一种基于人体交互动作的体验者动作生成方法与流程
本发明涉及计算机图像处理技术领域,特别是涉及一种人体交互动作的体验者动作生成方法。
背景技术:
随着计算机领域的不断发展,用户对图像以及视频处理技术的要求越来越高,交互式的舞蹈动作生成,作为一种娱乐方式以及基本性的计算机图像处理工作吸引了很多研究者的目光。
体验者动作生成,一般指通过一些具体的动作,可以将这些动作迁移到体验者的身上,合成一段数字影像,可以让体验者切实的感受到自己从未经历过的一些动作。
现有技术中公开了一种关于pix2pix图像翻译的方法,虽然该方法能够对大多结构化的图像数据进行翻译,但是对于非结构化的图像数据容易造成结构上细节的缺失,本发明通过添加一种拉普拉斯金字塔的结构损失,有效的解决了这种在结构上细节缺失的问题。
技术实现要素:
本发明的目的在于,提供一种人体交互动作的体验者动作生成方法及装置,在体验者交互设计上,使得体验者体验不同虚拟动作的乐趣。
为了达到本发明目的,本发明提供的一种基于人体交互动作的体验者动作生成方法,其特征在于:包括以下步骤:
步骤1、收集体验者的动作图像,对图片进行预处理,构成只有体验者单人的真实动作图像数据集;
步骤2、使用openpose算法,提取真实动作图像中的人体动作,所述方法在于:
将体验者的真实动作数据集中的每张真实动作图像经过openpose算法处理提取出人体动作图像,将预处理后的真实动作图像与提取出的人体动作图像相配对得到若干图像对,并对所述图像对划分,得到训练集和验证集;
步骤3、构建由人体动作图像生成体验者真实动作图像的模型,该模型包括生成器g和判别器d;生成器g用来模拟真实的数据分布,使得生成图像
判别器d用来判断输入图像的来源;当输入的信息是真实图像时,判别器判断出图像来源于真实图像的数据分布,判别器d输出结果为1;输入的信息为生成图像时,判别器判断数据来源于生成图像的数据分布,判别器d输出结果为0;
使用训练集对生成器g和判别器d进行训练,训练的损失函数为l=lpix+lvgg+llap+lgan,lpix为生成图像
其中,
e(s,x,l)[logd(x,s,l)]是函数logd(x,s,l)的期望;
步骤4、使用验证集对训练完成后的生成器g进行验证;
步骤5、收集多个风格的具有标准舞蹈动作舞蹈视频,对舞蹈视频的每一帧图像经过openpose算法处理,得到若干人体舞蹈动作图像,将人体舞蹈动作图像和人为设定的风格标签作为生成器g的输入,由生成器g输出体验者的生成图像并转换为体验者的舞蹈视频。
本发明使用一种条件形式的生成式对抗网络来满足舞蹈动作的生成任务,用下述最大最小目标函数抗式地训练生成器g和判别器d;在训练时,为了使图片信息看起来主观效果看起来更加的自然,加上经过预训练过的vgg特征损失lvgg。该vgg特征损失使得生成的图像跟目标图像相比于pixel级别的损失函数在语义上更加的相似。由于添加了条件风格信息,在训练过程中人物动作会产生些许的形变,为了使图像在形状上更加的契合,在生成过程中,使用基于拉普拉斯金字塔损失函数使得图像更加平滑。最终得到的生成器能够较好的对体验者动作进行模拟。
假设这样的一种场景:某人想要跳某个舞蹈,但他自己并不会跳舞,或者没有大量的时间去学习某个舞蹈,将我们的算法模型跟vr眼镜结合,体验者可以在vr眼镜中虚拟的体验自己跳舞的样子。使用本发明方法,通过人体动作合成真实场景下的体验者舞蹈动作,能够辅助展演的效果以及使得体验者体会到不同动作的乐趣。
附图说明
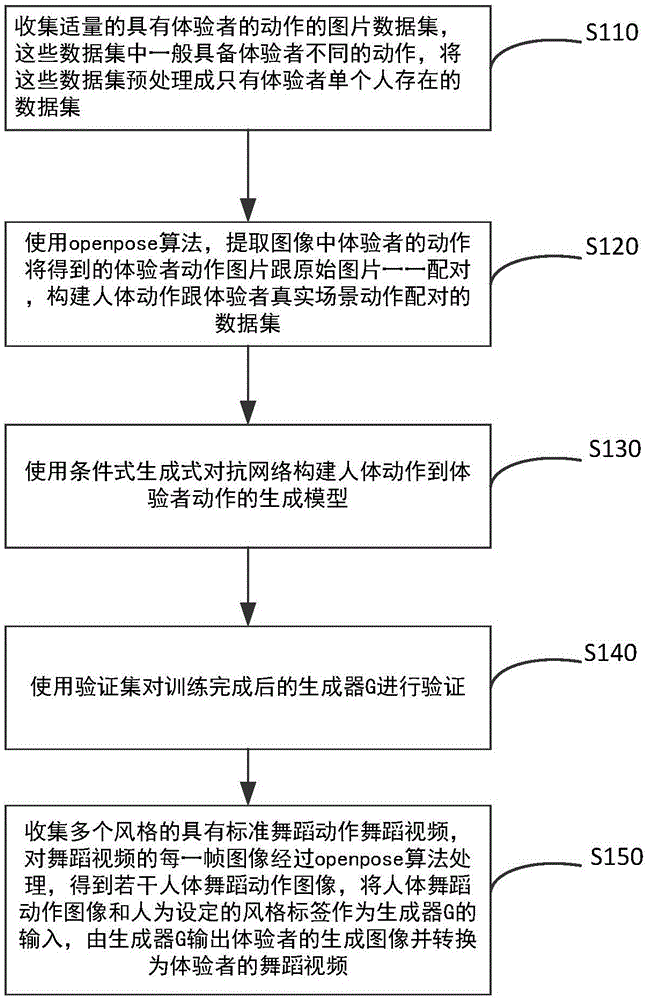
