一种基于特征融合的安全驾驶判别方法、系统及车辆与流程
本发明涉及车辆技术领域,具体涉及一种基于特征融合的安全驾驶判别方法、系统及车辆。
背景技术:
随着国内经济的发展,人们生活水平的提高,使得越来越多的家庭和个人拥有了车辆,而车辆是一种高速运行的工具,给人们带来便捷的同时,也隐藏着危险。且随着车辆的增多,交通事故的数次也增加。其最重要的原因在于司机,司机驾驶时的情绪会影响其驾驶行为,给自身和他人带来了严重的危险。
对比文件1(cn104574819a)公开了一种基于嘴巴特征的疲劳驾驶检测方法,通过监控驾驶员的嘴巴张开特征,并依据打哈欠行为来判断驾驶员是否处于疲劳驾驶状态。对比文件2(cn104809445b)公开了基于眼部和嘴部状态的疲劳驾驶检测方法,通过结合眼部和嘴部两个特征参数进行判断,与单一参数相比对疲劳判断的准确率和可靠性更高。对比文件3(cn106682603a)公开了一种基于多源信息融合的实时驾驶员疲劳预警系统,通过实时的跟踪定位出的眼睛和嘴巴,满足实时对司机驾驶的疲劳状态作出准确预测的需求。
目前的安全驾驶判别方法都是采用嘴巴特征、眼睛特征或者两者结合来判断,现有技术中基于嘴巴特征、眼部特征或其结合而言算法都比较复杂,且影响安全驾驶判别方法的精度,甚至会出现判断延迟。因此,现有技术还有待于改进和发展。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供了一种基于特征融合的安全驾驶判别方法、系统及车辆,旨在解决现有技术中算法复杂、精度低且判断延迟的问题。
本发明解决技术问题所采用的技术方案如下:
一种基于特征融合的安全驾驶判别方法,包括以下步骤:
获取待识别的语音信号,形成基于语音信号的第一识别结果;
获取待识别的人脸信号的特征,形成基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果;
将所述第一识别结果、第二识别结果和第三识别结果通过融合算法进行融合处理输出一融合结果;
根据所述融合结果判断是否处于安全驾驶状态。
优选地,所述基于语音信号的第一识别结果的形成方法为:
将获取的语音信号进行预处理;
对预处理后的语音信号进行分析,得出相邻的两个语音信号之间的时间间隔;
若该时间间隔大于一设定阀值,则所述第一识别结果为连续语音输出,否则所述第一识别结果为非连续语音输出。
优选地,所述基于视觉特征的第二识别结果的形成方法为:
获取训练数据集;
采用基于深度神经网络算法对训练数据集的微表情进行识别,形成表情识别结果;
将获取的待识别的人脸信号的特征与表情识别结果进行比对,形成第二识别结果,所述第二识别结果包括平和、开心、惊讶、伤心、生气、厌恶、恐惧或轻视。
优选地,所述基于嘴巴特征的第三识别结果的形成方法为:
提取帧图像检测人脸,嘴部粗定位进行肤色分割;
对嘴部进行精确定位,获取嘴部外轮廓张口度特征值;
计算一设定时间内张口度特征值大于设定阈值的总数,并计入所述第三识别结果中。
优选地,所述将所述第一识别结果、第二识别结果和第三识别结果通过融合算法进行融合处理输出一融合结果的具体方法为:
将第一识别结果和第三识别结果进行融合,形成第一输出结果;
将第一输出结果与第二识别结果进行融合,形成第二输出结果;
所述第一输出结果为驾驶人员处于说话状态且处于不安全驾驶状态、驾驶人员处于非说话状态且处于安全驾驶状态、驾驶人员处于哈欠状态且处于不安全驾驶状态、驾驶人员处于非哈欠状态且处于安全驾驶状态或驾驶员处于安全驾驶状态,所述第二输出结果为安全驾驶状态、轻度不安全驾驶状态、中度不安全驾驶状态或重度不安全驾驶状态。
优选地,所述将第一识别结果和第三识别结果进行融合,形成第一输出结果的具体方法包括:
