一种基于弱监督学习的视频异常事件检测系统及其方法与流程
本发明涉及视频行为分析技术领域,具体涉及到一种基于弱监督学习的视频异常事件检测系统及其方法,该方法采用深度学习框架,设计一种弱监督学习策略来训练视频行为正常\异常分类器,在此基础上完成视频行为异常事件检测。
背景技术:
视频行为异常事件检测是计算机视觉领域长期以来的一个研究热点。随着我国城市中高清监控摄像头的越来越普及,随之产生的海量的监控视频给视频操作人员带来了繁重的工作负担。同时现有的视频行为检测技术不能及时地发现正在发生的异常事件(例如:暴恐犯罪事件),进而提醒工作人员阻止事态的进一步发展,把可能的损失最小化。当前视频行为异常事件检测方法主要基于以下假设:与经常出现的行为模式不同的模式即为异常行为模式。从这个假设出发,现有的方法通常由正常行为数据来构建正常行为模型,用此模型对视频中出现的模式进行打分,得分低的模式被检测为异常行为模式。由于日常生活中正常行为事件的模式多种多样,再加上视频拍摄场景和拍摄角度不同带来的行为表现形式上的变化,使得很难对所有的正常行为构建统一的模型。另外,在现实的生活中,人们对异常行为模式总是有一定的先验,比如:打架、抢劫等事件总是被视为异常事件,而不需要预先和正常事件进行比较再做判断。本发明提出的方法直接从现实中海量的监控视频出发,通过少量的标注(只标注视频是否含有异常事件而不需要给出异常事件的起止时间点)来构建正常/异常事件分类器,从而实现对测试视频中含有的异常事件进行检测和定位。
技术实现要素:
本发明的目的是提供一种基于弱监督学习的视频异常事件检测系统。
本发明的另一目的是提供一种基于弱监督学习的视频异常事件检测方法,通过在海量弱标注视频数据集上(只标注视频是否含有异常事件而没有指出异常事件起止的时间位置)应用弱监督学习方法来构造正常/异常事件分类器,从而实现对于给定的待测视频,自动完成判定其中是否含有异常事件和定位异常事件发生的时间轴位置。
本发明提出的方法与现有的方法相比有两点主要的改进:1.)本发明的方法是基于弱监督学习框架,相比于传统的基于强监督学习的方法,此方法只需要对数据集进行若标注即可(只标注视频是否含有异常事件),从未节省了大量的人工标注成本和劳动时间;2.)本发明提出的模型是基于正常/异常两类样本来构建的,相比于目前只关注于正常样本的模型构建方法,引入了对异常事件的先验信息,从而使模型对于日常常见的异常事件具有更加准确地判定。
本发明的原理是:1.)把弱监督视频异常事件检测问题表述成一个多实例学习模型。每个实例对应于视频序列中的一个视频片段,多个实例构成一个实例包,对应于一个视频序列。多实例学习的任务即是建立实例包中多个实例间的偏序关系;2.)通过加入实例得分平滑性约束来确保同一个视频序列中相邻的视频片段得分是平滑地连续变化的,符合行为事件发展变化连续性原理,而加入实例得分稀疏性约束来确保只有少量的实例取得较大的得分值,符合异常事件是少量的、偶发的性质。
本发明提供的技术方案如下:
一种基于弱监督学习的视频异常事件检测系统,其特征在于,包括视频片段层次结构深度特征提取模块、行为实例包弱监督学习模块以及行为实例异常得分损失函数约束模块;其中:
所述的视频片段层次结构深度特征提取模块,用于对指定长度的视频片段也即行为实例,提取多个层次的rgb图像-光流图像联合表述特征;
所述的行为实例包弱监督学习模块,用于将包含多个行为实例的视频序列作为一个整体,只使用正常/异常的视频标签,进行弱监督学习;
所述的行为实例异常得分损失函数约束模块,用于约束行为实例得分符合视频事件连续性、异常事件偶发性的性质,来指导异常事件评分网络更加有效地进行学习。
所述视频片段层次结构深度特征提取模块具体包括:rgb图像-光流图像深度特征提取网络,用于提取行为实例在指定的划分层次上外形-运动信息的联合表述特征;行为实例多层次结构划分模块,用于对行为实例进行多个层次的结构划分,提取从粗到细多个粒度上的外形-运动信息联合表述特征;
