一种基于特征提取的调解案件智能分派方法及系统与流程
本发明涉及司法领域的自然语言处理领域,尤其涉及一种基于特征提取的调解案件智能分派方法及系统。
背景技术:
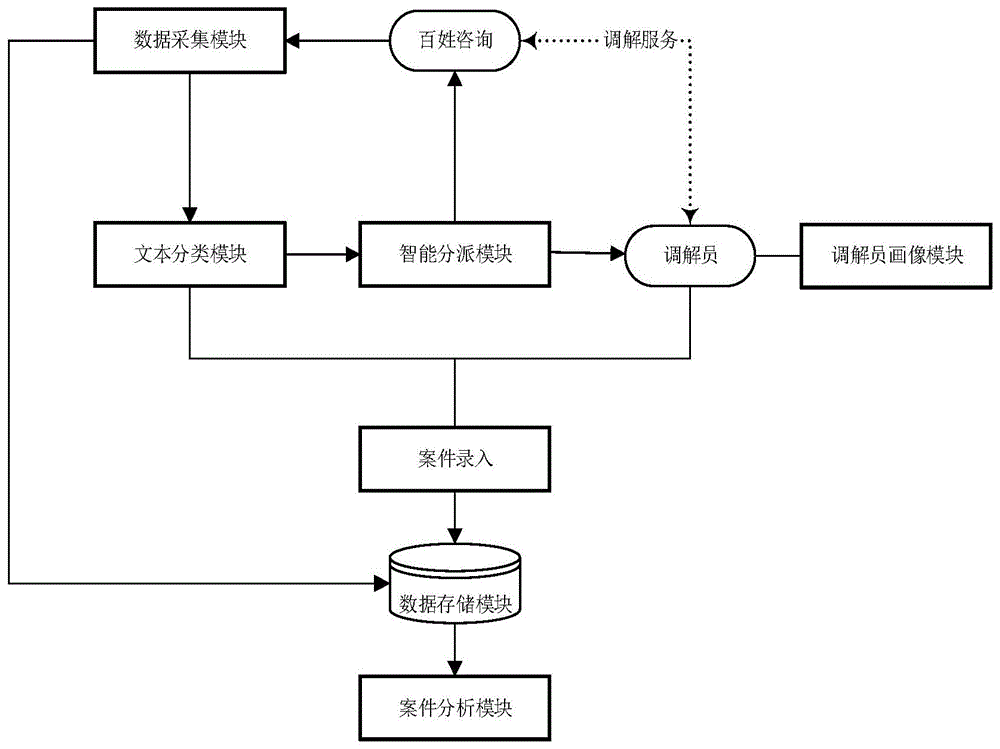
:目前,我国有近77万个人民调解组织、367万人民调解员,每年调解纠纷900多万件,案件类型可细分达到80多类,案件数量的增多和案件种类的繁多,使人民调解工作的压力和困难不断增大,怎样更好的进行调解服务,提高调解服务满意度,是目前人民调解工作面临的严峻问题。12348法律服务网提供了人民调解服务,但该服务有以下不足:1、服务方式单一,只提供调解机构查询服务;2、服务模式被动,调解员不能主动联系矛盾纠纷当事人,主动化解矛盾纠纷;3、难以管理调解资源,目前调解案件类型达到80多类,矛盾纠纷当事人难以判断纠纷所属类型,不能有效的申请调解资源。除了12348网站,110也会分派调解案件,随着移动互联网技术的发展,也促使移动端产生大量的案件申请。以上案件来源法律服务所产生的矛盾纠纷数据主要为短文本数据,文本挖掘技术可以帮助人们快速从海量数据中获取关键信息。文本分类和推荐系统在新闻、电商、社交等领域已广泛应用,并发挥重要作用,但在司法领域中该技术的应用仍属空白。短文本具有语法随意、结构松散、语义稀疏、停用词占比大等特点,以往适用于长文本的方法不再适用。人民调解属于司法领域,调解员具有自己所专长的案件类型,短文本数据专业性强,分类类别达80多类,分类粒度细,文本特征提取困难,上述分类和推荐方法的精度和实时性达不到业务要求。综上所述,有必要使用新的技术方法手段,来弥补以上不足,促使调解服务升级,提高调解效率,提升调解满意度。技术实现要素:本发明为克服上述的不足之处,目的在于提供一种基于特征提取的调解案件智能分派方法及系统,根据特征词的相似性进行案件分派,时效性好,准确度高,从而提高人民调解效率和服务质量。本发明是通过以下技术方案达到上述目的:一种基于特征提取的调解案件智能分派系统,包括:数据采集模块、文本分类模块、智能分派模块、调解员画像模块、案件录入模块、案例分析模块、数据存储模块;其中,数据采集模块用于采集用户和调解员相关信息,以及相关咨询和调解数据,对资源进行整合、清理、存储;其中清理包括去除无效数据,空值,异常值;文本分类模块用于使用训练好的分类模型对案件类型进行分类;智能分派模块用于根据案件智能分派方法,对案件进行分派;调解员画像模块用于对调解员业务能力及服务水平进行分析画像,清晰了解调解员群体现状,调解资源情况,提供资源调配依据;案件录入模块用于记录案件过程中的重要信息,使用训练好的分类模型对案件类型进行辅助分类;案例分析模块用于对案件进行分析评估,掌握当前的调解服务状态;数据存储模块用于存储各类数据,包括调解案件库、调解员调解案件特征库、标签文本库、各案件类型的调解员调解案件集等数据。作为优选,所述采用案件智能分派方法进行分派时,把案例信息及咨询人员信息分派给调解员;把案例分类、调解员信息和调解地址信息推送给咨询人员,其中,使用多途径进行信息推送,推送方式包括webservice、html5、rest、wap,可根据具体需求进行多种方式的推送服务。