使用掩模来提高卷积神经网络对于癌细胞筛查应用的分类性能的制作方法
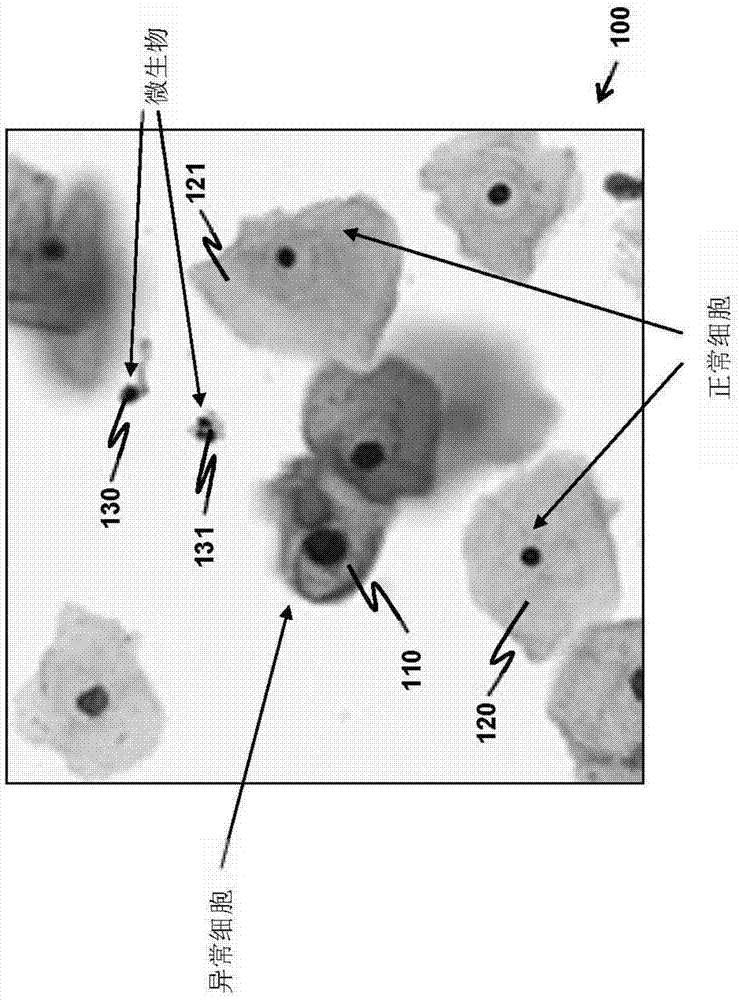
adc宫颈腺癌agc非典型腺体细胞异常ais原位腺癌asc-h非典型鳞状细胞-不排除hsilasc-us意义不明确的非典型鳞状细胞异常cnn卷积神经网络hsil高度鳞状上皮内病变lsil低度鳞状上皮内病变scc鳞状细胞癌tbsbethesda系统wsi全视野数字切片本发明涉及用于提高卷积神经网络(cnn)在细胞分类中的性能的方法。更特别地,本发明涉及用于提高在癌细胞筛查中使用的cnn的分类性能的方法。
背景技术:
:宫颈癌是产生于女性宫颈的癌症。宫颈癌筛查的常规方法是细胞化验员通过显微镜直观检查切片上的宫颈细胞来核查有恶性变化迹象的任何细胞。一般地,单个样本中需要检查约100000个细胞。该检查过程耗费大约10-15分钟并且从而耗时且成本很高。为了减少时间和成本,计算机辅助自动癌症筛查特别有用。由于各种图像分类任务中的高准确度,cnn例如在us9,739,783和cn106991673中已经被用于自动宫颈癌筛查。然而,用对抗性样本来训练cnn已显示出导致cnn分类性能明显下降。每个对抗性样本是包含经分类和标记的宫颈细胞并且进一步包括一定数量的无关对象(例如噪杂背景、无关细胞、微生物或甚至在背景中具有相反标签的细胞)的图像。作为说明示例,图1是现实生活中的对抗性样本。用于训练cnn的训练图像100具有异常细胞110作为用于训练cnn的主预分类对象。在异常细胞110附近,有邻近的正常细胞120、122和微生物130、131。正常细胞120、121和微生物130、131是干扰cnn的训练过程的无关对象。这些无关对象可能使cnn学习不正确的特征,由此导致误分类。需要这样一种技术,这种技术在存在干扰的无关对象的情况下会提高cnn对异常细胞成功分类的机会。技术实现要素:在本发明中,掩模有利地用于在存在干扰的无关对象的情况下提高cnn在对异常细胞分类时获得的分类准确度。本发明的第一方面提供由一个或多个计算处理器执行以通过使用cnn来对多个细胞分类的方法。在该方法中采用图像端掩蔽法。多个细胞初始可以从患者宫颈获得以用于癌细胞筛查或癌前异常筛查。在该方法中,获得多个训练图像和多个测试图像。该多个训练图像用于训练cnn。单个训练图像包含一个或多个细胞,每个细胞被预分类为属于一细胞类型,该细胞类型选自一组预定的细胞类型。每个测试图像包含选自多个细胞的相应细胞。选择掩模用于掩蔽训练和测试图像。掩模具有从掩模的中心向其周边单调递减的透过率函数,使得掩模的中心比其周边更透明。单个训练图像用掩模来掩蔽以形成单个经掩蔽的训练图像以便生成多个经掩蔽的训练图像。用多个经掩蔽的训练图像来训练cnn。当经预分类的一个或多个细胞位于单个训练图像中心附近并且单个训练图像进一步包含位于单个训练图像的周边附近的第一多个无关对象时,通过使用单个经掩蔽的训练图像而不是原始的单个训练图像,在训练cnn时减少了由于第一多个无关对象引起的干扰。优选地,单个测试图像也用掩模进行掩蔽以形成单个经掩蔽的测试图像以便生成多个经掩蔽的测试图像。在训练后通过用cnn来处理多个经掩蔽的测试图像来根据一组预定细胞类型对多个细胞分类以产生多个分类结果。当相应细胞位于单个测试图像中心附近并且单个测试图像进一步包含位于单个测试图像周边附近的第二多个无关对象时,通过使用单个经掩蔽的测试图像而不是原始的单个测试图像,在对相应细胞分类时减少了由于第二多个无关对象引起的干扰。