一种大规模RFID系统中多组标签并行搜索方法与流程
本发明属于rfid标签搜索领域,特别涉及一种大规模rfid系统中多组标签并行搜索方法。
背景技术:
射频识别(rfid)技术如今被广泛应用于许多领域,包括供应链监控、仓库管理和库存控制。在某些场景中,并不需要对系统中所有标签进行识别或监测,而仅仅希望对某一部分感兴趣的特定标签进行监测来确定它们在系统中是否存在。例如,系统中可能存储了来自多个不同组织(供应商)的标签(商品),某个供应商只想对属于自己的商品进行监测并进一步处理相关商品。为区别于普通的监测,将这种操作称之为标签搜索:给定一组特定的标签称为待查找标签,标签搜索的目的是确定这些标签哪些目前在系统中,哪些不在。
标签搜索是rfid系统中一种非常重要的操作,但是目前仅有少数研究,并且这些研究都只考虑一次对一组标签进行搜索。如果遇到下面这种情景:在一个大型仓库中存放着多家厂商的不同商品,如果同时有几家厂商拿着商品列表要求进行搜索,由于涉及商业机密和可能存在的竞争关系,这些厂商待搜索商品的信息不愿互相公开,所以不能把这几家厂商的待搜索的商品列表放在一起进行搜索。按照以前的方法就只能等一组标签搜索完成之后进行下一组标签的搜索,但由于阅读器识别区中存在大量非待查找标签,每次搜索都需要排除大量相同的非待查找标签,极大的浪费了时间,本发明就考虑同时对这些组的标签同步进行搜索得到结果来提高搜索效率。
在近年来,出现了一些高效的标签搜索研究。例如,定义标签搜索问题并且提出基于标签搜索紧凑逼近(cats)方法,cats采用了bloom过滤器来紧密结合阅读器和标签之间的信息交换,这避免了耗时的标签id传输,从而减少了搜索时间。虽然执行一小部分待查找标签集,但是,当待查找标签数增加时,cats的性能大大降低。当在阅读器的覆盖区域有更多的待查找标签,cats甚至可能不工作。相比于使用一个单一的大的bloom过滤器,迭代标签搜索方法(itsp)提议使用一系列的短过滤向量过滤掉非目标标签。随着非目标标签被逐渐的过滤出来,过滤向量的大小逐渐减小,这促进了itsp的高时效。itsp在每一轮过滤出一半的非目标标签,在许多情况下,这并不是最优效果,从而降低其性能。在step中,为多个阅读器的射频识别系统提出了一个标签搜索方法。然而,在step方法中使用待查找标签的映射时隙和识别区标签的回复来过滤掉非目标标签,当单个阅读器识别区域标签数量较大时,会大大降低其性能。
所有目前提出的标签搜索方法都没有考虑同时存在多组待查找标签的情况,按照以前的方法就只能等一组标签搜索完成之后进行下一组标签的搜索,但由于阅读器识别区中存在大量非待查找标签,每次搜索都需要排除大量相同的非待查找标签,极大的浪费了时间。
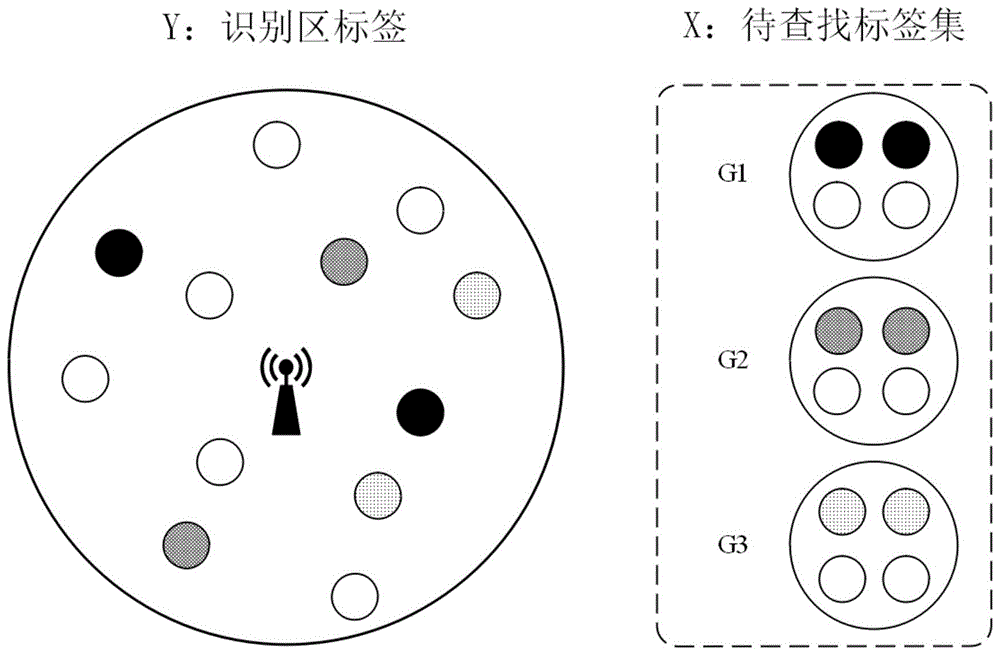
问题定义如图1和图2所示,考虑在一个大规模rfid系统中,阅读器识别区内存在的标签表示为y={y1,y2,...},待查找标签共f组,分别表示为g1={g11,g12,...},g2={g21,g22,...},…,gf={gf1,gf2,...},且g1∩g2∩...∩gf=θ。所有待搜索标签集表示为x={g1,g2,...,gf}。传统的标签搜索问题即找到某一组待查找标签与识别区标签的交集。而在本发明中要同时找到多组待查找标签和识别区的交集,即同时找到g1∩y,g2∩y,...,gf∩y。因为识别区标签和待查找标签的交集是未知的,所以极端情况下可能待查找标签和识别区标签没有交集,即x∩y=θ,也有可能待查找标签全部都在识别区标签中,即x∩y=x。用|·|表示集的基数。举例说明,如图1所示,有3组待查找标签集合g1,g2,g3,每一组中有阴影的标签代表现在存在于阅读器识别区y中,白色代表不存在识别区中,y中不同阴影标签在x中对应阴影标签代表不同组现在存在于识别区的标签。
