面向自然资源矢量地表覆盖变化统计处理方法与流程
本发明涉及国土资源统计领域,具体的,涉及一种面向自然资源矢量地表覆盖变化统计处理方法,能够以同一行政区划为单位对某地的历史土地资源进行统计分析,从而便于利用多核计算资源进行并行处理计算。
背景技术:
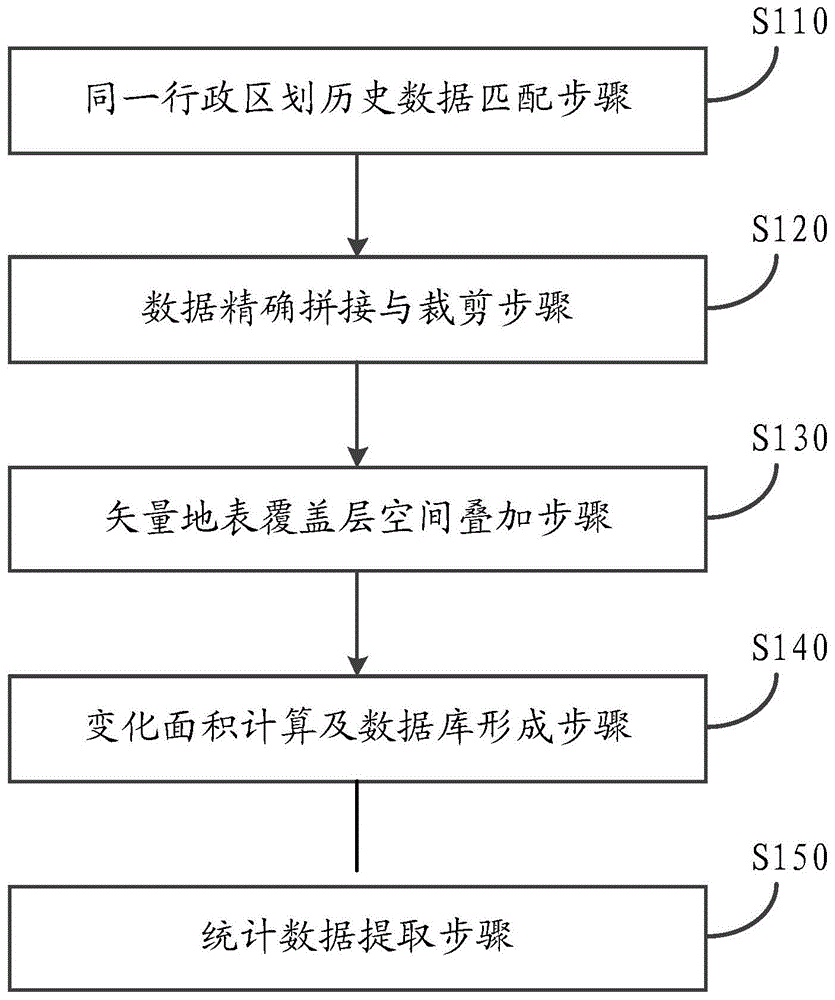
:地表覆盖是指地球表面各种物质类型及其自然属性与特征的综合体,其现状和变化是环境变化研究、地球系统模式模拟、地理国情监测和可持续发展规划等方面不可或缺的重要科学数据和关键参量。既有成果多采用遥感影像的形式进行存储和表达。近年来,随着高分辨率、短周期数据获取手段的进步和各类地表要素高精度提取方法的自动化、智能化发展,矢量形式存储的地表覆盖数据逐渐为一种可面向基础应用和生产服务的海量高精细数据产品。地表覆盖变化的研究和应用属于土地利用/土地覆盖变化(land-useandland-coverchange,lucc)研究。随着第一次全国地理国情普查的成功实施和常态化监测生产工作在全国的正式铺开,每年数以亿计的反映地表覆盖现状和变化的矢量图斑快速累积,成为变化统计的主要数据源之一。目前,研究的侧重点在于地表变化驱动力因素分析、高精确变化检测方法设计和地表变化预测三个方面研究。根据中国知网最新搜索显示,仅有少量研究将高性能计算方法应用于高精度影像自动解译、大规模矢量地表覆盖数据的快速检索和分类统计计算、基于元胞自动机的地理模拟和预测等方面的研究和应用。利用高性能计算手段解决大规模矢量地表覆盖变化统计的作业需求,涉及了数据界限匹配、地表覆盖拼接和裁切、数据分层叠加、变化面积计算和矩阵输出五个核心环节。其中,数据拼接和裁切、数据分层叠加、变化面积统计三个环节最高耗时,平均占到全部统计时间的98%以上。目前,主流的应用软件提供了较为基础的矢量图斑叠置分析和面积计算方法,但都采用串行模式进行运行,对小规模矢量数据支持较好,无法实现大规模数据的高效并行处理。通过分析主流商业软件和最新科研论文,认为大规模矢量地表覆盖变化统计主要存在以下方面问题:(1)缺乏针对矢量地表进行变化统计的业务化技术流程在自然资源和环境监测工作普遍受到重视的背景下,变化统计已成为信息获取的有效手段,既有的方法和软件尚不能对整个作业过程和技术细节提供专业指导。最新的研究论文提供了基于遥感影像的变化检测方法,但可操作性较差,且不能适用于大规模矢量数据。主流的商业和开源软件仅提供了基础的空间分析操作工具,但不能对复杂流程进行有效建模。(2)无法有效衔接现有分析方法与高性能计算设施以提高处理效率主流的计算机普遍提供了多核计算能力,总体性能远超过传统单核处理器性能。现有的方法或软件多侧重于算法精度的提升,没有按照并行思想进行设计。如果对既有的方法或算法完全重构开发,工作代价过高,不利于变化统计分析的快速开展。因此,如何面对计算机处理能力的增长,以同一行政区划为单位对某地的历史土地资源进行统计分析,从而便于利用多核计算资源进行并行处理计算,以提高数据处理的效率和能力,进一步的,分析提取不同类型的土地类型变化情况,成为现有技术亟需解决的技术问题。技术实现要素:本发明的目的在于提出一种面向自然资源矢量地表覆盖变化统计处理方法,能够实现多个历史事件的矢量自然地表覆盖数据的自动化匹配预处理、叠置分析、统计计算和地表转移矩阵输出,为有效支撑自然资源调查监测和变化统计分析,并实现并行计算,提高分析计算效率提供技术支撑。