一种实现影响因素多源异构融合的农作物产量预测方法与流程
本发明涉及多源异构数据的融合和挖掘领域,特别涉及一种实现影响因素多源异构融合的农作物产量预测方法。
背景技术:
目前通用的农作物长势检测和产量估算方法主要有传统的气象估产方法和农学估产方法,这两种方法在大面积或大范围的农作物估产中,精度会有较大的起伏,因为农作物的产量受许多因素的影响。
而由于农业大数据的分散性、多样性和复杂性,影响农作物产量的诸多因素包括农学数据、气象数据、地理数据等,具有多源异构性。因此需要基于农作物产量的多源异构特性进行产量预测,常见的预测算法如回归分析等无法处理产量影响因素来自不同数据源,具有不同种类特征的问题。
对于不同数据源的数据融合通常采用神经网络、卡尔曼滤波(kalman)等方法,但对于大数据的处理,卡尔曼滤波方法对脏数据很敏感,而且滤波参数计算不确定,会导致预测精度不高;神经网络方法在使用中,参数设置不当会出现学习不足或过学习现象,会陷入局部极小,处理大数据时,易出现维数灾难,从而导致预测精度不高。
为此需要一种通过不同数据源的农业大数据高精度预测农作物产量的方法。
技术实现要素:
本发明的目的在于提供一种实现影响因素多源异构融合的农作物产量预测方法,以提高农作物产量的预测精度。
为解决上述技术问题,本发明技术方案如下:
一种实现影响因素多源异构融合的农作物产量预测方法,包括如下步骤:
s1、获取农业的大数据,大数据包括:农作物历年产量数据和影响产量的指标数据,指标数据包括:历年气象数据和土壤特性数据;
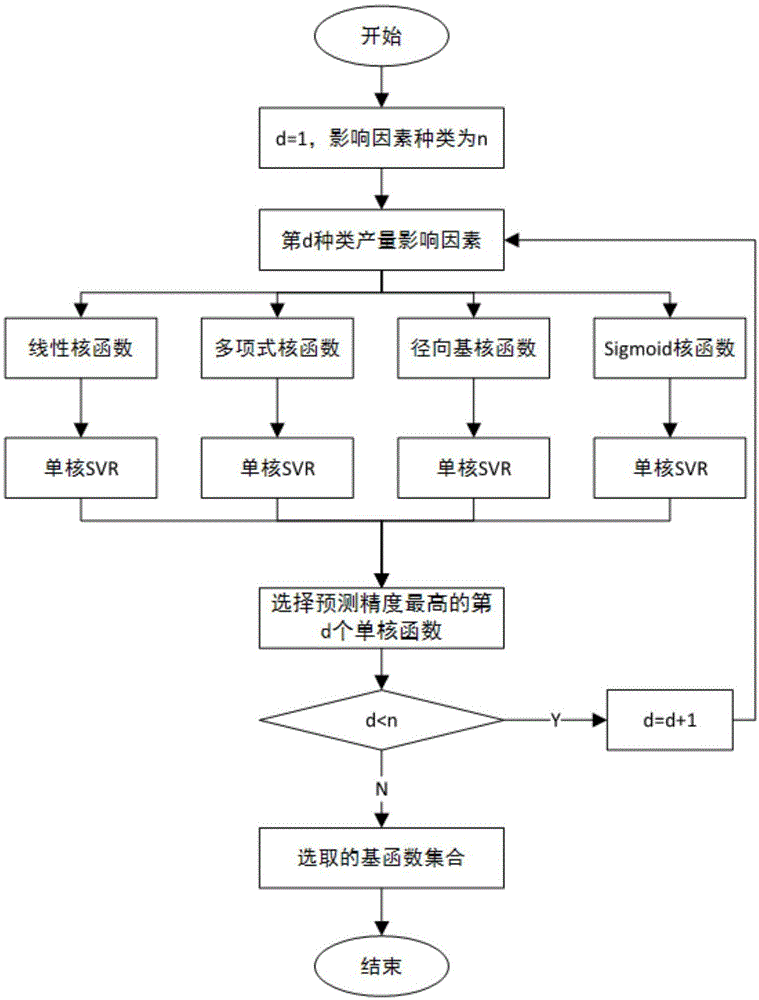
s2、建立包含线性核函数、多项式核函数、径向基核函数和sigmoid核函数的单核函数库;
s3、根据单变量法从单核函数库中选取单核函数,将大数据作为单核函数的输入变量,构建成为单核svr模型;
s4、利用单核svr模型进行预测,分别选取精度最接近1的单核函数,构成基核函数;其中基核函数的参数包括:基核函数的权重、基核函数自身核参数的取值和惩罚项的系数;
s5、初始化基核函数的参数,形成初始线性多核函数;建立包括粒子位置的粒子群优化算法,利用粒子群优化算法对初始线性多核函数的参数进行联合迭代优化,构建多核svr预测模型;利用优化后的多核svr预测模型进行初步预测,得到预测结果;
s6、建立包括估计值和精确值的交叉验证算法;利用交叉验证算法验证预测结果;取结果中估计值和精确值相关系数的均值作为适应度值,根据适应度值的大小更新基核函数各参数的值;其中,适应度值越接近1,表面预测结果精度越高;
s7、粒子群优化算法达到最大迭代次数或粒子位置满足最小界限时,输出基核函数各参数的值,得到最终的预测方程。
基础方案原理及有益效果如下:
1、本方法对农作物产量的预测考虑了多种影响因素的作用;利用多核svr预测模型进行预测,融合了多种核,能有效处理多源异构的数据;
2、借助粒子群优化算法自动学习得到基核函数的参数,不需要主观确定基核函数的参数。因此能提高预测的合理性和精度;
3、粒子群优化算法比遗传算法规则更为简单,它没有遗传算法的“交叉”和“变异”操作;实现容易、精度高;
4、单核函数的精度值越接近于1,表明其预测精度越高,选取精度最接近1的单核函数构成基核函数,有助于提高预测精度。
进一步,步骤s5中,初始线性多核函数,表示为:
其中,kh(x,y)为基核函数,λh∈(0,1),λh为核函数的权重,权重之和为1,m为核函数的个数。
不同的核函数,选取对应的单核函数,针对性强,准确度高。