技术实现要素:
本发明的目的在于,针对上述现有技术的不足,提供一种大规模rfid系统中多组标签并行搜索方法,能够多种标签并行搜索,自动识别待搜索标签的分组信息、快速排查非待查找标签,执行时间短且错误分类几率小。
为解决上述技术问题,本发明所采用的技术方案是:
一种大规模rfid系统中多组标签并行搜索方法,其特点是包括以下步骤:
第一步,假设有n个待搜索标签组;服务器为每一组待查找标签分配一个组号及与该组号相对应的哈希函数集hi(1≤i≤n),针对所有待查找标签,利用其对应的哈希函数集进行映射得到一个二进制比特串l;
第二步,阅读器广播l和n个哈希函数集hi(1≤i≤n),识别区标签利用收到的n个哈希函数集合hi在l上映射得到自己的映射组号;当该映射组号不为0时,则对应的识别区标签认为自己是映射组的成员并保持活跃;当该映射组号为0时,则对应的识别区标签不是待搜索标签,使其沉默;重复执行操作直到无分组失败标签;
第三步,根据候选目标标签集ci计算测试时隙和非测试时隙,然后根据非测试时隙的回复中去活非目标标签,根据测试时隙中的标签回复情况从ci排除不存在的目标标签并确认存在的目标标签;重复上述过程,直到满足终止条件。
作为一种优选方式,在第一步中,若一共有f组待搜索标签,则为每一组待查找标签分配一个长度为f比特的组号,该组号由一个1以及f-1个0组成,其中第i组标签集的组号设置规则为:第i个比特设置为1,其它f-1个比特设置为0。
作为一种优选方式,第三步处理过程包括:
首先,阅读器根据当前候选目标标签集计算测试时隙;
然后,阅读器广播构造测试时隙时使用的帧长和哈希函数;识别区标签在接收到参数信息后,用与计算测试时隙相同的哈希函数在帧上选择自己对应的时隙,然后发送回应至阅读器;
若阅读器在测试时隙收到回应,则阅读器通知相应的标签保持活跃;
若阅读器在非测试时隙收到回应,则阅读器通知相应的标签沉默;
最后,阅读器更新候选目标标签集并进行下一次匹配。
作为一种优选方式,二进制比特串长度
作为一种优选方式,最优帧大小是fl=1.03*nl;其中nl表示阅读器的本地活跃标签数量。
与现有技术相比,本发明能够多种标签并行搜索,自动识别待搜索标签的分组信息、快速排查非待查找标签,执行时间短且错误分类几率小。
附图说明
图1为问题模型图。
图2为一组待查找标签与识别区有交集的情况下,各区域的表示名称。
图3为标签构造比特串l及映射组号示意图。
图4为识别区标签分组后系统情况示意图。
图5为测试时隙筛选标签过程。
图6为x,li和s(ri)之间的关系。
图7(a)和图7(b)为不同规模下待查找标签数量变化时各方法执行时间对比图。
图8为目标标签比例变化后各方法执行时间对比图。
图9为组数变化后各方法执行时间对比图。
具体实施方式
利用本发明进行标签分组可能发生的错误类型可以分为三类,如表1所示。
1.假阳性:即阅读器识别区的某个标签并不属于任何一个待查找标签组,但是经过筛选却表现出属于某一组标签,把这种标签称为假阳性标签。发生这种情况的概率称为假阳性率,这与bloom过滤器中的假阳性概率相似。用α表示假阳性概率。
