基于双向位图的稀疏矩阵压缩存储方法与流程
本发明涉及大数据存储方法,尤指基于双向位图的稀疏矩阵压缩存储方法。
背景技术:
图结构是大数据应用中最重要的数据结构之一,在众多领域中得到广泛的应用,如社交媒体、生物信息学、天体物理学、人工智能、数据挖掘、智能推荐、自然灾害预测等等。这些应用的共同特点是数据量大和结构复杂,往往可以达到数十亿条边和数万亿个节点,这导致在数据存储和计算力方面有更高的需求。超级计算机主要用于数值计算,大多数高性能计算机的基准测试都是以计算力作为衡量标准,如top500采用的hpl(highperformancelinpack)。在数据密集型应用广泛兴起的大数据时代,graph500成为了一个新的超级计算机计算力的基准测试程序。graph500作为top500的重要补充,以每秒遍历图中的边的数量(teps)来衡量超级计算机的大数据处理能力。
graph500中图遍历采用宽度优先搜索即bfs(breadth-firstsearch)算法。宽度优先搜索算法可描述为:已知图g=(v,e)和一个源顶点s,宽度优先搜索将探寻g的所有边,从而发现s所能到达的所有顶点,并计算s到所有这些顶点的距离(最少边数),该算法同时能生成一棵根为s且包括所有可达顶点的宽度优先树,对从s可达的任意顶点v,宽度优先树中从s到v的路径对应于图g中从s到v的最短路径。
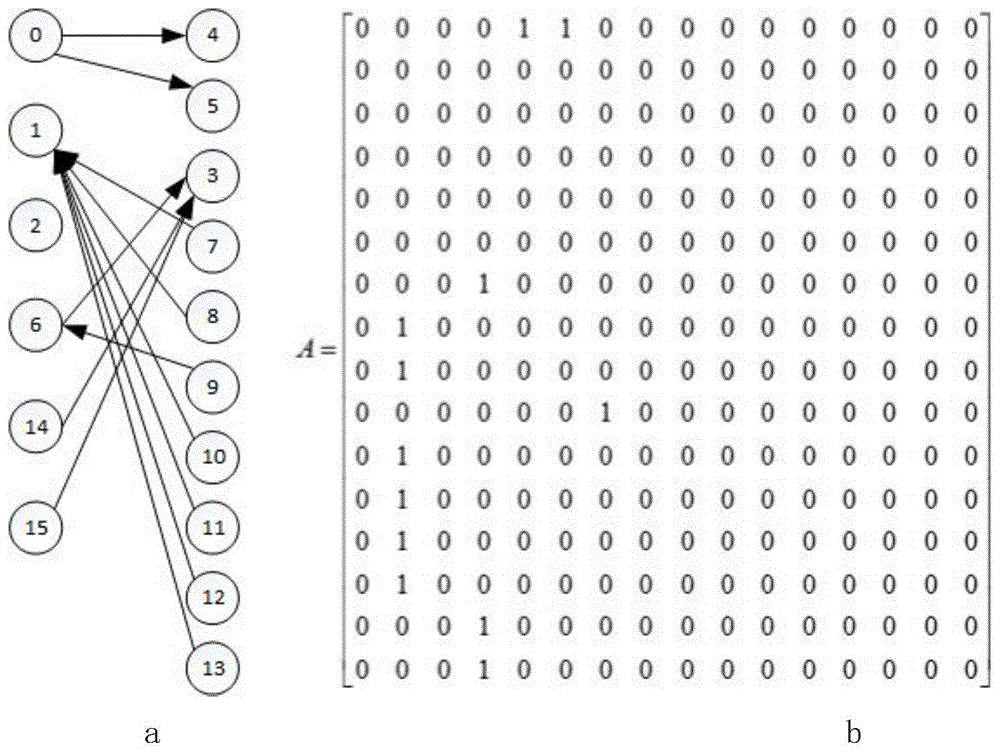
图g=(v,e)包含顶点集合v和边集合e,通常使用vi表示v中编号为i的顶点,使用顶点对(vi,vj)表示顶点i到顶点j的边,(vi,vj)∈e,0≤i≤nv-1,0≤i≤nv-10≤j≤nv-1,nv为v中顶点个数。g通常用邻接矩阵a表示,a中的第i行ai为邻接表。如图1所示,形如图1(a)的图g可用图1(b)的邻接矩阵a表示,a中第i行第j列的元素aij表示边(vi,vj)。通常使用1表示存在这样的边,0表示不存在这样的边。
大部分从现实问题抽象出来的图中,顶点的邻居数往往远小于顶点总数,即顶点的平均度数较低,其邻接矩阵为稀疏矩阵。稀疏矩阵可以使用按行压缩(compressedsparserow,csr)的方式来存储以扩大图的测试规模。csr使用列数组colums和行数组rowstarts来表示邻接矩阵,colums存储按行压缩的列标号,rowstarts存储对应行在colums中的索引位置,如图2所示。colums中的标号邻接矩阵a对应非零元素的列标号,如:第一个数字4表示第一个非零元的列标号为4,第二个数字5表示第二个非零元的列标号为5,第三个数字3表示第三个非零元的列标号为3,第四个数字1表示第四个非零元的列标号为1;第五个数字1表示第五个非零元的列标号为1;第六个数字6表示第六个非零元的列标号为6;第八个数字1表示第八个非零元的列标号为1;第九个数字1表示第九个非零元的列标号为1;第十个数字1表示第十个非零元的列标号为1;第十一个数字3表示第十一个非零元的列标号为3;第十二个数字3表示第十二个非零元的列标号为3;rowstarts中的索引位置对应a中非零元的行标号相对偏移,即对应行中非零元的个数,如:第二个数字2和第一个数字0表示a中第0行中非零元的个数为2-0=2个,第三个数字2和第二个数字2表示a中第1行中非零元的个数为2-2=0个,第四个数字2和第三个数字2表示a中第2行中非零元的个数为2-2=0个,第五个数字2和第四个数字2表示a中第3行中非零元的个数为2-2=0个,第六个数字2和第五个数字2表示a中第4行中非零元的个数为2-2=0个,第七个数字2和第六个数字2表示a中第5行中非零元的个数为2-2=0个,第八个数字3和第七个数字2表示a中第6行中非零元的个数为3-2=1个,第九个数字4和第八个数字3表示a中第7行中非零元的个数为4-3=1个;第十个数字5和第九个