基于文本分析和语义抓取技术的法律人工智能交互式平台的制作方法
本发明涉及大数据平台以及人工智能领域,旨在结合法律领域,利用文本分析和语义抓取技术实现用户和机器的智能交互,提供一整套法律纠纷的解决方案给用户,简化流程。
背景技术:
市场上出现的法律领域的相关技术提供法律纠纷解决方案的技术平台,产品介绍能提供的法律解决方案,通常仅能够提供相关的部分法律条文,甚至许多都是人工回复,其中一部分能实现和智能交互的产品,其实现方式大体包括用户通过诸如计算机等的终端产品输入自己的问题,计算机根据用户的问题,匹配预先设置的答案,该答案一般包括与用户问题对应的法律条文,基于此,本发明的发明人发现,如今市场上的技术功能简单仅能够通过关键词匹配提供相关法律条文,而无法真正提供一整套纠纷的解决方案,比如计算该纠纷案件赔偿金额,更无法为用户专门提供私人定制的专项建议,公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。
当今产品的不足,显而易见:第一,自成体系,但不具有权威性,无法有资格有能力精确定位用户法律纠纷的细分领域。第二,技术上无法实现智能化解决方案。第三,数据上无法实现多次聚集,形成潜在新的模式和新的数据(无法有效的使用机器学习技术)。第四,无法实现多领域交叉分析。第五,根本不是自动化,智能化,基本上依然是人工参与的。
但是当今市场,一是需要得到法律援助的市场巨大;二是明白了真正的价值体系来源于技术以及模式,而并非领域。如果能够时刻把技术和模式当作产品本身的价值,那么在设计产品的时候,关注点就不再是花哨的界面和华而不实的功能。而是,如何设计好平台的api,如何设计好可以自我改进的模式框架,如何提供二次多次的数据聚集和人工智能分析,如何定制人工智能的规则,让本产品能够高精度,多维度的定位出用户的纠纷领域,细分再细分,扩充解决方案数据库,随着应用端的数据增加,利用机器学习的技术,使产品不断迭代升级。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于文本分析和语义抓取技术的法律人工智能交互式平台。
本发明的目的可以通过以下技术方案来实现:
一种基于文本分析和语义抓取技术的法律人工智能交互式平台,包括:
文本信息接收和分析模块,用于对用户输入的问题进行识别以提取关键词;
关键词精确匹配模块,用于将关键词与法律词汇建立对应关系,确定与所述关键词对应的法律词汇,并根据所述法律词汇生成并显示包含所述法律词汇的联想句;
多维度数据库匹配模块,用于分析生成案例的解决方案;
智能交互和推送模块,用于根据用户输入的用户信息和数据变量,计算数据结果并生成法律解决方案。
所述关键词精确匹配模块工作过程具体包括步骤:
将提取的关键词与法律词汇建立对应关系;
确定与所述关键词对应的法律词汇;
根据所述法律词汇生成并显示包含所述法律词汇的联想句;
接受对联想句的选择;
建立所选择的联想句与法律条文的对应关系;
确定与选中的联想句对应的法律条文。
所述语义抓取是对文本数据以句子为单位,每一句话是一组数据,所述标题的关键词为用户问题中词义与问题含义最接近的单词。
所述多维度数据库匹配模块工作过程具体包括步骤:
生成法律解决方案,所述法律解决方案包括所述法律条文;
接受用户输入的数据变量;
用于大数据的积累和沉淀。
所述生成法律解决方案,解决方案内容包括:有效建议、计算赔偿金额、推送相关信息。
与现有技术相比,本发明就有以下优点:
1)运用语义抓取和文本分析技术让一个法律事务平台,全智能,无人工参与的和用户进行交互,反馈,建议,订制,推送。
2)通过多维度的模型设计和多维度的数据库搭建方式,使机器高精准匹配,达到了准确语义抓取和文本分析的目的。
3)此技术的运用可以轻松实现机器深度理解用户的文本意义。
附图说明
图1为本发明的结构示意图
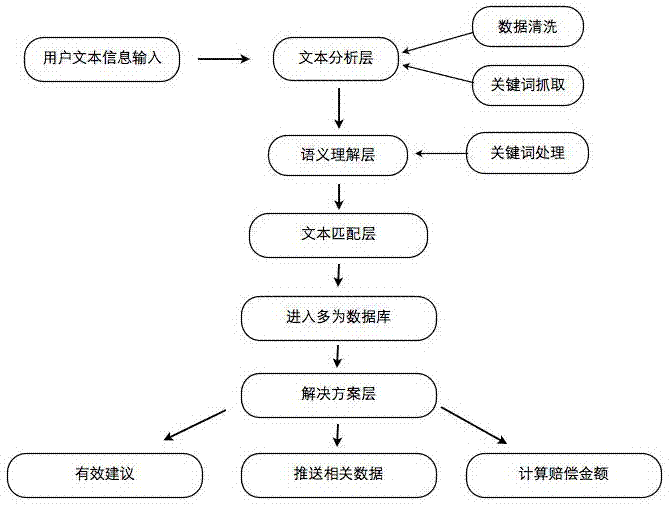
图2系统技术流程图
图3句式说明图