2.错误分组:即阅读器识别区的某个标签实际属于a组却被错误分组进了b组。还有一种特殊情况是,标签实际属于某一个组,经过筛选却被认为不属于任何一个组,这种情况称为假阴性。有些应用程序,假阴性和错误分类是不可取的或不可接受的。
3.分组失败:即阅读器识别区的某个标签表现出同时属于多个组,这种情况下,无法确定此标签到底属于哪一组,或者根本就不属于任何一组,把这种标签称为分组失败标签。发生这种情况的概率称为分类失败率。用β表示分组失败概率。
表1标签分组错误类型举例
本发明所述的大规模rfid系统中多组标签并行搜索方法(msts)原理为:
首先在利用待查找标签集g作为映射标签集和其对应的哈希函数集h构造一个二进制比特串l,之后阅读器将构造好的比特串l和所有的哈希函数集h广播给识别区标签,识别区标签根据收到的比特串l和哈希函数集h构造自己的“映射组号”,其中会有分组失败的标签,这些标签作为下一轮的映射标签集。然后阅读器收取标签信息,根据时隙类别以及回复信息去活非目标标签并排除不存在的目标标签/确认存在的目标标签。最后,只剩下每个组在识别区的标签,完成标签搜索操作。
本发明详细过程如下所述,假设一共有f个待搜索的组,首先将这f个组分别赋予1到f的顺序。在第一阶段中,构造一个f位的二进制串,并给每一位分配一组对应的哈希函数集h,每个哈希函数集都有h个哈希函数,且互不相同。由于有f个位,每个位都有h个哈希函数,总共有f*h个哈希函数。为每个组分配一个哈希函数集,为方便表示,直接将第一位的哈希函数集分配给第一组,以此类推,将第f位的哈希函数集分配给第f组。将每一组待查找标签集的组号转换成对应的f位的二进制串,将对应的位标1,其余位标0,得到每组对应的组号。例如一共有5个组,第一组对应第一位的哈希函数集,则第一组的组号为10000;以此类推,第5组对应第五位的哈希函数集,对应组号为00001。
f个待查找标签组,组中标签的组号和“映射组号”分别用g(t)和g'(t)表示,根据本发明构造规则,同一组标签的组号相同,但“映射组号”却可能因为分组失败的情况而不同。本发明主要步骤如下:
(1)构造比特串l:利用每个组对应的哈希函数集,构造一个长为l的包含所有组的标签信息的比特串。具体过程即,每个组标签利用自己组的哈希函数集中的h个哈希函数映射到l上,l初始全为0,被标签映射到的位标1,等到所有组的所有标签都映射完后形成比特串l。
举例说明,如图3所示,假设现在有3个组,第一组g1={t1},组号g(t1)=100,对应哈希函数集h1={h1,h2};第二组g2={t2},组号g(t2)=010,对应哈希函数集h2={h3,h4};第三组g3={t3},组号g(t3)=001,对应哈希函数集h3={h5,h6};比特串l初始全为0,t1使用h1,h2映射到l上,对应位标1;t2使用h3,h4映射到l上,对应位标1;t3使用h5,h6映射到l上,对应位标1;等所有标签都映射完成后形成二进制比特串l。
(2)构造“映射组号”:构造完l后,再为每个组标签获取“映射组号”:再次利用所有f个组的哈希函数集在比特串l上进行映射,构造一个长为f的“映射组号”。具体过程即,每个组标签依次利用f组的哈希函数集中的h个哈希函数映射到l上,如果这一组哈希函数集全都映射到1,则将对应映射组号位标1,否则只要这一组哈希函数集中有一个哈希函数映射到0,对应映射组号位就标0。等到依次把f个哈希函数集映射完之后形成标签对应的“映射组号”,对每个组的每个标签进行此操作,会得到每个标签对应的特有的“映射组号”信息。注意,由于l是由标签对应组号位的哈希函数集映射而来,所以标签对应组号的1位一定是1,因为那一位所有的哈希函数都会映射到1。举例说明,如第一组标签组号为10000,那么这一组标签的对应“映射组号”的第一位一定是0。