数字4表示a中第8行中非零元的个数为5-4=1个;第十一个数字6和第十个数字5表示a中第9行中非零元的个数为6-5=1个;第十二个数字7和第十一个数字6表示a中第10行中非零元的个数为7-6=1个;第十三个数字8和第十二个数字7表示a中第11行中非零元的个数为4-3=1个;第十四个数字9和第十三个数字8表示a中第12行中非零元的个数为9-8=1个;第十五个数字10和第十四个数字9表示a中第13行中非零元的个数为10-9=1个;第十六个数字11和第十五个数字10表示a中第14行中非零元的个数为11-10=1个;第十七个数字12和第十六个数字11表示a中第15行中非零元的个数为12-11=1个。colums和rowstarts中均使用1个整型(32个bit位)来表示索引信息,因此a的存贮空间为(12+17)×32=928bit,而rowstarts的存贮空间为17×32=544bit。
许多采用图结构的应用程序(如graph500)的性能主要受限于内存大小和访存带宽,内存越大,可应用的图规模越大,性能表现越好。当内存恒定时,如何压缩数据存储规模成为提升图结构的应用性能的重要途径,也是本领域技术人员亟需解决的技术难题。
技术实现要素:
本发明要解决的技术问题在于:提出一种基于双向位图的稀疏矩阵压缩存储方法,可以更加紧凑地存储邻接矩阵,进一步减少存储空间,扩大图的规模,优化采用图结构的应用程序的性能。
为了解决上述技术问题,本发明的技术方案为:通过仅保留存储一个或者多个顶点或边的起始位置来压缩csr的数据结构,并分别在行列两个方向使用一个额外的位图(bitmap)来辅助识别顶点的边信息,其中行方向位图中每一位存储一个顶点信息,列方向位图中每一位存储列连续编号信息。
具体技术方案为:
第一步、读取图g的邻接矩阵csr存储数据结构,主要包含列数组colums[v″]和行数组rowstarts[v'],v',v″均为正整数,v'=nv+1,v″为非零元的个数,rowstarts[v']中的每一个元素为int整型量,表示对应非零元的行索引偏移,列数组colums[v″]中每一个元素为int整型量,表示对应非零元的列位置编号,一个int类型通常包含4个字节,每字节由8个bit位组成,即,一个int整型元素通常包含32个bit位;
第二步、简化行数组rowstarts[v'],具体方法如下:
2.1.统计rowstarts[v']数组中不同元素的个数,记为vb,并定义数组rowstarts'[vb]来存放这vb个元素;
2.2.将rowstarts[v']数组中vb个不同元素依次分别表示为rowstarts'[0],rowstarts'[1],…,rowstarts'[n],…,rowstarts'[vb-1],n=0,1,2,…,vb-1;
2.3.定义具有vb个元素的改进型位数组csr-rowstarts'[vb];对csr-rowstarts'[vb]进行赋值,具体方法如下:
2.3.1定义变量i'=0;
2.3.2如果i'<vb,转2.3.3;否则,转2.3.6;
2.3.3csr-rowstarts'[i']=rowstarts'[i'],将数组rowstarts'[vb]中vb个元素依次赋值给数组csr-rowstarts'[vb];
2.3.4i'=i'+1;
2.3.5若i'<vb,转2.3.3;否则,转2.3.6;
2.3.6赋值完毕;
第三步、计算偏移量,具体方法如下:
3.1.定义有nv个元素的偏移数组offset[nv];
3.2.定义变量j'=0;
3.3.若j'<nv,转3.4;否则,转3.7;
3.4.offset[j']=rowstarts[j'+1]-rowstarts[j'],即计算相应的行非零元的个数;
3.5.j'=j'+1;
3.6.若j'<nv,转3.4;否则,3.7;