进一步,所述s3还包括:步骤s5中,粒子位置包括总群最优位置和个体最优位置;利用粒子群优化算法对初始线性多核函数的参数进行联合迭代优化时,每个粒子根据之前的种群最优位置和个体最优位置信息调整自身位置,调整公式为:
其中,r1、r2为区间[0,1]上的随机数,可取该区间均匀分布的伪随机数,vi(k)、
与遗传算法比较,粒子群优化算法的信息共享机制是很不同的。在遗传算法中,染色体互相共享信息,所以整个种群的移动是比较均匀的向最优区域移动。在粒子群优化算法中,只有总群最优位置的粒子或个体最优位置的粒子给出信息给其他的粒子,这是单向的信息流动。粒子对自身位置的调整更新过程是跟随当前最优解的过程。与遗传算法比较,在大多数的情况下,所有的粒子可能更快的收敛于最优解。
进一步,步骤s6中,交叉验证算法的计算公式为:
其中,
交叉验证算法用于评估初始线性多核函数的预测精度,可以在一定程度上减小过拟合;还可以从有限的数据中获取尽可能多的有效信息。
进一步,步骤s3中,交叉验证采用五折交叉验证。
五折交叉验证的结果与十折交叉验证的结果相差无几,但是五折交叉验证计算次数更少,耗费时间更短。
进一步,步骤s1中,指标数据还包括:水环境数据和地理位置数据。
引入水环境数据和地理位置数据,增加了数据的类型的丰富性。
附图说明
图1为实施例一确定基核函数的流程图;
图2为实施例一利用粒子群优化算法优化多核svr预测模型的流程图;
图3为实施例一预测误差折线图。
具体实施方式
下面通过具体实施方式进一步详细说明:
实施例一
实现影响因素多源异构融合的农作物产量预测系统,包括:输入模块、储存模块、处理模块和输出模块;
输入模块用于输入农作物历年产量数据和影响产量的指标数据,其中,指标数据包括历年气象数据、土壤特性数据、水环境数据和地理位置数据。输入模块将输入的数据发送至储存模块;
储存模块用于接收农作物历年产量数据和影响产量的指标数据;储存模块预存有包括线性核函数、多项式核函数、径向基核函数、sigmoid核函数的单核函数库,还预存有粒子群优化算法和五折交叉验证算法;本实施例中,存储模块采用希捷st4000vn008机械硬盘。
处理模块用于调取存储模块中的数据和函数,对不同类型的数据分别根据单变量法从线性核函数、多项式核函数、径向基核函数或sigmoid核函数中选取对应的单核函数,构建单核svr模型;
本实施例中,单核srv模型构建过程为:
对于大数据的样本集t={(xi,yi)|i=1,2,...,l},其中,xi∈rn,xi为n维输入变量,yi为对应的输出值,l为样本数;寻求样本最优拟合函数为:f∈f=(f|f:rn→r),
可转化为求解约束极值问题:
使得,
其中,k(xi,xj)为核函数,利用非线性规划最佳解的必要条件(kkt条件)可以计算得到
ai,aj,b,最后得到单核srv模型:
利用单核svr模型进行预测,分别选取精度最接近1的单核函数,构成基核函数;基核函数的参数包括:基核函数的权重、基核函数自身核参数的取值和惩罚项的系数;初始化基核函数的权重、基核函数自身核参数的取值和惩罚项的系数,利用基核函数形成初始线性多核函数,表示为:
其中,kh(x,y)为基核函数,kh(x,y),λh为核函数的权重,权重之和为1,m为核函数的个数。
处理模块利用粒子群优化算法对基核函数的权重、基核函数自身核参数的取值和惩罚项的系数进行联合迭代优化,将式①中的核函数替换为初始线性多核函数,构建多核svr预测模型;
利用粒子群优化算法迭代优化过程中,每个粒子根据之前的种群最优和个体最优位置信息调整自身位置,调整公式为:
其中,r1、r2为区间[0,1]上的随机数,可取该区间均匀分布的伪随机数,vi(k)、
使用交叉验证多核svr预测模型的泛化预测能力,采用估计值