若第一识别结果为连续语音输出,则判断第三识别结果的张口度特征值大于设定阈值的总数是否大于设定值,若是则第一输出结果为驾驶人员处于说话状态且处于不安全驾驶状态,否则第一输出结果为驾驶人员处于非说话状态且处于安全驾驶状态。
优选地,所述将第一识别结果和第三识别结果进行融合,形成第一输出结果的具体方法还包括:
若第一识别结果为非连续语音输出,则判断第三识别结果的张口度特征值大于设定阈值的总数是否大于设定值;若是则计算嘴部内轮廓张口度特征值,若该嘴部内轮廓张口度特征值大于阀值,则第一输出结果为驾驶人员处于哈欠状态且处于不安全驾驶状态,若该嘴部内轮廓张口度特征值小于阀值,则第一输出结果为驾驶人员处于非哈欠状态且处于安全驾驶状态;若第三识别结果为张口度特征值大于设定阈值的总数小于设定值,则第一输出结果为驾驶员处于安全驾驶状态。
优选地,所述根据所述融合结果判断是否处于安全驾驶状态后还包括:根据驾驶状态信息对车辆进行控制。
一种基于特征融合的安全驾驶判别系统,包括以下模块:
语音信号获取模块,用于获取待识别的语音信号,形成基于语音信号的第一识别结果;
人脸信号获取模块,用于获取待识别的人脸信号的特征,形成基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果;
融合模块,用于将所述第一识别结果、第二识别结果和第三识别结果通过融合算法进行融合处理输出一融合结果;
判断模块,用于根据所述融合结果判断是否处于安全驾驶状态;
控制模块,用于根据驾驶状态信息对车辆进行控制。
一种车辆,包括车辆本体,该车辆本体内包括上述的基于特征融合的安全驾驶判别系统。
与现有技术相比,本申请实施例主要有以下有益效果:
本发明所提供的基于特征融合的安全驾驶判别方法、系统及车辆,将基于语音信号的第一识别结果和基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果进行融合,通过融合结果来判断车辆是否处于安全驾驶状态,这样提高安全驾驶判别方法的精度,避免处于延迟现象,同时也能降低算法的复杂程度。
附图说明
为了更清楚地说明本申请的方案,下面将对实施例描述中所需要使用的附图作一个简单介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明基于特征融合的安全驾驶判别方法较佳实施例的流程图。
图2是本发明中基于语音信号的第一识别结果的形成方法流程图。
图3是本发明中基于视觉特征的第二识别结果的形成方法流程图。
图4是本发明中基于视觉特征的第三识别结果的形成方法流程图。
图5是本发明中嘴唇轮廓结构示意图。
图6是本发明嘴巴特征的提取示意图。
图7是本发明中融合算法流程图。
图8是本发明基于特征融合的安全驾驶判别系统较佳实施例的框图。
图9是本发明中语音信号获取模块的框图。
图10是本发明中人脸信号获取模块的框图。
具体实施方式
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请技术领域的技术人员通常理解的含义相同;本文中在申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本申请;本申请的说明书和权利要求书及上述附图说明中的术语“包括”和“具有”以及它们的任何变形,意图在于覆盖不排他的包含。本申请的说明书和权利要求书或上述附图中的术语“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。
在本文中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本文所描述的实施例可以与其它实施例相结合。
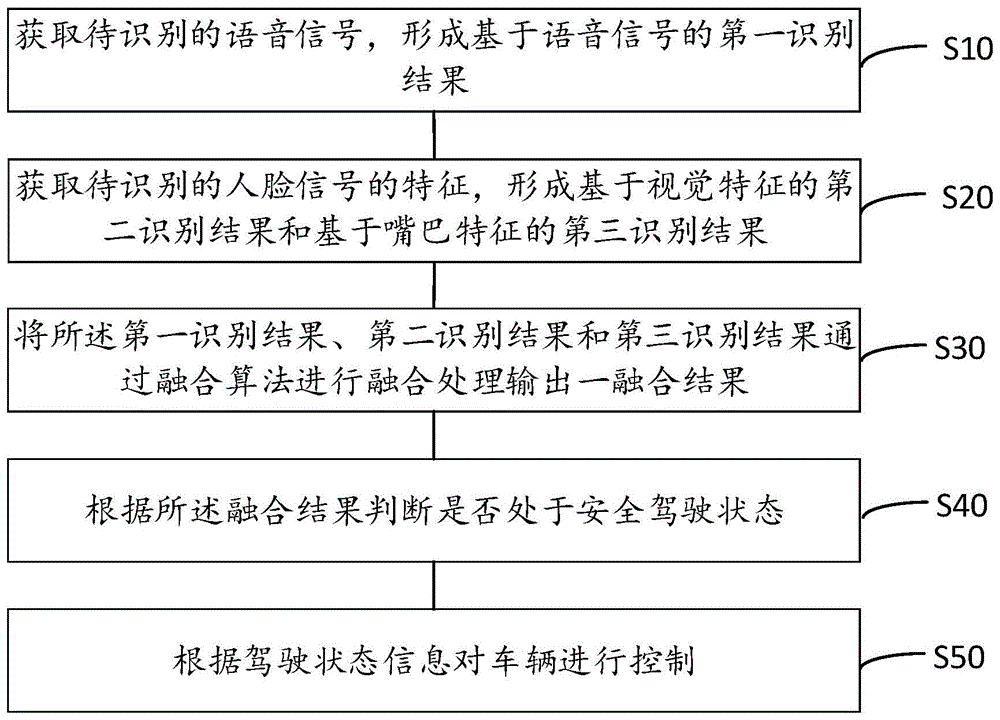