3.7.偏移量计算完成,得到偏移数组offset[nv];
第四步、构建行方向位图数组,由改进型位数组csr-rowstarts'[vb]和行方向位图数组压缩存储行数组rowstarts[v']全部信息,具体方法如下:
4.1定义有nv个元素的行方向位图数组row-bitmap[nv];row-bitmap[nv]中的每一个元素仅有一个bit位,用来表示两个顶点之间是否有边,1表示有边,0表示无边;
4.2定义变量k=0;
4.3若k<nv,转4.4;否则,转4.7;
4.4若offset[k]≠0,转4.5;否则,转4.6;
4.5bitmap[k]=1,表示顶点之间有边,转4.7;
4.6bitmap[k]=0,表示顶点之间无边,转4.7;
4.7k=k+1;
4.8若k<nv,转4.4;否则,转4.9;
4.9位图数组row-bitmap[nv]构建完毕。通过位图数组row-bitmap[nv]和csr-rowstarts'[vb]可以还原出csr中的数组rowstarts[v']。
第五步、计算列数组colums[v″]连续片段长度并构建连续片段二元组集合。依次统计colums[v″]数组中连续列编号片段的长度,即,colums[v″]中相同的列编号连续无间断出现的次数,若列编号没有连续出现,其连续片段长度为1,若列编号存在连续出现,其连续片段长度必定大于等于2,并定义二元组集合f,f中存放形如<colums,len>的二元组,<colums,len>表示每个连续片段列位置编号colums连续出现了len次,len≥1,colums是连续片段列位置编号,len是colums连续出现的次数,且len,colums均为正整数;如图2中colums[12]={4,5,3,1,1,6,1,1,1,1,3,3},则colums[12]对应的二元组集合f={<4,1>,<5,1>,<3,1>,<1,2>,<6,1>,<1,4>,<3,2>},表示列编号“4”连续出现了1次,列编号“5”连续出现了1次,列编号“3”连续出现了1次,列编号“1”连续出现了2次,列编号“6”连续出现了1次,列编号“1”连续出现了4次,列编号“3”连续出现了2次;具体方法如下:
5.1.定义二元组集合
5.2.定义循环变量m=0,令len=1;
5.3.定义当前位置cur=m;
5.4.若cur<v″,转5.5,否则,统计完毕,转第六步;
5.5.若colums[cur]==colums[m+1],转5.6,否则,进行下一个连续片段统计,转5.9;
5.6.len=len+1;
5.7.colums=colums[cur];
5.8.m=m+1;
5.9.若m<v″,转5.5,否则,当前片段统计完毕,转5.9;
5.10.将二元组<colums,len>以元素形式加入集合f,即,f=f+{<colums,len>};
5.11.cur=cur+len,转5.4;
第六步、依据第五步建立的二元组集合f构建简化列数组和列方向位图数组,由简化列数组和列方向位图数组压缩存储列数组colums[v″]全部信息,具体方法如下:
6.1.统计二元组集合f中的元素个数,记为s1;
6.2.统计二元组集合f中的元素的第二元信息len≥2的个数,记为s2;
6.3.令尺度变量size=s1+s2;
6.4.定义含有size个元素的简化列数组colums'[size];
6.5.定义列方向位图数组column-bitmap[size],列方向位图数组中的元素1表示连续片段,列方向位图数组中的元素0表示非连续片段;
6.6.定义集合f-tmp=f;
6.7.定义变量s=0;
6.8.若
6.9.将二元组f从集合f-tmp中删除,f-tmp=f-tmp-{f};
6.10.若f.len=1,f.len表示二元组f的len值,转6.11;否则,f.len≥2,转6.14;
