一种基于核主成分分析的日负荷曲线降维聚类方法与流程
本发明属于电力系统分析与控制技术领域,主要涉及基于核主成分分析的日负荷曲线降维聚类方法。
背景技术:
日负荷曲线聚类是配用电大数据挖掘的基础,对负荷预测、电网规划和需求侧响应均有一定的指导意义。随着智能电网的不断推进,电力系统信息化程度不断提高,用电信息采集系统、配网gis系统、配网自动化系统等逐渐完善,配用电数据呈现出数据量大、类型多、增长快等大数据特征。如何采取有效的数据挖掘技术,在大数据背景下对不同类型的海量用户进行精细化划分,从而挖掘出不同类型负荷间的内在联系及对应的用电行为、用电特性等信息,无疑对电网公司及电力用户具有重要的意义。
传统的日负荷曲线聚类方法通常以日负荷曲线各采样时刻点的功率值经极大值归一化后,采用k-means、模糊c均值等算法以欧式距离作为相似性判据对日负荷曲线进行聚类。该类方法存在如下两个弊端:1)作为时间序列的负荷曲线来说,曲线之间的相似性易受气温气候、收入、电价政策等许多因素的影响,不能通过距离得到充分反映,且像日负荷曲线这类有明显负荷形状的曲线,在高维情况下会出现不理想的等距性,从而造成负荷曲线的误分;2)随着负荷数据规模的不断增长,该类方法在计算效率上面临着巨大的挑战。
间接聚类方法可有效解决传统方法的两个弊端,通过对日负荷曲线进行降维处理,提取降维指标作为聚类算法的输入。但仍面临两个重要问题:1)降维指标及数目的确定;2)降维指标权重的确定。如何选择合适的降维指标数目并合理的配置各个指标的权重可以在很大程度上提升日负荷曲线聚类结果的准确性及效率。
技术实现要素:
本发明所解决的技术问题是,针对现有日负荷曲线聚类方法中存在的问题,提出一种基于核主成分分析的日负荷曲线降维聚类方法,通过合适的核函数将原始日负荷数据集向量做非线性映射至高维特征空间,并在高维特征空间进行主成分分析,获得线性成分替代原始非线性日负荷数据集向量并采用加权k-means算法进行日负荷曲线聚类。
本发明采取的技术方案为:
一种基于核主成分分析的日负荷曲线降维聚类方法,包括以下步骤:
步骤1),对日负荷功率曲线数据进行预处理:首先对日负荷功率曲线中的数据进行识别与修正,将负荷功率变化率超过预设阈值的数据识别为异常数据,并对出现异常和缺失数据的曲线通过一元三点抛物线插值算法进行修正,然后以日负荷功率曲线的功率最大值为基准值,对修正后的日负荷功率曲线数据进行标幺化处理,得到归一化的日负荷功率曲线有功功率标幺值矩阵作为原始数据矩阵;
步骤2),根据原始数据矩阵,首先选取高斯径向基核函数对其做非线性映射至高维特征空间,获得核矩阵,然后对核矩阵进行修正;
步骤3),对修正后的核矩阵做主成分分析,确定主成分分量及降维指标数目:首先进行特征值分解,获得特征值和特征向量,然后通过gram-schmidt正交法得到单位化特征向量,计算特征值对应的累计贡献率,然后通过拟合按顺序递增数量的特征值形成不同的拟合曲线,并选择与x轴、y轴所围图形的面积最小的拟合曲线所对应的特征值数量作为特征指标数目,并以该数目作为降维指标数目,且该数目对应的单位化特征向量即为主成分分量;
步骤4),以修正后的核矩阵在主成分分量上的投影得到的投影矩阵作为经核主成分分析降维后获得的降维数据矩阵,然后以各主成分分量对应的特征值作为降维指标权重,同时得到相应的降维指标权重向量;
