一种基于卷积神经网络的道路场景语义分割方法与流程
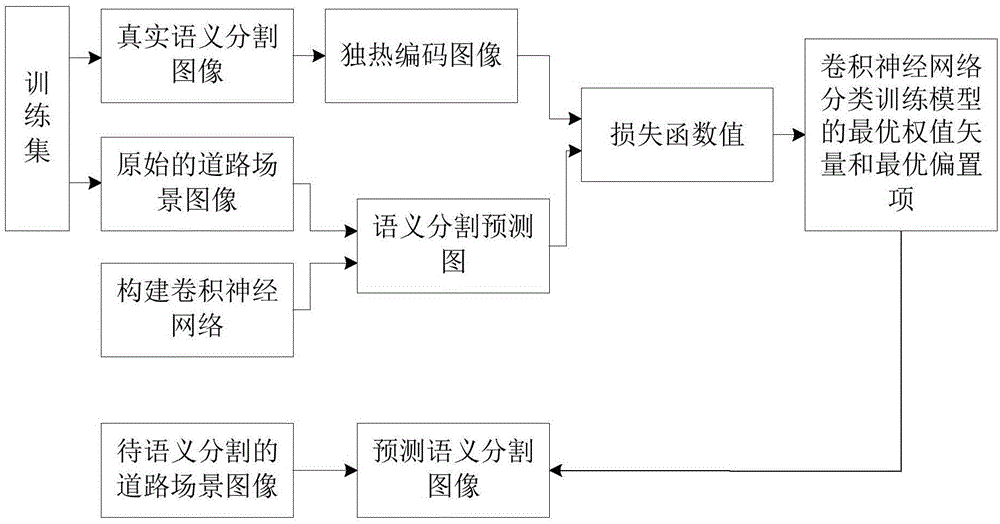
本发明涉及一种道路场景语义分割技术,尤其是涉及一种基于卷积神经网络的道路场景语义分割方法。
背景技术:
近年来,具有执行计算密集型任务能力的机器的进步使得研究人员能够更深入地挖掘神经网络。卷积神经网络在图像的分类、定位以及场景理解等方面取得了最近的成功。目前,由于增强现实和自动驾驶车辆等任务的激增,因此许多研究人员将注意力转移到场景理解上,其中一个主要步骤就是语义分割,即对所给定的图像中的每一个像素点做分类。语义分割在移动和机器人相关应用中具有重要意义。
当然,目标检测方法可以帮助绘制出某些确定实体的边框,但人类对场景理解能以像素级的精细程度对每一个实体进行检测并标记精确的边界。现在已经开始发展自动驾驶汽车和智能机器人,这些都需要深入理解周围环境,因此精确分割实体变得越来越重要。
深度学习在语义分割、计算机视觉、语音识别、跟踪方面都有极广泛的应用,其极强的高效性也使得它在实时应用等各方面具有巨大的潜力。现如今获取特征的方法主要可以分为两类:使用手动特征的传统方法和针对问题自动学习的深度学习方法,前者通常为了适应新的数据集需要专家相关经验和时间对特征进行调整;后者在物体检测和图像分类等方面的成功鼓舞着研究人员探索此类网络对像素级标记,如语义分割方面的能力。因此,深度学习语义分割方法的研究更高效实用。
经典的语义分割方法有全连接网络(fullconnectednetwork,fcn),其能够做到端到端,像素点对像素点的连接,而且相比于传统的基于cnn(卷积神经网络)做分割的网络更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题,其是最先进的语义分割方法之一。但它存在很多缺点,首先是训练比较麻烦,需要训练三次才能够得到fcn-8s;其次是对图像的细节不够敏感,这是因为在解码过程,也就是恢复原图像大小的过程中,输入上采样层的labelmap(标签图片)太稀疏,而且上采样过程就是一个简单的deconvolution(反卷积),因此得到的分割结果还是不精细。
技术实现要素:
本发明所要解决的技术问题是提供一种基于卷积神经网络的道路场景语义分割方法,其语义分割精度高。
本发明解决上述技术问题所采用的技术方案为:一种基于卷积神经网络的道路场景语义分割方法,其特征在于包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取q幅原始的道路场景图像及每幅原始的道路场景图像对应的真实语义分割图像,并构成训练集,将训练集中的第q幅原始的道路场景图像记为{iq(i,j)},将训练集中与{iq(i,j)}对应的真实语义分割图像记为
步骤1_2:构建卷积神经网络:卷积神经网络包括输入层、隐层和输出层;隐层由13个神经网络块、7个上采样层、8个级联层组成;第1个神经网络块由第一卷积层、第二卷积层、第一最大池化层、第三卷积层、第四卷积层组成,第2个神经网络块由第五卷积层、第六卷积层、第二最大池化层、第七卷积层、第八卷积层组成,第3个神经网络块由第九卷积层、第十卷积层、第十一卷积层、第三最大池化层、第十二卷积层、第十三卷积层组成,第4个神经网络块由第十四卷积层、第十五卷积层、第十六卷积层、第四最大池化层、第十七卷积层组成,第5个神经网络块由第十八卷积层、第十九卷积层、第二十卷积层、第二十一卷积层、第二十二卷积层、第二十三卷积层组成,第6个神经网络块由第二十四卷积层、第二十五卷积层、第二十六卷积层组成,第7个神经网络块由第二十七卷积层、第二十八卷积层、第二十九卷积层组成,第8个神经网络块由第三十卷积层、第三十一卷积层组成,第9个神经网络块由第三十二卷积层、第三十三卷积层组成,第10个神经网络块由第三十四卷积层、第三十五卷积层、第三十六卷积层组成,第11个神经网络块由第三十七卷积层、第三十八卷积层、第三十九卷积层组成,第12个神经网络块由第四十卷积层、第四十一卷积层组成,第13个神经网络块由第四十二卷积层、第四十三卷积层组成;输出层由第四十四卷积层组成;其中,第一卷积层至第四十四卷积层各自的卷积核大小为3×3,第一最大池化层至第四最大池化层各自的池化步长为2,7个上采样层各自的上采样步长为2;
对于输入层,输入层的输入端接收一幅原始输入图像的r通道分量、g通道分量和b通道分量,输入层的输出端输出原始输入图像的r通道分量、g通道分量和b通道分量给隐层;其中,要求输入层的输入端接收的原始输入图像的宽度为w、高度为h;
对于第1个神经网络块,第一卷积层的输入端接收输入层的输出端输出的原始输入图像的r通道分量、g通道分量和b通道分量,第一卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c1;第二卷积层的输入端接收c1中的所有特征图,第二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c2;第一最大池化层的输入端接收c2中的所有特征图,第一最大池化层的输出端输出64幅特征图,将64幅特征图构成的集合记为z1;第三卷积层的输入端接收c2中的所有特征图,第三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c3;第四卷积层的输入端接收c2中的所有特征图,第四卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c4;其中,c1、c2、c3、c4各自中的每幅特征图的宽度为w、高度为h,z1中的每幅特征图的宽度为