6.11.令colums'[s]=f.colums,f.colums表示二元组f的colums值;
6.12.令column-bitmap[s]=0,表示对应的列编号不是连续片段的起始列编号;
6.13.s=s+1;转6.20。
6.14.令column-bitmap[s]=1,表示对应的列编号是连续片段的起始列编号。此时,colums'[size]需要连续存储列编号和片段长度,将占用两位;列标号对应的位图为1,长度对应的位图为0;
6.15.令colums'[s]=f.colums;
6.16.s=s+1;
6.17.column-bitmap[s]=0;表示连续片段的长度值并不是连续片段的起始列编号;
6.18.令colums'[s]=f.len,即,将二元组的连续片段长度赋值给简化列数组;
6.19.s=s+1;
6.20.若s<size,转6.8,否则,转第七步;
第七步、结束。
采用本发明可以达到以下技术效果:
1.本发明第四步建立的行方向位图数组可以将行数组rowstarts[v']中的每个非零元的表示信息大小由32bit降低至1bit;可以将图数据存储空间节约近60%,可以扩大图的应用规模,优化采用图结构的应用程序的性能。
2.本发明第六步建立的列方向位图数组可以将列数组colums[v″]中的每个非零元列编号大小由32bit降低至1bit;可以将图数据存储空间在行方向位图数组的基础上进一步压缩,极大规模扩大图的应用规模,优化采用图结构的应用程序的性能。
本发明可以广泛应用于存储受限的图计算与应用系统中,提升系统效率。
附图说明
图1为图的邻接矩阵表示;图1(a)为含15个节点的图;图1(b)是图1(a)的邻接矩阵。
图2为图1(b)所示邻接矩阵的csr存储示意图;左侧为邻接矩阵,右侧是csr存储示意图。
图3为本发明总体流程图。
图4为采用本发明对图2进行基于双向位图的邻接矩阵csr存储示意图;左侧为邻接矩阵,右侧为双向位图的邻接矩阵csr存储示意图。
具体实施方式
图3为本发明总体流程图。如图3所示,本发明的步骤如下:
第一步、读取图g的邻接矩阵csr存储数据结构,包含列数组colums[v″]和行数组rowstarts[v'],v',v″均为正整数,v'=nv+1,v″为非零元的个数;
第二步、简化行数组rowstarts[v'],具体方法如下:
2.1.统计rowstarts[v']数组中不同元素的个数,记为vb,并定义数组rowstarts'[vb]来存放这vb个元素;
2.2.将rowstarts[v']数组中vb个不同元素依次分别表示为rowstarts'[0],rowstarts'[1],…,rowstarts'[n],…,rowstarts'[vb-1],n=0,1,2,…,vb-1;
2.3.定义具有vb个元素的改进型位数组csr-rowstarts'[vb];对csr-rowstarts'[vb]进行赋值,将数组rowstarts'[vb]中vb个元素依次赋值给数组csr-rowstarts'[vb];
第三步、计算偏移量,具体方法如下:
3.1.定义有nv个元素的偏移数组offset[nv];
3.2.定义变量j'=0;
3.3.若j'<nv,转3.4;否则,转3.7;
3.4.offset[j']=rowstarts[j'+1]-rowstarts[j'],即计算相应的行非零元的个数;
3.5.j'=j'+1;
3.6.若j'<nv,转3.4;否则,3.7;
3.7.偏移量计算完成,得到偏移数组offset[nv];
第四步、构建行方向位图数组,由改进型位数组csr-rowstarts'[vb]和行方向位图数组压缩存储行数组rowstarts[v']全部信息,具体方法如下:
4.1定义有nv个元素的行方向位图数组row-bitmap[nv];row-bitmap[nv]中的每一个元素仅有一个bit位,用来表示两个顶点之间是否有边,1表示有边,0表示无边;