本发明实施例提供了一种基于特征融合的安全驾驶判别方法,如图1所示,包括以下步骤:
步骤s10:获取待识别的语音信号,形成基于语音信号的第一识别结果;
步骤s20:获取待识别的人脸信号的特征,形成基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果;
步骤s30:将所述第一识别结果、第二识别结果和第三识别结果通过融合算法进行融合处理输出一融合结果;
步骤s40:根据所述融合结果判断是否处于安全驾驶状态;
步骤s50:根据驾驶状态信息对车辆进行控制。
如图2所示,本发明进一步较佳实施例中,所述基于语音信号的第一识别结果的形成方法为:
步骤s110:将获取的语音信号进行预处理,包括滤波和a/d转换;
步骤s120:对预处理后的语音信号进行分析,即根据a/d转换后的波形图,得出相邻的两个语音信号之间的时间间隔t;
步骤s130:若该时间间隔t大于一设定阀值t2,则所述第一识别结果为连续语音输出,否则所述第一识别结果为非连续语音输出。
如图3所示,本发明进一步较佳实施例中,所述基于视觉特征的第二识别结果的形成方法为:
步骤s210:获取训练数据集,可采用ferc-2013(脸部表情识别比赛数据集),ck+(extendedcohn-kanade)和rafd(radboundfacesdatabase)等等的混合数据集,共12万张表情图片;
步骤s220:采用基于深度神经网络算法对训练数据集的微表情进行识别,形成表情识别结果,具体为:采用tensorflow+keras框架自主搭建卷积神经网络结构,其输入大小为48*48的单通道图片,经过2层64个过滤器大小3*3的卷积层和1个过滤器大小为2*2、步长为2的池化层,2层128个过滤器大小3*3的卷积层和1个过滤器大小为2*2、步长为2的池化层,2个3层256个过滤器大小3*3的卷积层和1个过滤器大小为2*2、步长为2的池化层,接着经过三层1024个节点的全连接层,最后输出表情识别结果,包括平和、开心、惊讶、伤心、生气、厌恶、恐惧或轻视。
步骤s230:将获取的待识别的人脸信号的特征与表情识别结果进行比对,比对方法可以采用人脸属性识别技术,形成第二识别结果,所述第二识别结果包括平和、开心、惊讶、伤心、生气、厌恶、恐惧或轻视。
如图4所示,本发明进一步较佳实施例中,所述基于嘴巴特征的第三识别结果的形成方法为:
步骤s240:提取帧图像检测人脸,嘴部粗定位(例如landmark可进行粗定位)进行肤色分割;
步骤s250:对嘴部进行精确定位,获取嘴部外轮廓张口度特征值,如图5所示,张口度a的计算公式为,a=(h+τup+τdown)/lm;
步骤s260:计算一设定时间内张口度特征值a大于设定阈值的总数,并计入所述第三识别结果中。
如图6所示,本发明进一步较佳实施例中,所述融合算法具体为:
步骤s310:判断第一识别结果是否为连续语音输出,若是则执行步骤s311,否则执行步骤s314;
步骤s311:判断第三识别结果:张口度特征值大于设定阈值的总数大于设定值,若是则执行步骤s312,否则执行步骤s313;
步骤s312:输出第一输出结果:驾驶人员处于说话状态且处于不安全驾驶状态;
步骤s313:输出第一输出结果:驾驶人员处于非说话状态且处于安全驾驶状态;
步骤s314:判断第三识别结果:嘴部外轮廓张口度特征值a大于设定阈值的总数大于设定值,若是则执行步骤s315,否则执行步骤s318;
步骤s315:判断嘴部内轮廓张口度特征值是否大于阈值,嘴部内轮廓张口度特征值的计算公式为(如图5所示)b=h/l,若是则执行步骤s316:输出第一输出结果为驾驶人员处于哈欠状态且处于不安全驾驶状态,否则执行步骤s317:输出第一输出结果为驾驶人员处于非哈欠状态且处于安全驾驶状态;
