一种可重构的深度置信网络实现系统的制作方法
本发明涉及人工智能算法领域,尤其涉及一种可重构的深度置信网络实现系统。
背景技术:
随着机器学习的进步和深度学习的出现,一些工具和图形表示被逐渐用来关联大量的数据。深度置信网络(deepbeliefnetworks,dbn)在2006年被hinton等人提出,其本质上是一种具有生成能力的图形表示网络,即它生成当前示例的所有可能值。作为概率统计学与机器学习和神经网络的融合,dbn由多个带有数值的层组成,其中层之间存在关系,而数值之间没有。深层置信网络主要目标是帮助系统将数据分类到不同的类别,广泛地应用于模式识别、特征提取等应用场景中。因此,研究适用于各种应用场景,灵活可配的深度置信网络实现系统具有极强的理论意义与应用价值。
dbn可以被看成简单的无监督网络的组成,如受限玻尔兹曼机(restrictedboltzmannmachine,rbm)。作为dbn的重要组成部分,rbm只有两层神经元,一层叫做显层(visiblelayer),由显元(visibleunits)组成,用于输入训练数据。另一层叫做隐层(hiddenlayer),相应地,由隐元(hiddenunits)组成,用作特征检测器(featuredetectors)。
dbn的训练和推理算法都是一层一层进行的,每个子网络的隐层作为下一层的显层。和其他神经网络不同的是,dbn的训练是逐层进行的,先对一个rbm应用对比分歧(contrastivedivergence,cd)算法充分训练后才进行下一个rbm的训练。通过这种非监督贪婪逐层方法,可以获得生成模型的权值。在这个训练阶段,在显层会产生一个向量v,通过它将值传递到隐层。反过来,显层的输入会被随机的选择,以尝试去重构原始的输入信号。最后,这些新的可视的神经元激活单元将前向传递重构隐层激活单元,获得向量h。在训练过程中,首先将可视向量值映射给隐单元;然后可视单元由隐层单元重建;这些新可视单元再次映射给隐单元,以获得新的隐单元,执行的这种反复步骤叫做gibbs采样。隐层激活单元和可视层输入之间的相关性差别就作为权值更新的主要依据。
若干次训练后,隐层不仅能较为精准地显示显层的特征,同时还能够较好的还原显层,因此被大量用于模式识别、特征提取。但现有的深度置信网络算法大多聚焦于应用层面,少有高效灵活的深度置信网络实现系统及架构被提出,无法兼顾性能与灵活性,并不能很好地满足实际应用的需求。
技术实现要素:
本发明的目的在于克服以上现有技术之不足,提供一种可重构的深度置信网络实现系统,该系统可以有效地提高深度置信网络的配置灵活性,减少硬件资源开销,更好地满足实际应用的需求,具体由以下技术方案实现:
所述可重构的深度置信网络实现系统,包括:
数据暂存单元,存储计算所需的输入层信息、权重、偏置及输出层结果;
受限玻尔兹曼机,计算深度置信网络中各层结点的激活概率,以决定其激活概率及激活状态;
参数更新单元,更新深度置信网络中各层结点的权重及偏置;