之所以构造“映射组号”,是因为当待查找标签实际存在于识别区时,根据提供的l和h映射出来的组号不一定和赋予的组号相同,可能会出现分组失败的情况,这种情况下无法确定其属于哪一组。所以提前在后台把可能出现这种情况的标签提前选出来,在下一轮进行排除。可以观察到,如果待查找标签的“映射组号”可以成功分组,则其标签如果存在于识别区就一定也可以成功分组,所以只需要关注“映射组号”中分组失败的标签。
举例说明分组失败的组号情况,如图3所示,现在第一组的标签t1来构造“映射组号”,t1依次使用h1={h1,h2},h2={h3,h4},h3={h5,h6}来映射l,其中h1,h2,h5,h6映射到1,所以t1的“映射组号”第一位和第三位标1;其中h3,h4映射到0,所以t1的“映射组号”第二位标0,由此得到其“映射组号”g'(t1)=101。这种情况下,标签t1如果存在于识别区就会发生分组失败。
(3)阅读器广播数据:阅读器广播比特串l和所有哈希函数集h给识别区y的标签,标签依次利用f个哈希函数集来映射l,形成识别区标签对应的组号。识别区标签的组号具体构造过程和待查找标签的“映射组号”构造过程相同,即,识别区标签依次利用f组的哈希函数集中的h个哈希函数映射到l上,只有当每组哈希函数集的所有哈希函数都映射到1,对应位才标1,否则只要有一个哈希函数映射到0,对应位就标0。
从识别区y标签的映射结果讨论:
(1)标签组号中有0个1,说明此标签不属于任何一个组,可以将其沉默,以减小识别区标签数。
(2)标签组号中有1个1,这种标签可以成功分组,不再参与下一轮的分组操作,只有进入第二阶段才会重新激活。但需要注意的是,此时标签会存在两种情况,第一种情况是此标签确实属于这一组,第二种情况是此标签为假阳性标签。对于这二种情况,不论是否为假阳性标签,直接将其分到对应组中,下一阶段再排除假阳性标签。
(3)组号中有多于1个1,则此标签分组失败。对于这种情况,标签不确定属于哪一组,保持活跃继续参与下一轮分组操作。如此循环直到待查找标签集中的标签没有分组失败的情况后,发送其构造的l到识别区y,经过本轮筛选后,如果y中仍然有未分组的标签,说明此标签肯定不属于待查找标签集中标签,可排除。
如图4所示,经过第一阶段后,识别区标签数量会大量减少,所有剩余参与第二阶段的标签都知道自己的组号,完成识别区标签的分组操作。
接下来对每组待查找标签单独进行第二阶段,第二阶段完成会得到本组标签的目标标签,依次对每一组标签进行此操作,直到得到所有组的目标标签,整个方法完成。
测试时隙筛选标签由多轮组成,过程为:为了不失一般性,假设在第l轮,阅读器首先根据候选目标标签集cl计算测试时隙和非测试时隙,然后从cl消除非目标标签并确认排除在识别区的非待查找标签。重复上述过程,直到满足终止条件。
在第l轮开始,阅读器首先根据当前候选目标标签集cl计算测试时隙,然后阅读器广播构造测试时隙时使用的帧长l和哈希函数h。在接收到参数信息后,识别区标签用计算测试时隙的相同的哈希函数在帧上选择它们的时隙,然后在他们所选择的时隙给阅读器发送简短的回应。阅读器根据收到回应的时隙从cl排除非目标标签:
在测试时隙,如果阅读器收到回应,它回复一个nak保持标签的活跃。如果阅读器没有在此时隙得到回应,它可以确定那些cl中选择此时隙的候选目标标签现在不在识别区,一定是非目标标签,并从cl排除这些待查找标签。
在非测试时隙,如果阅读器收到一些回应,一定来自非待查找标签,它回复ack通知这些标签沉默,来阻止他们参与接下来的筛选轮。
在每轮结束时,阅读器会更新候选目标标签集cl+1并检查是否达到终止条件。如果它不满足终止条件,它将开始一个新的轮,并重复测试和消除过程。
如图5所示,演示了第二阶段是怎样工作的。在这个示例中,虚线箭头表示候选目标标签和测试时隙之间的映射,而实心箭头表示识别区标签和阅读器之间的传输。最初的候选目标标签集c1=(t1,t2,t3,t4,t5)。有五个识别区标签,其中t1和t3是目标标签。图5(1)和图5(2)说明本发明第一轮的执行。阅读器首先计算在c1的标签的测试时隙并收集识别区标签的回应(图5(1)),然后从c1消除非目标标签并确认沉默在识别区域的非待查找标签(图5(2))。阅读器在它接收到回复的1、2和3测试时隙回复nak,保持标签活跃。测试时隙4是空的,所以阅读器从c1排除相应的非目标标签t4和t5。同时,它在时隙5回复ack通知非待查找标签y2和y3沉默。图5(3)和5(4)说明了第二轮执行。阅读器用更新的候选目标标签集c2=(t1,t2,t3),重新计算测试时隙并且识别区标签也重新选择自己的时隙。类似于第一轮,阅读器消除了c2中映射到测试时隙3的非目标标签t2,并通知映射到非测试时隙4的非待查找标签y1。如果本发明第二轮后终止,本组搜索结果将是s(ri)=(t1,t3)。
分组阶段最佳比特串大小设置:
首先计算任意哈希函数集的假阳性率
m为待查找标签数,f为组号长,h为哈希函数集h的哈希函数个数,l为比特串长。
任意哈希集的假阳性概率,即f位中某一位假阳性概率
为了找到最小化假阳性概率p的哈希函数个数h的值,关于h求导上述表达式并将其设置为0以得到p'=0,求出最优哈希函数个数为
此时组号中某一位为假阳性的概率最小,为
则第一阶段中标签的假阳性率为
pfp=fp(1-p)f-1≤fpbf
第一阶段中标签的分类失败率为
pcf=1-(1-p)f-1≤(f-1)p≤fpbf
此时指定假阳性率的值等于分类失败率的值为α,令pfp<α和pcf<α,即fp<α和fp<α,即
l=mlog0.6185p
即满足指定假阳性率和分类失败率α的情况下的最优比特串长l
其中
其中α和f都是已知的,由此可得第一阶段的最优比特串长l。
测试时隙筛选阶段最佳帧大小设置
在这一部分中,分析如何设置帧的大小来最小化排除候选标签集中的非目标标签的平均时间成本cl。
不失一般性,考虑第l轮。让nl表示阅读器ri的本地活跃标签数量,并让fl表示帧大小。对于帧中的一个时隙,它是空的概率等于没有识别区标签选择该时隙的概率,即
显然,一个时隙是ri非空的概率是(1-pe)。整个帧的总持续时间为
其中,te是一个空时隙的持续时间,和ts是一个短响应时隙的持续时间。
让zl表示在第l轮所有的非目标标签集,即zl=yl-(x∩li),其中x∩li是阅读ri的目标标签集。因此,可以从yl消除的标签总数是|zl|。zl中的一个标签如果选定的测试时隙实际上是空的就会被排除。因为待查找标签一起选择时隙,在这一轮预期消除的非目标标签的数量大约是
neli≈|zl|*pe
从yl消除一个非目标标签的平均时间成本为
为了最小化cl,让
并且cl取得最小值,当
定义负载系数ρ=nl/fl,当下面等式成立时cl取最小值