为达此目的,本发明采用以下技术方案:一种面向自然资源矢量地表覆盖变化统计处理方法,包括如下步骤:同一行政区划历史数据粗分匹配步骤s110:以某行政区划最新一年的生产界限为基础,考虑同一行政区划在不同历史时期可能发生的地理范围的变化,对不同历史时期的矢量地表覆盖数据进行粗分匹配,得到某行政区划在不同历史时期所包含的地理位置的匹配关系文件;数据精确拼接与裁剪步骤s120:利用步骤s110中的匹配关系文件,获取不同历史时期的矢量地表覆盖数据,以本年度地区覆盖数据为准对历史的,例如上一年度的,地理覆盖数据进行拼接,然后进行裁切,使得本年度地表覆盖数据与上一年地表覆盖数据空间范围上完全一致,并形成不同的历史时期的矢量地表覆盖层;矢量地表覆盖层空间叠加步骤s130:将步骤s120中形成的不同的历史时期的矢量地表覆盖层进行空间叠加,形成新的融合层,该层中所有图斑均包含了不同历史时期地表覆盖数据的地类分类代码,所述地类分类编码表示土地的属性;变化面积计算及数据库形成步骤s140:基于大地坐标系,利用地类分配编码计算叠加的融合层中各矢量图斑的面积,形成图斑面积数据库;统计数据提取步骤s150:根据步骤s140中的图斑面积数据库,以行政区划代码和地类分配编码中的组合的方式进行查询,以实现不同行政区划的分级、地类分级和分类面积汇总和提取。可选的,在步骤s110中,多期的分区界限数据基础上,通过擦除、追加、求交的基础空间分析操作的组合,完成匹配关系文件的构建,实现了统一空间范围约束条件下的一对多数据匹配关系构建。可选的,在步骤s110中,所述匹配关系文件以行政区划代码为索引。可选的,在步骤s140中,图斑面积数据库包括不同类别的地类分配编码不变的部分,变化的部分,以及变化后的类型。可选的,所述不同历史时期为本年度和前一年,一共两年。可选的,本统计处理方法能够以行政区划为单位,对多个行政区域同时进行处理,各行政区域的处理步骤并行运行。本发明进一步公开了一种存储介质,用于存储计算机可执行指令,其特征在于:所述计算机可执行指令在被处理器执行时执行上述的面向自然资源矢量地表覆盖变化统计的处理方法。本发明以行政区划为统计单位进行统计分析,降低了每个数据处理任务的体量,可以利用现有计算机的并行的处理资源,将大量的面向自然资源矢量地表覆盖的历史数据同时进行处理,提高了处理速度和处理效率,并且能够以行政区划代码和地类分配编码中的组合的方式进行查询,以实现不同行政区划的分级、地类分级和分类面积汇总和提取。附图说明图1是根据本发明具体实施例的面向自然资源矢量地表覆盖变化统计处理方法的流程图;图2是根据本发明具体实施例的地表覆盖转入量、转出量、净变化量和现状信息统计示意图;图3是根据本发明具体实施例的地表覆盖转移矩阵一级类报表输出格式说明;图4是根据本发明具体实施例的多个行政区划数据并行处理的多任务进程并行调度说明。具体实施方式下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。本发明所针对的对象是某个行政区域不同的自然资源地表覆盖的变化情况,例如某县的林地、水域、田园等在不同年份的增加或者减少的问题。本发明的思路在于以行政区划为统计单位,将多个不同历史时期的数据进行匹配、精确拼接与裁剪,在地表覆盖层空间叠加后进行不同地类分类编码的统计分析,最终根据需要选取不同类型的统计数据报表输出。由于以行政区划为统计单位进行统计分析,降低了每个数据处理任务的体量,可以利用现有计算机的并行的处理资源,将大量的面向自然资源矢量地表覆盖的历史数据同时进行处理,提高了处理速度和处理效率,并且能够以行政区划代码和地类分配编码中的组合的方式进行查询,以实现不同行政区划的分级、地类分级和分类面积汇总和提取。具体的,参见图1,示出了本发明具体实施例的面向自然资源矢量地表覆盖变化统计处理方法的流程图,包括如下步骤:同一行政区划历史数据粗分匹配步骤s110:以某行政区划最新一年的生产界限为基础,考虑同一行政区划在不同历史时期可能发生的地理范围的变化,对不同历史时期的矢量地表覆盖数据进行粗分匹配,得到某行政区划在不同历史时期所包含的地理位置的匹配关系文件。该步骤在于,同一行政区划,例如某县,在不同的年份,可能会发生地理范围的变化,例如某乡村或者某块土地被划分出去,或者划归进来。因此为了统计某县的地表覆盖数据的历史变化,本步骤,以某县为索引,考虑到不同年份可能包含的区域进行粗分统计。