控制单元,读取配置信息,通过内部的有限状态机控制深度置信网络算法的运算流程,通过复用受限玻尔兹曼机、选通参数更新单元以实现训练和推理两种算法。
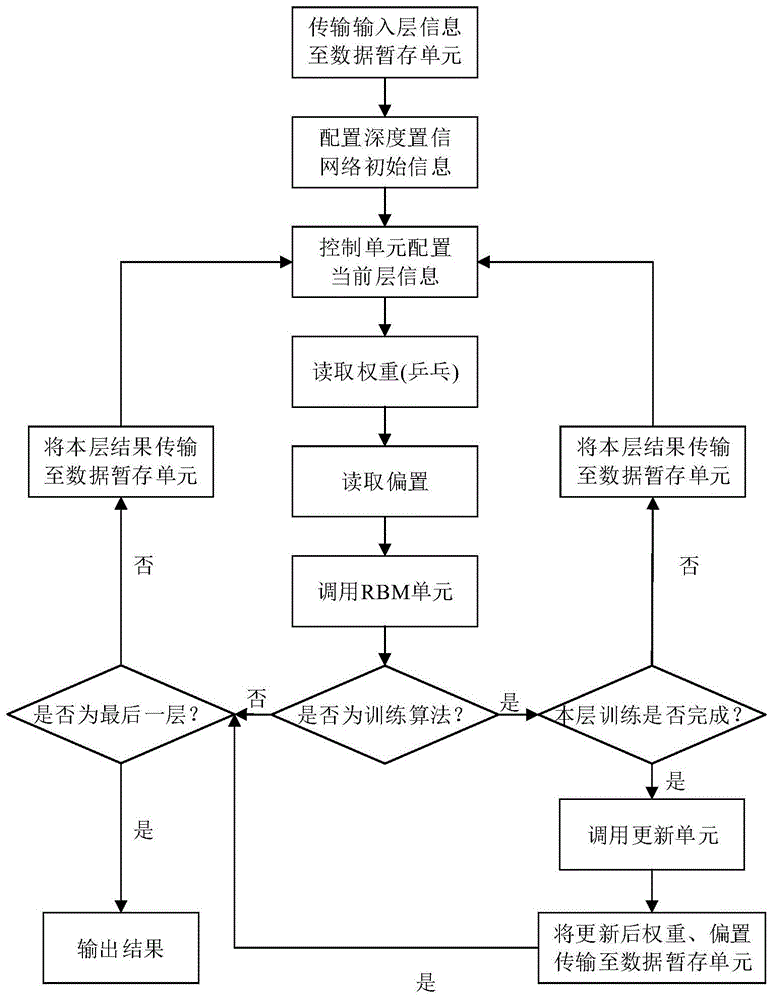
所述可重构的深度置信网络实现系统的进一步设计在于,该系统的计算流程包括如下步骤:
步骤1)初始化:读取存储在数据暂存单元中的深度置信网络输入层信息及网络配置信息,并将配置信息传输至控制单元,并将当前访问层数置为1;
步骤2)数据传输:控制器根据当前访问层数将对应的输入层信息、权重及偏置传输至数据暂存单元;
步骤3)调用受限玻尔兹曼机:受限玻尔兹曼机读取数据暂存单元中存储的信息,计算出深度置信网络当前层所对应的输出层中各神经元的激活概率及激活状态,并存入数据暂存单元中;
步骤4)判决:根据当前执行的算法判决下一步操作,若执行训练算法,判断当前层的训练是否完成,未完成则返回步骤2),已完成则执行步骤5);若执行推理算法,判断当前层是否为最后一层,如果为最后一层则将输出层的激活状态输出作为最终结果,算法结束,否则返回步骤2);
步骤5)参数更新:调用参数更新单元,根据数据暂存单元中存储的信息对权重、偏置进行更新并传输回数据暂存单元中,然后判断当前层是否为最后一层,为最后一层则训练结束,否则返回步骤2)。
所述可重构的深度置信网络实现系统的进一步设计在于,所述配置信息包括网络层数、各层结点个数、执行的算法类型、当前访问层数及当前层训练状态。
所述可重构的深度置信网络实现系统的进一步设计在于,该系统可根据配置信息进行重构,执行训练或推理算法,所执行深度置信网络的层数及各层结点个数灵活可配。
所述可重构的深度置信网络实现系统的进一步设计在于,所述受限玻尔兹曼机由n输入乘加树、累加器、超越函数运算器、除法器、伪随机数发生器及比较器组成,乘加树用于计算权重与输入乘累加的结果,累加器用于将乘加树输出的结果与偏置进行累加,超越函数运算器用于计算出输出层结点的激活概率,伪随机数发生器产生随机数,并通过比较器将其与输出层结点的激活概率进行比较,以决定结点的激活状态。
所述可重构的深度置信网络实现系统的进一步设计在于,所述n输入乘加树的参数n代表并行路数,其取值取决于运算资源,n路并行实现架构包括:n个乘法器,n输入加法树、n/4个累加器、一个超越函数及一个比较器。
所述可重构的深度置信网络实现系统的进一步设计在于,所述数据暂存单元根据执行算法类型进行拆分,执行训练算法时,将数据暂存单元拆分为5*n个存储块,其中权重乒乓存入2*n个存储块中的前二分之一空间,另有n个存储块的前二分之一空间存放偏置,输入层数据存在n个bank中,输出层数据占据数据暂存单元中的其余空间;对于推理算法,权重和偏置分别乒乓存入2*n个存储块中,输入层数据存在n个存储块中,输出层数据直接覆盖输入层数据。
所述可重构的深度置信网络实现系统的进一步设计在于,所述参数更新单元仅在训练过程中更新权重和偏置时才被激活,通过先前rbm单元的输出及数据暂存单元中存放的信息更新深度置信网络中各层结点的权重及偏置,其具体方法如式(1):