步骤5),结合降维数据矩阵及降维指标权重向量,以加权k-means算法进行聚类:首先在降维数据矩阵中随机选择多个样本作为初始聚类中心,然后结合降维指标及指标权重向量来将各样本划分至相应加权欧式距离最小的初始聚类中心的聚类中,再根据所形成的每个聚类中的样本情况来更新聚类中心,接下来计算每个样本到聚类中心的平方误差,当平方误差小于上次迭代后得到的平方误差时则完成聚类,否则重新回到以上步骤进行新一轮的迭代;完成聚类后再计算不同聚类数下聚类结果的silhouette指标,取silhouette指标值最大的聚类数及聚类结果来作为最佳。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述的步骤1)包括以下过程:
步骤1-1),对日负荷功率曲线中的异常数据进行识别与修正:
首先异常数据进行识别,对某条负荷曲线在各采样时刻点的功率值pk=[pk,1,pk,2···,pk,m]t,以公式(1)对异常数据进行识别:
式中:δk,i为负荷曲线在第i点的负荷功率变化率,当超过预设的阀值ε后视为异常数据;
然后进行修正,若某条负荷曲线的数据缺失量和异常量不小于10%时,直接删除该条负荷曲线;
若某条负荷曲线的数据缺失量和异常量低于10%时,则通过一元三点抛物线插值算法来插值拟合以重新得到异常量与缺失量的值,一元三点抛物线插值算法包括以下步骤:
设n个节点xi(i=0,1,···,n-1)的函数值为yi=f(xi),有x0<x1<···<xn-1,对应函数值y0<y1<···<yn-1,为计算指定的插值点t的近似函数值z=f(t),选择最靠近t的3个节点:xk-1、xk、xk+1(xk<t<xk+1),然后根据抛物线插值公式(2)计算z的值,即
式中,当|xk-t|<|t-xk+1|时,m=k-1;当|xk-t|>|t-xk+1|时,m=k;
若插值点t不在包含n个节点的区间内,则只选取区间某一端的2个节点来进行线性插值;
步骤1-2),对修正后的日负荷功率曲线数据进行标幺化处理:
记pk=[pk1,...,pki,...,pkm]∈r1×m为修正后第k条日负荷功率曲线的m点原始有功功率矩阵,k=1,2,3,…,n,n为日负荷功率曲线总条数,pki为第k条日负荷功率曲线的第i点原始有功功率,i=1,2,…,m,m为采样点个数;则p=[p1,...,pk,...,pn]t∈rn×m为n条日负荷功率曲线的m点原始有功功率矩阵,其中r1×m指1行m列实数矩阵,rn×m指n行m列实数矩阵;
取日负荷功率曲线的功率最大值pk.max=max{pk1,pk2,...,pki,...,pkm}为基准值,根据式(3)对原始数据样本进行标幺化处理,
p'ki=pki/pk·max(3)
得到归一化的日负荷功率曲线有功功率标幺值矩阵:
p'k=[p'k1,p'k2,...,p'ki,…,p'km]∈r1×m,并令该矩阵为a∈rn×m,其中n为日负荷曲线条数。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述的步骤2)包括以下过程:
步骤2-1),对原始数据矩阵a做非线性映射至高维空间,获得核矩阵k:
设向量xi∈r1×m,yj∈r1×m,(i≠j)分别为原始数据矩阵a中的任意两条日负荷曲线标幺化数据,以高斯径向基核函数并按公式(4)对矩阵a做非线性映射,获得核矩阵k;
步骤2-2),对核矩阵k进行修正:
按照下式(5)对核矩阵k进行修正:
式(5)中:i,j=1,2,···,m,m为日负荷曲线维数也即采样点个数,n为日负荷曲线条数,对所有的i,j,有li,j=1。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述的步骤3)包括以下过程:
对修正后的核矩阵k做主成分分析的方法步骤为:
a)对修正后的核矩阵k做特征值分解,获得特征值λ1,λ2,···,λn及对应的特征向量v1,v2,···,vn;
b)将特征值做降序排列,并调整对应的特征向量;
c)利用gram-schmidt正交法单位化特征向量,获得α1,α2,···,αn;
主成分分量及降维指标数目的确定方法为:
计算特征值λ1,λ2,···,λn对应的累计贡献率b1,b2,···,bn,设定提取效率η,若第t个特征值所对应的累计贡献率大于设定的提取效率,即bt≥η,则将t设定为降维指标数目,而λ1,λ2,···λt所对应的单位化特征向量α1,α2,···αt即为主成分分量;其中效率η的设定方法按如下步骤进行:
a)设定效率η的初始值,使得t=3,以前三个特征值λ1,λ2,λ3拟合曲线y=ax+b,计算拟合曲线与x轴、y轴所围图形的面积s1;
b)改变效率η的初始值,使得t=4,5,6….,计算拟合曲线与x轴、y轴所围图形的面积s2,s3,s4…;
c)比较不同t值下所围图形面积的大小,面积最小时所对应的η即为提取效率,而满足此时bt≥η所对应的t即为最终确定的特征指标数目。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述的步骤4)包括以下过程:
降维数据矩阵b获得的方法为:
计算修正的核矩阵k在主成分分量上的投影y=k·α,其中α=(α1,α2,···αt),所得投影矩阵y即为数据经核主成分分析降维后获得的降维数据矩阵b;
降维指标权重向量的确定方法为:
设各主成分分量对应的特征值为λ1,λ2,···λt,各特征值所占权重按式(6)进行确定,
按照式(6)计算的到各指标对应的权重系数wi,也即确定了降维指标权重向量w=[w1,w2,···,wt]。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述的步骤5)包括以下过程:
以加权k-means算法进行聚类的步骤为:
a)初始化:初始化包括初始聚类数k、迭代次数n、初始聚类中心的初始化;
b)样本归类:在降维数据矩阵b中随机选择k个样本,作为初始聚类中心
c)更新聚类中心:设nj是由步骤b)获得的第j类样本的个数,yi,j为第j类中第i个样本,按下式(8)更新各类聚类中心;
d)迭代计算:设当前的迭代次数为t,按下式(9)计算矩阵b中所有样本到对应聚类中心的平方误差j(t),并与前一次的误差j(t-1)进行比较,若j(t)-j(t-1)<0,则跳转至步骤b),否则算法结束输出相应的聚类结果;
基于silhouette指标确定最佳聚类数及聚类结果的方法步骤为:
e)设定最大聚类数
f)基于kmin≤k≤kmax的不同聚类数k,通过加权k-means算法获得不同聚类数下的聚类结果,然后分别对这些聚类结果计算silhouette指标;
g)比较不同聚类数下的silhouette指标,silhouette指标最大时所对应的k值即为最佳聚类数k*,对应的结果即为最佳聚类结果。
所述的一种基于核主成分分析的日负荷曲线降维聚类方法,所述步骤f)中silhouette指标定义的方法为:
设n条日负荷曲线被分为k类,对于第j类中的第i个样本,定义da(i)为样本i与类内其他样本的平均距离,其值越小表明类内越紧凑;定义db(i)为样本i到非同类内所有样本的最小平均距离,其值越大表明类间越分散;则样本i的silhouette指标isil(i)按式(10)进行定义,所有样本的silhouette指标isilhouette按式(11)进行定义:
式(11)中isilhouette值越大表明聚类质量越好,其值为负表明聚类失效,isilhouette值最大所对应的k即为最佳聚类数,该k值对应下的聚类结果即为最佳聚类结果。
本发明的技术效果在于,本发明技术方案在大数据背景下可以很大程度上提升日负荷曲线聚类的效率及质量。另一方面,本发明可以有效解决间接聚类方法中降维处理过程中降维指标数目及权重难以确定等问题。聚类结果与工程实际相符,能够为电网公司分析用户用电行为,制定合理的用电计划提供有力的支撑。具有良好的应用前景。
附图说明
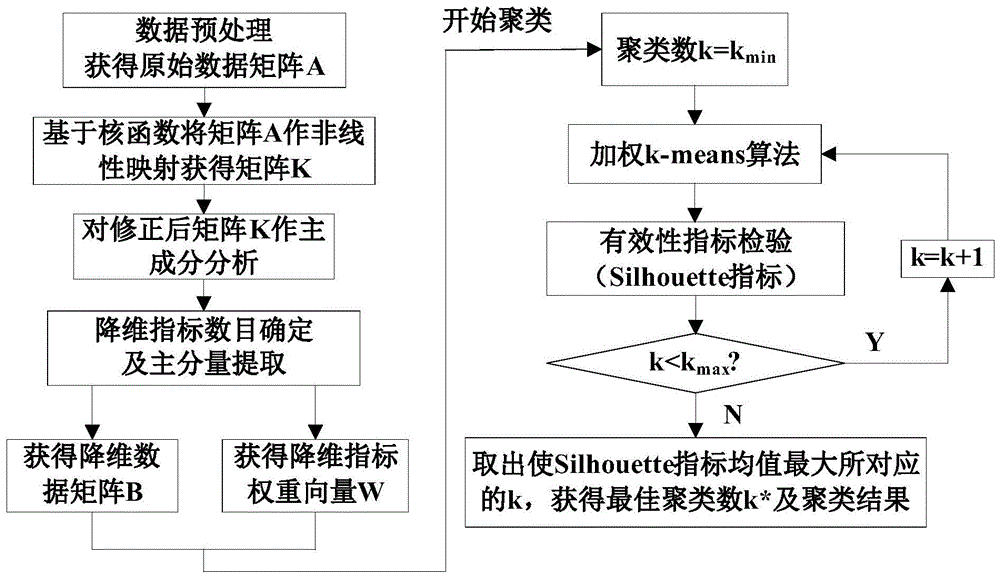
图1为本发明的方法总体思路框图。
图2为特征值降序排列结果图。
图3为加权k-means算法流程图。
图4为基于silhouette指标确定最佳聚类数及聚类结果流程图。
具体实施方式
本发明提出的基于核主成分分析的日负荷曲线降维聚类方法结合附图详细说明如下:
本发明的总体思路框图如图1所示,包括以下步骤:
1)对日负荷功率曲线数据进行预处理,获得原始数据矩阵a∈rn×m。其中n为日负荷曲线条数,m为维数也即采样点个数;
2)结合步骤1)所得原始数据矩阵a,选取高斯径向基(rbf)核函数对其做非线性映射至高维特征空间,获得核矩阵k,并对其进行修正;
3)对修正后的核矩阵k做主成分分析,确定主成分分量及降维指标数目;
4)结合步骤2)所得核矩阵k及步骤3)所确定的主成分分量获得降维数据矩阵b,以各主成分分量对应的特征值作为降维指标权重,并确定降维指标权重向量w;
5)结合步骤4)所得降维数据矩阵b及降维指标权重向量w,以加权k-means算法进行聚类,并基于silhouette指标确定最佳聚类数及聚类结果。
所述步骤1)包括以下步骤:
1-1)对日负荷功率曲线中的异常数据进行识别与修正;
1-2)对修正后的日负荷功率曲线数据进行标幺化处理;
对于以上步骤进行相关解释如下:
所述步骤1-1)中异常数据的识别方法具体为:
记pk=[pk,1,pk,2···,pk,m]t为某条负荷曲线在各采样时刻点的功率值,以公式(1)对异常数据进行识别。
式中:δk,i为负荷曲线在第i点的负荷功率变化率,当其超过预设的阀值ε后视为异常数据。在不失一般性的前提下,ε可取0.5~0.8。
所述步骤1-1)中异常数据的修正方法具体为:
若某条负荷曲线的数据缺失量和异常量达到10%或以上时,认定该曲线无效直接删除该条负荷曲线。
若某条负荷曲线的数据缺失量和异常量低于10%时,则将缺失量和异常量的值都置为0,再以一元三点抛物线插值算法对被置为0的缺失量和异常量进行插值拟合,以重新得到正常值。一元三点抛物线插值算法的原理为:
设n个节点xi(i=0,1,···,n-1)的函数值为yi=f(xi),有x0<x1<···<xn-1,对应函数值y0<y1<···<yn-1。为计算指定的插值点t的近似函数值z=f(t),选择最靠近t的3个节点:xk-1、xk、xk+1(xk<t<xk+1),然后根据抛物线插值公式(2)计算z的值,即