对于第2个神经网络块,第五卷积层的输入端接收z1中的所有特征图,第五卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c5;第六卷积层的输入端接收c5中的所有特征图,第六卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c6;第二最大池化层的输入端接收c6中的所有特征图,第二最大池化层的输出端输出128幅特征图,将128幅特征图构成的集合记为z2;第七卷积层的输入端接收c6中的所有特征图,第七卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c7;第八卷积层的输入端接收c6中的所有特征图,第八卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c8;其中,c5、c6、c7、c8各自中的每幅特征图的宽度为
对于第3个神经网络块,第九卷积层的输入端接收z2中的所有特征图,第九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c9;第十卷积层的输入端接收c9中的所有特征图,第十卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c10;第十一卷积层的输入端接收c10中的所有特征图,第十一卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c11;第三最大池化层的输入端接收c11中的所有特征图,第三最大池化层的输出端输出256幅特征图,将256幅特征图构成的集合记为z3;第十二卷积层的输入端接收c11中的所有特征图,第十二卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c12;第十三卷积层的输入端接收c11中的所有特征图,第十三卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c13;其中,c9、c10、c11、c12、c13各自中的每幅特征图的宽度为
对于第4个神经网络块,第十四卷积层的输入端接收z3中的所有特征图,第十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c14;第十五卷积层的输入端接收c14中的所有特征图,第十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c15;第十六卷积层的输入端接收c15中的所有特征图,第十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c16;第四最大池化层的输入端接收c16中的所有特征图,第四最大池化层的输出端输出512幅特征图,将512幅特征图构成的集合记为z4;第十七卷积层的输入端接收c16中的所有特征图,第十七卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c17;其中,c14、c15、c16、c17各自中的每幅特征图的宽度为
对于第5个神经网络块,第十八卷积层的输入端接收z4中的所有特征图,第十八卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c18;第十九卷积层的输入端接收c18中的所有特征图,第十九卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c19;第二十卷积层的输入端接收c19中的所有特征图,第二十卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c20;第二十一卷积层的输入端接收c20中的所有特征图,第二十一卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c21;第二十二卷积层的输入端接收c21中的所有特征图,第二十二卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c22;第二十三卷积层的输入端接收c22中的所有特征图,第二十三卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c23;其中,c18、c19、c20、c21、c22、c23各自中的每幅特征图的宽度为