本发明的第二方面提供由一个或多个计算处理器执行以用于通过使用cnn来对多个细胞分类的方法。在该方法中采用特征端掩蔽法。多个细胞初始可以从患者宫颈获得以用于癌细胞筛查。在该方法中,cnn被配置成包括多个层、卷积掩蔽层和分类层。该多个层用于基于cnn接收的输入图像来生成多个特征图。卷积掩蔽层用于使掩模与特征图中的每个卷积以便生成多个尺寸缩小的特征图。掩模具有全零最外侧区域和非零卷积核。最外侧区域具有均匀的像素宽度。分类层用于根据尺寸缩小的特征图生成分类结果。在该方法中,获得多个训练图像和多个测试图像。该多个训练图像用于训练cnn。单个训练图像包含一个或多个细胞,每个细胞被预分类为属于一细胞类型,该细胞类型选自一组预定的细胞类型。测试图像中的每个包含从多个细胞选择的相应细胞。用多个经掩蔽的训练图像来训练cnn,其中cnn接收经掩蔽的训练图像中的每个作为输入图像。在训练后通过用cnn处理多个经掩蔽的测试图像来根据一组预定细胞类型对多个细胞分类以产生多个分类结果,其中cnn接收经掩蔽的测试图像中的每个作为输入图像。本发明的第三方面提供用于由cnn根据如在本发明的第一或第二方面中阐述的方法来将多个细胞分类为正常和异常细胞的系统。该系统用于癌细胞筛查和/或癌前异常筛查。系统包括一个或多个计算处理器,其被配置成执行下列操作。首先,获得包含多个细胞的切片的全视野数字切片(wsi)以用于癌细胞筛查。在使用cnn来对多个细胞分类之前,预处理wsi来获得多个测试图像,每个测试图像包含从多个细胞选择的相应细胞。获得用于训练cnn的多个训练图像,其中单个训练图像包含一个或多个细胞,每个细胞被预分类为属于一细胞类型,该细胞类型选自一组预定的细胞类型。执行根据本发明的第一或第二方面的方法的实施例中的任一个,由此获得多个分类结果。后处理多个分类结果来产生bethesda(tbs)分级。本发明的其他方面如由下文的实施例说明的那样公开。附图说明图1描绘现实生活中的对抗性样本作为用于训练cnn以用于癌细胞识别的示例图像。图2是示出一般情况下由细胞化验员通过显微镜观看来识别异常细胞所观察到的视觉图像的草图,其示意了细胞化验员通常将目标异常细胞位于视觉图像中心附近并且看不到图像四个角周围的任何对象。图3描绘根据本发明的在cnn处理之前使用掩模来处理输入图像的示范性过程。图4描绘可用于处理经掩蔽图像的cnn的一个典型实现方式。图5描绘根据用于对细胞分类的方法的一个实施例的步骤的处理流程,其中使用了图像端掩蔽法。图6为了说明而描绘了具有圆对称透过率函数的掩模。图7描绘具有圆对称透过率函数的掩模的示例。图8描绘示意了在cnn中执行的池化操作的示例。图9提供掩蔽特征图的概念图示。图10描绘掩蔽特征图的一个实际实现方式。图11是使用特征端掩蔽法的示范性cnn的示意图。图12描绘根据用于对细胞分类的方法的另一个实施例的步骤的处理流程,其中使用了特征端掩蔽法。图13描绘用于癌细胞筛查和/或癌前异常筛查的示范性系统的示意结构。具体实施方式当在本文中使用时,训练图像意指用于训练cnn的图像,并且测试图像意指由cnn处理过或待处理以用于分类的图像。此外,此处在说明书和附上的权利要求中,应该理解“包含细胞的图像”意指图像包含细胞的子图像而不是图像包含实体细胞。本发明关于通过使用cnn来对细胞分类。该分类的重要应用包括癌细胞筛查和癌前异常的筛查。然而,本发明不限于仅癌细胞筛查和癌前异常筛查的应用。本发明可用于其他医学和生物学应用。此外,并不限制该分类中涉及的细胞仅源于人类。细胞可以源于动物(例如马)或源于植物。在下文,参考用于宫颈癌细胞筛查的cnn分类的应用来示范性说明本发明。