在具体的实施例中,所述匹配关系文件以行政区划代码为索引。例如,参见表1,a县,行政区划代码为**0015,在过去一年所下辖的地理范围割让出去某块位置给b县,其所管理的行政区划完全落入上一年的a县范围内,因此,上一年度行政区划代码仍然是**0015。b县,行政区划代码为**0016,在过去一年,得到了原来a县**0015的部分地理范围,得到了c县**0107的部分地理范围,因此,上一年度行政区划代码包括了a县、b县和c县三部分。表1行政区划匹配关系表序号本年度行政区划代码上一年度行政区划代码1**0105**01052**0106**0105,**0106,**0107………在这一步骤中仅仅只是初步的关系匹配,只需要知道和其它的哪些行政区划的匹配关系即可,无需进行细致的划分。在具体的操作中,可以利用对上一年度的界限进行擦除操作(erase),得到本年度相对于上一年度的扩充范围部分,然后将该扩充部分追加(append)到上一年度数据界限中,利用两期界限进行空间求交操作查找(intersect),使得本年度地域范围能够涵盖上一年度的所有的地理范围,即考虑到上一年度到本年度可能发生的地理区划变更的情况。即该步骤在两期或者多期的分区界限数据基础上,通过擦除、追加、求交等基础空间分析操作的组合,完成匹配关系文件的构建,实现了统一空间范围约束条件下的一对多数据匹配关系构建。实现的方式可以将该匹配关系表存储为基本配置文件,用于指导后续的矢量地表覆盖分层的拼接与裁切。为便于流程化操作,可采用python脚本对既有的软件功能模块进行封装和调用,例如可依次调用arcgis软件中的erase、append和intersect操作形成新层,并进而将属性表存储为可直接读取的txt文件。数据精确拼接与裁剪步骤s120:利用步骤s110中的匹配关系文件,获取不同历史时期的矢量地表覆盖数据,以本年度地区覆盖数据为准对历史的,例如上一年度的,地理覆盖数据进行拼接,然后进行裁切,使得本年度地表覆盖数据与上一年地表覆盖数据空间范围上完全一致,并形成不同的历史时期的矢量地表覆盖层。这样,就从地理位置上实现了本年度相对于之前年度的地理位置的精确覆盖数据。在具体的实施例方式中,能够根据本年度行政区划代码依次创建对应的gdb格式文件(文件名与行政区划代码名称相同),并将本年度的矢量地表覆盖数据通过arcgis的“featureclasstofeatureclass”拷贝至新创建的gdb中,形成本年度图层;然后根据匹配关系配置文件与各gdb对应的一年度的一个或多个矢量地表覆盖数据层进行拼接(merge),并按照新界限进行裁切(clip),形成上一年度图层。本步骤中,涉及的各类操作均通过python脚本进行调用,形成一个独立的可执行文件。矢量地表覆盖层空间叠加步骤s130:将步骤s120中形成的不同的历史时期的矢量地表覆盖层进行空间叠加(intersect),形成新的融合层,该层中所有图斑均包含了不同历史时期,即不同年度,例如本年度和上一年度两期,地表覆盖数据的地类分类代码,所述地类分类编码表示土地的属性,例如。0100表示耕地,0200表示园地,0300表示林地等等。在一个可选的例子中,该步骤中叠加操作可基于python脚本调用arcgis中的intersect操作,并形成独立的可执行文件。变化面积计算及数据库形成步骤s140:基于例如cgcs2000的大地坐标系,利用地类分配编码计算叠加的融合层中各矢量图斑的面积,形成图斑面积数据库。在一个可选的实施例中,图斑面积数据库包括各地块的行政区划代码、变化前后的地类分类编码、地块面积。具体而言,可采用arcgis软件的地图投影变化的方法,将该层进行albers等面积投影,从而获得各图斑的面积。或根据《地理国情普查基本统计技术规定》,按照其中关于椭球面积算法的详细描述,实现按照经纬度直接计算以获得图斑面积。完成计算后,将图斑的面积按照【pac,cc_old,cc_new,area】四元组的方式统一注入到sql数据库中。