对于第1个上采样层,第1个上采样层的输入端接收c23中的所有特征图,第1个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y1;其中,y1中的每幅特征图的宽度为
对于第1个级联层,第1个级联层的输入端接收y1中的所有特征图和c17中的所有特征图,第1个级联层的输出端输出1024幅特征图,将1024幅特征图构成的集合记为l1;其中,l1中的每幅特征图的宽度为
对于第6个神经网络块,第二十四卷积层的输入端接收l1中的所有特征图,第二十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c24;第二十五卷积层的输入端接收c24中的所有特征图,第二十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c25;第二十六卷积层的输入端接收c25中的所有特征图,第二十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c26;其中,c24、c25、c26各自中的每幅特征图的宽度为
对于第2个上采样层,第2个上采样层的输入端接收c26中的所有特征图,第2个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y2;其中,y2中的每幅特征图的宽度为
对于第2个级联层,第2个级联层的输入端接收y2中的所有特征图和c12中的所有特征图,第2个级联层的输出端输出768幅特征图,将768幅特征图构成的集合记为l2;其中,l2中的每幅特征图的宽度为
对于第7个神经网络块,第二十七卷积层的输入端接收l2中的所有特征图,第二十七卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c27;第二十八卷积层的输入端接收c27中的所有特征图,第二十八卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c28;第二十九卷积层的输入端接收c28中的所有特征图,第二十九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c29;其中,c27、c28、c29各自中的每幅特征图的宽度为
对于第3个上采样层,第3个上采样层的输入端接收c29中的所有特征图,第3个上采样层的输出端输出256幅特征图,将256幅特征图构成的集合记为y3;其中,y3中的每幅特征图的宽度为
对于第3个级联层,第3个级联层的输入端接收y3中的所有特征图和c7中的所有特征图,第3个级联层的输出端输出384幅特征图,将384幅特征图构成的集合记为l3;其中,l3中的每幅特征图的宽度为
对于第8个神经网络块,第三十卷积层的输入端接收l3中的所有特征图,第三十卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c30;第三十一卷积层的输入端接收c30中的所有特征图,第三十一卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c31;其中,c30、c31各自中的每幅特征图的宽度为
对于第4个上采样层,第4个上采样层的输入端接收c31中的所有特征图,第4个上采样层的输出端输出128幅特征图,将128幅特征图构成的集合记为y4;其中,y4中的每幅特征图的宽度为w、高度为h;
对于第4个级联层,第4个级联层的输入端接收y4中的所有特征图和c3中的所有特征图,第4个级联层的输出端输出192幅特征图,将192幅特征图构成的集合记为l4;其中,l4中的每幅特征图的宽度为w、高度为h;
对于第9个神经网络块,第三十二卷积层的输入端接收l4中的所有特征图,第三十二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c32;第三十三卷积层的输入端接收c32中的所有特征图,第三十三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c33;其中,c32、c33各自中的每幅特征图的宽度为w、高度为h;
对于第10个神经网络块,第三十四卷积层的输入端接收c16中的所有特征图,第三十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c34;第三十五卷积层的输入端接收c34中的所有特征图,第三十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c35;第三十六卷积层的输入端接收c35中的所有特征图,第三十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c36;其中,c34、c35、c36各自中的每幅特征图的宽度为
对于第5个上采样层,第5个上采样层的输入端接收c36中的所有特征图,第5个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y5;其中,y5中的每幅特征图的宽度为
