对于在计算机中的其他瓦片上执行的其他指令的定时而言是预先确定的。这将在后面更详细地描述,但首先将描述接收瓦片可以在预定时间接收数据的机制。每个瓦片4与其自己的多路复用器210相关联:因此,芯片具有1216多路复用器。每个多路复用器具有1216个输入,每个输入为32位宽(加上可选的一些控制位)。每个输入连接到切换结构34中相应的连接线组140x。切换结构的连接线还连接到从每个瓦片输出数据连接线组218(后面描述的广播交换总线),因此存在1216组连接线,在该实施例中,这些连接线在穿过芯片的方向上延伸。为了便于说明,示出了单个加粗的线组140sc,其连接到南阵列6b中的出自图2中未示出的瓦片的数据输出线218s。这组线被标记为140x,以指示它是多组交叉线1400-1401215中的一组。如现在从图2中可以看出的,应当理解,当将多路复用器210切换到标记为220x的输入时,则这将连接到交叉线140x并因此连接到来自南阵列6b的瓦片(图2中未示出)的数据输出线218s。如果控制多路复用器在某个时间切换到该输入(220sc),那么在连接到该组连接线140x的数据输出线上接收的数据将在某个时间出现在多路复用器210的输出230处。它将在此之后的一定延迟后到达瓦片4,该延迟取决于多路复用器距瓦片的距离。由于多路复用器形成切换结构的一部分,因此从瓦片到多路复用器的延迟可以取决于瓦片的位置而变化。为了实现切换,在瓦片上执行的本地程序包括切换控制指令(puti),其使得多路复用器控制信号214被发出以控制与该瓦片相关联的多路复用器以在预期在瓦片上接收特定数据的时间之前的某个时间切换其输入。在交换阶段,切换多路复用器并使用切换结构在瓦片之间交换包(数据)。从该说明中可以清楚地看出,切换结构没有状态——每个数据的移动由每个多路复用器的输入所切换到的特定线组预先确定。
在交换阶段,启用所有瓦片到所有瓦片通信。交换阶段可以具有多个周期。每个瓦片4具有对其自己的唯一输入多路复用器210的控制。可以选择来自连接链路之一或来自芯片中的任何其他瓦片的传入业务。注意,将多路复用器设置为接收“空”输入是可能的——即,在该特定交换阶段中没有来自任何其他瓦片的输入。选择可以在交换阶段逐个周期地改变;它不必始终保存不变。取决于所选择的链路,数据可以在芯片上交换、或从芯片到芯片交换或从芯片到主机交换。本申请主要涉及芯片上的瓦片间通信。为了在芯片上执行同步,从所有瓦片向芯片上的同步控制器36提供少量流水线信号,并且从同步控制器回向所有瓦片广播流水线同步信号。在一个实施例中,流水线信号是一位宽的菊花链and/or(和/或)信号。实现瓦片之间同步的一种机制是上面提到或者在下面描述的sync指令。可以利用其他机制:重要的是所有瓦片可以在芯片的计算阶段和芯片的交换阶段之间被同步(图3)。sync指令触发以下功能性以在瓦片4上的专用同步逻辑中以及在同步控制器36中被触发。同步控制器36可以在硬件互连34中实现,或者如所示,可以在单独的片上模块中实现。瓦片上同步逻辑和同步控制器36二者的这种功能性在专用硬件电路中实现,使得一旦执行sync芯片,其余的功能性继续进行而无需执行另外的指令。