用于训练cnn以进行宫颈癌筛查的训练图像通常由人类细胞化验员通过显微镜搜寻切片上沉积的异常细胞、接着对识别的异常细胞成像来制备。图2是示出细胞化验员通过显微镜观看的包含异常细胞的典型视觉图像的草图。作为人的本能,细胞化验员一般将感兴趣的异常细胞210放置在显微镜图像200的中心220附近。此外,图像200的四个角231-234中的任何对象无法观察并且由此在细胞化验员检查图像200时被忽略。该观察启示发明人在训练cnn之前使用掩模掩蔽训练图像。发明人还将该想法扩展到有利地掩蔽要供应给cnn以进行分类的测试图像。本发明的第一方面提供由一个或多个计算处理器执行以用于通过使用cnn来对多个细胞分类的方法。图3描绘根据本发明使用掩模来处理输入图像310的示范性过程,该输入图像310可以是训练图像或测试图像。输入图像310施加掩模320来形成经掩蔽的图像330。掩模320具有透过率函数,透过率函数用于描述掩模320上透明度的分布。特别地,掩模320具有沿从掩模320的中心321到其周边322的任何直线路径(比如路径325,其在掩模320上形成直线)单调递减的透过率函数。透过率函数提供沿路径325的任何位点上的透过率值。透过率是示出掩模的透明性的值,并且透过率在0到1之间。通过选择单调递减的透过率函数,如果路径325上的第一位点比路径325上的第二位点更接近周边322,则该第一位点处的透过率小于或等于该第二位点处的透过率。此外,选择透过率函数使得在掩模320上,中心321比周边322更透明。假设i’x,y是位于经掩蔽的图像330的坐标(x,y)处的像素的亮度值。则i’x,y由i’x,y=ix,y×hx,y给出,其中ix,y是在输入图像310的(x,y)处的像素的亮度值,并且hx,y是掩模320在(x,y)处的透过率值。在输入图像310包含多个颜色通道(例如rgb通道)的情况下,掩模320的透过率函数被应用于输入图像310的每个通道来产生经掩蔽的图像330。根据输入图像310是训练图像还是测试图像,经掩蔽的图像330由cnn进行处理以用于训练或用于推断。用于处理经掩蔽的图像330的cnn是常规cnn。在现有技术中,存在提供cnn实现的细节的参考文献,例如1998年11月ieeeproceedings卷86、11期、2278-2324页y.lecun等人的“gradient-basedlearningappliedtodocumentrecognition(应用于文档识别的基于梯度的学习)”,将上述参考文献通过引用结合到本文中。图4描绘可用于处理经掩蔽的图像330的一个典型cnn实现方式。cnn400包括多个层420,用于基于经掩蔽的图像330生成多个特征图。层420中的每个可以是卷积层、子采样层或池化(pooling)层。特征图然后由分类层430进行处理以产生分类结果495。如果从训练图像生成经掩蔽的图像330,则将分类结果495与为训练图像预定的类别进行比较来确定如何更新cnn。在从测试图像生成经掩蔽的图像330的情况下,cnn400产生测试图像的分类结果495。公开的用于通过使用cnn来对多个细胞分类的方法借助于图5示范性说明,图5描绘根据方法的一个实施例的步骤的处理流程。在预备步骤510中,获得多个训练图像和多个测试图像。该多个训练图像用于训练cnn。单个训练图像包含一个或多个细胞,每个细胞被预分类为属于一细胞类型,该细胞类型选自一组预定的细胞类型。测试图像中的每个包含从多个细胞选择的相应细胞。在方法用于癌细胞筛查或癌前异常筛查的情况下,成像在多个测试图像上的多个细胞初始从患者的身体部位或器官获得。