基于综合得分法水文模型精度识别的方法与流程
本发明属于水文水资源技术领域,涉及一种基于综合得分法水文模型精度识别的方法。
背景技术:
流域内降雨径流过程是一个复杂的问题,历来备受水文学者的关注。水文模型是研究水文循环和各种水文过程中无法替代的重要工具,水文模拟的确定性方法主要是基于数学方程和物理模型构建水文模型,对复杂的水文过程进行抽象和概化,具有化繁为简的优点,但水文模型并非能完全地模拟和预测复杂的水文系统,研究过程中不可避免地简化处理使得模拟和预测过程中存在必然的不确定性,导致模型的模拟精度受到影响,因此,对水文模型进行模型精度评价是十分必要的。
目前研究多使用一种或几种评价指标进行模型精度评价,这使得一些模型在不同评价指标下呈现出不同的模拟精度水平,且评价指标离散化,缺乏系统性,亟需构建评价指标体系化,以便有效解决模型精度集合评估问题。
技术实现要素:
本发明的目的是提供一种基于综合得分法水文模型精度识别的方法,通过建立指标综合评价体系,构造模型综合得分,准确地进行多指标下的模型精度集合评估。
本发明所采用的技术方案是,一种基于综合得分法水文模型精度识别的方法,具体按照以下步骤实施:
步骤1、收集整理研究区各水文站的水文资料,包括各站逐年日降雨量及日径流量,选择用于径流量拟合的水文模型;
步骤2、对步骤1收集整理的水文资料进行前期处理,分析各站点资料的趋势性变化,划分模型率定期及验证期,进行水文模型模拟及参数率定,计算各模型精度评价指标值;
步骤3、对收集到的研究区各水文站降雨量及径流量数据进行归一化处理,引入惩罚因子,计算各评价指标的隶属度值;
步骤4、对步骤3得到的各指标隶属度值先进行主成分分析,得到指标敏感性排名;然后,进行指标的层次分析得到指标权重;
步骤5、根据步骤3和步骤4得到的各模型指标隶属度值及权重,构建模型综合指标,根据综合指标进行各模型精度评价。
本发明的有益效果是,该方法基于综合得分法水文模型进行精度识别,解决了现有技术不能综合全面地评价各水文模型在降雨、径流模拟精度方面的问题。针对依据各模型模拟结果所得的多个精度评价指标,得到不同指标对径流量模拟的隶属度;在分析时综合考虑主客观计算方法,采用主成分回归分析进行各指标的敏感性排名,并以此进行层次分析法权重计算;在评价模型精度时,考虑各模型指标的加权得分,以指标综合得分作为模型精度评价的最终依据。
附图说明
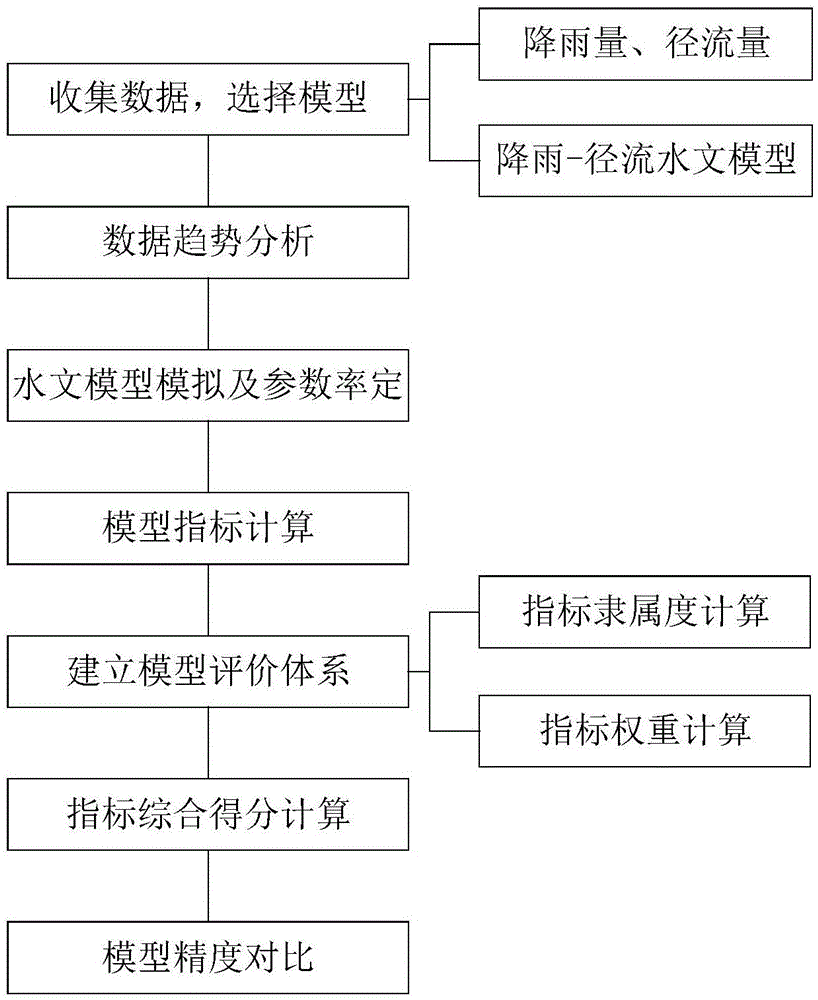
图1为本发明基于综合得分法水文模型精度识别方法的流程图;
图2为本发明实施例的研究区水文站网及河流水系;
图3a为本发明率定期模型评价指标隶属度计算值统计图一;
图3b为本发明率定期模型评价指标隶属度计算值统计图二;
图3c为本发明率定期模型评价指标隶属度计算值统计图三;
图3d为本发明率定期模型评价指标隶属度计算值统计图四;
图4a为本发明验证期模型评价指标隶属度计算值统计图一;
图4b为本发明验证期模型评价指标隶属度计算值统计图二;
图4c为本发明验证期模型评价指标隶属度计算值统计图三;
图4d为本发明验证期模型评价指标隶属度计算值统计图四。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
参照图1,本发明的基于综合得分法水文模型精度识别的方法,具体按照以下步骤实施:
步骤1、收集整理研究区各水文站的水文资料,包括各站逐年日降雨量及日径流量,选择用于径流量拟合的水文模型(四个常用的水文模型见表1);
步骤2、对步骤1收集整理的水文资料进行前期处理,分析各站点资料的趋势性变化,划分模型率定期及验证期,进行水文模型模拟及参数率定,计算各模型精度评价指标值;
具体过程如下:
2.1)采用mk趋势检验及pettitt检验对各水文站点水文资料进行趋势及变点分析,根据得到的突变年份,将研究时段分为率定期及验证期;
2.2)根据步骤1选取的水文模型进行降雨径流关系拟合,将研究区实测降雨量及径流量数据代入选取的水文模型中,得到各水文模型的率定参数,再根据确定参数后的水文模型计算模拟径流量;
2.3)根据各模型实测及模拟径流量,分别计算各模型在率定期及验证期内的精度评价指标值,评价指标包括纳什效率系数nse、决定性系数r2、校正决定性系数adjustedr2、相对误差re、一致性指数d、相对均方根误差rmse、相对平方均方误差msesq及相对对数均方误差mseln,各评价指标均为现有技术,各自具有自己的算法,具体公式见表2;
步骤3、对收集到的研究区各水文站降雨量及径流量数据进行归一化处理,引入惩罚因子,计算各评价指标的隶属度值;
具体过程如下:
3.1)对所得的各评价指标引入惩罚因子,用来防治出现过度拟合,改进后惩罚因子为:
其中k为模型参数个数,n为水文序列长度;
3.2)在所建立的评价指标体系中,由于定量指标的量纲不统一,很难直接应用于模型评价,所以必须对步骤3.1)所得各评价指标值进行无量纲化,将指标实际量值转化为0~1区间上的无量纲数,计算公式如下:
极小最优型:
极大最优型:
适中最优型:
根据式(2)~式(4)及表2所给的各指标隶属度类型,计算得到各模型下不同指标的隶属度值。
步骤4、对步骤3得到的各指标隶属度值先进行主成分分析,得到指标敏感性排名;然后,进行指标的层次分析得到指标权重;
具体过程如下:
4.1)根据步骤3综合不同指标在各模型各时期所得隶属度值,构成隶属度矩阵,进行评价指标的主成分分析,
使用r语言编程实现该步骤,计算提取特征根大于1,且累积方差大于80%的成分为评价体系的主成分,得到各主成分的方差贡献率及载荷矩阵;
4.2)进行各指标的敏感性排名,
由步骤4.1)所得,对各主成分的方差贡献率及主成分载荷矩阵进行加权平均,得到各评价指标综合得分,综合得分排名即为指标敏感性排名;
4.3)根据步骤4.2)所得指标敏感性排名进行指标层次分析法计算,
构造指标判断矩阵b-ci,计算得到评价体系的一致性指数ci及一致性比率cr,当ci>0且cr<0.1时说明评价体系的判断矩阵均具有满意的一致性,由此得到判断矩阵的层次排序权值,作为各评价指标权重。
步骤5、根据步骤3和步骤4得到的各模型指标隶属度值及权重,构建模型综合指标,根据综合指标进行各模型精度评价,
具体过程如下:
根据步骤3和步骤4得到的各模型指标隶属度值及权重,计算模型综合指标,综合指标的计算公式为:
其中,scorem为水文模型综合得分;wi为第i项模型精度评价指标的权重;indexi,m为第i项模型精度评价指标的隶属度值;
分别计算各模型下不同站点在率定期及验证期的综合得分,并对综合得分进行排名,以综合得分作为模型模拟精度评价因子,进行各模型精度评价分析;对比各模型在率定期及验证期内综合得分排名,最终确定各站点的最优拟合模型。