首先,瓦片上同步逻辑使得所说的瓦片4上的监督者的指令发出自动暂停(使得提取级14和调度器24暂停发出监督者的指令)。一旦本地瓦片4上的所有未完成的工作者线程都已经执行退出(exit),则同步逻辑自动向同步控制器36发送同步请求“sync_req”。然后,本地瓦片4继续等待,并且暂停监督者指令发出。类似的过程也在阵列6中的每个其他瓦片4上实现(每个瓦片包括其自己的同步逻辑的实例)。因此,在某个点处,一旦当前计算阶段52中的所有最终工作者已经在阵列6中的所有瓦片4上退出(exit),则同步控制器36将已从阵列6中的所有瓦片4接收到相应的同步请求(sync_req)。只有这样,响应于从同一芯片2上的阵列6中的每个瓦片4接收到sync_req,同步控制器36将同步确认信号“sync_ack”发送回到每个瓦片4上的同步逻辑。直到此时,每个瓦片4都已暂停其监督者指令发出,等待同步确认信号(sync_ack)。在接收到sync_ack信号后,瓦片4中的同步逻辑自动取消对该瓦片4上的相应监督者线程的监督者指令发出的暂停。监督者然后可以在随后的交换阶段50中自由地继续经由互连34与其他瓦片4交换数据。
优选地,经由互连34中将每个瓦片4连接到同步控制器36的一个或多个专用同步线,分别向同步控制器和从同步控制器发送和接收sycn_req和sync_ack信号。
现在将更详细地描述瓦片的连接结构。
每个瓦片具有三个接口:
exin接口224,其将数据从切换结构34传递到瓦片4;
exout接口226,其通过广播交换总线218将数据从瓦片传递到切换结构;和
exmux接口228,其将控制多路复用器信号214(mux-select)从瓦片4传递到其多路复用器210。
为了确保每个单独的瓦片在适当的时间执行send指令和切换控制指令以发射和接收正确的数据,将各个程序分配给计算机中的各个瓦片的程序员或编译器需要让交换调度要求被满足。该功能由交换调度器执行,该调度器需要知道以下交换定时(bnet)参数。为了理解这些参数,图4中示出了图2的简化版本。图4还示出了接收瓦片(tid1)以及发射瓦片(tid0)。
i.每个瓦片的相对sync确认延迟,bnet_rsak(tid)。tid是稍后描述的tile_id寄存器中保存的瓦片标识符。这是总是大于或等于0的周期数,其指示每个瓦片相对于最早接收瓦片何时从同步控制器36接收ack信号(确认信号)。这可以从瓦片id计算出,注意,瓦片id指示该瓦片在芯片上的特定位置,并且因此反映了物理距离。图4示出了一个发射瓦片4t和一个接收瓦片4r。尽管仅示意性地示出并且未按比例示出,但是瓦片4t被指示为更靠近同步控制器并且瓦片4r被指示为更远,结果是瓦片4t的同步确认延迟将比瓦片4r更短。对于同步确认延迟,特定值将与每个瓦片相关联。这些值可以被保存在例如延迟表中,或者可以每次基于瓦片id在运行中被计算。
ii.交换多路复用器控制环路延迟,bnet_mxp(接收瓦片的tid)。这是发出改变瓦片的输入多路复用器选择的指令(puti-muxptr)与同一瓦片可以为存储在存储器中的交换数据发出(假设的)加载指令的最早点——作为新的多路复用选择的结果之间的周期数。参见图4,该延迟包括控制信号从接收瓦片4r的exmux接口228r到其多路复用器210r以及从多路复用器的输出到数据输入exin接口224的线路的长度而来的延迟。
iii.瓦片到瓦片的交换延迟,bnet_tt(发送瓦片的tid,接收瓦片的tid)。这是在一个瓦片上发出的send指令与接收瓦片可以发出指向其自己的存储器中的发送值的(假设的)加载指令的最早点之间的周期数。这已经通过访问诸如已经讨论过的表格或者通过计算而根据发送和接收瓦片的瓦片id来确定。再次参见图4,该延迟包括数据从发射瓦片4t从其ex_out接口226t沿其交换总线218t到切换结构14并且然后经由接收瓦片4r处的输入多路复用器210r到接收瓦片的ex_in接口224r行进所花费的时间。
iv.交换业务存储器指针更新延迟,bnet_mmp()。这是发出改变瓦片的交换输入业务存储器指针的指令(puti-memptr)与该同一瓦片可以为存储在存储器中的交换数据发出(假设的)加载指令的最早点——作为新指针的结果之间的周期数。这是一个小的固定周期数。存储器指针尚未被讨论,但在图2中被示为参考标号232。它充当指向数据存储器202的指针并指示来自ex_in接口224的传入数据要被存储的位置。这稍后将更详细地进行描述。