4.2定义变量k=0;
4.3若k<nv,转4.4;否则,转4.7;
4.4若offset[k]≠0,转4.5;否则,转4.6;
4.5bitmap[k]=1,表示顶点之间有边,转4.7;
4.6bitmap[k]=0,表示顶点之间无边,转4.7;
4.7k=k+1;
4.8若k<nv,转4.4;否则,转4.9;
4.9位图数组row-bitmap[nv]构建完毕。
如图4所示,图2所示的csr存储的行数组rowstarts[v']经过第四步后存贮到了csr-rowstarts'和row-bitmap中,row-bitmap中的每一位对应csr-rowstarts'数组对应所在的行是否有非零元,如:第一个数字1表示第0行有非零元,第二个数字0表示第1行没有非零元,第三个数字0表示第2行没有非零元,第四个数字0表示第3行没有非零元,第五个数字0表示第4行没有非零元,第六个数字0表示第5行没有非零元,第七个数字1表示第6行有非零元,第八个数字1表示第7行有非零元,第九个数字1表示第8行有非零元,第十个数字1表示第9行有非零元,第十一个数字1表示第10行有非零元,第十二个数字1表示第11行有非零元,第十三个数字1表示第12行有非零元,第十四个数字1表示第13行有非零元,第十五个数字1表示第14行有非零元,第十六个数字1表示第15行有非零元;存在非零元的行含有多少个非零元则由csr-rowstarts'来表示,如:第0行中非零元的个数由数组csr-rowstarts'数组中第二个数字2和第一个数字0决定,第0行非零元的个数为2-0=2个,第6行中非零元的个数由csr-rowstarts'中第三个数字3和第二个数字2决定,第6行非零元的个数为3-2=1个,第7行中非零元的个数由csr-rowstarts'中第四个数字4和第三个数字3决定,第7行非零元的个数为4-3=1个,第8行非零元的个数为5-4=1个,第9行非零元的个数为6-5=1个,第10行非零元的个数为7-6=1个,第11行非零元的个数为8-7=1个,第12行非零元的个数为9-8=1个,第13行非零元的个数为10-9=1个,第14行非零元的个数为11-10=1个,第15行非零元的个数为12-11=1个。
通过上述变换将数组rowstarts[v']的存储空间17*32=544bit用数组csr-rowstarts'占有12*32=384bit和row-bitmap占有16bit,总共384+16=400bit来存储,存储空间节约率为26%之多。实际工程中,图的规模会非常大,节点通常是成千上万亿个顶点,图用邻接矩阵表示时“稀疏”的特性会越明显,随着真实图遍历中非零元的增加,采用这种存储方法时存储空间节约率越来越大。
第五步、计算列数组colums[v″]连续片段长度并构建连续片段二元组集合。
具体方法如下:
5.1.定义二元组集合
5.2.定义循环变量m=0,令len=1;
5.3.定义当前位置cur=m;
5.4.若cur<v″,转5.5,否则,统计完毕,转第六步;
5.5.若colums[cur]==colums[m+1],转5.6,否则,进行下一个连续片段统计,转5.9;
5.6.len=len+1;
5.7.colums=colums[cur];
5.8.m=m+1;
5.9.若m<v″,转5.5,否则,当前片段统计完毕,转5.9;
5.10.将二元组<colums,len>以元素形式加入集合f,即,f=f+{<colums,len>};
5.11.cur=cur+len,转5.4;
第六步、依据二元组集合f构建简化列数组和列方向位图数组,由简化列数组和列方向位图数组压缩存储列数组colums[v″]全部信息,具体方法如下:
6.1.统计二元组集合f中的元素个数,记为s1;