对于第5个级联层,第5个级联层的输入端接收y5中的所有特征图和c13中的所有特征图,第5个级联层的输出端输出768幅特征图,将768幅特征图构成的集合记为l5;其中,l5中的每幅特征图的宽度为
对于第11个神经网络块,第三十七卷积层的输入端接收l5中的所有特征图,第三十七卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c37;第三十八卷积层的输入端接收c37中的所有特征图,第三十八卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c38;第三十九卷积层的输入端接收c38中的所有特征图,第三十九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c39;其中,c37、c38、c39各自中的每幅特征图的宽度为
对于第6个上采样层,第6个上采样层的输入端接收c39中的所有特征图,第6个上采样层的输出端输出256幅特征图,将256幅特征图构成的集合记为y6;其中,y6中的每幅特征图的宽度为
对于第6个级联层,第6个级联层的输入端接收y6中的所有特征图和c8中的所有特征图,第6个级联层的输出端输出384幅特征图,将384幅特征图构成的集合记为l6;其中,l6中的每幅特征图的宽度为
对于第12个神经网络块,第四十卷积层的输入端接收l6中的所有特征图,第四十卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c40;第四十一卷积层的输入端接收c40中的所有特征图,第四十一卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c41;其中,c40、c41各自中的每幅特征图的宽度为
对于第7个上采样层,第7个上采样层的输入端接收c41中的所有特征图,第7个上采样层的输出端输出128幅特征图,将128幅特征图构成的集合记为y7;其中,y7中的每幅特征图的宽度为w、高度为h;
对于第7个级联层,第7个级联层的输入端接收y7中的所有特征图和c4中的所有特征图,第7个级联层的输出端输出192幅特征图,将192幅特征图构成的集合记为l7;其中,l7中的每幅特征图的宽度为w、高度为h;
对于第13个神经网络块,第四十二卷积层的输入端接收l7中的所有特征图,第四十二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c42;第四十三卷积层的输入端接收c42中的所有特征图,第四十三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c43;其中,c42、c43各自中的每幅特征图的宽度为w、高度为h;
对于第8个级联层,第8个级联层的输入端接收c33中的所有特征图和c43中的所有特征图,第8个级联层的输出端输出128幅特征图,将128幅特征图构成的集合记为l8;其中,l8中的每幅特征图的宽度为w、高度为h;
对于输出层,第四十四卷积层的输入端接收l8中的所有特征图,第四十四卷积层的输出端输出12幅与原始输入图像对应的语义分割预测图;其中,每幅语义分割预测图的宽度为w、高度为h;
步骤1_3:将训练集中的每幅原始的道路场景图像作为原始输入图像,输入到卷积神经网络中进行训练,得到训练集中的每幅原始的道路场景图像对应的12幅语义分割预测图,将{iq(i,j)}对应的12幅语义分割预测图构成的集合记为
步骤1_4:计算训练集中的每幅原始的道路场景图像对应的12幅语义分割预测图构成的集合与对应的真实语义分割图像处理成的12幅独热编码图像构成的集合之间的损失函数值,将
步骤1_5:重复执行步骤1_3和步骤1_4共v次,得到卷积神经网络分类训练模型,并共得到q×v个损失函数值;然后从q×v个损失函数值中找出值最小的损失函数值;接着将值最小的损失函数值对应的权值矢量和偏置项对应作为卷积神经网络分类训练模型的最优权值矢量和最优偏置项,对应记为wbest和bbest;其中,v>1;
所述的测试阶段过程的具体步骤为:
步骤2_1:令
步骤2_2:将
所述的步骤1_4中,
与现有技术相比,本发明的优点在于:
1)本发明方法将第1个至第9个神经网络块、第1个至第4个上采样层、第1个至第4个级联层构成一个尺度模型,将第10个至第13个神经网络块、第5个至第7个上采样层、第5个至第7个级联层构成另一个尺度模型,采用两个尺度模型学习将来自不同层的多层信息与不同的接受域大小相结合,两个尺度模型的设置减少了冗余性,在数据量上相比现有的fcn等其他模型而言较少的情况下同样能够做到端到端,像素点对像素点的连接,因此相比于传统的基于cnn(卷积神经网络)做分割的网络更加高效,极大增强了创建的卷积神经网络的学习能力,从而能够有效地提升语义分割精度。
2)本发明方法利用了vgg-16网络模型(即设置的13个神经网络块)为基础架构,充分吸收vgg-16网络模型小卷积核及高效性优点,使得每个上采样层输出的特征图即labelmap(标签图片)较为密集,从而使得训练集和测试集的结果均稳定提升,有极强的鲁棒性,因此提高了语义分割精度。