本实施例中使用五折交叉验证,取五次结果的r2均值作为适应度函数,其值越接近于1,表明预测精度越高。
根据适应度的值更新基核函数各参数的值,直到达到粒子群优化算法最大迭代次数或粒子全局最优位置满足最小界限。
处理模块将基核函数各参数的值发送至输出模块;本实施例中,处理模块采用intel至强e5-2690处理器。
输出模块将基核函数各参数的值输出,得到最终的预测方程;本实施例中,输出模块采用delle2216hv显示器。
基于实现影响因素多源异构融合的农作物产量预测系统,本发明还提供一种实现影响因素多源异构融合的农作物产量预测方法,包括如下步骤:
s1、获取农业的大数据,大数据包括:农作物历年产量数据和影响产量的指标数据,指标数据包括:历年气象数据、土壤特性数据、水环境数据和地理位置数据;
s2、建立包含线性核函数、多项式核函数、径向基核函数和sigmoid核函数的单核函数库;
s3、如图1所示,根据单变量法从线性核函数、多项式核函数、径向基核函数或sigmoid核函数中选取对应的单核函数,将大数据作为单核函数的输入变量,构建单核svr模型;例如对于历年气象数据,利用其作为输入变量,从单核函数库中的四个核函数中选取一个单核函数,构建单核svr模型;
s4、利用单核svr模型进行预测,分别选取精度最接近1的单核函数,构成基核函数;基核函数的参数包括:基核函数的权重、基核函数自身核参数的取值和惩罚项的系数;
s501、初始化基核函数的权重、基核函数自身核参数和惩罚项的系数,利用基核函数形成初始线性多核函数,表示为:
其中,kh(x,y)为基核函数,kh(x,y),λh为核函数的权重,权重之和为1,m为核函数的个数。
s502、如图2所示,建立包括粒子位置的粒子群优化算法(pso),粒子位置包括总群最优位置和个体最优位置;利用粒子群优化算法对初始线性多核函数的参数进行联合迭代优化;将式①中的核函数替换为初始线性多核函数,构建多核svr预测模型;
利用粒子群优化算法对初始线性多核函数的参数进行联合迭代优化时,每个粒子根据之前的种群最优位置和个体最优位置信息调整自身位置,调整公式为:
其中,r1、r2为区间[0,1]上的随机数,可取该区间均匀分布的伪随机数,vi(k)、
利用多核svr预测模型进行初步预测,得到预测结果;
s6、建立包括估计值和精确值的交叉验证算法;利用交叉验证算法验证多核svr预测模型的预测结果;取结果中估计值和精确值相关系数的均值作为适应度值,根据适应度值的大小更新基核函数各参数的值;其中,适应度值越接近1,表面预测结果精度越高;
五折交叉验证算法的计算公式为:
其中,
s7、粒子群优化算法达到最大迭代次数或粒子位置满足最小界限时,输出基核函数各参数的值,得到最终的预测方程。
对比例一
与实施例一相比,区别在于,未采用五折交叉验证算法生成的适应度值更新基核函数各参数的值。
对比例二
与实施例一相比,区别在于,未使用粒子群优化算法对初始线性多核函数进行联合迭代优化。
在实验中,分别用神经网络算法、卡尔曼滤波算法和多核svr预测模型、对比例一和对比例二对2008-2012年重庆地区粮食产量数据进行预测,得到如表1的数据:
表1:
如图3所示,实验中的实际预测结果表明,在神经网络算法、卡尔曼滤波算法和多核svr预测模型中,神经网络算法预测结果波动幅度最小,但是预测准确度最低;卡尔曼滤波算法波动幅度最大;比例一和对比例二由于省略了步骤预测精度较低,多核svr预测模型波动幅度小,预测准确度高。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!