图5更深入地示出了交换定时。在图4的左侧是从0-30运行的ipu时钟周期。发送瓦片4t上的动作发生在ipu时钟周期0和9之间,从发出发送指令(发送f3)开始。在ipu时钟周期10到24中,数据流水线穿过切换结构34。
在ipu时钟周期11中查看接收瓦片4r,执行puti指令,其改变瓦片输入多路复用器选择:puti-mxptr(f3)。在图5中,该puti指令被标记为“putiincomingmux(f3)”。
在周期18中,执行存储器指针指令puti-memptr(f3),在itu时钟周期25中允许加载指令。在图5中,该puti指令被标记为“putiincomingadr(f3)”。
在发送瓦片4t上,ipu时钟周期1、3和5被标注为“传输()”。这是在send指令的发布和exout接口f4上的send指令的数据的表现之间的内部瓦片延迟,e1、e3等表示从传输到exout接口的先前send指令的数据。ipu时钟周期2被分配以形成用于send指令的地址e0。注意,这是从中提取e0的位置,而不是其目的地地址。在ipu时钟周期4中,执行存储器宏以从存储器中提取e2。在ipu时钟周期6中,在e4上执行奇偶校验。在ipu时钟周期7中,执行mux输出指令以发送e5。在ipu时钟周期8中e6被编码,并且在ipu时钟周期中e7被输出。
在交换结构34中,ipu时钟周期10到24被标记为“交换流水线级”。在每个周期中,数据沿着流水线(在临时存储之间)移动“一步”。
周期25-28表示在exin接口处接收数据之间在接收瓦片4r上的延迟(参见针对exc的存储器宏(e2)),而周期25-29表示在exin接口处接收数据与将其加载到存储器之间的延迟(参见针对ld的存储器宏(e2))。可以在该延迟中执行其他功能——参见最早的ld(f3)、regfilerd(f4)、形成地址(e0)、传输(e1)。
简单来说,如果接收瓦片4r的处理器想要作用于作为发射瓦片4t上的过程理的输出的数据(例如,f3),则发射瓦片4t不得不在某个时间(例如图5中的ipu时钟周期0)执行send指令[send(f3)],并且接收瓦片不得不在相对于在发射瓦片上执行send指令[send(f3)]的特定时间(如在ipu时钟周期11中)而执行切换控制指令putiexchmxptr。这将确保数据及时到达接收瓦片以在ipu周期25中被加载[最早的ld(f3)]以用于在接收瓦片处执行的小代码中使用。
注意,接收瓦片处的接收过程不需要像指令putimemptr那样涉及设置存储器指针。相反,存储器指针232(图2)在exin接口224处接收到每个数据之后自动递增。然后将接收到的数据加载到下一个可用存储器位置中。然而,改变存储器指针的能力使得接收瓦片能够更改写入数据的存储器位置。所有这些都可以由编译器或程序员确定,编译器或程序员将各个程序写入各个瓦片,以便它们正确地通信。这导致内部交换(芯片上的内部交换)的定时完全是时间确定性的。交换调度器可以使用此时间确定性来高度优化交换序列。
图6图示出了本文所公开的处理器架构的示例性应用,即,对机器智能的应用。
如前所提及的并且如机器智能领域的技术人员所熟悉的,机器智能从学习阶段开始,其中机器智能算法学习知识模型。该模型可以被表示为互连的节点102和链路104的图形60。节点和链路可以被称为顶点和边缘。图形中的每个节点102具有一个或多个输入边缘和一个或多个输出边缘,其中一些节点102的一些输入边缘是一些其他节点的输出边缘,从而将节点连接在一起以形成图形。此外,一个或多个节点102的一个或多个输入边缘作为整体形成对图形的输入,并且一个或多个节点102的一个或多个输出边缘作为整体形成图形的输出。每个边缘104通常以张量(n维矩阵)的形式传送值,这些值分别形成在其输入和输出边缘上提供给节点102和从节点102提供的输入和输出。