3)本发明方法创建的卷积神经网络中的第1个至第5个神经网络块构成了编码部分,第1个至第7个上采样层、第1个至第8个级联层、第6个至第13个神经网络块构成了解码部分,编码部分和解码部分组成了编解码神经网络体系结构,本发明方法同时考虑了编解码神经网络体系结构和跳跃再融合结构,打破了传统一步到位的模型,同时卷积核在编码部分逐步增加,在解码部分逐渐减少,优化了创建的卷积神经网络的结构对称性,同时跳跃融合域的特征信息增加了deconvolution(反卷积)数据量,防止了创建的卷积神经网络的过拟合,提升了创建的卷积神经网络的效率;同时,与fcn相比,本发明方法在结构上比较大的改动在上采样阶段,打破了其一步到位的上采样模式,本发明方法的上采样层包含了很多层的特征,减少了由于一步到位的上采样模型导致的信息损失,提升了分割结果的精确度;此外,本发明方法只需要一次训练,而fcn需要三次训练。
附图说明
图1为本发明方法的总体实现框图;
图2为本发明方法创建的卷积神经网络的组成结构示意图;
图3a为选取的一幅待语义分割的道路场景图像;
图3b为图3a所示的待语义分割的道路场景图像对应的真实语义分割图像;
图3c为利用本发明方法对图3a所示的待语义分割的道路场景图像进行预测,得到的预测语义分割图像;
图4a为选取的另一幅待语义分割的道路场景图像;
图4b为图4a所示的待语义分割的道路场景图像对应的真实语义分割图像;
图4c为利用本发明方法对图4a所示的待语义分割的道路场景图像进行预测,得到的预测语义分割图像。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种基于卷积神经网络的道路场景语义分割方法,其总体实现框图如图1所示,其包括训练阶段和测试阶段两个过程;
所述的训练阶段过程的具体步骤为:
步骤1_1:选取q幅原始的道路场景图像及每幅原始的道路场景图像对应的真实语义分割图像,并构成训练集,将训练集中的第q幅原始的道路场景图像记为{iq(i,j)},将训练集中与{iq(i,j)}对应的真实语义分割图像记为
步骤1_2:构建卷积神经网络:如图2所示,卷积神经网络包括输入层、隐层和输出层;隐层由13个神经网络块、7个上采样层、8个级联层组成;第1个神经网络块由第一卷积层、第二卷积层、第一最大池化层、第三卷积层、第四卷积层组成,第2个神经网络块由第五卷积层、第六卷积层、第二最大池化层、第七卷积层、第八卷积层组成,第3个神经网络块由第九卷积层、第十卷积层、第十一卷积层、第三最大池化层、第十二卷积层、第十三卷积层组成,第4个神经网络块由第十四卷积层、第十五卷积层、第十六卷积层、第四最大池化层、第十七卷积层组成,第5个神经网络块由第十八卷积层、第十九卷积层、第二十卷积层、第二十一卷积层、第二十二卷积层、第二十三卷积层组成,第6个神经网络块由第二十四卷积层、第二十五卷积层、第二十六卷积层组成,第7个神经网络块由第二十七卷积层、第二十八卷积层、第二十九卷积层组成,第8个神经网络块由第三十卷积层、第三十一卷积层组成,第9个神经网络块由第三十二卷积层、第三十三卷积层组成,第10个神经网络块由第三十四卷积层、第三十五卷积层、第三十六卷积层组成,第11个神经网络块由第三十七卷积层、第三十八卷积层、第三十九卷积层组成,第12个神经网络块由第四十卷积层、第四十一卷积层组成,第13个神经网络块由第四十二卷积层、第四十三卷积层组成;输出层由第四十四卷积层组成;其中,第一卷积层至第四十四卷积层各自的卷积核大小为3×3,第一最大池化层至第四最大池化层各自的池化步长为2,7个上采样层各自的上采样步长为2,每个上采样层使输出的特征图的尺寸为输入的特征图的尺寸的2倍。
对于输入层,输入层的输入端接收一幅原始输入图像的r通道分量、g通道分量和b通道分量,输入层的输出端输出原始输入图像的r通道分量、g通道分量和b通道分量给隐层;其中,要求输入层的输入端接收的原始输入图像的宽度为w、高度为h。
对于第1个神经网络块,第一卷积层的输入端接收输入层的输出端输出的原始输入图像的r通道分量、g通道分量和b通道分量,第一卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c1;第二卷积层的输入端接收c1中的所有特征图,第二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c2;第一最大池化层的输入端接收c2中的所有特征图,第一最大池化层的输出端输出64幅特征图,将64幅特征图构成的集合记为z1;第三卷积层的输入端接收c2中的所有特征图,第三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c3;第四卷积层的输入端接收c2中的所有特征图,第四卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c4;其中,c1、c2、c3、c4各自中的每幅特征图的宽度为w、高度为h,z1中的每幅特征图的宽度为