所述行为实例包弱监督学习模块具体包括:正/负样本行为实例包设置,即把一段视频作为一个行为实例包,一段视频包含多个行为实例,根据其类别标签分别作为正样本行为实例包,包含异常事件和负样本行为实例包,负样本行为实例包只包含正常事件。构建行为实例包用于实现弱监督学习中的偏序学习;行为实例异常事件分类网络,即构建一个多层次深度神经网络模型对行为实例进行异常度评分,若为异常,则期望输出值为1,若为正常,则期望输出值为0。
本发明提出的弱监督视频异常事件检测方法包括三个部分:对输入视频进行划分,得到行为实例,进而构成行为实例包;利用深度学习模型对行为实例进行特征提取;构建行为实例正常/异常得分模型,由行为实例得分偏序性、稀疏性和连续性约束构造损失函数,从而对模型进行优化求解。从一段视频输入到异常事件检测结果输出包括以下若干步骤:
1)对输入视频进行均匀划分,每段包括若干帧,构成一个行为实例。一个视频序列所有的行为实例构成一个整体,称之为实例包;
2)利用深度学习模型对每个行为实例提取外形和运动联合表述层次结构特征;
3)把联合表述特征输入到正常/异常事件分类网络,得到行为实例得分。根据设定的得分阈值,得到异常事件检测结果。
与现有技术相比,本发明的有益效果是:
利用本发明提供的技术方案,在对视频中存在的异常事件进行检测时,采用了一种半监督学习的模式。相比于传统的基于强监督的异常事件检测方法,节省了大量的人力劳动和时间成本来进行样本的精确标注;同时,本发明中提出的模型是对正常/异常事件进行建模,相比于传统的只基于正常事件建模的方法,对现实中常见的异常事件具有一定的先验信息,因而提高了异常事件检测的准确率。
下面结合附图,通过实施例子对本发明进一步说明如下:
附图说明
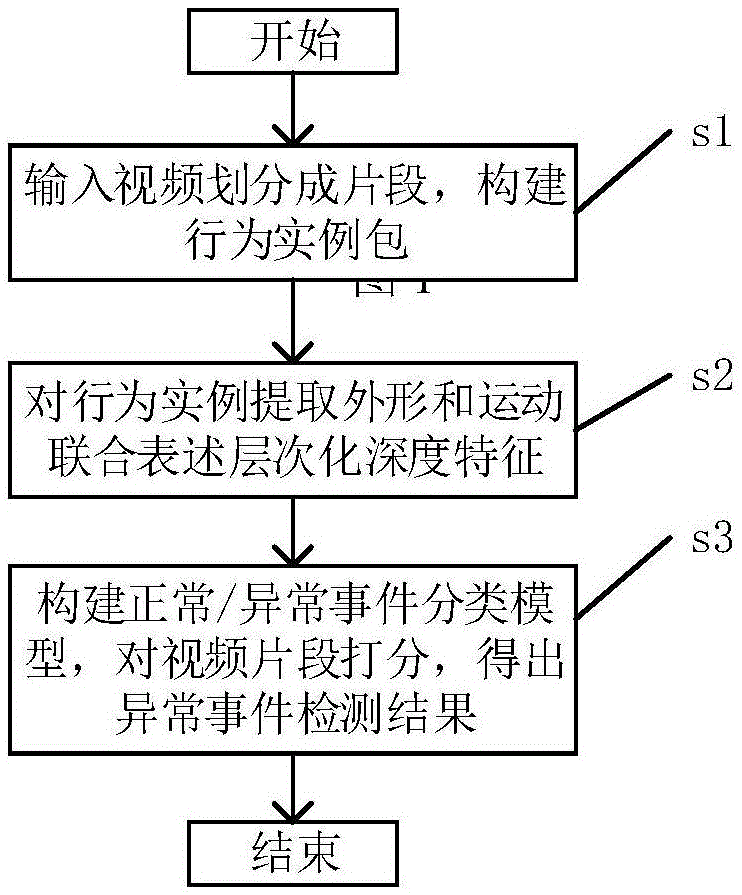
图1为本发明的流程图;
图2为本发明所提出模型的网络结构图;
图3为视频片段层次划分结构图;
附图中:
1—异常事件视频,2—异常行为实例包,3—正常事件视频,4—正常行为实例包,5—特征提取深度网络模型,6—正常/异常事件分类模型,7—隐含层一,8—隐含层二,9—隐含层三,10—事件行为分类得分,11—视频片段零级划分,12—视频片段1级划分,13—视频片段2级划分,14—视频片段3级划分。
具体实施方式
图2为本发明所提出模型的网络结构图,如图2所示,本实施例系统包含:特征提取深度网络模型5,正常/异常事件分类模型6,隐含层一7,隐含层二8,隐含层三9。
图3为视频片段层次划分结构图,如图3所示,本实施例包含:视频片段零级划分11,视频片段1级划分12,视频片段2级划分13,视频片段3级划分14。
图1为本发明的流程图,其中s1—s3依次对应于具体实施步骤1)—3)。一种基于弱监督学习的视频异常事件检测方法,整体操作流程现分述如下:
1)输入视频划分成片段,构建行为实包s1:给定一段视频,把它均匀地划分为若干段,每段包含32帧图像。每段视频构成一个行为实例,对于包含异常事件的视频1,此行为实例记为ia,而对于正常事件视频3,此行为实例记为in。由ia构成的集合称之为异常行为实例包,记为ga2,由in构成的集合称之为正常行为实例包,记为gn4;
2)对行为实例提取外形和运动联合表述层次化深度特征s2:在训练阶段,由深度网络模型5提取ia或者in的深度表述特征用于训练正常/异常事件分类器6。以下依ia的处理过程为例进行说明,in的处理过程与之相同。首先提取ia中每帧图像的光流信息,得到相应的光流图像,记为po,而原始rgb图像记为pc。这里po和pc均代表图像序列。把po和pc按照不同的层次进行划分,共计4个层次,分别对应保留整段的零级层次11,划分为2段的1级层次12,划分为4段的2级层次13,划分为8段的3级层次14。对每个层次分别提取各段的光流图像和rgb图像联合表述特征,对各段特征进行平均求和作为该层次的表述特征。记深度网络模型为mf,记第i(i=0,1,2,3)个层次第j(j=1,2,…,2i)段视频为vij。具体操作过程为:对于vij,从其对应的pc中随机抽取一帧rgb图像输入mf,计算rgb特征fc;同时把其对应的po全部输入mf,计算光流特征fo,把fc和fo联结起来得到vij的联合表述特征