每个节点102表示在其一个或多个输入边缘上接收的其一个或多个输入的功能,该功能的结果是在一个或多个输出边缘上提供的(一个或多个)输出。这些结果有时被称为激活(activation)。由一个或多个相应参数(有时称为权重,但它们不需要一定是乘法权重)对每个功能进行参数化。通常,由不同节点102表示的功能可以是不同形式的功能和/或可以通过不同参数来参数化。
此外,每个节点的功能的一个或多个参数中的每一个的特征在于相应的差错值。此外,相应的差错条件可以与每个节点102的(一个或多个)参数中的(一个或多个)差错相关联。对于表示由单个差错参数参数化的功能的节点102,差错条件可以是简单阈值,即如果差错在指定的阈值内,则满足差错条件,但如果差错超出阈值,则不满足条件。对于由多于一个相应参数参数化的节点102,针对该节点102的差错条件可能更复杂。例如,仅当该节点102的每个参数都落入相应阈值内时,才可以满足差错条件。作为另一示例,可以定义组合度量来组合针对相同节点102的不同参数中的差错,并且在组合度量的值落入指定阈值内的条件下可以满足差错条件,但是如果组合度量值超出阈值则不满足差错条件(或者反之亦然,取决于度量的定义)。无论差错条件如何,这都给出了节点的(一个或多个)参数中的差错是否低于某一可接受程度或水平的度量。
在学习阶段,算法接收经验数据,即表示对图形的输入的不同可能组合的多个数据点。随着越来越多的经验数据被接收,该算法基于经验数据逐渐调整图形中各节点102的参数,以试图最小化参数中的差错。目标是找到参数的值,使得图形的输出尽可能接近期望的结果。由于图形作为整体倾向于这种状态,因此计算据称会收敛。
例如,在监督方法中,输入经验数据采取训练数据的形式,即与已知输出相对应的输入。对于每个数据点,算法可以调整参数,使得输出更接近地匹配针对给定输入的已知输出。在随后的预测阶段中,该图形然后可以被用来将输入查询映射到近似预测输出(或者如果进行推断则反之亦然)。其他方法也是可能的。例如,在无监督的方法中,不存在每个输入数据的参考结果的概念,而是改为将机器智能算法留下来在输出数据中标识其自己的结构。或者在强化方法中,算法针对输入经验数据中的每个数据点试验至少一个可能的输出,并且被告知该输出是正还是负(并且可能被告知正或负的程度),例如赢或输、或奖励或惩罚、或类似的。在许多试验中,算法可以逐渐调整图形的参数,以便能够预测将导致正结果的输入。用于学习图形的各种方法和算法对于机器学习领域的技术人员来说是已知的。
根据本文所公开的技术的示例性应用,每个工作者线程被编程为执行与机器智能图形中的相应的各个节点102相关联的计算。在这种情况下,节点102之间的边缘104对应于线程之间的数据的交换,其中至少一些可以涉及瓦片之间的交换。
图7是图示出编译器70的功能的示意图。编译器接收这样的图形60并将图形中的功能编译成多个小代码,这些小代码被包含在图7中被标记为72的本地程序中。每个本地程序被设计为加载到计算机的特定瓦片中。每个程序包括一个或多个小代码72a、72b...加上监督者子程序73,其每一个都由指令序列形成。编译器生成程序,使得它们在时间上相互链接,即它们是时间确定性的。为了做到这一点,编译器访问瓦片数据74,瓦片数据74包括瓦片标识符,瓦片标识符指示瓦片的位置以及因此编译器需要了解的延迟以便生成本地程序。上面已经提到了延迟,并且可以基于瓦片数据来计算延迟。可替代地,瓦片数据可以并入数据结构,其中这些延迟可通过查找表获得。