作为优选,所述调解员画像模块包括基础信息、业务状态、个人能力、服务评级子模块;基础信息包括调解员年龄、性别、执业年限、联系方式信息;业务状态指调解员当前调解状态,判断调解资源利用情况;个人能力指调解员的工作能力,调解业绩情况信息;服务评级指对调解员的服务评价和业务能力的综合评级。作为优选,所述案件分析模块包括时间序列、人员画像、风险预警、工作质量、效率评估子模块;其中时间序列指案件历史变化趋势;人员画像指对咨询人员属性描述,包括年龄、性别、籍贯、历史记录信息;风险预警指对重大案件、群体案件、涉老涉幼等重点关注,社会影响广泛案件进行预警提示;工作质量指对结案案件结果、满意度、评价进行综合考量;效率评估指对调解案件从介入到结案整个服务过程的效率情况。一种基于特征提取的调解案件智能分派方法,包括如下步骤:(1)采集调解案件数据,进行数据预处理后存入调解案件库;(2)对调解案件文本进行分类处理,获得各案件类型的调解员调解案件集;(3)对调解案件文本提取特征词,获得调解员调解案件特征库;(4)对待分派调解案件文本进行分类与分词处理,确定分类结果,提取该案件特征词;(5)比对待分派调解案件和同案件类型下各调解员调解案件的特征词相似度,结合各调解员当前工作量和服务评级,对调解员进行排序,分派调解案件。作为优选,分类方法包括:将调解案件文本分词,获得词汇文本;对词汇文本进行向量化和归一化处理;对处理后的数据进行聚类,并根据专家经验分类添加标签,存入标签文本库;采用机器学习算法训练、优化分类模型,进而用于调解案件文本分类。作为优选,所述进行聚类时采用dbscan算法进行聚类,具体步骤如下:(a)初始化选取邻域参数(∈,minpts),∈为聚类半径,minpts为最低样本数;(b)计算距离,其中距离计算方式:欧式距离,点a(x11,x12,...,x1n)与b(x21,x22,...,x2n)间的欧式距离为(c)通过距离度量方式找到样本xj的∈-邻域样本集n∈(xj),若样本集个数满足|n∈(xj)|≥minpts,将xj加入核心对象样本集合ωk;(d)如果样本集合ωk为空集,则结束流程;否则执行步骤(e);(e)在ωk中,随机选择核心对象o,执行步骤(b)直到算法结束生成聚类簇ck;(f)优化邻域参数组合,重复步骤(b),达到最佳聚类结果。作为优选,所述获得调解员调解案件特征库的方法包括:将调解案件文本分词,提取特征词,获得一级特征库;对特征词进行合并或扩展,获得二级特征库。作为优选,所述获得一级特征库的具体方法如下:统计常规词的组合词频,将组合词频满足设定阈值i的常规词组合作为新词汇加入词汇表;定义窗口长度l,采用窗口遍历的方法统计任意m个词汇组合出现的次数,将出现次数最高的k个组合中的词汇作为特征词,统计所述特征词中单个词汇的词频,将词频满足设定阈值ii的词汇作为候选特征词,加入一级特征库。作为优选,所述获取二级特征库的具体方法如下:计算特征词的相似度;当两个特征词的相似度满足设定阈值iii或两个特征词的相似度在一级特征库的特征词相似度值前n位时,则将两个特征词合并,保留其中一个特征词,将另一个特征词从一级特征库中去除;当两个特征词的相似度满足设定阈值iv时,从扩展词典中抽取对应的扩展词汇,对特征词进行扩展,将扩展特征词加入一级特征库,获得二级特征库。