图1为本发明实施例提供的基于人体交互动作的体验者动作生成的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
如图1所示,为本发明实施例提供的基于人体交互动作的体验者动作生成方法流程图,该方法原理为:使用条件式生成式对抗网络构建图像序列到图像序列的转换任务,为了使任务更加适合舞蹈动作处理,在原有的图像翻译结构上添加了基于拉普拉斯金字塔的结构损失函数,另外,通过添加额外的信息,能够让体验者体验到多种风格的自己,使得体验者能够交互的享受到舞蹈的乐趣。
本实施例基于人体交互动作的体验者动作生成方法,包括以下步骤:
s110、收集适量的具有体验者的动作图像,这些动作图像中一般具备体验者不同的动作,将这些动作图像预处理成只有体验者单个人存在的图像,构成真实动作图像数据集。
s120、将体验者的真实动作数据集中的每张真实动作图像经过openpose算法处理提取出人体动作图像,将预处理后的真实动作图像与提取出的人体动作图像相配对得到若干图像对,并对所述图像对划分,得到训练集和验证集。
s130、使用条件式生成式对抗网络构建人体动作到体验者动作的生成模型,该模型由生成器g以及判别器d组成。使用训练集对生成器g和判别器d进行训练,训练的损失函数为l=lpix+lvgg+llap+lgan,lpix为生成图像
s140、使用验证集对训练完成后的生成器g进行验证。将验证集中的人体动作图像和风格标签作为生成器g的输入,生成器输出的生成图像与对应的真实动作图像进行比对,验证生成器g的模拟性能。一般可采用肉眼识别验证相似度,也可用结构相似性或者峰值信噪比来判断两幅图像的相似度以进行验证。
s150、收集多个风格的具有标准舞蹈动作舞蹈视频,提取舞蹈视频中的人体动作,将提取到的人体动作和设定的风格标签作为作为生成器g的输入,由生成器g输出体验者的生成图像并转换为体验者的舞蹈视频。
步骤s130中,构建人体动作与体验者真实动作生成的模型,该模型由一个生成器以及一个判别器组成,生成器为g,判别器为d;
a1:令x为一体验者真实动作图像,s为其相对应通过openpose算法提取的人体动作图像,建立一个通过人体动作图像s到体验者真实动作图像x的模型,用数学符号可以表示如下,
其中,s指通过openpose算法处理后的人体动作图像,x指未经处理过的体验者原始真实动作图像,
a2:将真实动作图像数据集x人体动作图像数据集s中的图像进行配对,
在实验中,体验者希望能够体验到自己有不同穿着或者不同风格时的舞蹈,因此,数据集中另外加上条件风格信息的标签l,条件风格信息使用one-hot进行编码,例如:(1,0,0,0,0…0)代表具有某种风格特征的舞蹈信息。因此,在a2步的数学表述如下,
其中l指在生成器中输入额外的风格信息,以模拟不同风格动作图像的生成。
a3:使用一种条件形式的生成式对抗网络来满足舞蹈动作的生成任务,令g为人体与真实场景下图像生成的生成器,d为条件式图像判别器,用下述目标函数对抗式地训练生成器g和判别器d:
上述最大最小目标函数为基本的生成式对抗网络的训练模式,生成器用来模拟真实的数据分布,判别器用来判断输入数据的来源。
判别器d最大可能的来判断输入的图像数据来自于真实数据或者生成数据。当输入的信息是(x,s,l)时,判别器应该判断数据来源于真实的数据分布,输入的信息为
生成式对抗网络自2014年提出,在无监督的图像生成,文本生成,强化学习等领域均有突破性的应用。生成式对抗网络一共包括两个部分,一个生成器g以及一个判别器d。通过输入一些随机噪声到生成器中,生成器生成一个假的样本。与此同时,判别器同时输入一些真实的样本以及生成的样本并尽可能的去辨别它们,通过对抗式的训练,最终生成器能够模拟随机变量z到x的生成分布。生成器g以及判别器d的最小最大博弈目标可以用下列数学符号表示:
原始的生成式对抗网络的优化函数在应用时很容易遇到模式坍塌,梯度消失等问题。研究者分析原始gan在训练过程中生成分布跟原始分布跟真实分布在大部分并不重合,并提出了wgan。wgan使用wassersteindistance有效的保持网络在训练时的梯度,为了限制梯度变化速度,wgan要求判别器d符合1-lipschitz条件,wgan-gp使用一个梯度罚项替代wgan的权重剪枝操作,减少了调参操作以及网络的鲁棒性,wgan-gp用数学符号可以表示:
其中d∈lp指判别器d符合1-lipschitz条件,第二项为wgan-gp优化损失的梯度罚项。
具体的,生成器的结构是一种广泛应用于图像翻译问题的一种架构。生成器包含两个步长为2的卷积层,8个残差网络模块(resblocks)以及2个步长为1/2的解卷积层。每个resblock包含卷积层,instancenorm层以及relu层,为了防止过拟合,在每一个resblock的第一个卷积层后,dropout的概率值取0.5。
在训练生成器g的同时,同时对抗式的训练一个判别器d,如图所示,判别器d全部由卷积层构成,跟pix2pix类似,使用一种马尔可夫随机场形式的patchgan结构,所有的非线性激活层使用leakyrelu(alpha=0.2),使用wgan-gp进行训练。
在训练时,为了使图片信息看起来主观效果看起来更加的自然,加上经过预训练过的vgg特征损失,该vgg特征损失使得生成的图像跟目标图像相比于pixel级别的损失函数在语义上更加的相似,vgg特征损失定义如下:
其中,φ为预训练的vgg网络,vgg网络一个用于图像分类的网络模型,在2014年imagenet数据分类比赛中,获得第二名,由于深度卷积神经网络能够有效的提取图像在高层的特征信息,因此经常被用来将图像像素信息投射到高层中,计算其中的损失,跟很多模型相同使用l2计算高层特征损失的大小。
由于添加了条件风格信息,在训练过程中人物动作会产生些许的形变,为了使图像在形状上更加的契合,在生成过程中,使用基于拉普拉斯金字塔损失函数使得图像更加平滑。
其中lj指的是图像下采样的第j个拉普拉斯金字塔,通过计算原始图像以及生成图像的拉普拉斯金字塔特征,使用l1计算图像的拉普拉斯金字塔特征损失。
最终,训练模型的损失函数可以用下面的数学形式表示:
l=lpix+lvgg+llap+lgan
其中lpix为生成图像
实施例二
实施例一中主要阐述了网络的架构以及优化的目标,在具体实施的细节中,为了使得能够生成多种风格的体验者交互动作,本实施例二在模型中增加分类器c(例如:残差网络或者vgg网络),并继续优化上述的损失函数。分类器c能够对目标图像进行风格分类,确定目标图像属于哪一种风格,具体的优化目标为:
其中,lc为生成图像
最终优化得到的损失函数为
l=lpix+lvgg+llap+lgan+lc
使用训练集对生成器g、判别器d和分类器c进行训练。
在某些场景下,需要更高分辨率的图像,为了合成更加高分辨率的图像,在原始的生成器架构上,在低分辨率的预训练模型下,可以使用低分辨率得到的结果作为高分辨率图片生成的条件,另外添加额外的相同架构的判别器继续训练,根据此种原理,能够精细的生成1024*512,2048*1024,4096*2048等规格分辨率的图像。
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!