w=w+λ(p(h1|v1)·v1-p(h2|v2)v2)
b=b+λ(v1-v2)
c=+mp(h1|v1)-p(h3|v2))
(1)
其中,λ表示学习率,w表示信息对层间权重,v1、v2表示显层神经元的激活状态,h1、h2表示隐层神经元的激活状态,c表示隐层偏置,b表示显层偏置,p表示神经元被激活的概率。
该单元的运算资源均为基本的乘加单元,在进行完权重及偏置的更新后将更新好的权重及偏置存回数据暂存单元中。
本发明的优点如下:
第一,本发明实现了一种高性能可重构的深度置信网络实现系统,可实现训练和推理两种算法,网络层数及各结点个数均灵活可配,适用于各种应用场景。
第二,本发明提出了一种可以复用的受限玻尔兹曼机,采用全流水的多路并行设计方式,以缩短推理与训练算法的运算周期,提高算法效率及硬件利用率。
第三,本发明提出的数据暂存单元可支持裁剪和拆分以实现无冲突访存,以保证运算的全流水。
第四,本发明架构的主要计算单元为加法器和乘法器,非常适合硬件实现,在保证性能的情况下,拥有低计算复杂度和低硬件开销。
综上所述,本发明可以有效地提高系统的性能、灵活性、数据处理能力和访存带宽,有着良好的实际应用价值。
附图说明
图1是本发明的可重构的深度置信网络实现系统的流程示意图。
图2是本系统的数据暂存单元无冲突访存示意图。
图3为本系统的模块流程示意图。
图4是本系统的受限玻尔兹曼机模型示意图。
具体实施方式
下面结合附图对本发明方案进行详细说明。
本发明所述的可重构的深度置信网络实现系统,由控制单元,受限玻尔兹曼机,参数更新单元,数据暂存单元几部分组成,如图1所示。
控制单元,读取包括网络层数l,各层结点个数ni,执行的算法类型(训练/推理),当前访问层数t及当前层训练状态在内的配置信息,通过有限状态机控制深度置信网络算法的运算流程,通过复用受限玻尔兹曼机、选通参数更新单元以实现训练和推理两种算法。
受限玻尔兹曼机用于计算深度置信网络中各层结点的激活概率,以决定其激活概率及激活状态。其包括:n输入乘加树,累加器,超越函数运算器,除法器,伪随机数发生器及比较器。其个数由并行路数决定,n路并行需要n个乘法器,n输入加法树,n/4个累加器,一个超越函数运算器及一个比较器。乘加树用于计算权重与输入乘累加的结果∑iwi,jxi,累加器用于将乘加树输出的结果与偏置进行累加,得到(bj+∑iwi,jxi),超越函数运算器用于计算出输出层结点的激活概率σ(bj+∑iwi,jxi),伪随机数发生器产生随机数,并通过比较器将其与输出层结点的激活概率进行比较,以决定结点的激活状态。
数据暂存单元用于存储计算所需的输入层信息、权重、偏置及输出层结果,可根据运行算法的类型及并行度进行裁剪拆分。执行训练算法时,将数据暂存单元拆分为5*n个bank,其中权重乒乓存入2*n个bank中的前二分之一,另有n个bank的前二分之一存放偏置,输入层数据存在n个bank中,输出层数据占据bank中的其余位置,以实现无冲突访存,其示意图如图2所示。对于推理算法,权重和偏置分别乒乓存入2*n个bank中,输入层数据存在n个bank中,输出层数据直接覆盖输入层数据。