作为优选,所述特征词的相似度计算方法包括:(i)设置基于字符的特征词相似度权重p和基于语义的特征词相似度权重q;(ii)获取特征词f1、f2基于字符的特征词相似度sim(f1,f2),其中,sim(f1,f2)=特征词f1和特征词f2中字符相同的数量/特征词f1和特征词f2的字符长度较大值;(iii)获取特征词f1、f2基于语义的特征词相似度score(f1,f2),其中,score(f1,f2)为特征词f1和特征词f2的相关性值,相关性值从案件库文本语言训练后的语义模型中获取;(iv)计算特征词的相似度=p*sim(f1,f2)+q*score(f1,f2)。作为优选,获得调解员调解案件特征库的方法还包括:从调解案件库中抽取n条调解案件数据,按照步骤(4)、(5)进行分派,根据案件分派准确度,更新参数获得三级特征库,具体如下:若分派准确度满足预设的阈值时,则将当前的二级特征库确定为最终的三级特征库,并加入调解员特征库;否则更新参数阈值直到分派准确率满足预设的阈值;其中分派准确度计算方法为:准确率=分派准确的案件数/总的案件数。作为优选,所述待分派调解案件和同案件类型下各调解员调解案件的特征词相似度比对的方法包括:将特征词向量化,采用余弦相似度计算特征词相似度si。作为优选,所述调解员排序的方法包括:调解员当前在调解案件数大于阈值γ时,则将调解员剔除;计算分派排序分值v,v=a*si+b*st,其中st为调解员服务评级,对调解员降序排序。作为优选,所述分词方法包括:根据调解案件数据将无法正确切分的词加入专业调解词典,将无意义、区分度不高的词、标点符号加入停用词典,将专业调解词典加入分词工具词典,采用分词工具对文本进行分词,分此后使用停用词典过滤。本发明的有益效果在于:(1)分派准确率高:采用多层级特征提取,多规则人案匹配,有效提高了案件分派准确率,分派准确率达到95.6%;(2)提升调解满意度:文本自动分类,免除案件类型划分的麻烦,减轻当事人咨询负担。快速无感进行问题解决的引导,提升了调解过程的服务体验;(3)提高调解效率和服务质量:案件智能派送,并且进行信息互推送,使调解沟通更加顺畅,改变了调解员被动工作状态,转被动为主动;(4)纠纷排查:通过智能派送系统,了解案件详情,对案件进行分流,使调解资源合理利用。案例分析模块,实时监控掌握纠纷人员画像和纠纷案件状态,对矛盾纠纷进行排查;(5)优化调解资源:问题的准确分类和精确推送,调解人员画像,保证了专业调节资源有效利用,不被一般问题所占用,合理优化有限的调解资源;(6)提升工作效率:调解过程中,案件录入工作可以实现自动分类处理,调解员只需确认即可,避免细分类别给调解员带来的困扰,提高了案件录入效率和准确率。附图说明图1是本发明整体系统的组成框架示意图;图2是本发明智能派送方法的流程示意图;图3是本发明数据采集模块的工作流程示意图;图4是本发明文本分类的流程示意图;图5是本发明文本分类模型训练及优化的的流程示意图。具体实施方式下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:实施例:如图1所示,一种基于特征提取的调解案件智能分派系统,包括:数据采集模块、文本分类模块、智能分派模块、调解员画像模块、案件录入模块、案例分析模块、数据存储模块;其中,数据采集模块用于采集用户和调解员相关信息,以及相关咨询和调解数据,对资源进行整合、清理、存储;其中清理包括去除无效数据,空值,异常值;文本分类模块用于使用训练好的分类模型对案件类型进行分类;智能分派模块用于根据案件智能分派方法,对案件进行分派;调解员画像模块用于对调解员业务能力及服务水平进行分析画像,清晰了解调解员群体现状,调解资源情况,提供资源调配依据;案件录入模块用于记录案件过程中的重要信息,使用训练好的分类模型对案件类型进行辅助分类;案例分析模块用于对案件进行分析评估,掌握当前的调解服务状态;数据存储模块用于存储各类数据,包括调解案件库、调解员调解案件特征库、标签文本库、各案件类型的调解员调解案件集。