如果打算针对宫颈癌来对患者进行诊断,则用于获得多个细胞的器官是患者的宫颈。对于宫颈癌诊断来说,一组预定细胞类型包括非异常对象和一个或多个异常细胞。一个或多个异常细胞可以包括以下中的一个或多个:lsil(低度鳞状上皮内病变)、hsil(高度鳞状上皮内病变)、agc(非典型腺体细胞异常)、asc-us(意义不明确的非典型鳞状细胞异常)、asc-h(非典型鳞状细胞-不排除hsil)、scc(鳞状细胞癌)、ais(原位腺癌)和adc(宫颈腺癌)。另外在步骤510中,选择用于掩蔽训练和测试图像中的每个的掩模。如上文提到的,掩模具有从掩模中心向其周边单调递减的透过率函数,使得掩模中心比其周边更透明。在步骤520中,用掩模来掩蔽单个训练图像以形成单个经掩蔽的训练图像。由此,生成多个经掩蔽的训练图像。多个经掩蔽的训练图像用于在步骤530中训练cnn。当经预分类的一个或多个细胞位于单个训练图像中心附近以用于对多个细胞分类时,并且当单个训练图像进一步包含位于单个训练图像周边附近的第一多个无关对象(例如正常细胞120、121和微生物130、131,如在图1中所示)时,通过使用单个经掩蔽的训练图像而不是原始的单个训练图像,在训练cnn时有利地减少了由于第一多个无关对象引起的干扰。干扰减少允许在对多个细胞的分类时提高准确度。无关对象通常不仅在多个训练图像中而且在多个测试图像中也存在。尽管掩模可以用于掩蔽单个训练图像以提高cnn分类性能,但是优选地,掩模也用于掩蔽单个测试图像以用于额外提高分类性能。在步骤540中,用掩模来掩蔽单个测试图像以形成单个经掩蔽的测试图像。由此生成多个经掩蔽的测试图像。步骤540可以在执行步骤530之前或之后执行。在步骤530中训练cnn之后,在步骤550中通过用经训练的cnn处理在步骤540中获得的多个经掩蔽的测试图像来根据一组预定细胞类型对多个细胞分类,从而产生多个分类结果。当上述相应细胞位于单个测试图像中心附近时并且当单个测试图像进一步包含位于单个测试图像周边附近的第二多个无关对象时,cnn具有通过使用单个经掩蔽的测试图像而不是原始的单个测试图像来使在对相应细胞分类时减少由于第二多个无关对象引起的干扰这一优势。作为掩模的一个方便实用的选择,它的透过率函数关于掩模中心是对称的。优选地,透过率函数关于中心圆对称。为了说明,图6描绘具有中心620的掩模610。掩模610上坐标(x,y)处的位点630与中心620相隔距离635,表示为dx,y。在(x,y)处,掩模610具有一定透过率,表示为hx,y。如果透过率函数关于中心620圆对称,则透过率函数是dx,y的函数,而不管x和y的单个值如何。将h(dx,y)表示为dx,y的圆对称透过率函数。图7描绘具有圆对称透过率函数的掩模的一些实际示例。锐利掩模710具有被完全非透明部分712环绕的圆形透明部分711。两个部分711、712截然不同并且不重叠。锐利掩模710的透过率函数由以下给出:h(dx,y)=1(dx,y≤r),否则h(dx,y)=0,其中r是圆形透明部分711的半径。作为锐利掩模710的备选,可以使用从透明部分到完全非透明部分具有渐变的过渡的梯度掩模。在一个实施例中,梯度掩模具有由h(dx,y)=1/(1+(dx,y/a)2b)给出的透过率函数,其中a和b是用于限定透过率函数的参数。图7描绘两个梯度掩模,每个梯度掩模具有矩形形状,作为示例:第一梯度掩模720(其中a=0.55w并且b=7),和第二梯度掩模730(其中a=0.5w并且b=3),其中w是每个掩模侧边的长度。