基于子图像和随机采样的模糊2D-LDA人脸识别方法与流程
本发明属于生物特征识别领域的一种方法,具体为“基于子图像和随机采样的模糊2d-lda人脸识别方法”,主要应用模式识别和机器学习领域技术实现人脸识别。
背景技术:
生物特征识别已经在我们的工作和生活中普及,与普通的密码卡,智能卡和银行卡相比,不存在被盗用与复制的危险。而人脸识别因为不具侵犯性,符合人们生活中自身识别的习惯,是一种非常人性化的技术,因而在生物识别中占据非常重要的位置。近年来,人脸识别技术在考勤,门禁,社区安防,海陆空关口通行,军事安全,银行金融系统,逮捕嫌疑犯和反恐等方面开始应用。其背后的人脸识别算法以及相关系统的不断发展为该技术的应用提供了强有力的支持。
虽然目前已经有许多人脸分析任务取得了较大的成就,但是在落地过程中仍然面临许多挑战,例如图像存在着光线不均匀,遮挡,模糊,不匹配不对齐等问题。这些问题极有可能导致图像类内的差异大于类间的差异,从而影响识别结果。
一般情况下,人脸识别技术步骤包括人脸的检测与定位,图像的预处理,面部特征提取和人脸识别等。其中特征提取作为其中一个至关重要的步骤强烈的影响着最后的识别结果。目前的特征提取方法主要分两类:人工提取方法和基于学习的方法。其中人工提取特征的方法是通过特定的领域只是人工设计特征的,具有较强的人为主观性,虽然可以在特定的任务中取得较好的结果,但是遇到新的数据和任务时往往需要新域的知识,不能直接用于新的任务。其次,基于学习的方法包括子空间方法和深度学习方法。基于子空间的方法出现较早,也是目前最成功和研究最为充分的技术之一。主成分分析(pca)和线性判别分析(lda)是两种经典的子空间方法。lda是一种监督学习方法,它通过最大化类间散度矩阵和最小化类内散度矩阵来找到一组投影向量,能够充分利用样本的类信息,因此性能优于无监督方法pca。但是在人脸识别中,2d图像需要先转化为向量,然后再使用lda或者pca,这不仅会导致小样本问题还破坏了图像原本的空间结构。针对这些问题,后来出现了大量基于这些子空间方法的2d扩展版本。yang和zhang等人提出的2dpca(two-dementionalprincipalcomponentanalysis)是一种直接基于原始二维图像矩阵进行主成分分析的方法。它不需要将原始图像事先转化为向量,而是直接使用原始图像矩阵构建协方差矩阵,和pca相比,其协方差矩阵的规模会小很多,更容易准确地计算。此外,该方法也大大减小了计算特征向量的时间。受2dpca算法的影响,li等人也提出了2dlda算法。该算法相对于传统fisher-face,也有效降低了计算复杂度和时间复杂度。此外,因为其类内和类间散度矩阵的维数比训练样本数小很多,因此可以解决类内散度矩阵可能存在的奇异值问题,从而解决了小样本问题。最近几年深度学习方法得到了广泛的关注。深度学习是一种主动学习特征的算法,是通过组合底层特征形成更加抽象的高层表示,具有更加强大的泛化能力,而且可以有效避免人工提取特征的主观性。但是深度学习方法具有参数多,对调参经验和技巧以及硬件有较高要求的缺点,同时过于复杂的网络还有引发梯度消失/爆炸,性能衰退等问题的风险。