现在接下来描述新的指令,这些指令是作为用于本文所定义的计算机架构的指令组的一部分而被开发的。图8示出了32位的send指令。send指令指示来自瓦片存储器的数据传输。它使得存储在瓦片的本地存储器22中的特定地址处的一个或多个数据在瓦片的exout接口处被发射。每个数据(在指令中被称为“项目”)可以是一个或多个字长。send指令作用于一个字或多个字以实现发送功能。send指令具有操作码80、表示消息计数的字段82、以一个或多个包的形式从地址字段84中表示的send地址发送的项目的数量。地址字段84以立即值的形式定义本地存储器中从中发送项目的地址,该立即值被添加到存储在基址寄存器中的基值。send指令还有发送控制字段86(sctl),其表示字大小,被选择为4和8字节之一。该包之中没有目的地标识符:换句话说,在该指令中没有唯一地标识要接收项目的接收瓦片。发送功能使得来自发送地址的指定数量的数据项目从本地存储器被访问并被放置在瓦片的ex_out接口处以在下一个时钟周期被发射。在send指令的另一个变体中,要从中发送项目的地址可以是隐含的;取自基址寄存器中的基值和传出增量寄存器中的增量值。可以基于先前send指令中的信息来设置增量值。代替预期接收瓦片的唯一标识符,编译器已经布置为:正确的接收瓦片将在正确的时间切换其(一个或多个)本地多路复用器以接收数据(数据项目),如本文已经描述的。注意,在某些情况下,预期的接收瓦片可能是发射瓦片本身。
为此,提供切换控制功能,如上所述。图9说明了执行此功能的put-i-mux指令。操作码字段90将指令定义为put-i-mux指令。可以通过延迟立即值92来指定延迟时段。该延迟值可以被用来替换“noop”(无操作)指令,并且是优化代码压缩的一种方式。该指令在被执行时在incoming_mux字段98中定义多路复用器210的哪个输入将被设置为“监听”已经从另一个瓦片发送的项目。为了紧凑的缘故,这个多路复用控制功能可以在单个指令中与上面定义的发送功能组合,如图10中所示。注意,在导致瓦片充当发射瓦片的发送功能和作为当瓦片正在充当接收瓦片时的一个功能的切换控制功能之间没有连接——除了它们可以在同一瓦片上的单个执行周期中执行之外。
图10是“合并”指令的示例。在此上下文中,“合并”指令意味着定义两个或更多个功能的指令,这些功能可以在一个瓦片上同时(在一个执行周期中)被执行。
图10图示出了“合并”发送指令的形式,其中发送功能与第二功能组合,该第二功能可以修改在瓦片处的寄存器中所保存的状态。一个功能是改变用于该瓦片上接收的数据的存储器指针。另一个功能是设置传入的mux。puti_memptr功能启用本地存储器中的存储器位置,在该位置处加载由瓦片接收的下一个数据以进行识别。该功能可以通过专用的“接收”指令来执行,但是其功能不是启用数据的接收而是修改存储器指针。实际上,不需要执行特别的指令以在瓦片处接收数据。在exin接口的控制下,到达exin接口处的数据将被加载到由存储器指针识别的下一个存储器位置中。图10的指令具有操作码字段100和要被发送的项目数量字段102。传入状态修改字段106中的立即值被写入由字段104指定的交换配置状态寄存器。在一种形式中,状态修改字段106可以写入传入增量,用于计算存储器指针要被设置的接收地址。在另一种形式中,用传入的mux值写入交换配置状态,该值设置多路复用器输入。
对于这种形式的“合并”指令,发送功能使用在指令中所隐含的从存储在一个或多个寄存器中的值所确定的发送地址。例如,可以从基址寄存器和增量寄存器确定发送地址。