则行为实例ia的表述特征
式(2)中fi为第i个层次的表述特征。
在训练阶段,行为实例由标签数据可以分为ia或者in,而在测试阶段,没有标签数据,行为实例统称为i。深度网络模型mf在实际实施中取为vgg-16模型(simonyank.andzissermana.2014.verydeepconvolutionalnetworksforlargescaleimagerecognition.arxiv(2014).https://doi.org/arxiv:1409.1556);
3)构建正常/异常事件分类模型,对视频片断打分,得出异常事件检测结果s3:把
在式(3)中,第一项
以上即为本发明提出的一种基于弱监督学习的视频异常事件检测方法的具体实施方案。此实施例实在异常事件数据集ucsd(1)上进行的,并用目前公认的评价标准auc(areaundercurve)对实验结果进行了评估证明本发明提出的方法都达到了目前领先的检测精度。本发明提出的方法与现有方法在ucsd(1)上的检测结果比较如表1所示。
表1检测结果比较表
表1以及说明书中方括号内的标号为下列方括号中所对应参考文献。例如:sparse[1]方括号内的1表示参考文献[1]中所提及的方法。
参考文献:
[1]y.cong,j.yuan,andj.liu,“sparsereconstructioncostforabnormaleventdetection,”inproceedingsofieeeconferenceoncomputervisionandpatternrecognition,2011,pp.3449–3456.
[2]v.mahadevan,w.li,v.bhalodia,andn.vasconcelos,“anomalydetectionincrowdedscenes,”inproceedingsofieeeconferenceoncomputervisionandpatternrecognition,2010,pp.1975–1981.
[3]d.xu,e.ricci,y.yan,j.song,andn.sebe,“learningdeeprepresentationsofappearanceandmotionforanomalouseventdetection,”inproceedingsofbritishmachinevisionconference,2015,pp.1–12.
[4]m.hasan,j.choi,j.neumann,a.k.roy-chowdhury,andl.s.davis,“learningtemporalregularityinvideosequences,”inproceedingsofieeeconferenceoncomputervisionandpatternrecognition,2016,pp.733–742.
[5]m.ravanbakhsh,m.nabi,e.sangineto,l.marcenaro,c.regazzoni,andn.sebe,“abnormaleventdetectioninvideosusinggenerativeadversarialnets,”inproceedingsofinternationalconferenceonimageprocessing,2017,pp.1–5.
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!