schroff等人提出的facenet属于端到端学习的模式,利用dnn直接学习从原始图片到欧氏距离空间的映射,从而使得在欧式空间里的距离的度量直接关系着人脸相似度。该方法在lfw数据集上的识别率高达99.63%,但是依然存在着上述深度学习所具有的共性问题。综上分析,为了避免上述所有方法所面临的问题,该发明的特征提取方法采用了一种新的基于子图像和随机采样的子空间方法。
技术实现要素:
【发明目的】
目前人脸识别算法依然面临许多问题,譬如图像存在着光线不均匀,遮挡,模糊,面部表情变化,不匹配等问题,这些问题极可能导致图像类内的差异大于类间的差异,从而影响识别结果。目前由于人脸识别算法的应用领域也越来越多,从扩展和适用性方面来讲,基于学习方法要普遍优于基于人工提取的方法。而基于学习方法中深度学习虽然可以获得较高的识别率,但是对硬件和调参经验要求较高。因此,条件不足的情况下,采用子空间的学习方法是一个较好的选择。为了缓解上述人脸识别目前还存在的问题,该发明采用基于子图像和随机采样的模糊2d-lda算法,首先添加了成员隶属度,能够尽可能获取到一个样本隐藏在其近邻样本中的类信息(有相关论文已经证明一个样本大约有一半的类信息隐藏在其近邻样本中)。其次采用子图像方法,使用对子图像进行特征提取来取代原始的基于整个图像进行特征提取,更有利于获取局部特征,从而在一定程度上减弱光照等容易引起局部特征变化的环境变化对识别率的影响。此外,我们还使用了随机采样的技术对行向量进行随机采样,增加样本的多样性,提升总体性能。
【技术方案】
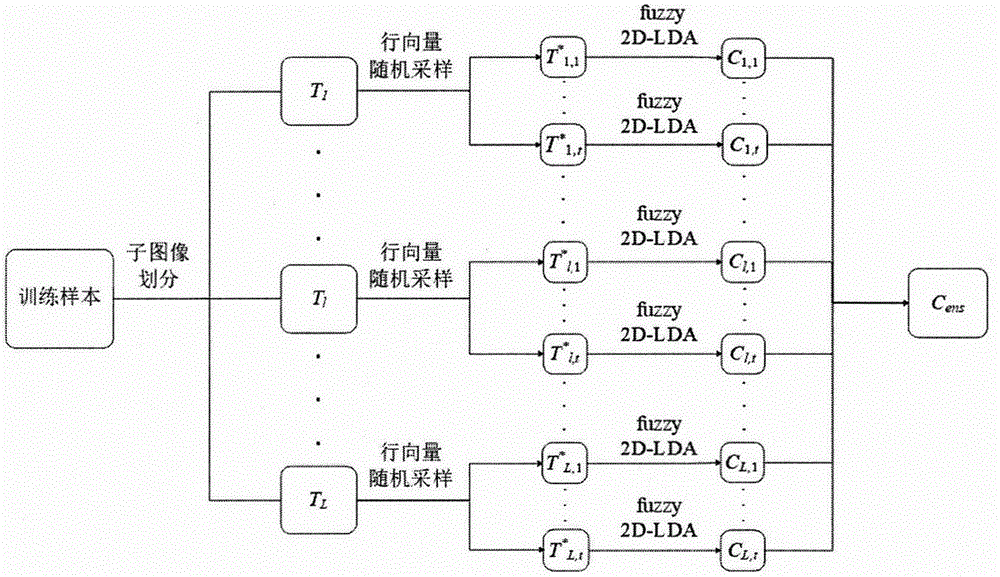
针对上述人脸识别中存在的环境变化问题,我们主要采用了三个技术:①使用子图像的方法,先对原始训练样本进行子图像划分,然后对子图像进行特征提取而非整个图像;②基于模糊理论,对经典的子空间方法之一2d-lda添加成员隶属度,即每个样本属于每个类的概率;③采用行向量随机采样技术,对行向量进行随机采样,而非对特征,样本或参数,从而形成多组特征,进而得到多组结果,最终用于集成。该方法在增加多样性的同时保留了原始图像的部分空间结构信息。本发明包括以下内容:
首先采用局部区域方法对图像进行子图像划分。对每张训练图像以非重叠的方式按照矩形划分为l个大小相同的子图像块,然后将每张图像相同位置的子图像块组合为一个子图像训练集,最终可以得到l个不同的子图像训练集。
然后对每个子图像训练集进行行向量随机采样。随机采样一般包括对样本,特征或参数的随机采样。该发明采用对行向量的随机采样相比于对训练样本或者子图像训练集的特征进行随机采样,可以尽可能地保留图像的部分空间结构信息。对于每个子图像训练集均进行t次的行向量随机采样,最终可以得到l×t个经过随机采样后的子图像训练集。
接着使用模糊2d-lda算法对采样后的子图像训练集进行特征提取。即在2d-lda算法中的类内散度矩阵和类间散度矩阵上加入成员隶属度ui,j。其中ui,j的计算方法是:
ni,j第j个样本的近邻样本中属于第i类的数量,k表示近邻样本数,a和b表示两个参数。该公式的设计能够保证如果第j个样本属于第i类,则第j个样本在第i类的成员隶属度大于其他类的。
得到成员隶属度后,模糊2d-dlda算法中的模糊类内散度矩阵和模糊类间散度矩阵可以分别表示为:
其中m和mi分别表示所有样本数据的平均和第i类样本数据的模糊平均。之后按照最大化模糊类间和类内散度矩阵之比的准则得到投影向量:
特征提取之后,我们为l×t个采样后的子图像集分别构造一个最近邻分类器,即l×t个分类器。对于一个测试样本p,我们按照上述步骤,先进行子图像划分得到pl(l=1,…,l),接着对其分别进行行向量随机采样得到
【有益效果】
yalea数据集的识别错误率(%)
extendedyaleb的识别错误率(%)
orl数据集的识别错误率(%)
ar数据集的识别错误率(%)
我们使用开发工具matlab实现本发明所提出的人脸识别算法rs-subimage-f2dlda。该算法中的基分类器为最近邻分类器,成员隶属度中的参数a,b和k根据经验设置分别设为0.51,0.49和5。此外对行向量进行随机采样的采样率为0.5,随机采样次数t=20。以yalea,extendedyaleb,orl和ar为实验数据集,将rs-subimage-f2dlda与现有的一些同类型的算法进行分类错误率对比,验证我们所提出的人脸识别算法有较低的错误率。(上述表中的每一行表示一种算法在不同数量的训练样本集下,测试集的平均错误率。)此外,实验过程中,yalea,extendedyaleb和orl的子图像块大小为8×8,ar数据集的为6×6。本发明还具有一定的推广性,不仅仅可用于人脸识别,也可用于字体识别,图像识别等。
附图说明
图1:rs-subimage-f2dlda人脸识别算法结构图
图2:子图像划分结构图
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定。
以yalea数据集为一个实验例,每个对象随机选择三张图像作为训练样本。本发明框架如图1所示,先对yalea训练样本进行子图像划分,子图像划分方式如图2所示,原始图像样本大小为64×64,子图像块大小设置大小为8×8,所以每张图像可划分子图像块的个数为l=64,共产生64个子图像训练集。然后对每个子图像集进行行向量随机采样,随机采样次数为t=20,最终得到l×t(64×20)个随机采样后的子图像训练集。之后,对于每一个随机采样后的子图像训练集分别使用模糊2d-lda算法进行特征提取,得到l×t个投影向量,并构建l×t个最近邻分类器。
然后可以将测试样本进行上述类似步骤,进行子图像划分,行向量随机采样,然后使用上述训练集中得到投影矩阵进行特征提取,然后使用相对应的最近邻分类器分别进行分类,最终将所有的分类结果进行多数投票法集成,进而得到最终的识别结果。以下是rs-subimage-f2dlda的伪代码实现;
该发明在实际应用过程中直接得到预测类标签即可,无需计算识别错误率,也无需执行第11步。实验例计算平均识别错误率是为了更严谨地衡量该发明的性能。
- 还没有人留言评论。精彩留言会获得点赞!