6.2.统计二元组集合f中的元素的第二元信息len≥2的个数,记为s2;
6.3.令尺度变量size=s1+s2;
6.4.定义含有size个元素的简化列数组colums'[size];
6.5.定义列方向位图数组column-bitmap[size],列方向位图数组中的元素1表示连续片段,列方向位图数组中的元素0表示非连续片段;
6.6.定义集合f-tmp=f;
6.7.定义变量s=0;
6.8.若
6.9.将二元组f从集合f-tmp中删除,f-tmp=f-tmp-{f};
6.10.若f.len=1,f.len表示二元组f的len值,转6.11;否则,f.len≥2,转6.14;
6.11.令colums'[s]=f.colums,f.colums表示二元组f的colums值;
6.12.令column-bitmap[s]=0,表示对应的列编号不是连续片段的起始列编号;
6.13.s=s+1;转6.20。
6.14.令column-bitmap[s]=1,表示对应的列编号是连续片段的起始列编号。
6.15.令colums'[s]=f.colums;
6.16.s=s+1;
6.17.column-bitmap[s]=0;表示连续片段的长度值并不是连续片段的起始列编号;
6.18.令colums'[s]=f.len;
6.19.s=s+1;
6.20.若s<size,转6.8,否则,转第七步;
第七步、结束。
如图4所示,经过第六步后,图2所示的列数组colums[v″]采用改进列数组colums'和位图数组colums-bitmap来存储,colums-bitmap中的每一位对应所在的列编号是否为连续列编号片段的起始列编号,1表示对应的列编号为连续片段的起始列编号,0表示非连续片段len≥2的列编号或是连续片段长度的指示,若0的紧前一位(即紧邻的前一位)是1则表示连续片段的长度指示,若0的紧前一位是0则表示列位置,非连续片段指示。如图4中:colums-bitmap第一个数字0表示对应colums'中第一个数字4为第一个非零元的列编号;第二个数字0表示表示对应colums'中第二个数字5为第二个非零元的列编号;第三个数字0表示表示对应colums'中第三个数字3表示第三个非零元的列编号;第四个数字1表示连续片段的起始列标号为colums'中第四个数字1,即第四个非零元的列编号为1;由于它的紧前第四个数字是1,第五个数字0表示连续片段的长度,其长度值为colums'中五个数字2;第六个数字0表示colums'中第六个数字6为第六个非零元的列编号;第七个数字1表示连续片段的起始列标号为colums'中第七个数字1,即,第七个非零元的列编号为1;由于它的紧前第七个数字是1,第八个数字0表示连续片段的长度,其长度值为colums'中八个数字4;第九个数字1表示连续片段的起始列标号为colums'中第九个数字3,即,第九个非零元的列编号为3;由于它的紧前第九个数字是1,第十个数字0表示连续片段的长度,其长度值为colums'中十个数字2;
通过上述变换将列数组colums[v″]的存储空间12*32=384bit用数组colums'和row-bitmap来存储,colums'占有10*32=320bit,row-bitmap占有10bit,总共320+10=330bit,存储空间节约率为13%,同行方向位图的原因一样,图的规模越大,随着真实图遍历中非零元的增加,存储空间节约率越来越大。
实验测试表明,基于列方向位图的csr存储方法可以进一步节约近30%的存储空间,进一步增大了图的测试规模,提升了每秒遍历的边数量,优化了graph500测试性能。
因此,基于本发明双向位图的csr存储方法可以节约近75%的存储空间,增大图的测试规模,提升每秒遍历的边数量,优化graph500测试性能。
- 还没有人留言评论。精彩留言会获得点赞!