所述采用案件智能分派方法进行分派时,把案例信息及咨询人员信息分派给调解员;把案例分类、调解员信息和调解地址信息推送给咨询人员,其中,使用多途径进行信息推送,推送方式包括webservice、html5、rest、wap,可根据具体需求进行多种方式的推送服务。所述调解员画像模块包括基础信息、业务状态、个人能力、服务评级子模块;基础信息包括调解员年龄、性别、执业年限、联系方式信息;业务状态指调解员当前调解状态,判断调解资源利用情况;个人能力指调解员的工作能力,调解业绩情况信息;服务评级指对调解员的服务评价和业务能力的综合评级。所述案件分析模块包括时间序列、人员画像、风险预警、工作质量、效率评估子模块;其中时间序列指案件历史变化趋势;人员画像指对咨询人员属性描述,包括年龄、性别、籍贯、历史记录信息;风险预警指对重大案件、群体案件、涉老涉幼等重点关注,社会影响广泛案件进行预警提示;工作质量指对结案案件结果、满意度、评价进行综合考量;效率评估指对调解案件从介入到结案整个服务过程的效率情况。如图2所示,一种基于人民调解案件特征提取的智能分派方法,具体步骤如下:步骤1:采集调解案件数据,并对数据进行预处理后存入调解案件库;其中,数据采集模块采集某市近5年人民调解案例近40万条数据,采集数据源包括调解员数据、用户数据、源数据库、文档数据等。如图3所示,数据采集模块对数据进行清洗存入基础数据库,清洗过程中删除纠纷详情为空、办理和办结时间异常以及重复的数据,将清洗后的数据存入调解员案件库中。采集的数据包括但不限于以下列出内容,如下表1所示:字段注释mediate_circs纠纷详情mediate_result调处结果mediate_explain调处结果说明mediate_type纠纷类型subgroup_county所属地区transact_date办理时间finish_date办结时间referee_dept调解机构referee_id调解人员iddissension_id纠纷事件主键result_recommend结果评价表1步骤2:对调解案件文本进行分类处理,获得各案件类型的调解员调解案件集。所述分类方法包括:将调解案件文本分词,获得词汇文本;对词汇文本进行向量化和归一化处理;对处理后的数据进行聚类,并根据专家经验分类添加标签,存入标签文本库;采用机器学习算法训练、优化分类模型,进而用于调解案件文本分类。如图4所示,文本分类模块首先将基础数据库的文本分词,根据调解案例数据将“村委会”等无法正确切分的词,加入专业司法词典,将无意义、区分度不高的词,例如:甲方、乙方等,加入停用词典,停用词典还包括常用的标点符号,“的”,“了”等。将调解专业词典加入分词工具词典中,对文本数据进行分词,分词工具有jieba、哈工大hanltp等,这里使用jieba,分词后使用停用词词典过滤,在本实施例中,某纠纷详情如下:2010.11.25,甲、乙系学校学生,双方因矛盾在学校打架受伤。