可以看到,ρ最优的值完全取决于te/ts。在系统模型中,te=0.184ms和ts=0.2ms。在这种情况下,ρ的最优值是0.9697,最优帧大小是fl=nl/0.9697=1.03*nl。
本发明终止条件
现在分析如何设置本发明的终止条件,以达到所需的精度要求。注意(x∩li)∈s(ri)。假阳性标签数为nδ=|s(ri)|-|x∩li|。图6说明了x,li和s(ri)之间的关系。目标是高概率的保证nδ至少不会超过preq的阈值,即,
p{nδ≤δ}≥preq
例如,如果△=2,preq=0.95,满足上述公式意味着大于或等于0.95的概率有最多两个假阳性标签在搜索结果中。
在本发明中,多轮的从候选目标标签集cl中迭代消除非目标标签。如果在某一轮(例如,第l轮)没有非目标标签从cl排除和没有非通缉标签被通知,可以推测,假阳性标签的数目很小。为了证明推断并保证假阳性标签数量不大于一个高概率,需要观察连续k个轮。如果在所有k轮没有非目标标签淘汰,那么阅读器终止本发明。否则,阅读器继续搜索的过程。
现在分析如何设置k以满足上述公式给定的△和preq。用ek表示事件在所有连续k个轮没有非目标标签淘汰,用ev表示事件在结果中恰有v个假阳性标签。然后有
根据贝叶斯定理,概率p{ev|ek}可以由下式计算
从总概率的定律,其遵循
代入公式有
p{ek|ev}是恰有v个假阳性标签和他们中没有一个在所有的k连续轮被排除的概率。可以知道,一个非目标标签当映射到一个非空的测试时隙时不能从候选目标标签集排除。因此p{ek|ev}等于所有v个假阳性标签在所有k个连续轮选择非空测试时隙的概率,即
p{ek|ev}=((1-pe)v)k=(1-pe)vk
(1-pe)是测试时隙非空的概率。
因为不知道v的分布,可以假设v遵循统一分布,即,
代入公式得
为了满足要求的精度,让
1-(1-pe)(δ+1)k≥preq
可得
这意味着,
如前面分析的,最佳的ρ是
表2不同△和preq的组合的k的最小值
实验仿真与分析
在仿真实验中,信道保持理想情况,忽略冗余检验等开销。实现了四个方法来比较它们的性能:msts(即本发明),step,cats,itsp。使用方法的执行时间(s)作为标准来比较不同方法的性能。执行时间是反应搜索方法性能最直观的标准,同等条件下,完成搜索的时间越短说明搜索方法性能越好。考虑可能影响不同方法性能的三个参数:(1)待查找标签的总数(|x|)。(2)目标标签与待查找标签的比例,定义为η=|x∩y|/|x|。(3)系统待查找标签组数(m)。对于每个参数设置,运行对比的方法100次,并计算平均度量数据。
仿真场景和时间设置
仿真场景:考虑有多个阅读器的rfid系统。系统默认有5个待查找标签组,默认部署64个阅读器和50000个标签。阅读器以网格模式部署,相邻阅读器之间的距离设置为√2r。这导致每个阅读器约有1500个覆盖标签。默认的每组待查找标签数量(|x|)被设置为10000,每组目标标签的默认比例(η)被设置为0.2。对于多个阅读器场景,使用图着色算法来寻找阅读器的可行调度。
时间设定:根据epcc1g2uhfrfid标签的时间指定设置不同的时隙的持续时间。阅读器与标签进行数据传输的速率定为62.5kbps。在这个数据速率下,不同时隙的时间如下:tid=2.4ms,te=0.184ms,ts=0.2ms。阅读器将二进制比特串l分为96位(即等于一个标签id的长度)进行广播,每段的传输时间为tid,则l的传输时间为(l/96)*tid。需要注意到,当数据速率发生变化时,绝对度量数据可能会有所不同,但可以达到类似的结论。