以上过程同样可基于python脚本语言完成,并形成独立可执行文件。注:pac为六位行政区划代码;cc_old,cc_new分别为上一年度和本年度的地类代码;area为图斑的面积值。参见图2,示出了在两年的时间内,某行政区域的地表覆盖转入量、转出量、净变化量和年度信息。统计数据提取步骤s150:根据步骤s140中的图斑面积数据库,以行政区划代码和地类分配编码中的组合的方式进行查询,以实现不同行政区划的分级、地类分级和分类面积汇总和提取。如图3所示,示出了本发明具体实施例的地表覆盖转移矩阵一级类报表输出格式说明。示例性的,各类的查询条件可以通过sql语言中sum、groupby等基本操作完成上述声明条件,可通过组合(1)、(2)与(3)、(4)、(5)中的要求完成相应的变化统计需求:(1)要求pac前两位相同为同一省统计单元;(2)要求pac前四位相同为同一地市统计单元;(3)要求cc_old或cc_new等于某地类可直接得到上一年度或本年度的该地类的面积;(4)要求cc_old和cc_new相同可分别得到两年各级地类的不变量;(5)要求cc_old为和cc_new不同可同时得到cc_old地类的转出量和cc_new地类的转入量。进一步的,本发明的统计处理方法能够以行政区划为单位,对多个行政区域同时进行处理,例如对多个县的数据同时进行处理,各行政区域的处理步骤并行执行。例如,参见图4,示出了根据本发明具体实施例的多个行政区划数据并行处理的多任务进程并行调度说明。按照县的行政区划为单位,对数据进行的大规模并行处理提供了可能。相比于以往的串行处理,本发明能够同时处理多个县,将高耗时的数据拼接和裁切、数据叠加、面积计算三个环节进行独立封装,形成可执行文件,从而实现并行处理。例如通过python进程池进行异步调度,可实现大规模独立计算任务的并行分发,极大缩减复杂大数据作业任务的统计时间,提高了工作效率。本发明进一步公开了一种存储介质,用于存储计算机可执行指令,其特征在于:所述计算机可执行指令在被处理器执行时执行上项所述的面向自然资源矢量地表覆盖变化统计的处理方法。综上,本发明具有如下的优点:(1)在两期分区界限数据基础上,通过擦除、追加、求交等基础空间分析操作的组合,完成两期匹配关系表的构建,实现了统一空间范围约束条件下的一对多数据匹配关系构建。(2)按诸如县的行政区划为单位,为数据的大规模并行处理提供了可能。相比于以往的串行处理,本发明能够同时处理多个县,或者多个行政区,这样,将高耗时的数据拼接和裁切、数据叠加、面积计算三个环节进行独立封装,形成可执行文件,从而实现并行操作。例如通过python进程池进行异步调度,实现了大规模独立计算任务的高效并行处理,极大缩减了复杂大数据作业任务的统计时间,提高了工作效率。(3)多维变化信息提取基于数据叠加和计算形成的变化地类面积列表,通过行政区划代码和地类代码的组合条件,可实现地类转入量、转出量、净变量和两期地表现状信息的准确提取,为整个变化统计输出直观、可追踪的地类流转成果。显然,本领域技术人员应该明白,上述的本发明的各单元或各步骤可以用通用的计算装置来实现,它们可以集中在单个计算装置上,可选地,他们可以用计算机装置可执行的程序代码来实现,从而可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件的结合。以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施方式仅限于此,对于本发明所属
技术领域:
的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单的推演或替换,都应当视为属于本发明由所提交的权利要求书确定保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1