对于第2个神经网络块,第五卷积层的输入端接收z1中的所有特征图,第五卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c5;第六卷积层的输入端接收c5中的所有特征图,第六卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c6;第二最大池化层的输入端接收c6中的所有特征图,第二最大池化层的输出端输出128幅特征图,将128幅特征图构成的集合记为z2;第七卷积层的输入端接收c6中的所有特征图,第七卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c7;第八卷积层的输入端接收c6中的所有特征图,第八卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c8;其中,c5、c6、c7、c8各自中的每幅特征图的宽度为
对于第3个神经网络块,第九卷积层的输入端接收z2中的所有特征图,第九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c9;第十卷积层的输入端接收c9中的所有特征图,第十卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c10;第十一卷积层的输入端接收c10中的所有特征图,第十一卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c11;第三最大池化层的输入端接收c11中的所有特征图,第三最大池化层的输出端输出256幅特征图,将256幅特征图构成的集合记为z3;第十二卷积层的输入端接收c11中的所有特征图,第十二卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c12;第十三卷积层的输入端接收c11中的所有特征图,第十三卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c13;其中,c9、c10、c11、c12、c13各自中的每幅特征图的宽度为
对于第4个神经网络块,第十四卷积层的输入端接收z3中的所有特征图,第十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c14;第十五卷积层的输入端接收c14中的所有特征图,第十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c15;第十六卷积层的输入端接收c15中的所有特征图,第十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c16;第四最大池化层的输入端接收c16中的所有特征图,第四最大池化层的输出端输出512幅特征图,将512幅特征图构成的集合记为z4;第十七卷积层的输入端接收c16中的所有特征图,第十七卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c17;其中,c14、c15、c16、c17各自中的每幅特征图的宽度为
对于第5个神经网络块,第十八卷积层的输入端接收z4中的所有特征图,第十八卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c18;第十九卷积层的输入端接收c18中的所有特征图,第十九卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c19;第二十卷积层的输入端接收c19中的所有特征图,第二十卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c20;第二十一卷积层的输入端接收c20中的所有特征图,第二十一卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c21;第二十二卷积层的输入端接收c21中的所有特征图,第二十二卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c22;第二十三卷积层的输入端接收c22中的所有特征图,第二十三卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c23;其中,c18、c19、c20、c21、c22、c23各自中的每幅特征图的宽度为
对于第1个上采样层,第1个上采样层的输入端接收c23中的所有特征图,第1个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y1;其中,y1中的每幅特征图的宽度为
对于第1个级联层,第1个级联层的输入端接收y1中的所有特征图和c17中的所有特征图,第1个级联层的输出端输出1024幅特征图,将1024幅特征图构成的集合记为l1;其中,l1中的每幅特征图的宽度为