甲方要求乙方赔偿医药费,双方为赔偿问题产生分岐引起纠纷。分词后结果如下:学校/学生/矛盾/学校/打架/受伤/要求/赔偿/医药费/赔偿问题/产生/分岐/引起纠纷然后分词后使用word2vec将文本数据转化为向量的形式,并进行归一化去量纲处理。归一化方法包括min-max方法和z-score。其中min-max方法是对原始数据线性变换,将其映射到区间[0,1]范围内,公式为:xnorm为归一化后的数据,x为原始数据,xmax、xmin分别为原始数据集的最大值和最小值。z-score方法将原始数据归一化为均值为0,方差为1的数据集,公式为:μ、σ分别为原始数据集的均值和方法,可以根据数据实际分布情况进行归一化方法的选择,本发明采用min-max方法进行归一化处理。对归一化后的数据进行聚类,提取标签。聚类方法有kmeans++、dbscan,本发明实施例采用dbscan算法进行聚类,其中dbscan算法聚类步骤如下:1)初始化选取邻域参数(∈,minpts),∈为聚类半径,minpts为最低样本数。2)计算距离,距离计算方式:欧式距离,点a(x11,x12,...,x1n)与b(x21,x22,...,x2n)间的欧式距离为3)通过距离度量方式,找到样本xj的∈-邻域样本集n∈(xj),如果样本集个数满足|n∈(xj)|≥minpts,将xj加入核心对象样本集合ωk。4)如果样本集合ωk为空集,算法结束。若非空进行步骤5)。5)在ωk中,随机选择核心对象o,进行步骤2),直到算法结束生成聚类簇ck6)优化邻域参数组合,重复步骤2)。聚类通过参数优化调整,对无效分组进行归并或去除处理,达到最佳聚类结果。聚类效果使用davies-bouldinindex和dunnvalidityindex指标进行评测。结合专家经验给每类别进行类别确认,并添加类别标签,分类好的数据存入特征库中。本实例根据实际情况细分出80个纠纷类别:遗产纠纷、物业纠纷、劳动工伤、劳动报酬、邻里纠纷、家庭纠纷、婚姻纠纷、交通事故、涉校纠纷、交通事故等。图5是分类模型训练及优化的流程图,可对模型进行训练优化迭代升级。从标签文本库抽取分类好的带有标签的数据集,将数据集随机分为训练集(80%)和测试集(20%),两个数据集中各类别数据量比例与原数据集保持一致。对训练集使用卷积神经网络dpcnn算法进行模型训练。模型训练完成后使用测试集进行测试,检验模型精度,其中精度=真正例/(真正例+假正例)。模型需要不断迭代优化才能达到最优的分类效果,模型分类准确率可达到96%。将训练好的分类模型存入模型库。步骤3:对调解案件文本提取特征词,获得调解员调解案件特征库。所述获得调解员调解案件特征库的方法包括:将调解案件文本分词,提取特征词,获得一级特征库;对特征词进行合并或扩展,获得二级特征库。基于分词结果统计常规词的组合词频,将组合词频满足设定阈值i的常规词组合作为新词汇加入词汇表。定义窗口长度l,使用窗口遍历的方法统计任意m个词汇组合出现的次数,将出现次数最高的k个组合中的词汇作为特征词,统计所述特征词中单个词汇的词频,将词频满足设定阈值ii的词汇作为候选特征词,加入一级特征库。然后,根据案件库中文本词频和组合词频,选择候选特征词,获得一级特征库。