对于使用锐利掩模710的两个梯度掩模720、730的情况获得基于公开的方法关于cnn分类性能的实验结果。为了比较,还生成没有掩蔽训练和测试图像的cnn的分类性能。在实验中使用下列参数:16个预定细胞类型;26350个训练图像;1200个测试图像;cnn在googlenet中实现;以及在训练cnn时进行100000次迭代。分类准确度的值计算为(tp+tn)/nc,其中tp、tn和nc分别指示真阳性的数量、真阴性的数量和样本数量。在细胞级测量准确度值。表1列出对于不同情况的准确度值。表1使用的掩模分类准确度无96.5%锐利掩模71097.5%第一梯度掩模72098%第二梯度掩模73099%表1中的实验结果指示使用掩模与不使用掩模相比使分类准确度提高。在实际情形中,用一个患者的细胞制备的切片通常具有超过10000个细胞。如果分类准确度提高了1%,则不正确地被分类的细胞的数量可以减少100个,从而大大影响诊断结果。通过在公开的方法中使用掩模,可实现准确度提高超过1%。特别地,通过使用第二梯度掩模730获得2.5%提高。前面提到的发现证明了公开的方法的有用性。在本发明的第一方面中阐述的方法中,向训练和测试图像直接应用掩蔽。与先于cnn处理的掩蔽的该图像端法不同,可以在cnn部分处理输入图像后对从输入图像生成的特征图应用掩蔽。本发明的第二方面提供由一个或多个计算处理器执行以用于基于掩蔽的特征端法通过使用cnn对多个细胞分类的方法。在详述特征端掩蔽法之前,考虑常规cnn。在常规cnn中,池化层用于使在先前的层中集群的神经元的输出组合成池化层中单个神经元的输出。图8描绘示意了池化操作的示例。在示例中,假设从先前的层生成2048个特征图820,每个特征图尺寸为8×8。通过执行特征图820中的每个与某个尺寸(比如7×7)的池化掩模810的卷积来执行池化操作。因此,生成2048个特征图830,每个具有减小的尺寸2×2。在特征端掩蔽法中,在生成尺寸减小的特征图时使用卷积掩蔽层而不是池化层。图9提供特征端掩蔽法的概念图示。掩模910用于与2048个特征图82中的每个卷积。在图9中示出的示例中,掩模910设置成具有尺寸7×7,其与池化掩模810的尺寸相同。掩模910特别地具有全零最外部侧区域915和非零卷积核912。最外侧区域915具有均匀的像素宽度。卷积核912被最外侧区域915包围。在图9中示出的示例中,最外侧区域915的宽度是1个像素,由此卷积核912具有尺寸5×5。为了说明,图9示出要与掩模910相乘的特征图920。在示例中,特征图920由cnn层从尺寸为224×224的图像960变换。图像960意在用于推断。使掩模910与特征图920相乘给出经掩蔽的特征图。掩蔽特征图相当于等同推断图像950的变换结果。值得注意的是,等同推断图像950具有被中心区域952围绕的变黑的周边区域955。中心区域952包含感兴趣的细胞951。通过使用掩模910,感兴趣的细胞951被突显,而在推断中产生干扰并且驻存在变黑的周边区域955中的对象有利地被去除。图10描绘使用掩模910用于与特征图820中的每个卷积的一个实际实现方式。卷积核912(尺寸为5×5)单独用于首先与2048个特征图820中的每个卷积来产生2048个中间特征图1040,每个中间特征图尺寸为4×4。每个中间特征图(引用为1041)具有中心区域1042和周边区域1045,其中周边区域1045包围中心区域1042。周边区域1045具有1个像素的均匀宽度,其与掩模910的最外侧区域915的宽度相同。于是得出中心区域1042具有尺寸2×2。