图11显示了“双倍宽度”指令,称为交换指令(exch)。该指令从瓦片存储器中的指示地址发起数据传输,并设置传入交换配置状态(多路复用器和/或用于接收数据的存储器指针)。exch指令的独特之处在于:它后面紧跟内联32位有效负载,其在指令之后立即位于存储器位置处。exch指令具有表示交换指令exch的操作码字段110。有效负载具有“coissue”标志119。
exch指令包括格式字段112,其具有指定传入格式数据宽度(32位或64位)的单个位。数据宽度可能会影响多路复用器线路的设置,如下所述。项目字段114定义导致由交换指令发送的项目的数量。这些项目是从使用字段116中的立即计算的发送地址发送的,如图9的发送指令中那样。该字段中的值被添加到基址寄存器中的值。
参考标号118表示控制字段,其定义用于发送数据的字大小。有效负载包括切换控制字段120,其作用于传入的多路复用器的切换控制,如上面结合图9所述。标号122表示有效负载的字段,其定义用于计算要存储传入数据的地址的传入增量,如上结合图10的指令所述。图11的64位宽交换指令exch可以在每个时钟周期被执行,并且因此同时允许:
·从特定地址发送
·更新传入的多路复用器
·更新传入地址
因此,任何交换调度都可以被编码在单个指令中。图8、图9和图10的指令执行类似的功能,但因为它们只有32位长可以被用来最小化每个瓦片的本地存储器中的交换代码的大小。在构造用于本地程序72的小代码时,在编译器70处做出关于在任何特定上下文中使用哪个指令的决定。
下面是关键寄存器列表及其用以支持上述指令的语义。这些寄存器形成每个瓦片上的寄存器文件的一部分。
注意,incoming_delta和incoming_mux寄存器形成瓦片的交换状态的一部分。
现在将参考图12来解释瓦片配对,其是物理瓦片对可以协作的特征,以便更有效地使用它们的组合交换资源。通过借用邻居(neighbour)的传输总线,可以使用瓦片配对来使单个瓦片的传输带宽加倍,或者通过共享邻居的接收总线和相关联的传入多路复用器,使瓦片对中的两个瓦片的接收带宽加倍。
图12示出了与用于执行双宽传输的瓦片对中的瓦片相关联的逻辑。通过在send期间借用邻居的传出交换资源来实现双宽传输。在此期间,邻居瓦片无法执行自己的数据传输。send指令能够执行单宽或双宽数据传输,传输宽度由寄存器或立即字段中保存的值指定。宽度可以表示为32位(一个字),在这种情况下字段的值为0,或者宽度也可以表示为64位(两个字),在这种情况下字段的值为1。其他逻辑定义也是可能的。指定的宽度从芯片4上的寄存器传递到瓦片的xout接口226中的控制存储1200。图12显示了两个这样的成对瓦片:tid00和tid01。xout接口226具有用于容纳最低有效字(leastsignificantword,lsw)和最高有效字(mostsignificantword,msw)的缓冲器。在这种情况下,每个字是32位。最低有效字直接连接到宽度控制多路复用器1202的输入。多路复用器的输出连接到交换总线34的相应交叉线,所述交叉线对应于该特定瓦片的输出线。如果发射宽度被设置为32位,则宽度控制多路复用器1202被设置为从成对瓦片的相应lsw接收输入,从而允许该对的瓦片同时发射相应的32位字。
如果该对中的一个成员希望发送64位字,则相邻瓦片的宽度控制多路复用器1202被设置为从发送瓦片接收最高有效字输出并将其传递到多路复用器的输出。这将使得来自发送瓦片的64位输出的最高有效字被放置在与相邻瓦片相关联的交换总线的交叉线上(此时禁止发送任何东西)。为了清楚起见,来自发送瓦片tid00的存储1200中的宽度控制标记的mux控制线被示出连接到相邻(非发送)瓦片tid01的多路复用器1202的控制输入。类似地,相邻瓦片tid01还具有从其控制存储1200连接到其配对瓦片的宽度控制多路复用器1202的输入的mux控制线,但是为了清楚起见未在图12中示出。