图4句式结构关系图
图5词汇与词汇的关系图
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
一种基于文本分析和语义抓取技术的法律人工智能交互式平台,包括:
文本信息接收和分析模块1,用于对用户输入的问题进行识别以提取关键词;
关键词精确匹配模块2,用于将关键词与法律词汇建立对应关系,确定与所述关键词对应的法律词汇,并根据所述法律词汇生成并显示包含所述法律词汇的联想句;
多维度数据库匹配模块3,用于分析生成案例的解决方案;
智能交互和推送模块4,用于根据用户输入的用户信息和数据变量,计算数据结果并生成法律解决方案。
关键词精确匹配模块2工作过程具体包括步骤:
将提取的关键词与法律词汇建立对应关系;
确定与关键词对应的法律词汇;
根据法律词汇生成并显示包含法律词汇的联想句;
接受对联想句的选择;
建立所选择的联想句与法律条文的对应关系;
确定与选中的联想句对应的法律条文。
对文本数据以句子为单位进行语义抓取,每一句话是一组数据;
关键词为用户问题中词义与问题含义最接近的单词。
多维度数据库匹配模块3工作过程具体包括步骤:
生成法律解决方案,包括法律条文;
接受用户输入的数据变量;
用于大数据的积累和沉淀。
生成法律解决方案,解决方案内容包括:有效建议、计算赔偿金额、推送相关信息。
本发明要解决的技术问题是如何让一个法律事务平台,全智能,无人工参与的和用户进行交互,反馈,建议,订制,推送。
这里,首先解决的一个大问题就是语义抓取,和文本分析。这是本发明的底层技术,市场上基本看不到的技术。
其次多维度的模型设计和多维度的数据库搭建方式,也是深度技术。
现有技术中,用户通过诸如计算机等的终端产品输入自己的问题,计算机根据用户的问题,匹配预先设置的答案,该答案一般包括与用户问题对应的法律条文。
这就是现有产品或现有的技术:数据库匹配。这里存在的问题是,数据库搭建往往比较简单,单一维度考虑搭建方式,匹配不上或匹配错误的概率很大。
本发明要解决的问题就是在通过多维度搭建数据库的基础上,使机器高精准匹配。
同时本发明的技术弥补了智能平台的最大核心技术问题:语义抓取和文本分析技术,让机器深度理解用户的文本意义。
具体技术方案如下:
1)用户通过计算机(包括手机端,以下同),用自然语言文字或语音在对话框内提出问题;
2)计算机系统从用户的自然语言问题描述中,通过提取分析关键词,进行语义抓取和文本识别,理解用户自然语言含义;
3)建立基于法律规定及法律词条的分类模式,建立由关键词、联想语句、问题解答、要素维度等要素组成的数据库,通过关键词与数据库检索匹配度高的答案,回答用户提问;
4)提取对话中有效的问答信息增加到数据库中,形成机器自主学习能力;
5)为用户自动提供系统的法律问题解决方案。
本发明如图2所示,展现了软件以及数据本身是如何做到自动分析自动处理并聚合和精准推送。
数据(文本)以句子为单位,每一句话是一组数据。
例如,“一些盗版制品经营者为了应付和躲避打击,经营手法更为隐蔽。”这一句话,技术分析后的关系图谱如图3所示,中文前面的英文是表示词性。注释说明如下:
ip:简单从句
np:名词短语
vp:动词短语
pu:断句符,通常是句号、问号、感叹号等标点符号
lcp:方位词短语
pp:介词短语
cp:由‘的’构成的表示修饰性关系的短语
dnp:由‘的’构成的表示所属关系的短语
advp:副词短语
adjp:形容词短语
dp:限定词短语
qp:量词短语
nn:常用名词
nr:固有名词
nt:时间名词
pn:代词
vv:动词
vc:是
cc:表示连词
ve:有
va:表语形容词
as:内容标记(如:了)。
接下来,如图4所示,是我们建立的句式结构。
最后,系统将句子中的词汇和词汇间的关系,用数字标记,前面的英文为词汇属性说明,如图5所示。
通过这样的抓取、匹配和建立对应关系,对用户信息的机器语义理解可以达到高精准度和准确度。
- 还没有人留言评论。精彩留言会获得点赞!