每个中间特征图1041的周边区域1045被截断而留下中心区域1042,其形成尺寸为2×2的一个尺寸缩小的特征图1051。卷积和截断的过程各自应用于全部的2048个特征图820。因此,获得2048个尺寸缩小的特征图1050。包含如上文描述的对于图9和10的操作细节的示范性cnn在图11中给出,图11描绘采用特征端掩蔽法的cnn1100的示意图。cnn1100包括多个层1120,用于基于cnn1100接收的输入图像1190生成多个特征图。在多个层1120的输出1122处获得特征图。cnn1100进一步包括卷积掩蔽层1140,用于使掩模与特征图中的每个卷积以便生成多个尺寸缩小的特征图。掩模(例如掩模910)具有全零最外侧区域和非零卷积核。最外侧区域具有均匀的像素宽度。在卷积掩蔽层1140的输出1145处获得尺寸缩小的特征图。在cnn1100中,分类层1130用于根据尺寸缩小的特征图生成分类结果1195。优选地,卷积掩蔽层1140包括卷积子层1143和截断子层1144。卷积子层1143用于从多个层1120接收特征图并且使特征图中的每个与卷积核卷积,以便生成多个中间特征图。由截断子层1144进一步处理中间特征图。截断子层1144用于截断中间特征图中的每个的周边区域来产生相应的尺寸缩小的特征图。周边区域具有等于掩模最外侧区域的宽度的均匀宽度。注意在e.teng等人在2017年9月15日的arxiv:1709.05021v1,[cs.cv]的“clickbait:click-basedacceleratedincrementaltrainingofconvolutionalneuralnetworks(clickbait:卷积神经网络的基于点击的加速增量训练)”(康奈尔大学图书馆)公开的cnn中也使用用于掩蔽特征的掩模。然而,e.teng等人的cnn在以下方面与本发明的cnn1100不同。在e.teng等人的cnn中,在对特征掩蔽之后,使用一般池化层使特征压缩。这与本发明的cnn1100不同,在本发明的cnn1100中卷积掩蔽层1140(在其中完成对特征图掩蔽)用于代替常规cnn中的池化层。cnn1100继卷积掩蔽层1140不包含池化层。此外,e.teng等人的cnn的掩蔽操作是元素方面(element-wise)的乘法操作。在cnn1100中,对应的掩蔽操作是卷积操作,后跟截断操作。另外,在e.teng等人的cnn中需要用户输入来指定在哪里应用掩模,而对于cnn1100则不需要用户输入来指定掩模位置。通过使用cnn1100,用于基于特征端掩蔽法对多个细胞分类的方法参考图12中示出的步骤来示范性说明。在预备步骤1210中,获得多个训练图像和多个测试图像。该多个训练图像用于训练cnn1100,cnn1100配置成采用特征端掩蔽法。单个训练图像包含一个或多个细胞,每个细胞被预分类为属于一细胞类型,该细胞类型选自一组预定的细胞类型。测试图像中的每个包含从多个细胞选择的相应细胞。如果将方法用于癌细胞筛查或癌前异常筛查的情况下,成像在多个测试图像上的多个细胞初始从患者的身体部位或器官获得。如果意在就宫颈癌来对患者进行诊断,则用于获得多个细胞的器官是患者的宫颈。对于宫颈癌诊断来说,一组预定细胞类型包括非异常对象和一个或多个异常细胞。一个或多个异常细胞可以包括以下中的一个或多个:lsil、hsil、agc、asc-us、asc-h、scc、ais和adc。在步骤1220中,用多个训练图像来训练cnn1100。cnn1100接收训练图像中的每个作为输入图像1190。