嘴部内轮廓可对对嘴部图像做垂直方向的gabor变换,然后再经过二值化得到内部轮廓。
步骤s318:输出第一输出结果:驾驶员处于安全驾驶状态;
步骤s319:判断第二识别结果,为平和、开心、惊讶、伤心、轻视、厌恶、恐惧或生气;
步骤s320:融合第一输出结果和第二识别结果,输出第二输出结果,第二输出结果有安全驾驶状态、轻度不安全驾驶状态、中度不安全驾驶状态和重度不安全驾驶状态。最后可根据第二输出结果来控制车辆状态,例如控制车速等方法。这种控制车辆状态可以根据第二输出结果来预先设定,以适用不同的驾驶习惯要求,当然,在设定的原则是确保车辆安全驾驶。
为了便于描述本实施例中的融合算法,下面以列表形式进行表述,如表1所示。
表1
如图7所示,本发明还提供一种基于特征融合的安全驾驶判别系统,包括以下模块:
语音信号获取模块,用于获取待识别的语音信号,形成基于语音信号的第一识别结果;
人脸信号获取模块,用于获取待识别的人脸信号的特征,形成基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果;
融合模块,用于将所述第一识别结果、第二识别结果和第三识别结果通过融合算法进行融合处理输出一融合结果;
判断模块,用于根据所述融合结果判断是否处于安全驾驶状态;
控制模块,用于根据驾驶状态信息对车辆进行控制。
如图9所示,本发明进一步较佳实施例中,所述语音信号获取模块包括:
语音信号预处理模块,用于将获取的语音信号进行预处理;
语音信号分析模块,用于对预处理后的语音信号进行分析,得出相邻的两个语音信号之间的时间间隔;
输出模块,若该时间间隔大于一设定阀值,则所述第一识别结果为连续语音输出,否则所述第一识别结果为非连续语音输出。
如图10所示,本发明进一步较佳实施例中,所述人脸信号获取模块包括:
训练数据集模块,用于获取训练数据集;
深度神经网络模块,用于采用基于深度神经网络算法对训练数据集的微表情进行识别,形成表情识别结果;
比对模块,用于将获取的待识别的人脸信号的特征与表情识别结果进行比对,形成第二识别结果,所述第二识别结果包括平和、开心、惊讶、伤心、生气、厌恶、恐惧或轻视。
嘴部粗定位模块,用于提取帧图像检测人脸,嘴部粗定位进行肤色分割;
嘴部精定位模块,用于对嘴部进行精确定位,获取嘴部外轮廓张口度特征值;
计算模块,用于计算一设定时间内外轮廓张口度特征值大于设定阈值的总数,并计入所述第三识别结果中。
本发明还提供一种车辆,包括车辆本体,该车辆本体内包括上述的基于特征融合的安全驾驶判别系统。
作为本发明的一种实施例,本发明中的车辆包括但不限于各种形式的机油汽车、柴油汽车、新能源汽车等。
综上所述,本发明公开了一种基于特征融合的安全驾驶判别方法、系统及车辆,将基于语音信号的第一识别结果和基于视觉特征的第二识别结果和基于嘴巴特征的第三识别结果进行融合,通过融合结果来判断车辆是否处于安全驾驶状态,这样提高安全驾驶判别方法的精度,避免处于延迟现象,同时也能降低算法的复杂程度。
显然,以上所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例,附图中给出了本申请的较佳实施例,但并不限制本申请的专利范围。本申请可以以许多不同的形式来实现,相反地,提供这些实施例的目的是使对本申请的公开内容的理解更加透彻全面。尽管参照前述实施例对本申请进行了详细的说明,对于本领域的技术人员来而言,其依然可以对前述各具体实施方式所记载的技术方案进行修改,或者对其中部分技术特征进行等效替换。凡是利用本申请说明书及附图内容所做的等效结构,直接或间接运用在其他相关的技术领域,均同理在本申请专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!