实施例:
黄河中游水沙问题一直都是水文研究的重点领域,对该地区水文模拟的研究有利于发展流域系统降雨产流预测理论方法,深入开展黄河中游典型流域水沙治理工作。本发明方法以黄河中游窟野河、秃尾河及无定河3个典型流域为研究对象,如图2所示,建立起径流量模拟的多指标确定性模型精度评估体系,进行黄河中游典型流域水文模型精度集合评价。具体过程如下:
首先计算各模型拟合参数值,将无定河、窟野河、秃尾河流域1960~2010年降雨和年径流数据带入选取的4个常用水文模型中,得到各模型的率定参数,见表1。
表1各站点降雨径流模拟及参数率定
注:w(模拟径流量/亿m3)、pa(年降雨量/mm)、pf(汛期降雨量/mm)、p7+8(7月及8月总降雨量/mm)、p6+9(6月及9月总降雨量/mm)。
由此得到各模型模拟径流量,并由下表2构建的模型精度评价体系计算各模型在率定期及验证期内的精度评价指标值。
表2确定性模型精度评价指标标准
计算中引入惩罚因子后得到的各指标隶属度值见图3a、图3b、图3c、图3d、图4a、图4b、图4c、图4d,由图3a、图3b、图3c、图3d所示的率定期各指标数值,以及图4a、图4b、图4c、图4d所示的验证期各指标数值,可知不同指标对同一模型的精度表达各不相同,因此进行系统性指标评估是十分必要的。构建隶属度矩阵进行主成分分析并得到模型评价体系的敏感性排名见下表3,可知评价体系中一致性指数d最为敏感,最能体现模型精度情况,相对对数均方误差mseln敏感性最差,能体现模型精度的能力最差。
表3模型精度评价指标敏感性排名
以敏感性排名为依据进行指标层次分析法计算,构造指标判断矩阵见下表4,其中ci=0.014>0且cr=0.010<0.1表明评价体系的判断矩阵均具有满意的一致性,由此得到各指标的权重值。
表4模型精度评价体系b-ci判断矩阵
以隶属度与权重乘积构造指标综合得分,分别计算率定期及验证期内各模型下不同站点的综合得分,并进行排名,见下表5,则排名越靠前模型精度越高。
表5各模型下站点指标综合得分计算结果
注:*表示最优模型类型。
由表5可知,率定期及验证期内各站点的综合指数排名在不同的水文模型下表现出不同的拟合优势。总观各模型之间来看,率定期与验证期平均得分表明四个模型对于各站点径流量的模拟精度大致相当,且各模型率定期的模拟精度均高于验证期,其中率定期内模型二的精度最高(0.66),模型四的精度最低(0.58),验证期内模型三的精度最高(0.48),模型一的精度最低(0.44);各模型在验证期的模拟精度下降原因在于,研究序列降雨量并无显著变化,而径流量存在突变点,因此认为突变年份之后引起径流量变化的影响因素增多,不只为降雨量,则在突变后的验证期内,根据降雨量模拟的模型精度会降低;在各模型中,模型一的精度降幅最大(数值为0.20),模型三的降幅最小(数值为0.11)。
对比同一模型中,指标排名越靠前表明此模型对该站点的模拟精度越高,计算结果显示,除神木站外各站点在不同模型下的排名顺序基本接近,其中白家川站精度最高;总体上各流域内站点模拟精度呈从上游至下游逐渐增高趋势,无定河流域较其他流域模拟最好,窟野河流域王道恒塔站及神木站的模拟精度最低;另外模型三下各站点在率定期及验证期精度排名变化情况最小,认为该模拟精度较为稳定。
- 还没有人留言评论。精彩留言会获得点赞!