在训练cnn1100后,在步骤1230中通过用cnn1100处理多个测试图像来根据一组预定细胞类型对多个细胞分类以产生分类结果1195,其中cnn1100接收测试图像中的每个作为输入图像1190。表2列出在实验中获得的分类准确度的值。在实验中,cnn1100分别被实现为googlenet和resnet-50。没有使用特征端掩蔽法的常规cnn也在实验中使用以用于比较。表2表2的结果证明通过使用特征端掩蔽法而使得分类性能显著提高。在对实现方式的影响方面来比较图像端掩蔽法和特征端掩蔽法是可取的。首先,在图像端掩蔽法中需要预处理训练和测试图像以生成经掩蔽的图像,而预处理对于特征端掩蔽法来说不是必需的。其次,在图像端掩蔽法中使用的掩模320通常具有比在其他方法中使用的掩模910更高的分辨率。最后,对于图像端掩蔽法,需要将cnn400的分类层430实现为全连接层。从而,cnn400是全连接网络。另一方面,对于特征端掩蔽法,cnn1100的分类层1130可以是全连接层或全卷积层。因此,cnn1100可以是全连接网络或全卷积网络。如果cnn1100被实现为全卷积网络,则可以比使用实现为全连接网络的cnn400有利地获得推断加速。本发明的第三方面提供用于由cnn根据在上文在本发明的第一或第二方面中阐述的方法来将多个细胞分类为正常和异常细胞的系统。该系统用于癌症筛查和/或癌前异常筛查。示范性地,系统借助于图13来说明,图13描绘为诊断宫颈癌和检测宫颈中出现的癌前异常而设计的系统1300的示意结构。系统1300包括诊断平台1350和分类平台1320。诊断平台1350是第一计算子系统,其与医师交互并且允许这些医师对一定(有限)数量的细胞分类和标记以用于cnn训练。因此,获得经标记的训练图像1351并且将它们发送到分类平台1320。分类平台1320是第二计算子系统,用于将细胞分类为正常和异常细胞。计算子系统可以由一个或多个计算处理器实现。分类平台1320首先获得包含用于癌细胞筛查或癌前异常筛查的多个细胞的切片的wsi1330。执行对wsi1330的预处理1322。通常,预处理1322包括将wsi1330分段为多个测试图像。预处理1322的细节在现有领域(例如cn103984958)中可获得。cnn1324(从上文公开的cnn400、1100选择)用于在用经标记的训练图像1351训练cnn1324之后处理多个测试图像。cnn1324产生多个分类结果。如果cnn400被选为cnn1324,则预处理1322进一步包括用掩模(例如,掩模710)来掩蔽测试图像和经标记的训练图像1351中的每个。实施对多个分类结果的后处理1326来产生tbs分级1332。tbs是常用于在宫颈或阴道细胞学诊断中报告子宫颈抹片检查(papsmear)结果的系统。对于tbs和tbs分级的细节,参见例如2015springer的r.nayar和d.c.wilbur的“thebethesdasystemforreportingcervicalcytology(用于报告宫颈细胞学的bethesda系统)”。上文提到的第一和第二计算系统中的每个可以由通用计算机、专门计算机、计算服务器、具有数据存储设备的一个或多个计算处理器等来实现。上述计算处理器可以是通用处理器或专门处理器,例如为cnn实现而专门设计的处理器。本发明可以采用其他特定形式体现而不偏离其精神或基本特性。本实施例因此在所有方面视为说明性而非限制性的。本发明的范围由附上的权利要求而不是前面的描述指示,并且在权利要求的等同物的含义和范围内的所有改变因此意在包含于其中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1