当两个特征词的相似度满足设定阈值iii,或两个特征词的相似度在一级特征库的特征词相似度值前n位时,将两个特征词合并,保留其中一个特征词,将另一个特征词从一级特征库中去除;当两个特征词的相似度满足设定阈值iv时,从扩展词典中抽取对应的扩展词汇,对特征词进行扩展,将扩展特征词加入一级特征库,获得二级特征库。其中,特征词的相似度,其计算方法包括:设置基于字符的特征词相似度权重p和基于语义的特征词相似度权重q;获取特征词f1、f2基于字符的特征词相似度sim(f1,f2),其中,sim(f1,f2)=特征词f1和特征词f2中字符相同的数量/特征词f1和特征词f2的字符长度较大值。例:特征词1为‘夫妇’、特征词2为‘夫妻’,字符长度分别为2、2,其中字符‘夫’相同,字符相同数为1,则标签的相似度为0.5。获取特征词f1、f2基于语义的特征词相似度score(f1,f2),其中,score(f1,f2)为特征词f1和特征词f2的相关性值,相关性值从案件库文本语言训练后的语义模型中获取,例:利用如word2vec语言模型构建语义模型;获取大量各种类型的司法文本作为语料,训练语义模型;将两个标签输入语义模型,获取两个标签的相关性score(f1,f2),将两个标签的相关性作为标签的相似度。最后,综合计算特征词的相似度=p*sim(f1,f2)+q*score(f1,f2)。从案件库中抽取n条案件记录,采用智能分派方法进行分派,根据案件分派准确度,更新参数获得三级特征库,具体如下:从案件库中抽取n条记录,按照智能分派方法,进行案件分派,分派准确度满足阈值v时,当前的二级特征库则确定为最终三级特征库,加入调解员特征库;否则更新参数阈值i、ii、iii、iv的值,直到分派准确度满足阈值v时。其中准确率计算方法为:准确率=分派准确的案件数/总的案件数。例如:总共抽取100件案件,其中有50件案件正确分派到相应的调解员,则相应的准确率为50%。通过更新参数i、ii、iii、iv值,最终分派准确率可达到95.6%。步骤4:对待分派调解案件文本进行分类与分词处理,确定分类结果,提取该案件特征词;步骤5:比对待分派调解案件和同案件类型下各调解员调解案件的特征词相似度,结合各调解员当前工作量和服务评级,对调解员进行排序,分派调解案件。举例,调解员特征库如下表2所示:调解员特征词med1交通车祸撞人赔偿死亡伤害走路红灯绿灯刮擦人行道med2儿女赡养抚养独生子婚生子家暴离婚财产父母表2智能分派方法具体如下:根据案件分类类别,获取该类型案件领域的调解员;待分派案件文本根据建立好的专业词汇表进行分词,提取该案件特征词。将特征词向量化,根据案件特征向量和调解员特征库(向量化),计算案件和列表s中调解员相似度si,相似度为二者余弦相似度,根据相似度si,对s中调解员进行排序。当前调解员在调解案件数为m,当m大于阈值γ时,则将调解员从s中剔除。获取分派排序分值v,v=a*si+b*st,其中st为调解员业务评级。根据s表中的分值v,进行案件分派。其中在进行分派时,把案例信息及咨询人员信息分派给调解员;把案例分类、调解员信息和调解地址信息推送给咨询人员。以上的所述乃是本发明的具体实施例及所运用的技术原理,若依本发明的构想所作的改变,其所产生的功能作用仍未超出说明书及附图所涵盖的精神时,仍应属本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1