现在将参考图13来解释使用成对的瓦片的双宽接收。图13中的成对瓦片被标记为tid03和tid04,但是将容易理解,该功能性可以与双宽发射功能结合使用,使得像tid00这样的瓦片也可以具有例如在tid03上示出的功能性。通过在传输期间共享邻居的传入交换资源来实现双宽接收。配置为双宽接收时,瓦片对中的每个瓦片可以选择采样或忽略传入数据。如果他们都选择采样,他们将看到相同的传入数据。通过前面描述的incoming_format值与邻居瓦片协作启用双宽接收,该值标识输入数据是32位还是64位。必须将瓦片对的主要瓦片的传入多路复用器210的值设置为发送瓦片的瓦片id。必须将瓦片对内的次要瓦片的传入多路复用器210的值设置为发送对内的另一瓦片的瓦片id。注意,在这种情况下,严格来说,发送瓦片对(例如tid01)的“发送”瓦片实际上并不是发送,而是提供了最高有效字以使用瓦片tid00的交换资源。因此,接收瓦片对的瓦片的传入多路复用器210必须分别连接到交叉线,在交叉线上放置了发送对的双宽传输输出的各个字。
注意,在一些实施例中,即使传入多路复用器210被切换为同时监听它们相应的交换的交叉线,这也不一定意味着输入值将同时在接收瓦片对的瓦片处被接收,因为交换和个别瓦片之间的行进延迟不同。因此,在瓦片的接收对中有三种可能性。
在第一种可能性中,exin接口的两个传入总线将被独立处理(瓦片对中的瓦片都不参与双宽接收)。
根据第二种可能性,本地传入交换总线用于传输双宽项目的早期组件(并且该组件现在应该被延迟)。这意味着邻居的总线将用于传输相同双宽项目的非早期组件。
根据第三种可能性,本地传入交换总线用于传输双宽项目的非早期组件。这意味着邻居的总线用于传输相同双宽项目的早期组件(因此邻居总线上的早期数据组件应该被延迟)。
图13示出了使用多路复用器1302和1304处理这些场景的电路1300。注意,电路1300在接收瓦片对的每个瓦片的输入上重复,但是为了清楚起见仅在tid03的输入上示出。
对多路复用器的控制来自传入格式控制,其从寄存器提供到exin接口224。如果瓦片tit03将以32位模式操作,则它控制多路复用器1302经由流水线级1306和控制缓冲器1308在图13中的多路复用器的上部输入处通传递32位字。
如果接收瓦片成对操作,则控制多路复用器1302以阻止其上部输入并允许最低有效字从下部输入传递到流水线级1306。在下一个周期,最高有效字被选择随着已通过流水线级1306计时的最低有效字通过多路复用器1304传递到控制缓冲器1308。控制缓冲器1308可以决定是否接收64位字。注意,根据逻辑,将在相邻瓦片(tid04)处同时接收64位字。在某些情况下,两个瓦片可能想要读取相同的64位值,但在其他情况下,其中一个瓦片可能希望忽略它。
注意,可能存在这样的实施例,其中64位传输的lsw和msw可以在其成对的接收瓦片处被同时接收,在这种情况下,将不需要流水线级1306的相对延迟。
本文已经描述了一种新的计算机范例,其在用于机器学习的知识模型的上下文中特别有效。提供了一种架构,其如在bsp范例的交换阶段中那样利用时间确定性来有效地处理非常大量的数据。虽然已经描述了特定实施例,但是一旦给出了本公开审理,所公开的技术的其他应用和变化对于本领域技术人员而言将变得显而易见。本公开的范围不由所描述的实施例来限制,而是仅由所附权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!