式中,当|xk-t|<|t-xk+1|时,m=k-1;当|xk-t|>|t-xk+1|时,m=k。
若插值点t不在包含n个节点的区间内,则只选取区间某一端的2个节点来进行线性插值。
所述步骤1-2)中对修正后的日负荷功率曲线数据进行标幺化处理的方法具体为:
记pk=[pk1,...,pki,...,pkm]∈r1×m为修正后第k条日负荷功率曲线的m点原始有功功率矩阵,k=1,2,3,…,n,n为日负荷功率曲线总条数,pki为第k条日负荷功率曲线的第i点原始有功功率,i=1,2,…,m,m为采样点个数也即维度,一般为48;则p=[p1,...,pk,...,pn]t∈rn×m为n条日负荷功率曲线的m点原始有功功率矩阵,其中r1×m指1行m列实数矩阵,rn×m指n行m列实数矩阵;
取日负荷功率曲线的功率最大值pk.max=max{pk1,pk2,...,pki,...,pkm}为基准值,根据式(3)对原始数据样本进行标幺化处理,
p'ki=pki/pk·max(3)
得到归一化的日负荷功率曲线有功功率标幺值矩阵p'k=[p'k1,p'k2,...,p'ki,...,p'km]∈r1×m,并令该矩阵为a∈rn×m。
2)结合步骤1)所得原始数据矩阵a,选取高斯径向基(rbf)核函数对其做非线性映射至高维特征空间,获得核矩阵k,并对其进行修正;所述步骤2)包括以下步骤;
2-1)对原始数据矩阵a做非线性映射至高维空间,获得核矩阵k;
2-2)对核矩阵k进行修正;
对以上步骤进行相关解释如下:
所述步骤2-1)中对原始数据矩阵a做非线性映射至高维空间,获得核矩阵k的方法具体为:
设向量xi∈r1×m,yj∈r1×m,(i≠j)分别为原始数据矩阵a中的任意两条日负荷曲线标幺化数据,以高斯径向基(rbf)核函数并按公式(4)对矩阵a做非线性映射,获得核矩阵k。
所述步骤2-2)中核矩阵k修正的方法为:
按照下式(5)对核矩阵k进行修正。
式(5)中:i,j=1,2,···,m,m为日负荷曲线维数,n为日负荷曲线条数,对所有的i,j,有li,j=1。
3)对修正后的核矩阵k做主成分分析,确定主成分分量及降维指标数目;
所述步骤3)中对修正后的核矩阵k做主成分分析的方法步骤为:
a)对修正后的核矩阵k做特征值分解,获得特征值λ1,λ2,···,λn及对应的特征向量v1,v2,···,vn;
b)将特征值做降序排列(图2为特征值降序排列结果),并调整对应的特征向量;
c)利用gram-schmidt正交法单位化特征向量,获得α1,α2,···,αn;
所述步骤3)中主成分分量及降维指标数目的确定方法为:
计算特征值λ1,λ2,···,λn对应的累计贡献率b1,b2,···,bn,设定提取效率η,若bt≥η,降维指标数目即设定为t,λ1,λ2,···λt所对应的单位化特征向量α1,α2,···αt即为主成分分量。其中效率η的设定方法按如下步骤进行:
a)设定效率η的初始值,使得t=3,以前三个特征值λ1,λ2,λ3拟合曲线y=ax+b,计算拟合曲线与x轴、y轴所围图形的面积s1;
b)改变效率η的初始值,使得t=4,5,6….,计算拟合曲线与x轴、y轴所围图形的面积s2,s3,s4…;
c)比较不同t值下所围图形面积的大小,面积最小时所对应的t即为最终确定的特征指标数目。
4)结合步骤2)所得核矩阵k及步骤3)所确定的主成分分量获得降维数据矩阵b,以各主成分分量对应的特征值作为降维指标权重,并确定降维指标权重向量w;