对于第6个神经网络块,第二十四卷积层的输入端接收l1中的所有特征图,第二十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c24;第二十五卷积层的输入端接收c24中的所有特征图,第二十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c25;第二十六卷积层的输入端接收c25中的所有特征图,第二十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c26;其中,c24、c25、c26各自中的每幅特征图的宽度为
对于第2个上采样层,第2个上采样层的输入端接收c26中的所有特征图,第2个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y2;其中,y2中的每幅特征图的宽度为
对于第2个级联层,第2个级联层的输入端接收y2中的所有特征图和c12中的所有特征图,第2个级联层的输出端输出768幅特征图,将768幅特征图构成的集合记为l2;其中,l2中的每幅特征图的宽度为
对于第7个神经网络块,第二十七卷积层的输入端接收l2中的所有特征图,第二十七卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c27;第二十八卷积层的输入端接收c27中的所有特征图,第二十八卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c28;第二十九卷积层的输入端接收c28中的所有特征图,第二十九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c29;其中,c27、c28、c29各自中的每幅特征图的宽度为
对于第3个上采样层,第3个上采样层的输入端接收c29中的所有特征图,第3个上采样层的输出端输出256幅特征图,将256幅特征图构成的集合记为y3;其中,y3中的每幅特征图的宽度为
对于第3个级联层,第3个级联层的输入端接收y3中的所有特征图和c7中的所有特征图,第3个级联层的输出端输出384幅特征图,将384幅特征图构成的集合记为l3;其中,l3中的每幅特征图的宽度为
对于第8个神经网络块,第三十卷积层的输入端接收l3中的所有特征图,第三十卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c30;第三十一卷积层的输入端接收c30中的所有特征图,第三十一卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c31;其中,c30、c31各自中的每幅特征图的宽度为
对于第4个上采样层,第4个上采样层的输入端接收c31中的所有特征图,第4个上采样层的输出端输出128幅特征图,将128幅特征图构成的集合记为y4;其中,y4中的每幅特征图的宽度为w、高度为h。
对于第4个级联层,第4个级联层的输入端接收y4中的所有特征图和c3中的所有特征图,第4个级联层的输出端输出192幅特征图,将192幅特征图构成的集合记为l4;其中,l4中的每幅特征图的宽度为w、高度为h。
对于第9个神经网络块,第三十二卷积层的输入端接收l4中的所有特征图,第三十二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c32;第三十三卷积层的输入端接收c32中的所有特征图,第三十三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c33;其中,c32、c33各自中的每幅特征图的宽度为w、高度为h。
对于第10个神经网络块,第三十四卷积层的输入端接收c16中的所有特征图,第三十四卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c34;第三十五卷积层的输入端接收c34中的所有特征图,第三十五卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c35;第三十六卷积层的输入端接收c35中的所有特征图,第三十六卷积层的输出端输出512幅特征图,将512幅特征图构成的集合记为c36;其中,c34、c35、c36各自中的每幅特征图的宽度为
对于第5个上采样层,第5个上采样层的输入端接收c36中的所有特征图,第5个上采样层的输出端输出512幅特征图,将512幅特征图构成的集合记为y5;其中,y5中的每幅特征图的宽度为
对于第5个级联层,第5个级联层的输入端接收y5中的所有特征图和c13中的所有特征图,第5个级联层的输出端输出768幅特征图,将768幅特征图构成的集合记为l5;其中,l5中的每幅特征图的宽度为
对于第11个神经网络块,第三十七卷积层的输入端接收l5中的所有特征图,第三十七卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c37;第三十八卷积层的输入端接收c37中的所有特征图,第三十八卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c38;第三十九卷积层的输入端接收c38中的所有特征图,第三十九卷积层的输出端输出256幅特征图,将256幅特征图构成的集合记为c39;其中,c37、c38、c39各自中的每幅特征图的宽度为