参数更新单元仅在训练过程中更新权重和偏置时才被激活,通过先前rbm单元的输出及数据暂存单元中存放的信息更新深度置信网络中各层结点的权重及偏置,其具体方法如下所示:
w=w+λ(p(h1|v1)·v1-p(h2|v2)v2)
b=b+λ(v1-v2)
c=+λ(p(h1|v1)-p(h2|v2))
(1)
其中λ表示学习率,在本发明中的取值为0.1。该单元的运算资源均为基本的乘加单元,在进行完权重及偏置的更新后将更新好的权重及偏置存回数据暂存单元中。
本实例所述的可重构的深度置信网络实现系统,其具体实现流程图如图3所示,具体步骤如下:
步骤1)初始化:读取存储在缓存中的深度置信网络输入层信息input及网络配置信息,并将配置信息传输至控制单元,其中包含网络层数l,每层结点个数ni(i=1,…,l)及执行的算法类型(训练/推理),将当前访问层数t置为1;
步骤2)数据传输:控制器根据当前访问层数t将对应的输入层信息v,层间权重w,各层偏置传输至数据暂存单元,传输结束后跳转至步骤3);
步骤3)调用受限玻尔兹曼机:rbm单元读取数据暂存单元中存储的输入层信息v,权重w及偏置b,计算出深度置信网络当前层所对应的隐层中各神经元的激活概率p(hj|v)(j=1,…,nt)及激活状态hj并存入数据暂存单元中,其模型示意图如图4所示,具体计算方式如下所示:
其中σ为sigmoid函数:
步骤4)判决:根据当前执行的算法判决下一步操作,若执行训练算法,判断当前层的训练是否完成,未完成则返回步骤2),已完成则执行步骤5);若执行推理算法,判断当前层t是否等于dbn的总层数l,若t=l则将输出层的激活状态输出作为最终结果,算法结束,否则返回步骤2)。当执行训练算法时,本发明的实施基于cd算法,需调用rbm单元3次,每调用一次令训练状态s=s+1,直至s=3后重置s为1,其三次调用的详细步骤如下:
步骤4-1)将输入层信息赋给显层v1,计算出隐层中每个神经元被激活的概率p(h1|v1),并通过激活概率得到隐层神经元的激活状态h1,令s=1;
步骤4-2)用h1重构显层,即通过隐层反推显层,计算显层中每个神经元被激活的概率p(v2|h1),并通过激活概率得到显层神经元的激活状态v2,令s=2;
步骤4-3)使用所推出的显层神经元的激活状态v2,计算出隐层中每个神经元被激活的概率p(h2|v2),并通过激活概率得到隐层神经元的激活状态h2,令s=3;
步骤5)参数更新:调用参数更新单元,根据数据暂存单元中存储的信息对层间权重w、显层偏置b、隐层偏置c进行更新并传输至数据暂存单元中,然后判断当前层是否为最后一层,为最后一层则训练结束,否则返回步骤2)。
综上所述,本实施例的可重构的深度置信网络实现系统,采用了全流水的多路并行设计方式,可实现训练和推理两种算法,网络层数及各结点个数均灵活可配,具有低计算复杂度、低硬件开销及高硬件利用率,同时显示了对于实际应用的巨大潜力。
- 还没有人留言评论。精彩留言会获得点赞!