不同方案性能比较
1)每组待查找标签数量的影响
系统设置了一个包含64个阅读器和50000个标签的大系统,其中待查找标签一共5组,为了方便表示,减少其他因素的影响,设定不同组待查找标签数量相同,且每组目标标签的比例相同。如图7(a)和图7(b)所示,描绘了当待查找标签数量增加时,不同方法的执行时间,其中横坐标表示5组待查找标签之和,因为计算的是所有待查找标签组的搜索时间之和。例如图7(a)中,每组待查找标签数量从200到1200,则5组总共的待查找标签数量从1000到6000。其中又分了两种情况进行讨论:一种是小规模待查找标签,每组待查找标签数量较少;一种是大规模待查找标签,每组待查找标签数量较多。其中图7(a)表示小规模情景,图7(b)表示大规模情景。
根据结果,可以观察到在所有考虑的方法中,执行时间都随着待查找标签的增加而增加。其中在小规模情景中,cats方法和itsp方法的执行时间在2500之前要优于step方法,而到了接近5000时,cats方法的执行时间已经超过itsp方法,成为执行时间最长的方法,而且根据图7(b)也可以看出cats方法的执行时间随着标签数量的增长而大幅上升,说明cats方法只适用于小数量的标签搜索,而msts方法不论小规模还是大规模情景,始终保持最优的执行时间,并且随着标签数量的增加,mtst方法的执行时间缓慢增加,稳定性最好。根据图7(b)得到,伴随着标签数量的变多,方法执行时间由多到少依次为cats方法,itsp方法,step方法和mtst方法。
2)每组目标标签比例的影响
本组实验场景设置与前面相同,其中每组待查找标签数量为10000,需要注意的改变是,在本组实验中不改变5组待查找标签的数量,只改变每组目标标签的数量。图8绘制了当每组目标标签比例η从0.1变化到0.9时不同方法的执行时间。从实验结果中可以看到,当η变大时,msts方法,step方法,itsp方法的执行时间全部增加,而cats方法的执行时间不受η的影响。这是因为在cats方法中布隆过滤器的大小是根据待查找标签的数量|x|来设置的,这与η无关。相反,当η增加时,每个阅读器区域会有更多的目标标签,在这种情况下,本发明方法和step方法以及itsp方法需要运行更多轮次以满足终止条件。但是,本发明mtst方法总是胜过step方法,cats方法和itsp方法。
3)待搜索标签组数的影响
本组实验场景设置与前面相同,固定目标标签的比例η为0.2,每组待查找标签数量为10000,然后改变待查找标签的组数。如图9所示,绘制了待查找标签的组数从1到10变化后不同方法的执行时间。从实验结果中可以看到,当待查找标签组数变大时,msts方法,step方法,itsp方法,cats方法的执行时间全部增加。其中step方法,itsp方法,cats方法的执行时间基本都是按照组数的数量按比例增加,因为这些方法不能并行计算多组标签的结果,只能单组搜索,重复执行,所以时间会根据组数递增,而msts方法在第一阶段会对所有组同时进行操作,缩小识别区标签数量,并且此操作对第二阶段的所有组生效,由此避免了重复对识别区并且进行删除操作,所以组数越大本发明所述msts方法优势越明显。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是局限性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!