对于第6个上采样层,第6个上采样层的输入端接收c39中的所有特征图,第6个上采样层的输出端输出256幅特征图,将256幅特征图构成的集合记为y6;其中,y6中的每幅特征图的宽度为
对于第6个级联层,第6个级联层的输入端接收y6中的所有特征图和c8中的所有特征图,第6个级联层的输出端输出384幅特征图,将384幅特征图构成的集合记为l6;其中,l6中的每幅特征图的宽度为
对于第12个神经网络块,第四十卷积层的输入端接收l6中的所有特征图,第四十卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c40;第四十一卷积层的输入端接收c40中的所有特征图,第四十一卷积层的输出端输出128幅特征图,将128幅特征图构成的集合记为c41;其中,c40、c41各自中的每幅特征图的宽度为
对于第7个上采样层,第7个上采样层的输入端接收c41中的所有特征图,第7个上采样层的输出端输出128幅特征图,将128幅特征图构成的集合记为y7;其中,y7中的每幅特征图的宽度为w、高度为h。
对于第7个级联层,第7个级联层的输入端接收y7中的所有特征图和c4中的所有特征图,第7个级联层的输出端输出192幅特征图,将192幅特征图构成的集合记为l7;其中,l7中的每幅特征图的宽度为w、高度为h。
对于第13个神经网络块,第四十二卷积层的输入端接收l7中的所有特征图,第四十二卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c42;第四十三卷积层的输入端接收c42中的所有特征图,第四十三卷积层的输出端输出64幅特征图,将64幅特征图构成的集合记为c43;其中,c42、c43各自中的每幅特征图的宽度为w、高度为h。
对于第8个级联层,第8个级联层的输入端接收c33中的所有特征图和c43中的所有特征图,第8个级联层的输出端输出128幅特征图,将128幅特征图构成的集合记为l8;其中,l8中的每幅特征图的宽度为w、高度为h。
对于输出层,第四十四卷积层的输入端接收l8中的所有特征图,第四十四卷积层的输出端输出12幅与原始输入图像对应的语义分割预测图;其中,每幅语义分割预测图的宽度为w、高度为h。
步骤1_3:将训练集中的每幅原始的道路场景图像作为原始输入图像,输入到卷积神经网络中进行训练,得到训练集中的每幅原始的道路场景图像对应的12幅语义分割预测图,将{iq(i,j)}对应的12幅语义分割预测图构成的集合记为
步骤1_4:计算训练集中的每幅原始的道路场景图像对应的12幅语义分割预测图构成的集合与对应的真实语义分割图像处理成的12幅独热编码图像构成的集合之间的损失函数值,将
步骤1_5:重复执行步骤1_3和步骤1_4共v次,得到卷积神经网络分类训练模型,并共得到q×v个损失函数值;然后从q×v个损失函数值中找出值最小的损失函数值;接着将值最小的损失函数值对应的权值矢量和偏置项对应作为卷积神经网络分类训练模型的最优权值矢量和最优偏置项,对应记为wbest和bbest;其中,v>1,在本实施例中取v=300。
所述的测试阶段过程的具体步骤为:
步骤2_1:令
步骤2_2:将
为了进一步验证本发明方法的可行性和有效性,进行实验。
使用基于python的深度学习库keras2.1.5搭建卷积神经网络的架构。采用道路场景图像数据库camvid测试集来分析利用本发明方法预测得到的道路场景图像的分割效果如何。这里,利用评估语义分割方法的3个常用客观参量作为评价指标,即像素精度(pixelaccuracy,pa)、均像素精度(meanpixelaccuracy,mpa)、均交并比(meanintersectionoverunion,miou)来评价预测语义分割图像的分割性能。
利用本发明方法对道路场景图像数据库camvid测试集中的每幅道路场景图像进行预测,得到每幅道路场景图像对应的预测语义分割图像,反映本发明方法的语义分割效果的像素精度pa、均像素精度mpa、均交并比miou如表1所列,像素精度pa、均像素精度mpa、均交并比miou的值越高,说明有效性和预测准确率越高。从表1所列的数据可知,按本发明方法得到的道路场景图像的分割结果是较好的,表明利用本发明方法来获取道路场景图像对应的预测语义分割图像是可行性且有效的。
表1利用本发明方法在测试集上的评测结果
图3a给出了选取的一幅待语义分割的道路场景图像;图3b给出了图3a所示的待语义分割的道路场景图像对应的真实语义分割图像;图3c给出了利用本发明方法对图3a所示的待语义分割的道路场景图像进行预测,得到的预测语义分割图像;图4a给出了选取的另一幅待语义分割的道路场景图像;图4b给出了图4a所示的待语义分割的道路场景图像对应的真实语义分割图像;图4c给出了利用本发明方法对图4a所示的待语义分割的道路场景图像进行预测,得到的预测语义分割图像。对比图3b和图3c,对比图4b和图4c,可以看出利用本发明方法得到的预测语义分割图像的分割精度较高,接近真实语义分割图像。
- 还没有人留言评论。精彩留言会获得点赞!