所述步骤4)中降维数据矩阵b获得的方法为:
计算修正所得核矩阵k在提取出的主成分分量上的投影y=k·α,其中α=(α1,α2,···αt)。所得投影矩阵y即为数据经核主成分分析降维后获得的降维数据矩阵b。
所述步骤4)中降维指标权重向量的确定方法为:
设各主成分分量对应的特征值为λ1,λ2,···λt,各特征值所占权重按式(6)进行确定。
按照式(6)即可获得各指标对应的权重系数wi,也即确定了降维指标权重向量w=[w1,w2,···,wt]。
5)结合步骤4)所得降维数据矩阵b及降维指标权重向量w,以加权k-means算法进行聚类,并基于silhouette指标确定最佳聚类数及聚类结果;
如图3所示,所述步骤5)中以加权k-means算法做聚类分析的步骤为:
a)初始化。初始化包括初始聚类数k、迭代次数n、初始聚类中心的初始化,迭代次数n一般取100;
b)样本归类。在降维数据矩阵b中随机选择k个样本,作为初始聚类中心
c)更新聚类中心。设nj是由步骤b)获得的第j类样本的个数,yi,j为第j类中第i个样本,按下式(8)更新各类聚类中心;
d)迭代计算。设当前的迭代次数为t,按下式(9)计算矩阵b中所有样本到对应聚类中心的平方误差j(t),并与前一次的误差j(t-1)进行比较,若j(t)-j(t-1)<0,则跳转至步骤b),否则算法结束输出相应的聚类结果。
如图4所示,所述步骤5)中基于silhouette指标确定最佳聚类数及聚类结果的方法步骤为:
a)设定最大、最小聚类数。不失一般性,设
b)取聚类数kmin≤k≤kmax,基于加权k-means算法获得不同聚类数下的聚类结果,计算不同聚类数下的silhouette指标。例如前一步骤得到kmax为10、kmin为2,那么设定的k值即在这个范围类变动,即计算聚类数为2-10之间的聚类结果,并计算这些聚类数下聚类结果的silhouette指标。
c)比较不同聚类数下的silhouette指标。silhouette指标最大时所对应的k值即为最佳聚类数k*,对应的结果即为最佳聚类结果。
对于以上步骤进行相关解释如下:
所述步骤b)中silhouette指标定义的方法具体为:
设n条日负荷曲线被分为k类,对于第j类中的第i个样本,定义da(i)为样本i与类内其他样本的平均距离,其值越小表明类内越紧凑;定义db(i)为样本i到非同类内所有样本的最小平均距离,其值越大表明类间越分散。则样本i的silhouette指标isil(i)按式(10)进行定义,所有样本的silhouette指标isilhouette按式(11)进行定义。
式(11)中isilhouette值越大表明聚类质量越好,其值为负表明聚类失效,isilhouette值最大所对应的k即为最佳聚类数。
本发明的基于核主成分分析的日负荷曲线降维聚类方法,首先利用高斯径向基(rbf)核函数对预处理后的日负荷数据矩阵做非线性映射至高维空间,获得核矩阵k;接着对核矩阵k做特征值分解获得对应特征值及单位化特征向量,并依据特征值下降趋势设定提取效率,获得主成分分量及降维指标数目;其次,以特征值作为降为指标的权重,对其做总和为1的归一化处理后获得权重向量w,以核矩阵在主成分分量上的投影作为降维数据矩阵b;最后以降维数据矩阵b及权重向量w作为加权k-means算法的输入对日负荷曲线进行聚类,并基于silhouette指标确定最佳聚类数及聚类结果。
- 还没有人留言评论。精彩留言会获得点赞!